
毫无疑问,2023年正式进入了AIGC元年。从2019年3亿参数的Bert打开了预训练大模型之门,到2020年1750亿参数GPT-3,再到2021年1.6万亿参数的Switch Transformer,以及2022年底正式上线的ChatGPT,人类就此打开了AI预训练大模型的神奇之门。经济学家们认为, AI预训练大模型将为人类生产力的提升带来了显著和深远的影响。
预训练大模型的底座是高性能的算力集群。各大云厂商纷纷为大模型“风暴”的到来,升级自家的算力 “底座”。今年4月,腾讯云发布了新一代HCC高性能计算集群,能为大模型训练提供高性能、高带宽、低延迟的智算能力支撑。。
6月26日,腾讯云进一步披露了与HCC高性能计算集群背后的网络底座“星脉”。“星脉”也是腾讯云数据中心网络架构的第三次进化,从第一代互联网服务到第二代云服务再到第三代大规模算力驱动,腾讯云网络经历了标准化数据中心网络、超大规模数据中心网络以及高性能计算网络三代进化。可以连接10万张GPU卡的“星脉”,也代表了腾讯云网络技术自研的全面进化,为AI大模型的高效训练和产品化打通了“星辰之力”。
腾讯云数据中心网络架构
作为全球及中国的头部云厂商之一,目前腾讯云在全球26个地理区域运营70个可用区,同时部署了超过2800个CDN加速节点,全网带宽资源储备超过200T。
腾讯云网络包括云网络(即Overlay网络)和基础网络(即Underlay网络)两大部分。其中,云网络是架构在同一基础网络上的多个虚拟网络,也就是在物理设备上按需创建、相互隔离的虚拟网络,并支持租户以多种网络方式接入虚拟网络,云网络提供三大类虚拟网络,其中ECN为外联架构,主要是运营商和运营商的互联,将终端用户连进来,然后通过企业专线把企业用户连到腾讯的数据中心。
基础网络是负责数据包传统的物理网络,由真实的交换机、路由器、防火墙等物理设备构成,各设备间通过路由协议实现相互之间的连通,主要包括DCN、DCI网络。其中,DCN为数据中心内机器互联,主要是数据中心的网络,实现数据中心里面超过10万或者几十万服务器的无阻塞连接;DCI主要是数据中心之间的互联,主要实现一个城市多数据中心或者多个城市的数据中心进行互联。
腾讯云通过ECN、DCI、DCN三大网络架构,把用户和业务服务器连接起来,并将数百万台服务器连接起来。其中,腾讯云数据中心网络DCN通过自研网络操作系统、智能网管平台、自动化运营系统和网络控制器等自研技术,实现了按需扩展的超大规模数据中心网络,打造了亚洲最大规模数据中心网络,覆盖100+园区,接入近200万服务器,全自动化运营体系保证秒级自愈。
腾讯数据中心网络进化三大阶段
腾讯云副总裁王亚晨介绍,从最初的腾讯网络到“星脉”高性能计算网络,腾讯数据中心网络技术共经历了三代架构的三大阶段。

在2006年的时候,腾讯的服务器总量低于一万台,那时腾讯网络架构基本上是通过商业设备和人工运维连接及打通整个网络,主要依靠人工方式运维。到2010年的时候,当时受QQ在线人数增长超过1亿、服务器规模增长超10万的需求驱动,腾讯形成了由互联网服务驱动的以南北向流量为主的第一代网络架构。
当时,腾讯的服务器量达到了10万台,对于网络的挑战主要是快速交付,满足用户需求。腾讯提出标准化理念以及用工具支撑运维,建有标准的IDC网络架构以及城域网和广域网。在这一阶段,腾讯通过与商业厂商的合作,通过商业设备以及工具支撑,快速将网络规模扩充到10万台左右,流量达到1个T,采用自动化工具进行监控,网络时延在10-100毫秒之间,丢包率为0.1%-2%,负载率达30%,网络故障处理效率基本上在15分钟完成。
2015年以后,腾讯云快速发展。特别是2018年腾讯服务器接近100万台,这个时候面临的主要是质量挑战。随着腾讯云的快速发展,腾讯服务器规模达到了近200万台,数据中心内部的网络流量形成规模,这时进入了腾讯云的第二代网络架构,即南北向流量和东西向流量兼顾的架构。在这一阶段,因为腾讯云上承载了很多第三方租户,第三方租户对于质量非常敏感,一旦腾讯网络抖动将会形成对第三方业务的放大效应,甚至是灾难性影响。
要降低设备故障对网络的影响,首先就是采用多平面,降低单一设备对整个故障的影响,其次在有了多平面、设备变多后,再用大型商业路由器则成本较高,腾讯开始定制网络设备,将路由器转为定制的交换机。但因为交换机的性能方面弱于路由器,于是腾讯引入了控制器的概念,对转发面和控制面进行分离,把控制面提到控制器上,让控制器能够了解全网的流量情况以及全网拓扑,并且计算出最优的路由下发到交换机。在这个阶段,腾讯基本上采用定制设备、多平面以及SDN进行路由器控制,网络时延降低到500纳秒到1毫秒,丢包率为0.1%-1%,负载率为30%,任何故障可在一分钟之内得到恢复。
2019年到2020年的时候,随着腾讯云的快速发展以及用户的迅猛增加,腾讯虚拟机规模达到了千万,IPV6导致路由条目达到亿级,不论是交换机、路由器以及还是网络设计处理能力都达到瓶颈,腾讯云于是引入X86网关集群作为控制面,同时在骨干网引入了X86 NFV设备,用控制器完整地调度全网路由以及全网的配置分发和计算,腾讯也加速了网络设备的迭代及提高可运维性,主要采用白牌硬件以及开源操作系统,形成了全自主研发、可控的网络体系,这为2020年和2021年进入算力时代的网络架构变革做好了准备。
在算力时代的网络架构变革到来之际,腾讯的网络系统已经从传统网络系统过渡到分布式互联网业务系统,故障实现零容忍及自愈能力,基础设施可靠性以及可运维性及能力达到了新的阶段。
大模型驱动数据中心网络变革
“星脉”高性能计算网络是腾讯云网络的第三代架构,在千亿和万亿参数预训练大模型新需求所驱动下形成了新型网络架构,也就是超大东西向(数据中心内)流量架构。在高性能计算网络架构下,腾讯网络时延进一步降至10-40纳秒,丢包率达到0,负载率超过90%。

腾讯云副总裁王亚晨表示,AI大模型的训练计算特点是需要在各个计算节点完成单个批次的梯度计算,然后需要在网络中同步这些梯度值并更新模型参数。简单理解,这就是大规模的并行计算。但面对千亿、万亿参数规模的大模型训练,仅仅是单次计算迭代内梯度同步需要的通信量就达到了百GB量级,还有各种并行模式、加速框架引入的通信需求,使得传统低速网络的带宽远远无法支撑GPU集群的高效计算。
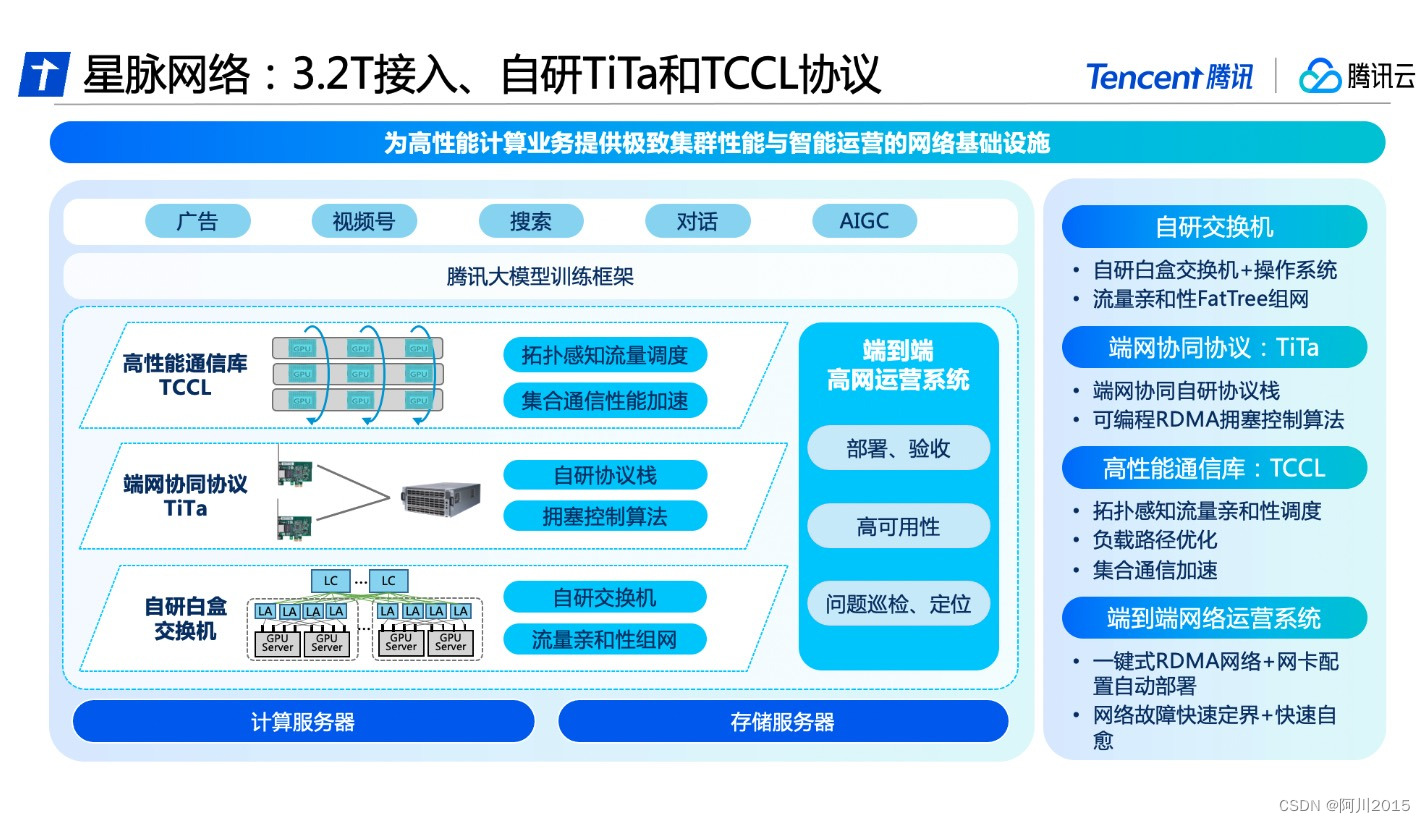
AI大模型对网络的需求为:大带宽、高利用率和无损网络。面向AI大模型训练需求,腾讯推出的业界领先的高性能计算网络架构——星脉。星脉网络在极致高性能上,采用3.2T超带宽接入、多轨道聚合流量网络架构、异构网络自适应通信优化技术、定制加速通信库,构建了3.2T ETH RDMA网络,实现了AI大模型通信性能的10倍提升,GPU利用率40%提升,通信时延降低40%,星脉单集群规模支持单 POD 1.6万个GPU 节点,最大支持10万级 GPU 集群组网。基于全自研网络硬件平台,网络建设成本降低30%,模型训练成本节省30%~60%。
简单理解,星脉网络将集群分为了Block、Pod和Cluster三个分级架构,每Block支持256个GPU,每Pod支持16-64个Block(4000-1.6个张GPU,也就是典型的集群规模),每Cluster支持最大16个Pod(6400-2.56万张GPU)以实现大规模扩展。星脉网络通过AI流量定制互联达到性能最大化,采用高性能RDMA网络实现GPU内存直接数据传输,采用无阻塞胖树(Fat-Tree)架构,确保多个层级间数据传输的均匀分布,同时能灵活扩展网络规模,星脉单集群规模支持1.6万个GPU节点(支持10万级GPU组网)。而星脉的 3.2T带宽,指的是每个计算节点(GPU服务器)之间的带宽,达到了业界最强。
星脉网络采用了多个自研“绝活儿”。首先,星脉网络采用的自研端网协同协议TiTa,提供更高的网络通信性能,特别是在满足大规模参数模型训练的需求方面。TiTa协议内嵌拥塞控制算法,以实时监控网络状态并进行通信优化,使得数据传输更加流畅且延迟降低。其次是开发了高性能集合通信库TCCL、以及多轨道流量聚合架构、异构自适应网络通信等,以协调计算资源和网络资源,充分利用计算节点间通信与处理能力,改善整个系统的性能和计算效率。
超大规模以太RDMA网络的工程实践
要实现高性能计算网络,就必须要处理GPU-GPU内存数据直接通信的问题。NVIDIA通过NVLink、NVLink Switch以及增强RDMA以太网和InfiniBand高性能网络等方式,实现不同规模GPU集群的GPU-GPU直通,但价格高昂,绝大多数厂商难以负担。而对于公有云来说,以太网是当下的标配,因此通过自研方式增强RDMA以太网就成为最佳选择。
众所周知,RDMA为业务带来了大带宽低时延,但同时其复杂多样化的配置也往往被带来了网络运营问题。在星脉网络之前,据统计高达90%的高性能网络故障都是网络配置错误导致的问题,主要原因就是网卡配置套餐多——取决于架构版本、业务类型和网卡类型等。
简单理解,要大规模实践RDMA以太网就必须要采用正确的运维方式和工具。为此,腾讯云自研了高性能网络运营平台。实现了端网部署一体化以及一键故障定位,提升高性能网络的易用性,进而通过精细化监控与自愈手段,提升网络可用性,为极致性能的星脉网络提供全方位运营保障。
在自研高性能网络运营平台提供的端网一体部署能力下,大模型训练系统的整体部署时间从19天缩减到4.5天,并保证了基础配置100%准确。在一键故障定位方面,目前已支持“性能不足”、“业务丢包”、“配置异常”、“连接建立不成功”四个维度的一键故障定位,轻松为高性能网络业务提供一键自检,健康可视等功能。而面对高性能业务的秒级自愈要求,腾讯网络转变了避障思路,既然需求起源于业务,那么就将避障的主动权交于业务。为此,腾讯云推出了秒级故障自愈产品——“HASH DODGING”。
星脉作为面向AI大模型定制优化的高性能计算网络架构,与最新代次GPU、高性能存储架构强强联合,共同打造腾讯云新一代HCC高性能计算集群。前期测试显示,星脉网络可以实现AllReduce通信性能提升13倍,All-to-All通信性能提升11倍,通信性能抖动减少85%。
展望未来:腾讯云的星脉网络还在不断进化,这就是星脉2.0——融合网卡升级+交换机升级+网络能力升级+GPU高速互联接口,打造下一代性能更高的计算集群。整体来说,星脉高性能计算网络的推出,是腾讯云面对大模型训练市场需求的快速响应,也是腾讯长期自研以太网全栈技术的大集成。没有前期自研网络技术的投入,也就没有今天腾讯第三代网络架构的进化。做大模型时代的“卖铲人”,腾讯正通过自研技术解开算力的“紧箍咒”。(文/宁川)