引言
关于MYSQL的索引结构为何为B+树而不是B树(B-树也成为B树)这个问题,面试过程中可能会经常被问到,因此我在这里总结一下,出一篇博客,希望看到这篇博客的人在面试中遇到这个问题可以很好的回答.
一 B树的定义
对于一棵m阶的B树,定义如下:
- 每个节点最多只有m个子节点。
- 除根节点外,每个非叶子节点具有至少有 m/2(向下取整)个子节点。
- 非叶子节点的根节点至少有两个子节点。
- 有k颗子树的非叶节点有k-1个键,键按照递增顺序排列。
- 叶节点都在同一层中。

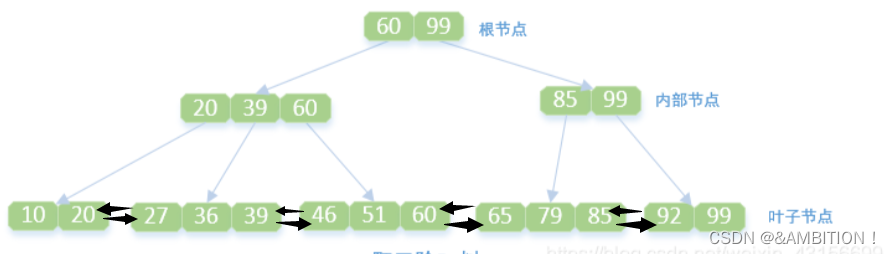
二 B+树的定义
对于一棵m阶的B+树,定义如下:
- 每个节点最多只有m个子节点。
- 除根节点外,每个非叶子节点具有至少有 m/2(向下取整)个子节点。
- 非叶子节点的根节点至少有两个子节点。
- 有k颗子树的非叶节点有k个键,键按照递增顺序排列。
- 叶节点都在同一层中,且叶子节点通过链表连接起来.(可以是双向也可以是单向)
- 非叶子节点不保存数据,只保存索引值,所有数据均由叶子节点保存
- 所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
三 采用B+树的原因
1. 一个节点可以保存更多的key,最终可以使得树的高度相对更矮,查询的时候减少了硬盘IO的访问次数,提高了效率.(这里B和B+树是一样的)
2. B+树的非叶子结点不保存数据,只保存索引,这就是使得以B+树为存储结构的数据的非叶子结点的空间被极大的缩小了.这也就可以在数据库查询数据的时候,可以将这些索引部分或者全部加载到内存中,而不是在硬盘上进行查询,即将大量的硬盘IO转化为内存IO操作,同时CPU读内存的速度要比读硬盘最少快几千倍,因此这就可以极大的提高访问速度,进而提高数据库运行的效率.
假如有10亿条数据,若以整形 int 作为索引,其索引也仅仅只有将近4G,而若以B树那样的存储结构,这10亿条数据很难一下加载到内存中.
3. MYSQL中范围查询是一个比较常用的操作,而B+树的所有数据均存储在叶子节点上,且MYSQL中的B+树叶子节点通过双向链表来连接,因此在进行范围查询的时候只需要查两个端点的节点,再进行遍历即可.即B+树在范围查询上效率很高.而B树想要进行范围查询,就需要一直遍历这个数,效率相较于B+树还差很多.
4. 在数据检索方面,由于B+树的所有数据均存储在叶子节点上,因此在B+树的查询任何一条数据,IO次数都是一样的; 相反B树的则不稳定,因为我们存放数据的节点的深度是不固定的.(不要小看这个稳定性,对于一个程序来说,稳定性是至关重要的)
5. 因为B+树的叶子节点存储所有的数据,因此B+树的全局扫描能力更强一些,因为它只需要扫描叶子结点即可,但是B树却需要遍历整个树才可以做到全局扫描.
四 总结
总的来说,技术方案的选择是为了解决当前场景下的特定问题,并不一定所对于所有的数据库来说B+树都是最好的选择,就像非关系型数据库多采用B树作为存储数据的结构,而像MYSQL这样的关系型数据库更多的是采用B+树.
如果本篇博客对您有帮助,也请你帮博主点赞收藏一下,非常感谢!