多处理器编程,本质上,就是把MR给每个处理器复制一份
每个处理器拿到MR,形成了自己的缓存内存空间,然后再在运行期间把运算结果写入共享内存

把i++做成一条指令
使用asm嵌入汇编,向sum的寄存器直接写入+1的值

把C语言转汇编
int main(){
int i = 0;
i++;
return 0;
}
Windows 在命令行使用 g++ sum_asm.c -S -fverbose-asm -o sum_asm.s
生成的结果如下
.text
.def __main; .scl 2; .type 32; .endef
.globl main
.def main; .scl 2; .type 32; .endef
.seh_proc main
main:
.LFB0:
pushq %rbp #
.seh_pushreg %rbp
movq %rsp, %rbp #,
.seh_setframe %rbp, 0
subq $48, %rsp #,
.seh_stackalloc 48
.seh_endprologue
# sum_asm.c:1: int main(){
call __main #
# sum_asm.c:2: int i = 0;
movl $0, -4(%rbp) #, i
# sum_asm.c:3: i++;
addl $1, -4(%rbp) #, i
# sum_asm.c:4: return 0;
movl $0, %eax #, _3
# sum_asm.c:5: }
addq $48, %rsp #,
popq %rbp #
ret
.seh_endproc
.ident "GCC: (x86_64-posix-seh-rev0, Built by MinGW-W64 project) 8.1.0"
从使用了rbp寄存器来判断,这是一个64位程序
CPU的μops(微操作)

基于data dependency做优化,两个修改相同寄存器(或读取等等有数据依赖关系)的指令CPU不能主动换顺序
- 根据data dependency,CPU会生成有向无环图(DAG)
- CPU就可以在一个时钟周期里取出多条指令,同时在处理器执行。

满足单处理器上 eventual memory consistency 的 内存一致性模型
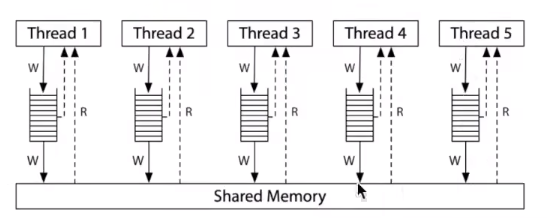
单核上遇到cache miss的时候,会把运行顺序修改,原本直接写入内存的操作,改为先写入cache,然后再等待任意长时钟周期再写入共享内存。
每个线程都有一个内存的副本(实际上就是MR),没有一致性可言
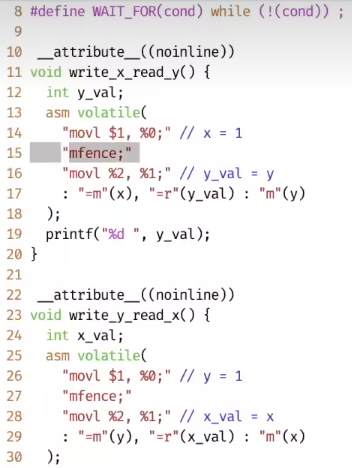
加入mfence 就可以保证当前线程缓存的内存写到共享内存以后,再处理下一条指令
python中的generator
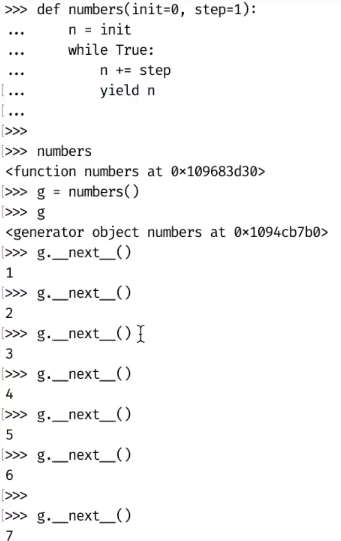
返回值中使用yield关键字,会生成generator
对generator使用__next__会让它执行到下一个yield中止
x86的原子操作

自旋锁
使用原子操作exchange实现
在一个原子过程内,把两个变量的值交换


为什么不使用table=YES?
因为使用exchange时,同时完成了获取table当前值和改变table值的操作

在执行sum++的时候,不会去DDR内存里读写,执行一次读内存,几百上千个时钟周期就过去了。实际上是从缓存里读的sum,每次想要读取sum都是从一级缓存(L1cache)里读写。
当有另外一个处理器想要读写sum,它就需要从当前处理器的一级缓存把sum拉取下来。

自旋锁在解决多核CPU互斥问题是唯一的方案。
因为一个CPU不应该关其他CPU的中断。
更广泛的一种无锁指令
compare and exchange
也叫 test and set

内存里的值与旧值相等的情况下才改变内存里的值。
长临界区互斥


扩展的方案
上锁成功就使用exchange,不通过操作系统
没上锁成功就申请操作系统把自己放入等待队列
同步
除了自旋锁,放入操作系统线程等待队列,还有一种方法:睡眠

走得快的人要等待走的慢的人赶上,再继续
线程操作有一个方法叫 join,等到所有线程都结束之后,才能继续
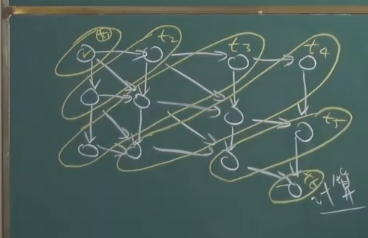
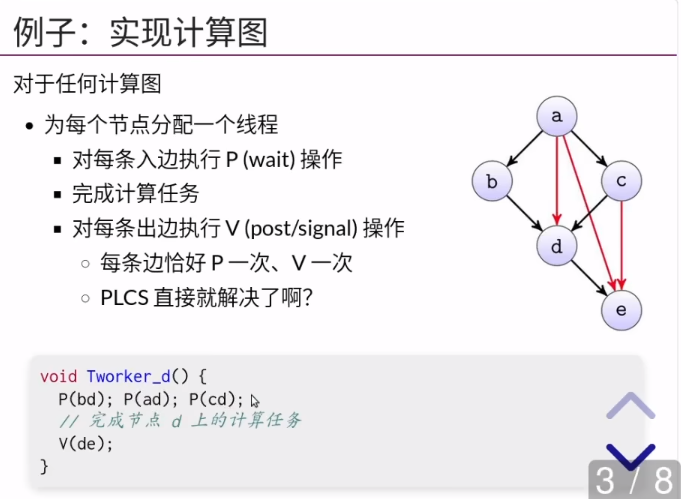
拓扑排序的最长路径就是它需要花的时间。(数据结构)

spin wait (忙等待):在生产者-消费者问题中,没有获得锁的一方,会进入忙等待状态。

这是两个线程间数据相互依赖的案例
条件变量

- 条件不成立的时候(此时自己已经加锁成功)调用wait,自己睡眠同时把锁释放掉
- 唤醒操作(signal:唤醒一个,broadcast:唤醒所有睡在这个条件变量上的人)

固定框架,黄框里面可以做任何实现

也可以直接全唤醒,只要保证唤醒的线程还会判断一遍自己是否成立即可
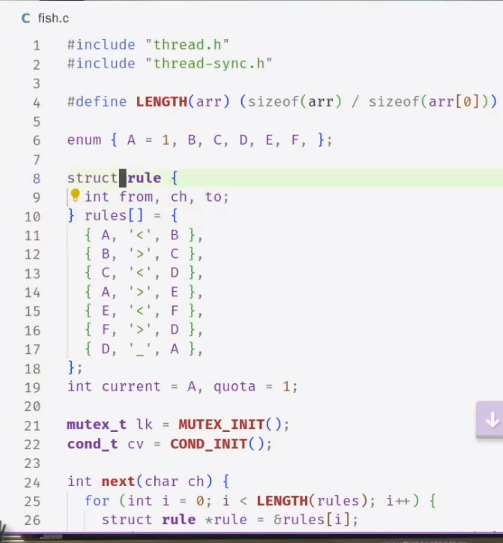
状态机:
- 定义初始状态
- 定义状态转移的路径 (比如A可以转移到B,也可以转移到E)
- 定义状态转移的时候要做的事情 (比如A转移到B,需要打印‘<’)
状态机模型处理并发编程是很强的,所有线程都在同一个状态里,就会知道下一步应该做什么。
信号量
是特殊的条件变量


自旋锁和互斥锁是两种不同的同步机制,它们都可以用来保护临界区,但是有以下区别 :
- 互斥锁:线程在申请互斥锁时,如果锁已经被占用,那么线程会被阻塞,释放CPU,等待锁的释放。这样可以避免浪费CPU资源,但是会产生上下文切换的开销。
- 自旋锁:线程在申请自旋锁时,如果锁已经被占用,那么线程会一直循环检测锁的状态,不会释放CPU,直到拿到锁为止。这样可以避免上下文切换的开销,但是会占用CPU资源。
一般来说,如果临界区的执行时间很短,那么自旋锁可能更合适;如果临界区的执行时间很长,那么互斥锁可能更合适。


信号量的应用:
- 实现一次临时的同步
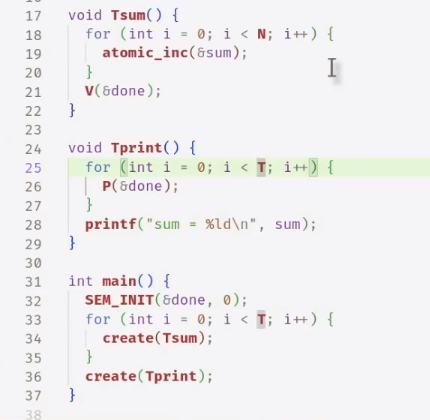

这里说的用信号量实现条件变量,实际上是实现wait函数的功能。

数据中心问题

协程

协程是在进程里模拟出的线程
只要yield执行了才会产生切换。



GPU并行计算架构


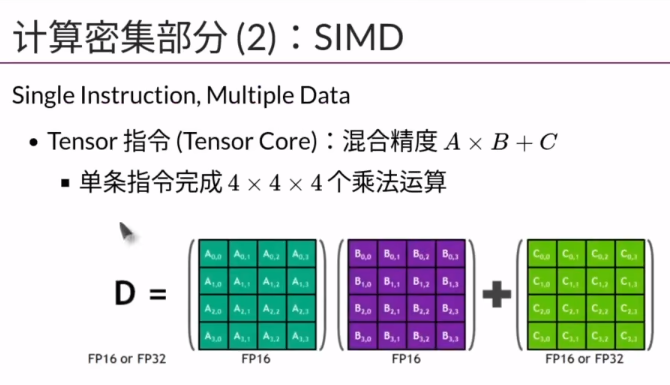



可以用C语言编程Cuda核
但是里面的指针都是指向显存地址,
需要用cudaMalloc 和 cudaMemcpy 完成从显存到内存的搬运。
Web2.0 架构
Html + CSS + JavaScript
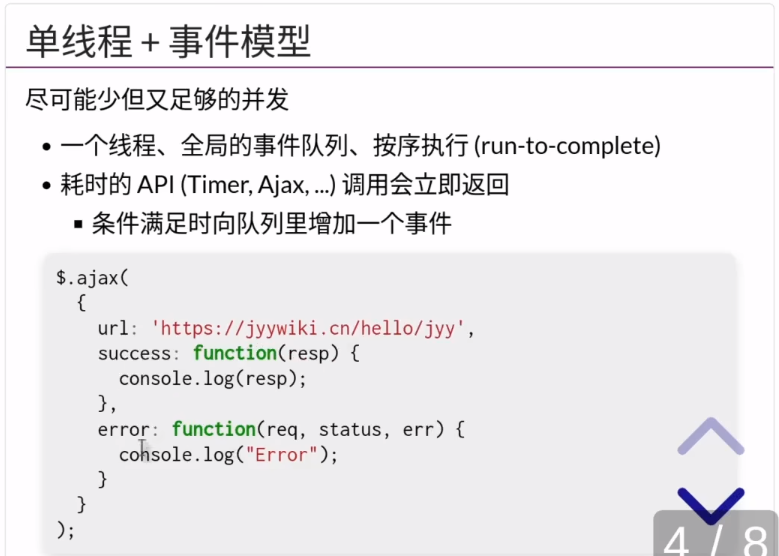
其中JavaScript是单线程模型


死锁是指多个进程因争夺有限的资源而相互等待,导致无法继续运行的现象。
死锁产生的四个必要条件是:
- 互斥条件:一个资源每次只能被一个进程使用。
- 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:进程已获得的资源,在未使用完之前,不能强行剥夺。
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
只有当这四个条件同时满足时,才会发生死锁。
打破123是很困难的,因为这会打破互斥的含义

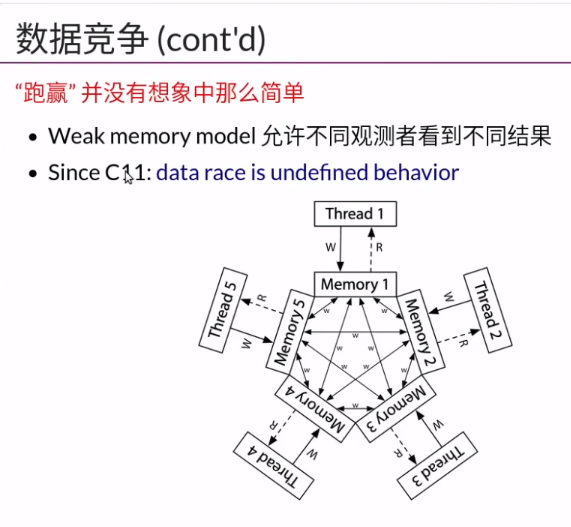
undefined behavior 是C和C++的灰色地带,当程序里有这个的时候,编译器没有任何保护,会产生安全漏洞或者突然Crash,


破坏死锁条件关键是:控制好上锁的顺序,防止循环等待
A等B,B等C,C等A是不行的
要做成一个有向无环图,1=2,2=3,3=4
执行完成后先释放4,再释放321
比如给每个锁一个编号,只能从编号最小的锁开始上锁,然后上锁编号大的。这样释放的顺序就可以从大的开始逐渐释放到小的

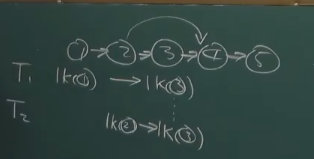
如果有线程1想获取 1,3
线程2想获取 2,3
那么他们都要按顺序获取,这样就必定有一个人可以拿到所有需要的条件
方法:写出不符合lock ordering的代码,编译器直接编译不通过
死锁和数据竞争都不应该发生
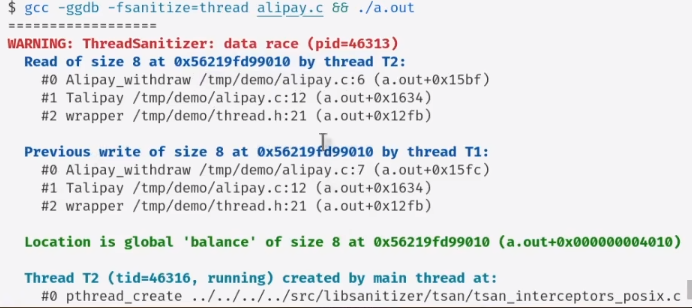
编译器自带的data race检测


在非栈空间的内存写入非初始化的值,然后在运行时可以进行内存检测,判断这段内存有没有被修改。