目录
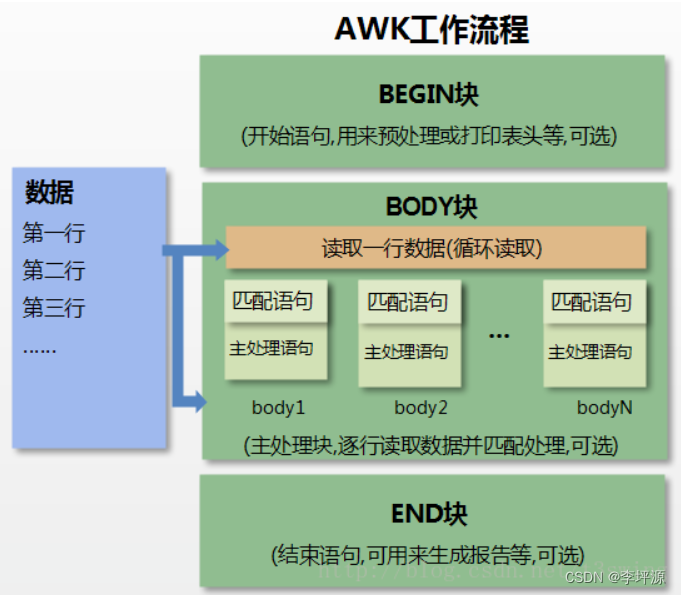
1.awk的工作流程
AWK 工作流程可分为三个部分:
- 读输入文件之前执行的代码段(由BEGIN关键字标识)。
- 主循环执行输入文件的代码段。
- 读输入文件之后的代码段(由END关键字标识)。
2.awk程序的执行方式
1)
.通过命令行执行
awk
程序,语法如下:
awk 'program-text' datafile
2)
.执行
awk
脚本
在awk
程序语句比较多的情况下,用户可以将所有的语句写在一个脚本文件中,然后通过
awk
命令来解 释并执行其中的语句。awk
调用脚本的语法如下:
awk -f program-file file ..
在上面的语法中,-f
选项表示从脚本文件中读取
awk
程序语句,
program-file
表示
awk
脚本文件名称,
file 表示要处理的数据文件。
3)
.可执行脚本文件
在上面介绍的两种方式中,用户都需要输入awk
命令才能执行程序。除此之外,用户还可以通过类似于 Shell脚本的方式来执行
awk
程序。在这种方式中,需要在
awk
程序中指定命令解释器,并且赋予脚本文 件的可执行权限。其中指定命令解释器的语法如下:
#!/bin/awk -f
以上语句必须位于脚本文件的第一行。然后用户就可以通过以下命令执行awk
程序:
awk-script file
其中,awk-script
为
awk
脚本文件名称,
file
为要处理的文本数据文件。
3.awk打印一个内容和打印多个内容
格式化输出:显示Hello World字符串且宽度为50,向左对齐
[root@localhost test]# echo "hello world"|awk -F "\n" '{printf "%-50s\n", $1}'
-F "指定分割符"
%s: 显示字符
+ 左对齐
- 右对齐
number 宽度
4.awk中所有内置变量的使用,以及自定义变量并使用

[root@localhost test]# echo "a b c"|awk '{print $0}'
a b c
[root@localhost test]# echo "a b c"|awk '{print $1,$3}'
a c
[root@localhost test]# echo "a b c"|awk '{print NF}'
3
[root@localhost test]# cat file.text
hello beijing
hello tianjing
hello hebei
export TERM=xterm
[root@localhost test]# awk '{print NR}' file.text
1
2
3
4
[root@localhost test]# awk '{print NR}' file.text file_test
1
2
3
4
5
6
7
8
9
10
11
12
13
14
[root@localhost test]# awk '{print FNR}' file.text file_test
1
2
3
4
1
2
3
4
5
6
7
8
9
10[root@localhost test]# awk '{print FILENAME}' file.text
file.text
file.text
file.text
file.text
[root@localhost test]# echo "a b:c d-e:f"|awk -F ":" '{print $1}'
a b
[root@localhost test]# echo "a b:c d-e:f"|awk -F ":" '{print $2}'
c d-e[root@localhost test]# echo "a b:c d-e:f"|awk -F ":" 'BEGIN{OFS="#"}{print $1,$2,$3}'
a b#c d-e#f[root@localhost test]# echo "a b:c d-e:f"|awk -F ":" 'BEGIN{RS="-"}{print $1,$2,$3}'
a b c d
e f
[root@localhost test]# awk '{print ENVIRON["PATH"]}' file.text
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
5.awk执行数学计算:
10/2*3+5%2+2^3
[root@localhost test]# awk '{print 10/2*3+5%2+2^3}'
24
awk处理文本:要求文本有5行内容,且当行数为奇数的时候打印第一个字段
[root@localhost test]# vim dispose_text.sh
{
m=NR
if ( m%2 == 1 ){
print $1
}
}
[root@localhost test]# ./dispose_text.sh file.text
hello
hello
this
awk处理文本: 要求文本有5行内容, 当行数不为3时打印第一个字段
[root@localhost test]# vim dispose_text.sh
{
m=NR
if ( m != 3 ){
print $1
}
}
[root@localhost test]# ./dispose_text.sh file.text
hello
hello
export
this
awk处理文本:文本内容为ls -l /root的内容,匹配所有的普通文件的文件名
[root@localhost test]# ls -l /root|awk '{++f[$NF]}{for(i in f);j=i+1;print "test -f /root/$j"|"bash"}'
6.awk的模式的使用:
每个模式下加样例
BEGIN
模式
BEGIN
模式是一种特殊的内置模式,其成立的时机为
awk
程序刚开始执行,但是又尚未读取任何数据之 前。因此,该模式所对应的操作仅仅被执行一次,当awk
读取数据之后,
BEGIN
模式便不再成立。所 以,用户可以将与数据文件无关,而且在整个程序的生命周期中,只需执行1
次的代码放在
BEGIN
模式对应的操作中。
[root@localhost test]# awk 'BEGIN{print}' result
[root@localhost test]# awk '{print}' result
result
[root@localhost test]# awk 'BEGIN{k=4}{print k}' result
4
END模式
END
模式是
awk
的另外一种特殊模式,该模式成立的时机与
BEGIN
模式恰好相反,它是在
awk
命令处理 完所有的数据,即将退出程序时成立,在此之前,END
模式并不成立。无论数据文件中包含多少行数据,在整个程序的生命周期中,该模式所对应的操作只被执行1
次。因此,一般情况下,用户可以将许多善后工作放在END
模式对应的操作中。
[root@localhost test]# awk '{k=1}END{print k;k=3}{print k}' result
1
1BEGINFILE
ENDFILE
/regular expression/
正则表达式
awk
支持以正则表达式作为匹配模式,与
sed
一样,用户需要将正则表达式放在两条斜线之间,其基本语 法如下:/regular_expression/
[root@localhost test]# awk '/^hello/ {print}' test_text
hello china 1
hello chongqing 2
hello shaanxixian 3
hello guandong 4 hello
hello zhejiang 5
relational expression
关系表达式
awk
提供了许多关系运算符,例如大于>、小于<或者等于
==
等。
awk
允许用户使用关系表达式作为匹 配模式,当某个文本行满足关系表达式时,将会执行相应的操作。
[root@localhost test]# awk '$1 >= 70 {print}' number.text
70
88
101pattern && pattern
[root@localhost test]# awk '/^zhangsan/ && $2>= 70 {print}' name_grad.text
zhangsan 71pattern || pattern
[root@localhost test]# awk '/^zhangsan/ || $2>= 70 {print}' name_grad.text
zhangsan 66
wangwu 90
zhangsan 71
lisi 98
wangwu 88
pattern ? pattern : pattern
[root@localhost test]# awk '2>1?/^zhangsan/:/^lisi/ {print}' name_grad.text
zhangsan 66
zhangsan 71
[root@localhost test]# awk '2<1?/^zhangsan/:/^lisi/ {print}' name_grad.text
lisi 55
lisi 98
(pattern)
[root@localhost test]# awk '(/^zhangsan/) {print}' name_grad.text
zhangsan 66
zhangsan 71
[root@localhost test]# awk '(/88/) {print}' name_grad.text
wangwu 88
! pattern
[root@localhost test]# awk '!/^zhangsan/ {print}' name_grad.text
lisi 55
wangwu 90
lisi 98
wangwu 88pattern1, pattern2
区间模式
awk
还支持一种区间模式,也就是说通过模式可以匹配一段连续的文本行。区间模式的语法如下:
pattern1, pattern2
其中,
pattern1
和
pattern2
都是前面所讲的匹配模式,可以是关系表达式,也可以是正则表达式等。当然,也可以是这些模式的混合形式。
[root@localhost test]# more name_grad.text
zhangsan 66
lisi 55
wangwu 90
zhangsan 71
lisi 98
wangwu 88
[root@localhost test]# awk '/^zhangsan/ {print}' name_grad.text
zhangsan 66
zhangsan 71
[root@localhost test]# awk '/^zhangsan/,/^lisi/ {print}' name_grad.text
zhangsan 66
lisi 55
zhangsan 71
lisi 98
7. awk中控制语句
if: 给定一个成绩0-100,输出等级: A:85-100, B:70-84, C:60-69, D:0-59
[root@localhost test]# vim compute.sh
{
if ( $1 >= 85) {
print "your grades are:A"
}
else{
if ( $1 >= 70 ) {
print "your grades are:B"
}
else {
if ( $1 >=60 ) {
print "your grades are:C"
}
else {
print "your grades are:D"
}
}
}
}
[root@localhost test]# ./compute.sh number.text
your grades are:D
your grades are:C
your grades are:B
your grades are:A
your grades are:A
for(): 计算1+2...+100的和
[root@localhost test]# vim for_accumulate.sh
{
for (i=1;i<=100;i++)
{
result=result+i
}
print result
}
[root@localhost test]# ./for_accumulate.sh
5050
for(in): 定义一个数组:数组中的元素为: array[name]=age,-> zhangsan:18 lisi:20 wangwu=21
循环访问数组,并输出数组中的key和value
[root@localhost test]# vim array.sh
{
array["zhangsan"]=18
array["lisi"]=20
array["wangwu"]=21
for (i in array) {
print i,array[i]
}
}
[root@localhost test]# ./array.sh result
zhangsan 18
wangwu 21
lisi 20
用while和do...while实现9*9乘法表
[root@localhost test]# vim while_9x9.sh
{
i=1
while (i<=9)
{
j=1
while (j<=i)
{
printf "%-8s", i"*"j"=" i*j
j++
}
i++
print " "
}
[root@localhost test]# ./while_9x9.sh result
1*1=1
2*1=2 2*2=4
3*1=3 3*2=6 3*3=9
4*1=4 4*2=8 4*3=12 4*4=16
5*1=5 5*2=10 5*3=15 5*4=20 5*5=25
6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36
7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49
8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64
9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81
8.awk中内置函数的使用:
substr
substr(string, start [, length])
功能:取
string
字符串中的子串,从
start
开始,取
length
个;
start
从
1
开始计数;
[root@localhost test]# awk '{print substr("abcdef",2,3)}' result
bcd
tolower
tolower(s)
功能:将
s
中的所有字母转为小写
[root@localhost test]# awk '{print tolower("WWw.HAha.Com")}' result
www.haha.cotoupper
toupper(s)
功能:将
s
中的所有字母转为大写
[root@localhost test]# awk '{print toupper("WWw.HAha.Com")}' result
WWW.HAHA.COM
system
system(command)
功能:执行系统
command
并将结果返回至
awk
命令
[root@localhost test]# awk '{print system(hostname)}' result
0
[root@localhost test]# awk '{print system($PATH)}' result
sh: result: command not found
127
game over