一、操作数据库的基本语句
cmd进入mysql:mysql -uroot -p
创建数据库:CREATE DATABASE 库名;
创建数据表:同sqlite;
查看数据库:SHOW DATABASES;
查看数据表:SHOW TABLES;
进入数据库:USE 库名;
查看库创建语句:SHOW CREATE DATABASE 库名;
查看表创建语句:SHOW CREATE TABLE 表名;
查看表结构:SHOW COLUMNS FROM 表名;或DESC 表名
记录的增删查改与sqlite一样。数据类型不再赘述。
二、约束和修改数据库结构
2.1 约束
非空约束:NOT NULL
主键约束:PRIMARY KEY(一个表中只能有一个)
唯一约束:UNIQUE KEY
默认约束:DEFAULT
检查约束:CHECK(用的较少)
外键约束:FOREIGN KEY
/*外键约束,格式:FOREIGN KEY REFERENCES 关联的表名(字段名),注意如下几点:
1.参考段需有索引,provinces的id字段为主键约束,自动有索引
2.外键段pid不创建索引,系统也会自动添加索引
3.参考段若为整型,那么整型类型,有无符号均要一样。若为字符型则无要求
*/
CREATE TABLE users1 (id SMALLINT PRIMARY KEY AUTO INCREMENT,pid INT FOREIGN KEY REFERENCES provinces(id))
注:外键约束只有在数据库引擎为InnoDB时有效!!!
2.2修改数据库结构语句
2.2.1 表字段
添加字段:ALTER TABLE users2 ADD id SMALLINT UNSIGNED;
删除字段:ALTER TABLE users2 DROP id ;
要批量操作则在末尾加上“,DROP col_name…”
添加字段到某指定位置:ALTER TABLE users2 ADD id SMALLINT UNSIGNED AFTER 列名(或FIRST,插到开头);
2.2.2 约束
添加主键约束:ALTER TABLE users2 ADD CONSTRAINT PK_users2_id PRIMARY KEY(id);
添加唯一约束:ALTER TABLE users2 ADD UNIQUE (username);
添加外键约束: ALTER TABLE users2 ADD FOREIGN KEY (pid) REFERENCES provinces(id);
添加删除默认约束: ALTER TABLE users2 ALTER age SET DEFAULT 15; ALTER TABLE users2 ALTER age DROP DEFAULT;
删除主键约束: ALTER TABLE users2 DROP PRIMARY KEY;
删除唯一约束:ALTER TABLE users2 DROP INDEX(KEY) index_name;
删除外键约束:ALTER TABLE users2 DROP FOREIGN KEY users2_ibfk_1;
2.2.3 列
修改列定义:ALTER TABLE tab_name MODIFY [COLUMN] col_name column_definition [FIRST|AFTER col_name];
举例: ALTER TABLE users2 MODIFY id SMALLINT UNSIGNED NOT NULL FIRST;(此时可对数据类型修改,由大范围变小会导致某些数据丢失)
修改列名称:ALTER TABLE tab_name CHANGE [COLUMN] old_col_name new_col_name column_definition [FIRST|AFTER col_name];
2.2.4 修改表名
(1)ALTER TABLE tab_name RENAME [AS|TO] new_tab_name(单次更名)
(2)RENAME TABLE tab_name TO new_tab_name[,tab_name2 TO new_tab_name2…];(批量更名)
注意:列名,表名可能被其他引用或创建了索引,改名后可能会导致视图,存储过程无法正常工作,慎用!!!
三、记录操作
INSERT:
- INSERT [INTO] tab_name [(col_name,…)] {VALUES|VALUE} ({expr|DEFAULT},…),(…),…(插入一条数据)
- INSERT [INTO] tab_name SET col_name={expr|DEFAULT},…(插入某字段数据)
- INSERT [INTO] tab_name [(col_name,…)] SELECT…(从其他表选取记录添加)
UPDATE
- 单表更新
UPDATE [LOW_PRIORITY] [IGNORE] table_references SET col_name1={expr|DEFAULT} [,col_name2={expr|DEFAULT} ]…WHERE where_condition - 多表更新,详见下节
DELETE
- 单表删除
DELETE FROM tab_name [WHERE where_condition] - 多表删除,详见下节
SELECT
- SELECT select_expr [,select_expr]
[
FROM table_references
[WHERE where_condition]
[GROUP BY {col_name|position} [ASC|DESC],…]
[HAVING where_condition]
[ORDER BY {col_name|position|expr} [ASC|DESC],…]
[LIMIT {[offset,] row_count|row_count OFFSET offset}]
]
四、子查询与连接
4.1子查询简介
子查询是指出现在其他SQL语句中的SELECT 子句。
例如:SELECT * FROM t1 WHERE col1=(SELECT col2 FROM t2);其中SELECT * FROM t1称为Outer Query/Outer Statement,SELECT col2 FROM t2称为子查询;
- 子查询嵌套在查询内部,且必须始终存在于圆括号内()
- 子查询可包括多个关键字或条件,如DISTINCT,GROUP BY,ORDER BY,LIMIT,函数等。
- 子查询的外层查询可以是:SELECT,INSERT,UPDATE,DELETE,SET或DO
- 子查询可以返回标量,一行,一列,或子查询
4.2 使用子查询
4.2.1 使用比较符 = ,>,<,>=,<=,!=,<>,<=>
如: SELECT * FROM tdb_goods WHERE goods_price>=(SELECT ROUND(AVG(goods_price),2) FROM tdb_goods);
4.2.2用ANY,SOME,ALL修饰比较符,用于比较子查询返回的多条数据时,ANY与SOME等价,只要满足一条数据,ALL要满足所有数据。
如:SELECT goods_name FROM tdb_goods WHERE goods_price >= ALL(SELECT goods_price FROM tdb_goods WHERE goods_cate =’超极本’);
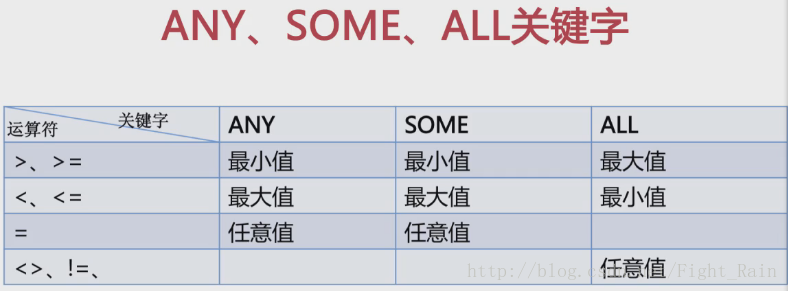
4.2.3使用[NOT] IN的子查询
=ANY与IN等价
!=ALL或<>ALL与NOT IN等价
4.2.4 将查询结果写入数据表
INSERT [INTO] tab_name [(col_name,…)] SELECT…
如: INSERT tdb_goods_cates(cate_name) SELECT goods_cate FROM tdb_goods GROUPBY goods_cate;
4.3多表更新
UPDATE table-references SET col_name1={expr1|DEFAULT}[,col_name2={expr2|DEFAULT}]…[WHERE where_condition]
4.4多表更新之一步更新(将创建表,查询结果写入新建表,多表更新合成一步)
第一步,第二步合为一步:
CREATE TABLE [IF NOT EXISTS] tab_name[(create_definition,…)] select_statement
如:
CREATE TABLE tdb_goods_brands (brand_id SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT,brand_name VARCHAR(40) NOT NULL)
SELECT brand_name FROM tdb_goods GROUP BY brand_name;第三步:
UPDATE tdb_goods AS g INNER JOIN tdb_goods_brands AS b ON g.brand_name = b.brand_name
SET g.brand_name = b.brand_id;(由于两表有同名字段brand_name,不能像之前那样直接=)
4.3连接
table_references{[INNER|CROSS]JOIN|{LEFT|RIGHT[OUTER]JOIN}table_references ON conditional_expr
当conditional_expr中两表比较的字段重名,则可设别名
(1)table_references tab_name [[AS] alias]|table_subquery [AS] alias
数据表可以使用tab_name AS alias_name或tab_name alias_name赋予别名,见上
(2)table_subquery可以作为子查询使用在FORM字句中,这样的子查询必须为其赋予
连接分为:
(1)内连接,显示左右表符合连接条件的记录
(2)左连接,显示左表全部记录和右表符合连接条件的记录
(3)右连接,显示右表全部记录和左表符合连接条件的记录
多表连接
如:SELECT goods_id,goods_name,cate_name,brand_name,goods_price FROM tdb_goods AS g INNER JOIN tdb_goods_cates AS c ON g.cate_id=c.cate_id INNER JOIN tdb_goods_brands AS b ON g.brand_id=b.brand_id;
关于连接的几点说明:
• A LEFT JOIN B join_condition
- 数据表B的结果集依赖数据表A。
- 数据表A的结果集根据左连接条件依赖所有数据表(B表除外)。
- 左外连接条件决定如何检索数据表B(在没有指定WHERE条件的情况下)
- 如果数据表A的某条记录符合WHERE条件,但是在数据表B不存在符合连接条件的记录,将生成一个所有列为空的额外的B行。
• 如果使用内连接查找的记录在连接数据表中部存在,并且在WHERE子句中尝试一下操作:col_name IS NULL时,如果col_name被定义为NOT NULL,MySQL将在找到符合连接条件的记录后停止搜索更多的行。
4.4无限极分类表设计
(1)无限分类的数据表设计
CREATE TABLE tdb_goods_types(type_id SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT,type_name VARCHAR(20) NOT NULL, parent_id SMALLINT UNSIGNED NOT NULL DEFAULT 0);
插入数据后:
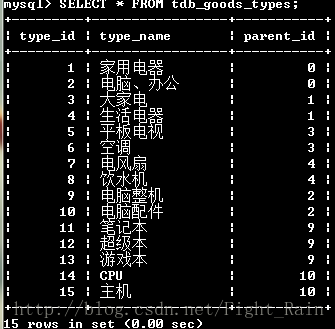
(2)查找所有分类及其父类
SELECT s.type_id,s.type_name,p.type_name
FROM tdb_goods_types
AS s LEFT JOIN tdb_goods_types AS p
ON s.parent_id = p.type_id;s.parent_id = p.type_id的顺序可变,LEFT JOIN左右顺序绝对不能变,表示显示哪张表的全部,要显示全的字段用左表.xx
4.5多表删除
删除重复数据中id较大的
DELETE t1 FROM tdb_goods
AS t1 LEFT JOIN (SELECT goods_id,goods_name FROM tdb_goods GROUP BY goods_name HAVING count(goods_name) >= 2 )
AS t2 ON t1.goods_name = t2.goods_name
WHERE t1.goods_id > t2.goods_id;五、运算符和函数
由于做过纸质笔记,暂时不再介绍,可直接百度
自定义函数的必要条件:
1.参数
2.返回值
函数都有返回值,不一定有参数
基本语句:
CREATE FUNCTION function_name RETURNS {STRING|INTEGER|REAL|DECIMAL} routine_body
routine_body——>函数体
- 函数体由合法的sql语句组成
- 函数体可以是简单的SELECT或INSERT语句
- 函数体如果为复合结构则使用BEGIN…END语句
复合结构可以包括声明,循环,控制结构
如:CREATE FUNCTION f1() RETURNS VARCHAR(30) RETURN DATE_FORMAT(NOW(),’%Y年%m月%d日%H点:%i分:%s秒’);
为什么我直接SELECT DATE_FORMAT(…)返回正确,SELECT f1()返回结果里:和中文变成了?号 视频里f1()返回正确!!!创建具有复合结构函数体的函数(以插入数据为例)
错误示范:
CREATE FUNCTION adduser(username VARCHAR(20)) RETURNS INT UNSIGNED RETURN INSERT test(username) VALUES(username);
因为insert返回的结果根本不是int型
正确示范:
1.DELIMITER // (修改分隔符;为//,其他均可)
2.把LAST_INSERT_ID()作为返回值
3.由于此时有insert语句和LAST_INSERT_ID()函数,需要用复合结构
4.最终语句如下:
CREATE FUNCTION adduser(username VARCHAR(20))
RETURNS INT UNSIGNED
BEGIN
INSERT test(username) VALUES(username) ;
RETURN LAST_INSERT_ID() ;
END //
**ps:注意这两个;号,缺一不可,且只能用;号**删除自定义函数
DROP FUNCTION [IF_EXISTS] fun_name
六、MySQL存储过程
6.1 什么是存储过程和如何创建
SQL命令执行流程:
SQL指令——>MySQL引擎_分析_>语法正确——>可识别命令_执行_>执行结果_返回_>客户端
Mysql储存过程是一组为了完成特定功能的SQL语句集,经过编译之后存储在数据库中,当需要使用该组SQL语句时用户只需要通过指定储存过程的名字并给定参数就可以调用执行它,从而省去分析语法等步骤,提高效率
语句:
CREATE [DEFINER={user|CURRENT_USER}]
PROCEDURE sp_name([proc_parameter[,…]])
[characteristic…]routine_body
其中proc_parameter–>[IN|OUT|INOUT] param_name type
IN,表示该参数的值必须在调用存储过程时指定
OUT,表示该参数的值可以被存储过程改变,并且可以返回
INOUT,表示该参数的值在调用存储过程时指定,并且可以被改变和返回
过程体:
- 过程体由合法的SQL语句构成
- 过程体可以是任意增删改查,多表连接等SQL语句
- 过程体如果为复合结构则使用BEGIN…END语句
- 过程体可以包括声明,循环,控制结构
举例:
创建存储过程:
CREATE PROCEDURE spl() SELECT VERSION();
使用:
CALL spl;或者CALL spl();(由于创建的时候没有指定参数,所以两种方法均可,如果指定了参数,必须第二种)
6.2创建带有IN类型参数的存储过程
DELIMITER //
CREATE PROCEDURE removeUserById(IN id INT UNSIGNED)
BEGIN
DELETE FROM users WHERE id=id;
END//
CALL removeUserById(1);注意:我们的本意是删除users表中id=1的记录,但结果是记录全被删除,这是因为我们设置的参数和id字段重名,在WHERE语句中,左边id是字段名,右边id是条数,但系统会误认为两边id都是字段名!!!
修改:
(1) DROP PROCEDURE removeUserById;(删除存储过程)
(2)重复上面操作,修改参数名不为id即可
6.3创建带有IN,OUT类型参数的存储过程
由于要用到MySQL变量,做下简单介绍:
mysql变量的术语分类:
1.用户变量:以”@”开始,形式为”@变量名”
用户变量跟mysql客户端是绑定的,设置的变量,只对当前用户使用的客户端生效
2.全局变量:定义时,以如下两种形式出现,set GLOBAL 变量名 或者 set @@global.变量名
对所有客户端生效。只有具有super权限才可以设置全局变量
3.会话变量:只对连接的客户端有效。
4.局部变量:作用范围在begin到end语句块之间。在该语句块里设置的变量
declare语句专门用于定义局部变量。set语句是设置不同类型的变量,包括会话变量和全局变量
CREATE PROCEDURE p8 ()
BEGIN
DECLARE a INT;
DECLARE b INT;
SET a = 5;
SET b = 5;
INSERT INTO t VALUES (a);
SELECT s1 * a FROM t WHERE s1 >= b;
END; //以创建删除指定行数,返回剩余行数的存储过程为例:
CREATE PROCEDURE removeUserAndReturnUserNums(IN p_id INT UNSIGNED,OUT userNum INT UNSIGNED)
BEGIN
DELETE FROM users WHERE _id=p_id;
SELECT count(_id) FROM users INTO userNum;
END//
CALL removeUserAndReturnUserNums(1,@nums);
SELECT @nums;
6.4创建带有多个OUT类型参数的存储过程
用到ROW_COUNT()函数,返回上一操作影响的记录条数
以创建删除指定记录,并返回删除记录数和剩余记录数的存储过程为例
DELIMITER //
CREATE PROCEDURE removeUserByNameAndReturnInfos(IN p_name VARCHAR(10) ,OUT deleteUsers SMALLINT UNSIGNED,OUT userCounts SMALLINT UNSIGNED)
BEGIN
DELETE FROM test WHERE username=p_name;
SELECT ROW_COUNT() INTO deleteUsers;
SELECT COUNT(id) FROM test INTO userCounts;
END
//
DELIMITER ;
CALL removeUserByNameAndReturnInfos('a',@a,@b);
SELECT @a,@b;
+------+------+
| @a | @b |
+------+------+
| 1 | 7 |
+------+------+
//表中有8条记录,只有1条username=a6.5存储过程与自定义函数的区别
- 存储过程实现的功能要复杂一些,而函数的针对性更强
- 存储过程可以返回多个值,函数只能有一个返回值
- 存储过程一般独立的来执行,而函数可以作为其他SQL语句的组成部分出现
实际开发中函数用的比较少,存储过程用的更多
七、MySQL存储引擎
MySQL可以将数据以不同的技术存储在文件(内存)中,这种技术称为存储引擎。
每一种存储引擎使用不同的存储机制、索引技巧、锁定水平,最终提供广泛且不同的功能。
先介绍几个名词:
- 并发控制
当多个连接对记录进行修改时保证数据的一致性和完整性 - 锁(类似Java里的锁,可以对某张表,某条记录加锁)
共享锁(读锁):在同一时间段内,多个用户可以读取同一个资源,读取过程中数据不会发生任何变化
排他锁(写锁):在任何时候只能有一个用户写入资源,当进行写锁时会阻塞其他的读锁或者写锁操作 - 锁颗粒
表锁,是一种开销最小的锁策略,一个表只有一个
行锁,是一种开销最大的锁策略,一个表可以有多个甚至每行一个锁 - 事务
事务用于保证数据库的完整性 - 事务特性
原子性
一致性
隔离性
持久性 - 外键
是保证数据一致性的策略 - 索引
是对数据表中一列或多列的值进行排序的一种结构
MySQL支持的存储引擎:
- MyISAM
- InnoDB
- Memory
- CSV
- Archive
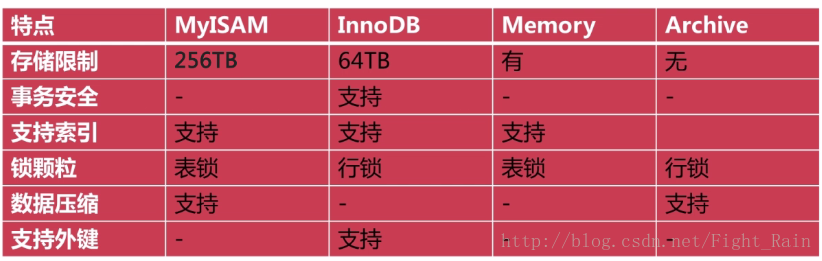
修改存储引擎的方法
通过修改mysql配置文件实现,5.5以上默认InnoDB
-default-storage-engine=engine通过创建数据表命令实现
-CREATE TABLE table_name(
…
)ENGINE=engine;- 通过修改数据表命令实现
-ALTER TABLE table_name ENGINE[=] engine_name;
八、MySQL图形化管理工具
由于数据库实战里用到Navicat,具体操作还请自行百度