背景
索引是数据库的基础组件,早在1970年代,SystemR 就已经通过增加索引来支持多维度查询。单机数据库中,索引主要按照用途和使用的数据结构分为 BTree 索引、Hash 索引、全文索引、空间索引等。通常,每张表中包含一个主键索引(Primary Index),主键索引以外的索引,统称为二级索引(Secondary Index)。
采用存储计算分离和 shared-nothing 架构的分布式数据库具备良好的水平扩展能力,通过数据分区和无状态的计算节点,允许计算和存储独立扩缩容,大量分布式数据库都采用这种架构(Spanner, CockroachDB, YugabyteDB 等)。

全局索引解决什么问题?
shared-nothing 架构引入了 分区 的概念,数据需要按照固定的 分区键 进行切分,这导致包含分区键的查询可以快速定位到一个具体分区,而其它查询需要全分区扫描。这个情况类似单机数据库中按照主键进行查询可以快速定位到数据所在的page,而按照非主键查询需要全表扫描。
与单机数据库不同的是,全分区扫描对于分布式数据库,除了会增加慢查询数量降低系统吞吐,还可能导致系统丧失线性扩展能力。参考下图的例子

扩容前:两个存储节点(Data Node, DN),两个数据分区,假设单个 DN 能承载的物理 QPS 为3,整体物理 QPS 为6,每个查询都是全分区扫描,逻辑 QPS: 6/2=3
扩容后:三个存储节点,三个数据分区,整体物理 QPS 为9,每个查询都是全分区扫描,逻辑 QPS: 9/3=3。机器成本上升50%,查询性能没有任何提升!
单机数据库使用二级索引来避免全表扫描,具体来说,二级索引选择非主键列作为 key,value 部分保存主键的值(也可能是到行记录的引用,具体实现不影响解题思路)。使用二级索引的查询过程变为,首先根据二级索引的索引列定位到page,读取主键的取值,然后返回主键索引查询整行记录(这一步称为回表)。本质上,二级索引通过冗余一份数据的方式,避免了全表扫描,属于系统优化的标准思路“空间换时间”
分布式数据库要消除全分区扫描,也可以采用类似的思路,冗余一份索引数据,索引采用与主表不同的分区键。查询时首先根据索引的分区键定位到一个分区,然后从分区中查到主表的分区键和主键,回表得到完整数据,整个只需要扫描固定数量的分区(比如对于点查,至多扫描两个分区)。
这种与主表分区维度不同的索引,我们称之为全局二级索引(Global Secondary Index, GSI, 也经常简称为全局索引),对应的与主表分区维度相同的索引,称为局部索引(Local Secondary Index,LSI)
为什么一定需要全局索引?
前面一直在说,全分区扫描会导致系统不可扩展,那么如果用户能够严格保证所有 SQL 都包含分区键,是不是就不需要全局索引了?
是的,这种情况确实不需要,但现实情况的复杂性决定了这是小概率事件,更常见的场景是:
● 用户表需要支持用户按照手机号和用户ID登录,分区键选哪个?
● 电商系统,需要按照买家ID和卖家ID查询订单,订单表分区键怎么选?
● 现有业务代码是外包公司写的,大范围修改SQL不现实,怎么办?
更多场景分析可以参考 TPCC与透明分布式,结论:要想提供与单机数据库相似的“透明分布式”使用体验,必须支持全局索引。
用户想要怎样的全局索引使用体验?
单机数据库中索引是非常常用的组件,用户接受度很高,全局索引如果能够做到与单机数据库索引相似的使用体验,就可以称得上是“透明”的索引使用体验。以下从用户使用视角出发,列举四个影响索引使用体验的关键特性
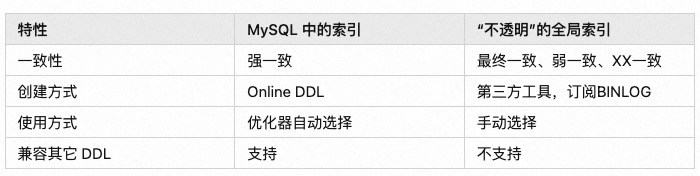
要满足这四个特性并不容易,读、写、schema 变更流程都需要做相应的设计。相关问题大到分布式事务,CBO 索引选择,Asynchronous Online Schema Change 如何实现,小到包括 on update current_timestamp 属性的列如何处理,affected rows 如何兼容 MySQL 行为,都需要考虑,同时还需要保证高性能。
以下介绍 PolarDB-X 在实现兼容 MySQL 索引使用体验的全局二级索引过程中,做出的技术探索。
全局二级索引实现
一致性
对于 OLTP 系统中的全局索引,首先需要保证数据与主表强一致,解决这个问题需要用到分布式事务、逻辑多写和 Asynchronous Online Schema Change (AOSC)。
数据写入的一致性
数据写入时,由于主表和 GSI 的数据可能位于不同分区,需要分布式事务保证原子提交,同时 由于写入存在并发,还需要处理写写冲突。对于没有全局索引的表,可以将 DML 语句路由到数据所在的分区,由 DN 完成并发控制,但对于包含 GSI 的表,更新数据时需要首先读取并锁定要变更的数据,然后按照主键更新主表和索引,这种先读后写的方法称为逻辑多写。

先读后写听上去并不难实现,只是 SELECT + UPDATE/DELETE 而已,但实际情况比想象的要复杂一些。首先,早期 DRDS 的 DML 实现完全依赖下推执行,缺少相应的逻辑计划,MySQL 的 DML 语法大约有 13 种,每种都需要支持,并且对于能够下推的场景,依然保留下推执行方案;其次,MySQL 很多细节行为并没有在官方文档上介绍,需要根据代码逐一适配,比如 类型转化、affected_rows、隐式 default 值等。另外为了支持全局唯一索引,还需要增加冲突检测的流程,导致 INSERT 语句的执行方式又增加了四种。上图展示了逻辑多写的执行流程,详细介绍可以参考源码解读
索引创建的数据一致性
保证数据一致性的第二个方面,是在索引创建过程当中保证数据一致。比如,下面左边这幅图,分布式场景下,多个节点对元数据的感知可能存在时间差。参考图中的情况,一个节点已知存在索引,所以它对索引进行了插入,同时写入主表和索引表。另一个节点并不知道索引的存在,所以它只对主表上的内容进行删除,没有删除索引表上的内容,这就导致索引表上多了一条数据。

PolarDB-X 为了解决这问题,参考 Google F1 的方案,通过引入多个相互兼容的阶段,来保证元数据的过渡是平滑的,详细实现参考这篇文章。同时由于 Schema Change 过程中,切换元数据版本的次数增加,我们也对单个 CN 上的元数据版本演进做了优化,使得 DDL 完全不会影响读写执行,具体参考这篇文章。
引入以上技术之后,我们的整个 DDL 框架就可以对全局索引进行不阻塞的创建了。值的一提的是,MySQL 从 8.0 版本开始支持原子 DDL,这方面 PolarDB-X 也有自己的实现,详见这篇文章
索引扫描的数据一致性
数据写入过程中由于存在并发,需要处理写写冲突,同样的,数据读取过程中由于存在并发读写,还需要处理读写冲突。现代数据库基本都通过 MVCC 来解决读写冲突,查询开始前从发号器获取一个版本号,通过版本号来判断数据行的最新版本是否对当前事务可见,使得读取到的数据满足指定隔离级别。PolarDB-X 支持基于 TSO 的 MVCC 实现,能够保证回表过程中索引表和主表读到相同的快照,MVCC 实现参考这篇文章。
索引选择
索引选择的核心目标是让用户在使用 GSI 的时候不需要手动指定索引,方案是基于 CBO 的自动索引选择,实现上涉及优化器如何评估和选择包含索引扫描 (特指二级索引上的索引扫描,常见名称有 IndexScan,IndexSeek 等,以下统称为 IndexScan)的执行计划。单机数据库的做法是将 TableScan 替换为 IndexScan,如果索引不能覆盖所需的列,则再增加一步回表操作,对 IndexScan 的优化主要是列裁剪和谓词下推,使用独立的算法计算 IndexScan 和回表的代价。

代价评估方面一个比较关键的问题是如何去评估回表的代价,GSI 本身也是一张逻辑表,回表操作相当于索引表和主表在主键上做 Join。因此我们做了工程上的优化,将索引回表的动作适配为 Project 加 Join 的操作,由此可以把整个关于索引的代价评估适配到普通查询计划的代价评估当中。

为了能够将包含 IndexScan 的计划纳入执行计划枚举流程,需要将索引扫描和回表算子适配到现有 CBO 框架。具体实现如上图所示,通过 AccessPathRule 生成使用 GSI 的执行计划,在后续迭代中通过比较代价选出最合适的计划。关于 CBO 框架参考这篇文章。同时,由于分布式数据库中回表需要网络 IO,比单机数据库的回表代价更高,PolarDB-X 还支持将 Join/Limit 等操作提前到回表之前,与索引扫描一起下压到 DN 上执行,达到减少回表的数据量降低网络 IO 的目的,具体参考这篇文章
覆盖索引
覆盖索引是一种特殊的索引,允许用户在索引中保存更多列的数据,目的是满足更多查询语句对引用列的需求,尽量避免回表。单机数据库中覆盖索引是一种常见的优化手段,比如 Sql Server 很早就支持通过覆盖索引优化查询性能。

对于分布式数据库,回表还可能影响系统的水平扩展能力。参考上图的例子,订单表按照 buyer_id 分区,当按照 seller_id 查询时需要全分区扫描。创建一个 seller_id 上的 GSI 来优化,由于索引表默认仅包含分区键、主表分区键和主键,没有 content 列,需要回表。随着卖家销售的订单数量增加,回表操作涉及的分区越来越多,最终也会变成一个全分区扫描,通过增加索引避免全分区扫描的目标并没有实现。为了避免这种情况出现,PolarDB-X 支持创建“覆盖索引”,通过 COVERING 语法在 GSI 中添加指定列,使得 GSI 更容易达到索引覆盖的情况。
除了缺少列,缺少历史版本也可能导致回表,比如 MySQL 没有为二级索引保存版本信息,仅在二级索引每个 page 头部保存了执行最后一次写入的事务id,导致如果需要查询历史版本必须回表。PolarDB-X 在写入过程中为 GSI 单独记录 undo-log,能够读取到索引的历史版本,不会因为查询历史版本而产生额外的回表操作,并且支持将闪回查询(Flashback Query)直接下发到 GSI 上执行。
性能优化
由于写入数据时必须使用分布式事务和逻辑多写,有额外的开销,需要优化写入性能,保证系统吞吐。具体来说,分布式事务依赖两阶段提交保证原子性,相比单机事务增加了 prepare 阶段和写入 commit-point 的步骤,同时依赖 TSO 获取提交时间戳,TSO 服务的吞吐量也可能成为瓶颈。针对分布式事务的优化,包括一阶段提交优化、单机多分区优化、TSO Grouping 等内容,可以参考分布式事务实现和全局时间戳服务设计。
逻辑多写需要先读取数据到 CN,原因有两个,首先 PolarDB-X 兼容 MySQL 的悲观事务行为,写入操作使用当前读,对于 UPDATE、DELETE 等根据谓词确定更新范围的语句,需要先查询并锁定需要修改的数据,避免不同分支事务读取到不一致的快照。其次对于 INSERT 语句,如果目标表上有唯一约束,也需要先读取数据进行唯一约束冲突检测。
单机数据库中也存在类似的流程,比如 MySQL 执行 DML 时先由 server 层从 innodb 中查询并锁定需要修改的数据,然后调用 ha_innobase::write_row 写入数据,MySQL 的唯一约束实现也要求 INSERT 前先做唯一约束检查。区别在于 MySQL server 层和 innodb 层的交互发生在单台机器内,只涉及内存和磁盘IO,代价较低,分布式数据库中 CN 和 DN 通过网络机交互,代价更高。

PolarDB-X 执行 DML 时,优先选择下推执行,对于必须使用逻辑多写的场景,针对“查询并锁定需要修改的数据”和“唯一约束冲突检测”分别进行了工程优化
● 读写并行:思路很简单,将“读取-缓存-写入”的串行执行过程转变为多个小批次的并行的“读取“和”写入”过程。要解决的一个关键问题是,MySQL 的事务与连接是绑定的,事务内如果创建多个读连接,会出现数据可见性问题。为了解决这个问题,我们引入了事务组的概念,使得多个连接可以共享相同的 ReadView,由此来解决事务内读写连接绑定的问题,使得不同批次的读取和写入可以并行执行。
● 唯一约束冲突检测下推:主要解决数据导入场景下的性能问题,数据导入为了做断点续传,通常会使用 INSERT IGNORE 这样的语句,但实际上插入的数据几乎都是没有冲突的,于是每条数据都做冲突检测就显得很不划算。我们优化的方法是采用乐观处理的思路,通过 RETURNING 语句 加补偿的方式。使得数据导入场景下,INSERT IGNORE 的性能与 INSERT 相同。
DDL 兼容性
良好的 DDL 兼容性是“透明”全局索引必须要关注的部分。试想一下,如果每次修改列类型之前,都需要先删除引用这一列的全局索引,类型变更完成后在重建索引,是多么令人“头大”的事情。PolarDB-X 全面兼容 MySQL DDL 语句,表、列、分区变更相关的语句都会自动维护 GSI。DDL 执行算法分为 Instant DDL 和 Online DDL 两种,Instant DDL 主要用于加列,Online DDL 基于 AOSC,针对不同 DDL 语句有细化设计,下面简单介绍比较有代表性的 ADD COLUMN 和 CHANGE COLUMN 的实现
ADD COLUMN
PolarDB-X 支持全局聚簇索引(Clustered Secondary Index, CSI),特点是始终保持与主表相同的结构,保证对所有查询都不需要回表。因此,主表加列时需要在 CSI 上也增加一列,一般情况下按照 AOSC 流程完成就可以保证加列过程中索引数据一致,但如果新增列包含了 ON UPDATE CURRENT_TIMESTAMP 属性,则可能产生问题。比如下面的场景,物理表加列完成,但 CN 还不知道新增列的存在,于是由 DN 独立填充主表和索引表中的值,导致数据不一致。为了解决这个问题,我们会在所有 CN 都感知到元数据更新后,使用回填流程重新刷新一遍索引上新增列的值,保证索引与主表数据一致。
CHANGE COLUMN
变更列类型是 DDL 中最复杂的操作,对写入有比较大的影响,比如 MySQL 8.0 在变更列类型过程中依然需要锁表。PolarDB-X 支持 Online Modify Column(OMC),通过“加列-复制数据-修改元数据映射”的方式,结合 Instant Add Column,实现支持 GSI 的不锁表列类型变更。

上图展示了在一张没有 GSI 的表上执行 CHANGE COLUMN 的过程。分为七个阶段,首先增加一个对用户不可见的 COL_B,在写入过程中使用相同的值填充 COL_A 和 COL_B,然后对表中已有的数据用 COL_A 的值回填到 COL_B,最后交换 COL_A 和 COL_B 的元数据映射,并删除 COL_A,完成列类型变更。存在 GSI 的场景也采用相同的流程,只是在每个步骤中都对 GSI 做相同处理。
DDL 兼容性使用的底层技术与创建 GSI 相同(AOSC、数据回填、逻辑多写、异步DDL引擎等),但实现上需要考虑每种 DDL 语句的语义,还需要考虑 MySQL 的细节行为,比如变更列类型中通过 UPDATE 语句在新老列之间回填数据,但 MySQL ALTER TABLE 和 UPDATE 的类型转换逻辑并不相同,为此我们实现了专门的类型转换逻辑在 UPDATE 中模拟 ALTER TABLE 的行为。总的来说,DDL 兼容性看起来只是支持了一些语法,但里面的工作量其实是很大的。
性能测试
全局索引对读写性能的影响,与具体业务场景有比较大关系,本质上是牺牲一部分写入性能换取读性能的大幅提升,下图以 Sysbench 场景为例,展示该场景下 GSI 对读写吞吐的影响。


总结
基于存储计算分离和 shared-nothing 架构的分布式数据库,需要支持全局二级索引来消除全分区扫描,保证线性可扩展性。单机数据库很早就引入了二级索引,使用体验用户接受度很高,良好的全局索引使用体验应该向单机数据库看齐,需要保证数据强一致,支持通过 DDL 语句创建,支持自动选择索引,同时索引的存在不应当阻碍其他 DDL 语句执行。PolarDB-X 通过分布式事务和逻辑多写保证索引数据强一致;支持 Online Schema Change,索引创建过程可以与写入并行;支持覆盖索引,解决回表带来的全分区扫描问题;精细化处理了包含 GSI 表的 DDL 语句兼容性。为用户提供”透明“的索引使用体验,降低分布式数据库的使用门槛。
作者:墨城
本文为阿里云原创内容,未经允许不得转载