PolarDB-X 为了方便用户体验,提供了免费的实验环境,您可以在实验环境里体验 PolarDB-X 的安装部署和各种内核特性。除了免费的实验,PolarDB-X 也提供免费的视频课程,手把手教你玩转 PolarDB-X 分布式数据库。
本期实验将指导您如何进行PolarDB-X分区管理。
前置准备
假设已经根据前一讲内容完成了PolarDB-X的搭建部署,使用PolarDB-X Operator安装PolarDB-X,并且可以成功链接上PolarDB-X数据库。
分区管理测试
本步骤将带您体验PolarDb-X数据库中的分区管理能力。
1.准备测试表。
执行如下SQL语句,创建测试数据库part_manage并创建测试表。
-- 创建测试库
create database part_manage mode='auto';
use part_manage;
-- 创建一个表组
create tablegroup test_tg1;
-- 创建表t1并绑定到表组为test_tg1
create table t1 (
a int
) partition by key(a) partitions 5 tablegroup=test_tg1;
-- 创建表t2, 让它和t1一样绑定到表组test_tg1
create table t2 (
a int
) partition by key(a) partitions 5 tablegroup=test_tg1;
-- 创建表t2,不指定表组
create table t3 (
a int
) partition by key(a) partitions 5;
-- 手工绑定t3到表组test_tg,效果和在创建时指定是一样的
alter table t3 set tablegroup=test_tg1 force;
-- 创建range分区的表t4
create table t4 (
a int
) partition by range(a) (partition p1 values less than(100),
partition p2 values less than(500),
partition p3 values less than(1000));
-- 创建list分区的表t5
create table t5 (
a int
) partition by list(a) (partition p1 values in (1,2,3,4,5),
partition p2 values in (6,7,8,9),
partition p3 values in (10,11,12,13,14));
-- 拆分方式创建表orders,order_details 默认将按主键hash拆分
create table orders(order_id bigint primary key auto_increment,
customer_id varchar(64) default null, create_time datetime not null,
update_time datetime not null);
create table order_details(order_detail_id bigint primary key auto_increment,
order_id bigint not null, customer_id varchar(64) default null,
create_time datetime not null, update_time datetime not null);
-- 查看一下orders表的拆分方式
show full create table orders;2.查看表的结构以及拓扑信息。
2.1 执行如下SQL语句,查看表结构。
-- set show_hash_partitions_by_range=true 然后执行show full create table 可以将hash分区的表各个分区的hash空间展示出来
set enable_set_global=true;
set global show_hash_partitions_by_range=true;
show full create table t1;
2.2 执行如下SQL语句,查看当前库中的所有的表组信息。
-- 精简模式 show tablegroup;
-- 详情模式 show full tablegroup;

2.3 执行如下SQL语句,查看表的拓扑信息,包括各个分区的物理分布。
show topology from t1;
3.分区合并。
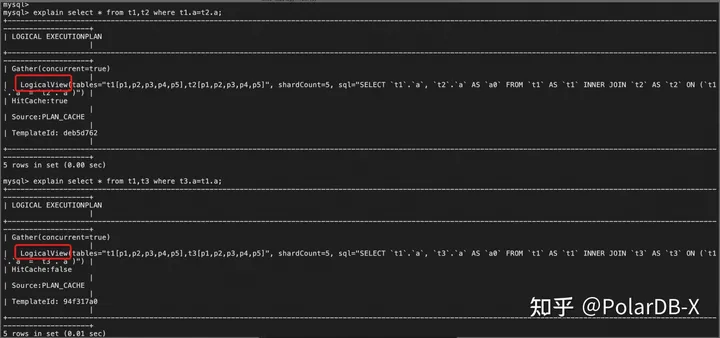
3.1 从上面的show full tablegroup可以看到,表t1、t2、t3都在表组test_tg1中,在做分区合并前,执行如下SQL语句,我们先看看他们之间的join能不能下推。
explain select * from t1,t2 where t1.a=t2.a;
explain select * from t1,t3 where t3.a=t1.a;返回结果如下,此时t1、t2 以及 t1、3的join是可以直接下推到存储节点执行的。
3.2 执行如下SQL语句,将t1的分区p2和p3合并。
alter table t1 merge partitions p2,p3 to p3;3.3 执行如下SQL语句,查看在合并完毕后t1、t2 以及 t1、3的join是否能继续下推。
explain select * from t1,t2 where t1.a=t2.a;
explain select * from t1,t3 where t3.a=t1.a;返回结果如下,合并p2、p3后,t1和t2、t1和t3的join不再下推,因为t1的分区方式和t2、t3的不一致了,表组也不一样了

3.4 目前t2和t3还在在同一个表组test_tg2中, t2和t3的join是可以下推的,如果想维持这种稳定的下推关系又想合并t2的p2和p3分区,应该怎么做?
您可以执行表组级别的分区合并,将表组内所有的表都同步执行相同的表更。例如执行如下SQL语句 ,会对test_tg2的所有表(t2、t3)都执行合并p2、p3分区的操作
alter tablegroup test_tg1 merge partitions p2,p3 to p3;3.5 原来t2、t3的join可以下推的,我们在看看执行了表组级别的分区合并之后是否能继续下推。
explain select * from t2,t3 where t3.a=t2.a;返回结果如下,执行了表组级别的分区合并之后还能继续下推。本质原因是表组内所有的表都做了相同的变更,不同表的名称相同的分区的定义和物理位置都是保持一致的,他们表组也还是相同的。

4.分区分裂。
在上面的例子中我们对表t1做了分区合并操作,在下面的例子中我们对其执行分区分裂操作。
4.1 执行如下SQL语句,在分裂前我们查看各个分区的内部hash空间。
set enable_set_global=true; set global show_hash_partitions_by_range=true; show full create table t1;返回结果如下,可以看到p3的hash空间范围是[-5534023222112865481, 1844674407370955163)。

4.2 执行如下SQL语句,我们对p3执行分裂,并查看分裂后的效果如何。
alter table t1 split partition p3;
show full create table t1;返回结果如下,可以看到分裂后相当于将p3按hash空间平均划分成两个新分区p6、p7。

4.3 对于分裂,PolarDB-X也支持表组级别的分区变更。
执行如下SQL语句,对test_tg1表组的分区变更。
alter tablegroup test_tg1 split partition p3;4.4 对于hash方式的分区表,我们在分裂的时候可以不指定新分区的任何信息,默认按照待分裂的分区的hash空间二等份分裂成两个新分区,对于range或者list拆分方式的分区表,对其分区分裂需要指定新分区的完整分区信息。例如执行如下SQL语句,分别对range分区表t4和list分区表t5执行分裂操作。
alter table t4 split partition p3 into (partition p30 values less than(600),
partition p31 values less than(800),
partition p32 values less than(1000));
alter table t5 split partition p2 into (partition p2_0 values in(6), partition p2_1 values in(7,8), partition p2_2 values in(9));5.分区迁移。
所谓分区迁移,就是将表的分区从一个存储节点迁移到另一个存储节点,以此达到数据均衡或者数据隔离的效果。所以在迁移前,我们需要知道当前实例有哪些存储节点。
5.1 执行如下SQL语句,查看当前实例的存储节点。
show storage;返回结果如下,其中INST_KIND=META_DB的节点只承担存储GMS信息,不承担普通用户表的存储任务,所有这个实例中,可以保存用户表信息的存储节点有两个,分别是polardb-x-9f8v-dn-0 和 polardb-x-9f8v-dn-1 。

5.2 接下来我们需要通过show topology from #tb的命令查看表的各个分区的物理分布。例如执行如下SQL语句,表查看t1的物理拓扑信息。
show topology from t1;返回结果如下,可以看到t1的分区p1在存储节点polardb-x-9f8v-dn-0上。

5.3 执行如下SQL语句,将t1的分区p1的存储节点迁移到polardb-x-9f8v-dn-1。
-- 实际执行过程,请根据用户的实例的存储节点信息,填写正确的存储节点 alter table t1 move partitions p1 to 'polardb-x-9f8v-dn-1'; show topology from t1;
5.4 分区迁移也支持表组级别的操作,语法如下。
-- 请根据实际情况,填写正确的存储节点信息 alter tablegroup test_tg1 move partitions p4 to 'polardb-x-9f8v-dn-1';6.修改分区值。
对于list/list column分区,PolarDB-X支持在线修改(增加或者删除分区值)各个分区的定义(也就是分区值)。
6.1 以表t5为例,执行如下SQL语句,修改前先查看各个分区定义。
show create table t5;
6.2 执行如下SQL语句,我们对表t5的分区p3增加两个值20和21。
alter table t5 modify partition p3 add values(20,21);6.3 执行如下SQL语句,查看变更后表t5的分区定义。
show create table t5;
6.4 相应的,PolarDB-X也支持删除部分分区值。执行如下SQL语句,执行如下SQL语句,我们对表t5的分区p3删除两个值20和21。
alter table t5 modify partition p3 drop values(20,21);分区修改也支持表组级别的操作,实例的具体操作如下。
6.5 执行如下SQL语句,查看t5的表组名称。
show full create table t5返回结果如下,可以看到t5的表组名称为tg4。

6.6 执行如下SQL语句,表组级别的增加分区值。
alter tablegroup tg4 modify partition p3 add values(20,21);6.7 执行如下SQL语句,表组级别的删除分区值。
alter tablegroup tg4 modify partition p3 drop values(20,21);7.重命名分区。
PolarDB-X也支持对已有分区进行重命名操作。
执行如下SQL语句,对表级别重命名分区。
alter table t4 rename partition p2 to p20;执行如下SQL语句,对表组级别的重命名分区。
alter tablegroup tg4 rename partition p3 to p30;分区热点散列测试
1.准备测试表。
执行如下SQL语句,创建测试数据库part_manage并创建测试表。
-- 创建测试库
create database hot_key_test mode='auto';
use hot_key_test;
-- 拆分方式创建表orders,order_details 默认将按主键hash拆分
create table orders(order_id bigint primary key auto_increment,
customer_id varchar(64) default null, create_time datetime not null,
update_time datetime not null);
create table order_details(order_detail_id bigint primary key auto_increment,
order_id bigint not null, customer_id varchar(64) default null,
create_time datetime not null, update_time datetime not null);2. 执行如下SQL语句,查看表的结构。
-- 查看一下默认主键拆分的orders和order_details表的拆分方式
set enable_set_global=true;
set global show_hash_partitions_by_range=false;
show full create table orders;
show full create table order_details;3. 准备测试数据。
3.1 热点值指的是某个key的某个值的行数或者写入量非常多,称为Big Key, PolarDB-X 支持热点识别及热点散列。
执行如下SQL语句,以orders、order_details为了例子,我们人为的造一下数据,让order_id=88。和order_id=null的数据特别多(表的总数据量大概100W行左右)。
insert into orders values (null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now());
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into orders select null,case cast(rand()*2 as signed) when 0 then concat("",cast(rand()*10000 as signed)) when 1 then 88 else null end ,now(),now() from orders;
insert into order_details select null, order_id,customer_id,now(),now() from orders order by rand();3.2 执行如下SQL语句,现在我们看看这两个表的各个分区的数据分布情况。
set names utf8mb4;
analyze table orders;
analyze table order_details;
select table_group_name,table_name,index_name,partition_name,table_rows,percent from information_schema.table_detail where table_schema='hot_key_test' and table_name = 'orders';
select table_group_name,table_name,index_name,partition_name,table_rows,percent from information_schema.table_detail where table_schema='hot_key_test' and table_name = 'order_details';返回结果如下,由于这两个表都是默认主键hash拆分的,所以各个分区的数据分布还是挺均衡的:

3.3 由于业务需要根据orders和order_details需要按一下关联查询统计订单信息, 查询的SQL如下。
select count(1) from orders a join order_details b on a.order_id=b.order_id and a.customer_id=b.customer_id;3.4 执行如下SQL语句,查看上一步SQL语句的执行计划。
explain select count(1) from orders a join order_details b on a.order_id=b.order_id and a.customer_id=b.customer_id;
3.5 执行如下SQL语句,查看具体执行时间。
select count(1) from orders a join order_details b on a.order_id=b.order_id and a.customer_id=b.customer_id ;
3.6 由于由于orders和order_details表都是按主键拆分的,没有在customer_id,order_id纬度拆分,所以上面的SQL需要将两个表的数据拉到CN上做JOIN,然后在聚合。为了提高以上SQL的查询效率,我们在分别在orders表和order_details表创建两个聚簇索引,索引按key(customer_id,order_id)拆分。
create clustered index clustered_idx_customer_id on orders(customer_id,order_id);
create clustered index clustered_idx_customer_id on order_details(customer_id,order_id);3.7 索引创建好后,我们看看这个查询语句变成了一条在索引表的一个分片上做下推的join查询,执行效率将得到很大的提高。我们可以看看这个SQL的执行计划。
explain select count(1) from orders a join order_details b on a.order_id=b.order_id and a.customer_id=b.customer_id;
3.8 执行如下SQL语句,查看具体执行时间。
select count(1) from orders a join order_details b on a.order_id=b.order_id and a.customer_id=b.customer_id where a.customer_id=1;返回结果如下,从执行时间看,好像并没有什么改善,为什么呢?

3.9 因为全局索引表是按照customer_id维度拆分的,数据分布很不均匀,我们通过一下SQL看看它的数据分布情况。
select table_group_name,table_name,index_name,partition_name,table_rows,percent from information_schema.table_detail where table_schema='hot_key_test' and table_name = 'orders';
select table_group_name,table_name,index_name,partition_name,table_rows,percent from information_schema.table_detail where table_schema='hot_key_test' and table_name = 'order_details';返回结果如下,可以看到两个索引表的p6和p12都有热点数据。


3.10 我们通过以下SQL查查看这个热点key是多少,
select count(*),customer_id from orders group by customer_id order by count(*) desc limit 10;
select count(*),customer_id from order_details group by customer_id order by count(*) desc limit 10;返回结果如下,可以看到customer_id=88和customer_id=null(匿名用户),符合我们造数据时的要求。

3.11 发现了热点key,我们可以使用PolarDB-X提供的热点散列能力对其打散。
执行如下SQL语句,我们分别对orders、order_details表的索引进行散列。
-- 将customer_id=null的数据按照表的第二个拆分列order_id的hash空间拆分为16个分区
alter table orders.clustered_idx_customer_id split into partitions 16 by hot value (null);
-- 将customer_id=88的数据按照表的第二个拆分列order_id的hash空间拆分为16个分区
alter table orders.clustered_idx_customer_id split into partitions 16 by hot value (88);
-- 将customer_id=88的数据按照表的第二个拆分列order_id的hash空间拆分为16个分区
alter table order_details.clustered_idx_customer_id split into partitions 16 by hot value (88);
-- 将customer_id=null的数据按照表的第二个拆分列order_id的hash空间拆分为15个分区
alter table order_details.clustered_idx_customer_id split into partitions 15 by hot value (null);3.12 散列完成后我们再看看这两个表的数据分布情况,索引表的数据已经很均衡了(由于分区太多,我们只截了关键部分的图)。
select table_group_name,table_name,index_name,partition_name,table_rows,percent from information_schema.table_detail where table_schema='hot_key_test' and table_name = 'orders';
select table_group_name,table_name,index_name,partition_name,table_rows,percent from information_schema.table_detail where table_schema='hot_key_test' and table_name = 'order_details';

3.13 执行如下SQL语句,我们再看看现在这个查询语句的执行计划。
explain select count(1) from orders a join order_details b on a.order_id=b.order_id and a.customer_id=b.customer_id;返回结果如下,可以看到这个sql已经不是一个下推的join,而是一个BKAJoin,效率肯定是没有下推的高。之所以不能下推,是因为这两个索引的表组不一致了,从上面的截图可以看到orders.clustered_idx_customer_id的表组是tg8,order_details.clustered_idx_customer_id的表组是tg7。

4. 变更表组。
4.1 为了让上面的两个索引组织到一个相同的表组中,我们手工创建一个表组tg_idx_customer_id,然后分别将他们通过以下命令绑定到相同的表组。
create tablegroup tg_idx_customer_id;
alter table orders.clustered_idx_customer_id set tablegroup=tg_idx_customer_id;
alter table order_details.clustered_idx_customer_id set tablegroup=tg_idx_customer_id force;4.2 执行如下SQL语句,查看之前的查询语句的执行计划。
explain select count (1) from orders a join order_details b on a.order_id=b.order_id and a.customer_id=b.customer_id;返回结果如下,此时之前的查询语句又可以变成可下推的join查询了。

4.3 执行如下SQL语句,查看查询语句的执行时间。
select count (1) from orders a join order_details b on a.order_id=b.order_id and a.customer_id=b.customer_id;返回结果如下,可以看到执行时间也减少了不少。

点击立即免费试用云产品 开启云上实践之旅!
本文为阿里云原创内容,未经允许不得转载。