目录
文章目录
计算平台体系结构
单核 CPU 和超线程
在诸如多核、虚拟 CPU 和逻辑 CPU 这样的概念诞生前,在奔腾系列处理器的年代,大部分计算机在它们的主板上装备了一块不大不小的芯片,我们把它叫做微处理器、处理器或直接叫 CPU。只有很少数需要更强处理能力的企业能够负担得起同一块主板上安装 2 块以上的处理器的费用:这些就是多处理器系统。这些处理器与主板上其它元件的通信通过一个连接器或 Socket 来完成。那我们很容易能计算得到一块主板上有多少连接器或 Socket,那么这块主板上最多就能有相同数量的 CPU。如果你需要更多的计算能力,你只需要寻找一块能够支持更多处理器的主板即可。
但是后来 Intel 意识到多处理器系统里,处理器之间通过系统总线进行通信是非常低效的,因为总线传输速度较慢。这样就会经常发生的性能瓶颈,无法最大化利用 CPU 的计算能力。
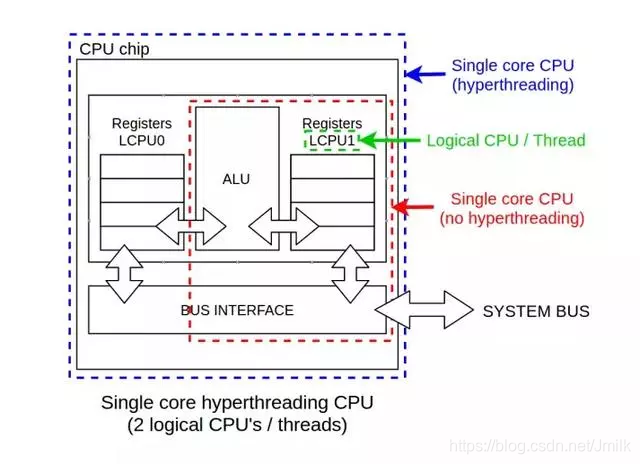
为了改善这个处境于是诞生了超线程技术。超线程的大意是复制一些 CPU 单元到同一块芯片上,比如寄存器或者一级缓存,这样可以在两个执行线程里共享这些数据,而无需经由系统总线和避免因为访问速度导致的性能下降问题。超线程还带来另外一个好处是可以当一个进程在等待中断的时候,另一进程仍然可以使用同一个 CPU 进行执行而且无需停止。
这种方式可以加速多个被处理的进程,比传统的单个核心(未开启超线程)提供更高的整体性能。操作系统有点像被欺骗的意思,因为它被提供了两个虚拟 CPU或者逻辑 CPU 并且可以“同时”执行两个进程。但是要非常注意的是,它并不能带来两倍的处理能力,也不提供完全并行计算能力。
这样, 从 Linux 或者其他操作系统的视角来看,一个单核 CPU 计算机通过超线程技术呈现出双核 CPU 的效果,但两个逻辑 CPU 实际上在同一个物理 CPU 中执行。
多核架构的出现
正如我在前面部分所说的,尽管开启了超线程的 CPU 能够提供更强的计算能力,但并不能提供 2 倍的处理能力和 2 个独立的 CPU,所以我打算进一步缩小 CPU 元件的视角,并且把它们都安装到统一块芯片上。如此一来每个被压缩的处理器都叫做核心,并且允许使用同一块硅晶的内部共享总线进行更快的通信。从那一刻开始再也不需要较慢的系统总线了。

不同于超线程技术,我们现在拥有多个完全独立的 CPU 服务于任何任务,每个任务可以分配一个核心。确实,从性能的角度来看,拥有单个多核芯片要比同一个主板上拥有多个单核芯片提供更好的性能。当然,拥有一个双数核心要比单数核心更好。
在操作系统层,一个物理的四核处理器可以看做是四个 CPU。但这些可能是四个逻辑 CPU 或者非物理的 LCPU。如果处理器还提供了超线程支持,那么像 htop 和 nproc 的命令会看到系统里有八个 CPU,但是可能在一个八核 CPU上看到少于八核的结果。
SMP 对称多处理结构
SMP(Sysmmetric Multi-Processor,对称多处理器),顾名思义,SMP 由多个具有对称关系的处理器组成。所谓对称,即处理器之间是水平的镜像关系,无有主从之分。SMP 的出现使一台计算机不再由单个 CPU 组成。
SMP 的典型特征为**「多个处理器共享一个集中式存储器」**,且每个处理器访问存储器的时间片相同,使得工作负载能够均匀的分配到所有可用处理器上,极大地提高了整个系统的数据处理能力。
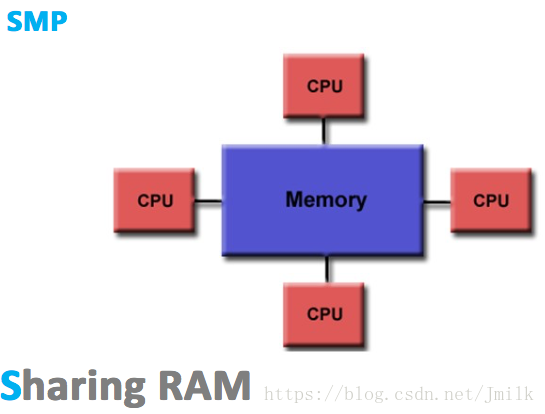
虽然 SMP 具有多个处理器,但由于只有一个共享的集中式存储器,所以 SMP 只能运行一个操作系统和数据库系统的副本(实例),依旧保持了单机特性。同时,SMP 也会要求多处理器保证共享存储器的数据一致性。如果多个处理器同时请求访问共享资源,就需要由软件或硬件实现的加锁机制来解决资源竞态的问题。由此,SMP 又称为 UMA(Uniform Memory Access,一致性存储器访问),所谓一致性指的是:
- 在任意时刻,多个处理器只能为存储器的每个数据保存或共享一个唯一的数值。
- 每个处理器访问存储器所需要的时间都是一致的
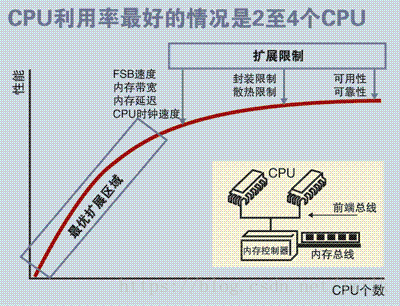
显然,这样的架构设计注定没法拥有良好的处理器数量扩展性,因为共享存储的资源竞态总是存在的,处理器利用率最好的情况只能停留在 2 到 4 颗。综合来看,SMP 架构广泛的适用于 PC 和移动设备领域,能显著提升并行计算性能。但 SMP 却不适合超大规模的服务器端场景,例如:云计算。
NUMA 非统一内存访问结构
现代计算机系统中,处理器的处理速度已经超过了主存的读写速度,限制计算机计算性能的瓶颈转移到了存储器带宽之上。SMP 由于集中式共享存储器的设计限制了处理器访问存储器的频次,导致处理器可能会经常处于对数据访问的饥饿状态。
**NUMA(Non-Uniform Memory Access,非一致性存储器访问)**的设计理念是将处理器和存储器划分到不同的节点(NUMA Node),它们都拥有几乎相等的资源。在 NUMA 节点内部会通过自己的存储总线访问内部的本地内存,而所有 NUMA 节点都可以通过主板上的共享总线来访问其他节点的远程内存。
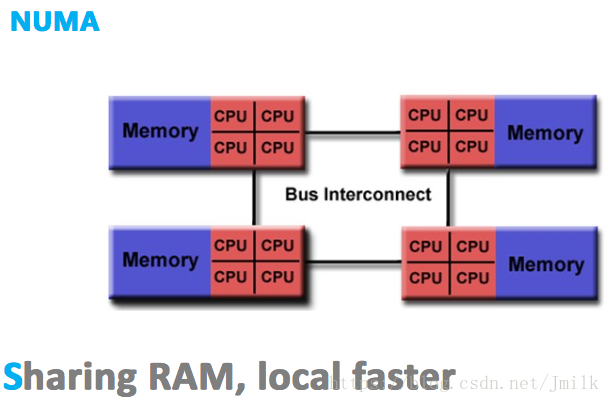
很显然,处理器访问本地内存和远程内存的时耗并不一致,NUMA 非一致性存储器访问由此得名。而且因为节点划分并没有实现真正意义上的存储隔离,所以 NUMA 同样只会保存一份操作系统和数据库系统的副本。
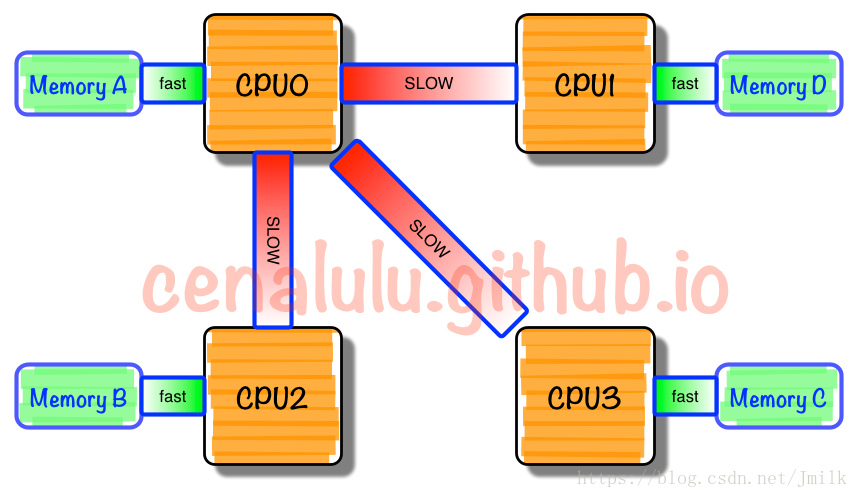
NUMA「多节点」的结构设计能够在一定程度上解决 SMP 低存储带宽的问题。假如有一个 4 NUMA 节点的系统,每一个 NUMA 节点内部具有 1GB/s 的存储带宽,外部共享总线也同样具有 1GB/s 的带宽。理想状态下,如果所有的处理器总是访问本地内存的话,那么系统就拥有了 4GB/s 的存储带宽能力,此时的每个节点可以近似的看作为一个 SMP(这种假设为了便于理解,并不完全正确);相反,在最不理想的情况下,如果所有处理器总是访问远程内存的话,那么系统就只能有 1GB/s 的存储带宽能力。
除此之外,使用外部共享总线时可能会触发 NUMA 节点间的 Cache 同步异常,这会严重影响内存密集型工作负载的性能。当 I/O 性能至关重要时,共享总线上的 Cache 资源浪费,会让连接到远程 PCIe 总线上的设备(不同 NUMA 节点间通信)作业性能急剧下降。
由于这个特性,基于 NUMA 开发的应用程序应该尽可能避免跨节点的远程内存访问。因为,跨节点内存访问不仅通信速度慢,还可能需要处理不同节点间内存和缓存的数据一致性。多线程在不同节点间的切换,是需要花费大成本的。
虽然 NUMA 相比于 SMP 具有更好的处理器扩展性,但因为 NUMA 没有实现彻底的主存隔离。所以 NUMA 远没有达到无限扩展的水平,最多可支持几百个 CPU。这是为了追求更高的并发性能所作出的妥协,一个节点未必就能完全满足多并发需求,多节点间线程切换实属一个折中的方案。这种做法使得 NUMA 具有一定的伸缩性,更加适合应用在服务器端。
MPP 大规模并行处理结构
MPP(Massive Parallel Processing,大规模并行处理),既然 NUMA 扩展性的限制是没有完全实现资源(e.g. 存储器、互联模块)的隔离性,那么 MPP 的解决思路就是为处理器提供彻底的独立资源。
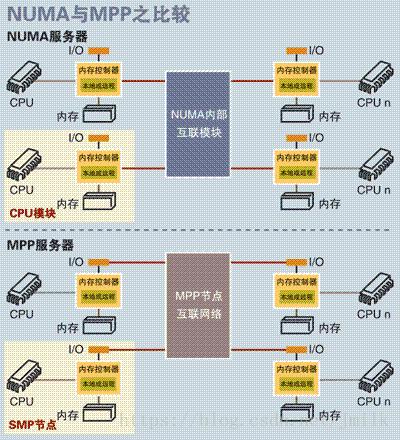
MPP 拥有多个真正意义上的独立的 SMP 单元,每个 SMP 单元独占并只会访问自己本地的内存、I/O 等资源,SMP 单元间通过节点互联网络进行连接(Data Redistribution,数据重分配),是一个完全无共享(Share Nothing)的 CPU 计算平台结构。
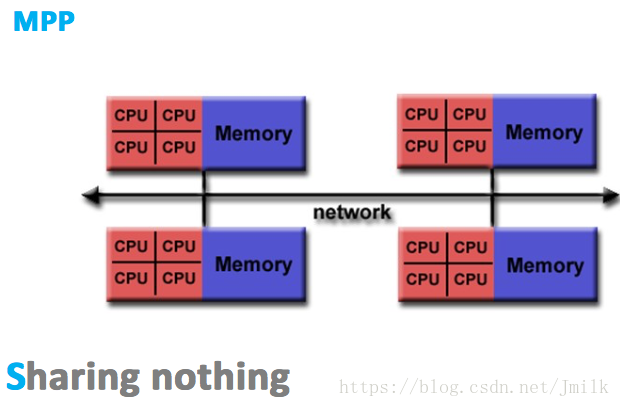
MPP 的典型特征就是**「多 SMP 单元组成,单元之间完全无共享」**。除此之外,MPP 结构还具有以下特点:
- 每个 SMP 单元内都可以包含一个操作系统副本,所以每个 SMP 单元都可以运行自己的操作系统
- MPP 需要一种复杂的机制来调度和平衡各个节点的负载和并行处理过程,目前一些基于 MPP 技术的服务器往往通过系统级软件(e.g. 数据库)来屏蔽这种复杂性
- MPP 架构的局部区域内存的访存延迟低于远地内存访存延迟,因此 Linux 会自定采用局部节点分配策略,当一个任务请求分配内存时,首先在处理器自身节点内寻找空闲页,如果没有则到相邻的节点寻找空闲页,如果还没有再到远地节点中寻找空闲页,在操作系统层面就实现了访存性能优化
因为完全的资源隔离特性,所以 MPP 的扩展性是最好的,理论上其扩展无限制,目前的技术可实现 512 个节点互联,数千个 CPU,多应用于大型机。
Linux 上的 NUMA
基本对象概念
- Node:包含有若干个 Socket 的组
- Socket:表示一颗物理 CPU 的封装,简称插槽。Intel 为了避免将物理处理器和逻辑处理器混淆,所以将物理处理器统称为插槽。
- Core:Socket 内含有的物理核。
- Thread:在具有 Intel 超线程技术的处理器上,每个 Core 可以被虚拟为若干个(通常为两个)逻辑处理器,逻辑处理器会共享大多数内核资源(e.g. 内存缓存、功能单元)。逻辑处理器被统称为 Thread。
- Processor:处理器的统称,可以区分为物理处理器(physical processor)和逻辑处理器(virtual processors),对于大多数应用程序而言,它们并不关心处理器是物理的还是逻辑的。
- Siblings:表示每一个 physical processor 所含有的 virtual processors 的数量。(If the number of siblings is equal to the number of cores then you have CPUs which are not hyperthreading or hyperthreading is switched off, If the number of siblings is 2x the number of cores then you have a hyperthreading CPU with hyperthreading switched on. )
(一个 Socket 4 个 Core)

包含关系:NUMA Node > Socket > Core > Thread
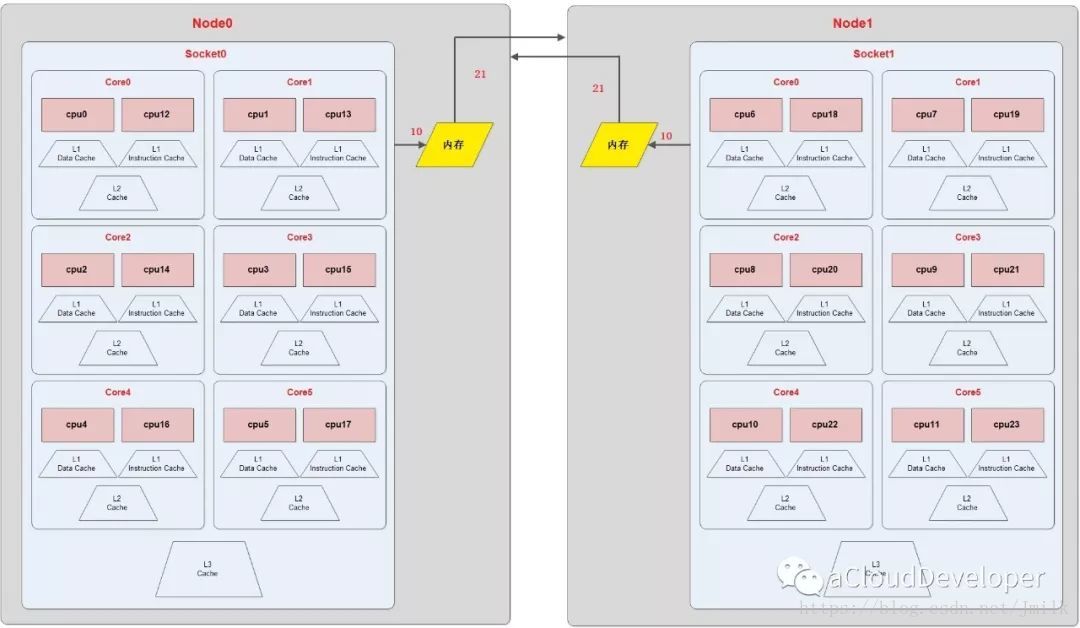
EXAMPLE:上图为一个 NUMA Topology,表示该服务器具有 2 个 numa node,每个 node 含有一个 socket,每个 socket 含有 6 个 core,每个 core 又被超线程为 2 个 thread,所以服务器总共的 processor = 2*1*6*2 = 24 颗。
NUMA 调度策略
Linux 的每个进程或线程都会延续父进程的 NUMA 策略,优先会将其约束在一个 NUMA node 内。当然了,如果 NUMA 策略允许的话,进程也可以调用其他 node 上的资源。
NUMA 的 CPU 分配策略有下列两种:
- cpunodebind:约束进程运行在指定的若干个 node 内
- physcpubind:约束进程运行在指定的若干个物理 CPU 上
NUMA 的 Memory 分配策略有下列 4 种:
- localalloc:约束进程只能请求访问本地内存
- preferred:宽松地为进程指定一个优先 node,如果优先 node 上没有足够的内存资源,那么进程允许尝试运行在别的 node 内
- membind:规定进程只能从指定的若干个 node 上请求访问内存,并不严格规定只能访问本地内存
- interleave:规定进程可以使用 RR 算法轮转地从指定的若干个 node 上请求访问内存
获取宿主机的 NUMA 拓扑
Bash 脚本:
#!/bin/bash
function get_nr_processor()
{
grep '^processor' /proc/cpuinfo | wc -l
}
function get_nr_socket()
{
grep 'physical id' /proc/cpuinfo | awk -F: '{
print $2 | "sort -un"}' | wc -l
}
function get_nr_siblings()
{
grep 'siblings' /proc/cpuinfo | awk -F: '{
print $2 | "sort -un"}'
}
function get_nr_cores_of_socket()
{
grep 'cpu cores' /proc/cpuinfo | awk -F: '{
print $2 | "sort -un"}'
}
echo '===== CPU Topology Table ====='
echo
echo '+--------------+---------+-----------+'
echo '| Processor ID | Core ID | Socket ID |'
echo '+--------------+---------+-----------+'
while read line; do
if [ -z "$line" ]; then
printf '| %-12s | %-7s | %-9s |\n' $p_id $c_id $s_id
echo '+--------------+---------+-----------+'
continue
fi
if echo "$line" | grep -q "^processor"; then
p_id=`echo "$line" | awk -F: '{print $2}' | tr -d ' '`
fi
if echo "$line" | grep -q "^core id"; then
c_id=`echo "$line" | awk -F: '{print $2}' | tr -d ' '`
fi
if echo "$line" | grep -q "^physical id"; then
s_id=`echo "$line" | awk -F: '{print $2}' | tr -d ' '`
fi
done < /proc/cpuinfo
echo
awk -F: '{
if ($1 ~ /processor/) {
gsub(/ /,"",$2);
p_id=$2;
} else if ($1 ~ /physical id/){
gsub(/ /,"",$2);
s_id=$2;
arr[s_id]=arr[s_id] " " p_id
}
}
END{
for (i in arr)
printf "Socket %s:%s\n", i, arr[i];
}' /proc/cpuinfo
echo
echo '===== CPU Info Summary ====='
echo
nr_processor=`get_nr_processor`
echo "Logical processors: $nr_processor"
nr_socket=`get_nr_socket`
echo "Physical socket: $nr_socket"
nr_siblings=`get_nr_siblings`
echo "Siblings in one socket: $nr_siblings"
nr_cores=`get_nr_cores_of_socket`
echo "Cores in one socket: $nr_cores"
let nr_cores*=nr_socket
echo "Cores in total: $nr_cores"
if [ "$nr_cores" = "$nr_processor" ]; then
echo "Hyper-Threading: off"
else
echo "Hyper-Threading: on"
fi
echo
echo '===== END ====='
OUTPUT:
===== CPU Topology Table =====
+--------------+---------+-----------+
| Processor ID | Core ID | Socket ID |
+--------------+---------+-----------+
| 0 | 0 | 0 |
+--------------+---------+-----------+
| 1 | 1 | 0 |
+--------------+---------+-----------+
| 2 | 2 | 0 |
+--------------+---------+-----------+
| 3 | 3 | 0 |
+--------------+---------+-----------+
| 4 | 4 | 0 |
+--------------+---------+-----------+
| 5 | 5 | 0 |
+--------------+---------+-----------+
| 6 | 0 | 1 |
+--------------+---------+-----------+
| 7 | 1 | 1 |
+--------------+---------+-----------+
| 8 | 2 | 1 |
+--------------+---------+-----------+
| 9 | 3 | 1 |
+--------------+---------+-----------+
| 10 | 4 | 1 |
+--------------+---------+-----------+
| 11 | 5 | 1 |
+--------------+---------+-----------+
| 12 | 0 | 0 |
+--------------+---------+-----------+
| 13 | 1 | 0 |
+--------------+---------+-----------+
| 14 | 2 | 0 |
+--------------+---------+-----------+
| 15 | 3 | 0 |
+--------------+---------+-----------+
| 16 | 4 | 0 |
+--------------+---------+-----------+
| 17 | 5 | 0 |
+--------------+---------+-----------+
| 18 | 0 | 1 |
+--------------+---------+-----------+
| 19 | 1 | 1 |
+--------------+---------+-----------+
| 20 | 2 | 1 |
+--------------+---------+-----------+
| 21 | 3 | 1 |
+--------------+---------+-----------+
| 22 | 4 | 1 |
+--------------+---------+-----------+
| 23 | 5 | 1 |
+--------------+---------+-----------+
Socket 0: 0 1 2 3 4 5 12 13 14 15 16 17
Socket 1: 6 7 8 9 10 11 18 19 20 21 22 23
===== CPU Info Summary =====
Logical processors: 24
Physical socket: 2
Siblings in one socket: 12
Cores in one socket: 6
Cores in total: 12
Hyper-Threading: on
===== END =====
NOTE 1:Processors / Cores = 每个物理内核超线程出来的逻辑处理器数量,一般为 2 个。
NOTE 2:上述具有相同 Socket ID 和 Core ID 的 2 个 Processors 就是由同一个 Core 超线程出来的两个逻辑处理器。
DPDK 官方提供的 Python 脚本:
#!/usr/bin/env python
# SPDX-License-Identifier: BSD-3-Clause
# Copyright(c) 2010-2014 Intel Corporation
# Copyright(c) 2017 Cavium, Inc. All rights reserved.
from __future__ import print_function
import sys
try:
xrange # Python 2
except NameError:
xrange = range # Python 3
sockets = []
cores = []
core_map = {}
base_path = "/sys/devices/system/cpu"
fd = open("{}/kernel_max".format(base_path))
max_cpus = int(fd.read())
fd.close()
for cpu in xrange(max_cpus + 1):
try:
fd = open("{}/cpu{}/topology/core_id".format(base_path, cpu))
except IOError:
continue
except:
break
core = int(fd.read())
fd.close()
fd = open("{}/cpu{}/topology/physical_package_id".format(base_path, cpu))
socket = int(fd.read())
fd.close()
if core not in cores:
cores.append(core)
if socket not in sockets:
sockets.append(socket)
key = (socket, core)
if key not in core_map:
core_map[key] = []
core_map[key].append(cpu)
print(format("=" * (47 + len(base_path))))
print("Core and Socket Information (as reported by '{}')".format(base_path))
print("{}\n".format("=" * (47 + len(base_path))))
print("cores = ", cores)
print("sockets = ", sockets)
print("")
max_processor_len = len(str(len(cores) * len(sockets) * 2 - 1))
max_thread_count = len(list(core_map.values())[0])
max_core_map_len = (max_processor_len * max_thread_count) \
+ len(", ") * (max_thread_count - 1) \
+ len('[]') + len('Socket ')
max_core_id_len = len(str(max(cores)))
output = " ".ljust(max_core_id_len + len('Core '))
for s in sockets:
output += " Socket %s" % str(s).ljust(max_core_map_len - len('Socket '))
print(output)
output = " ".ljust(max_core_id_len + len('Core '))
for s in sockets:
output += " --------".ljust(max_core_map_len)
output += " "
print(output)
for c in cores:
output = "Core %s" % str(c).ljust(max_core_id_len)
for s in sockets:
if (s,c) in core_map:
output += " " + str(core_map[(s, c)]).ljust(max_core_map_len)
else:
output += " " * (max_core_map_len + 1)
print(output)
OUTPUT:
[root@overcloud-compute-0 ~]# python cpu_topo.py
======================================================================
Core and Socket Information (as reported by '/sys/devices/system/cpu')
======================================================================
cores = [0, 1, 2, 3, 4, 5]
sockets = [0, 1]
Socket 0 Socket 1
-------- --------
Core 0 [0] [6]
Core 1 [1] [7]
Core 2 [2] [8]
Core 3 [3] [9]
Core 4 [4] [10]
Core 5 [5] [11]
上述输出的意义:
- 有两个 Socket(物理 CPU)
- 每个 Socket 有 6 个 Core(物理核),总计 12 个
Output:
[root@overcloud-compute-0 ~]# python cpu_topo.py
======================================================================
Core and Socket Information (as reported by '/sys/devices/system/cpu')
======================================================================
cores = [0, 1, 2, 3, 4, 5]
sockets = [0, 1]
Socket 0 Socket 1
-------- --------
Core 0 [0, 12] [6, 18]
Core 1 [1, 13] [7, 19]
Core 2 [2, 14] [8, 20]
Core 3 [3, 15] [9, 21]
Core 4 [4, 16] [10, 22]
Core 5 [5, 17] [11, 23]
上述输出的意义:
- 有两个 Socket(物理 CPU)
- 每个 Socket 有 6 个 Core(物理核),总计 12 个
- 每个 Core 有两个 Virtual Processor,总计 24 个
多处理器计算平台中的多任务并行与调度
多任务分为硬件支持的多任务与软件支撑的多任务。早期计算机系统中的多任务并行执行更多是由软件来实现的,采用多进程或多线程模型来设计用户程序。单处理器计算平台同一时间只能运行一个任务,但操作系统可以在很小的时间间隔内通过快速的切换多个不同的任务,来给用户造成一种多个任务同时执行的假象,但其本质仍是并发而非并行执行。这样的程序运行机制被称为软件支撑的多任务系统。
随着硬件的发展,推出了多处理器计算平台,现在的服务器系统大多是此类型,同时支持软硬两种方式的多任务并行处理。程序的多个进程或进程内的多个线程可以同时使用多个不同的处理器来执行各自的任务,如果任务的数目不超过处理器的数目,则操作系统通常会确保每个任务都独占一个处理器,以此来提高程序的并发和降低延时。这样的程序运行机制被称为硬件支撑的多任务系统。
多处理器计算平台的并发程序设计中,大致会引来两个问题,一个是内存可见性,一个是 Cache 一致性流量。内存可见性属于并发安全的问题,Cache 一致性流量引起的是性能上的问题。
-
内存可见性:在单处理器或单线程场景中不会发生该问题。在一个单线程环境中,为一个变量写入值,然后在没有干涉的情况下读取这个变量,得到的值始终会是最新的值。但如果读、写不在同一个线程中进行时,情况是不可预料的。同理,Core1 和 Core2 可能会同时把主存中某个位置的值加载到自己的一级缓存中,而 Core1 修改了自己一级缓存中的值后,却不更新主存中的值,这样对于 Core2 来讲,永远看不到 Core1 对值的修改,导致共享数据不一致。
-
Cache 一致性问题:例如在 SMP 体系结构中,Core1 和 Core2 同时加载了主存中的值到自己的一级缓存中,Core1 修改值后,会通过总线让 Core2 中的值失效,Core2 发现自己存的值失效后,会再通过总线从主存中得到新值,以此来保证数据一致性。总线的通信带宽是固定的,通过总线来进行各 CPU 的一级缓存数据同步,那么总线带宽就会成瓶颈。这会影响到 CPU 的性能,需要通过减小数据同步竞争来减少一致性维护流量。
在 SMP 体系结构中,各 CPU 可以共享一个全局的 run_queue(可执行队列)也可以拥有一个私有的 run_queue,一般每个 CPU 对应了一个 run_queue的情况较多。如果进程处于 TASK_RUNNING(可执行状态),则该进程会被加入且仅会被加入到其中一个 run_queue 中,以便让调度器从 run_queue 中调入 CPU。CPU 和可执行队列一一对应的好处在于维护了进程与 CPU 的亲和性。由于处理器 Cache 的原因,通常进程在某个 CPU 上开始执行后,就不会轻易切换到另一个 CPU 上运行。让一个持续处于 TASK_RUNNING 的进程总是趋向于在同一个 CPU 上运行,这样有利于提高进程数据的缓存命中率,提高运行效率。否则会带来额外的缓存开销。操作系统会积极的维护进程亲和性以提高执行效率,但有些情况下仍然会发生被动的 CPU 迁移。例如调度器的负载均衡机制。
多处理器计算平台是一个复杂的系统,有多复杂?现在服务器计算平台可能会集合了 SMP、NUMA、多核、超线程等技术。在这样复杂的系统,调度器要解决的一个首要问题就是如何让处理器保持忙碌,使得负载均衡。Scheduling Domain 就是负载均衡机制就是针对混合多处理器技术场景下的 Linux 的调度器实现。
Scheduling Domain 其实就是将具有相同属性的 CPUs 组成集合,并且跟据 Multicore-processors、Hyper-threading、SMP、NUMA 这样的多处理器技术划分成不同的级别。不同级别间通过指针链接在一起,从而形成一种的树状的关系。
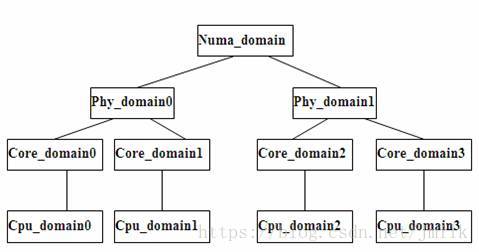
针对 Scheduling domain,从叶节点往上遍历,直到所有的 domain 中的负载都是平衡的。当然对不同的 domain 会有不同的策略识别负载是否为平衡,以及不同的调度策略。
通过这样的方式,能够针对不同的处理器类型、多处理器实现技术进行针对性的负载均衡算法,从而在各个 domain 都得到负载优化,以此来实现整体 CPUs 的负载优化。
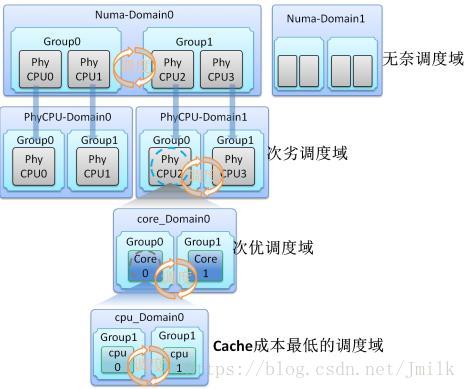
实际上多处理器之间的 Load Balance 同样是有代价的,比如对处于两个不同处理器上运行的进程进行负载平衡的话,将会使得处理器 Cache 失效,造成效率下降。还要考虑的一个问题就是功耗的问题,一个处理器中的两个逻辑处理器各执行一个进程,会比两个处理器各执行一个进程更节省功耗。
显然,调度器的负载均衡机制和进程亲和性原则是相悖的。虽然 Scheduling domain 自身也具有软 CPU 亲和特性,但正如在上文中我们反复提到过的,调度器的核心任务是负责保证每个 CPU 都是忙碌的,但并不负责用户程序的执行性能。所以 Linux 一方面提供了设定负载均衡触发阈值的接口,另一方面 Linux 内核也提供了将进程绑定到指定 CPU 的硬 CPU 亲和系统调用,可以明确指定该进程不允许发生 CPU 迁移。在 NUMA 体系结构中,内存管理器还会配合调度器做其相应的策略调整。当一个进程绑定到指定的 CPU 之后,进程申请的内存资源就都要从其相应的 NUMA 节点分配。
多处理器实现与多任务性能的影响
从微观的角度来看,不同的多处理器技术实现会对多任务的并行性能产生不同的影响。
多核处理器(Multicore-processors 或 CMP,Chip-level Multi Processor),每个处理器由多个核心构成,一般拥有独立的 L1 Cache,也可能拥有独立的 L2 Cache。与多处理器(Multi-processors)不同,多核处理器的多个核心在同一个物理芯片上,所以线程间交换数据的效率会更高,功耗也更少。
超线程(Hyper-threading 或 SMT),每个核心都通过超线程技术实现多个硬件线程(Thread),或称为 Virtual CPU,或称为逻辑处理器。这些硬件线程之间几乎所有的东西都会共享。包括 L1 Cache,甚至是逻辑运算单元(ALU)以及功耗(Power)。一般的,如果处理器 Cache 不命中,则处理器需要等待较长的时间从内存中读取数据,这段时间内的逻辑运算核心就会被挂起(Memory Stall),造成性能损耗。超线程的出现就是为了解决这个问题。与上层调度的思路类似,当逻辑运算核心在等待 I/O,那么这时就可以启动另一个隶属于同一个核心的硬件级线程来运行其他任务的指令,防止逻辑运算核心空闲。Linux 操作系统将每个硬件线程都抽象为独立的逻辑处理器,例如,一个双核 2 线程的处理器,从 Linux 操作系统看到的其实是 4 个 Processor 资源。
超线程具有粗粒度和精粒度两种超线程切换的方式,前者在 CPU 出现较大的空闲(e.g. Memory Stall)时才做进行切换,并且切换时由于要重新填充 Pipeline 多以会给性能带来额外开销;后者的控制则更加精细,切换逻辑也更加复杂,但效果较好。超线程技术极致的压榨了处理器的并发能力,提供了吞吐量。但同时也会因为多个线程在同一个物理核心中竞争,导致线程的处理时延变长。
NUMA 体系结构,我们已经在《OpenStack Nova 高性能虚拟机之 NUMA 架构亲和》 中详细的讨论过了,这里不再赘述。在 NUMA 体系结构中的多线程同样面临着调度器无情的 “负载优化” 使用户程序得不到最大的性能优化。例如:应用程序的线程首先在 NODE_A 内运行,但调度器发现存在可用的 NODE_B 异常空闲。调度器就会把应用程序的一个线程迁移到 NODE_B。但是,此时的线程可能仍然需要访问在 NODE_A 的内存。由于该线程当前在 NODE_B 运行,并且对于此线程来说 NODE_A 的内存已经变成了远程内存,远程内存的访问就要花更长的时间。**相较于线程在 NODE_A 内等待可用的处理器,该线程在 NODE_B 访问远程内存可能要更加费时。**正如上面提到的,Linux 内核同样会积极保持线程亲和性,保证 Cache 的命中率。该特性在 NUMA 体系结构中,同样有助于提高内存本地性,避免了队列操作的线程同步开销(Mutex,互斥锁)。如果可执行队列是全局并被所有 CPU 共享的,那么这种开销将会影响计算平台架构的扩展性。
CPU 亲和性
CPU 亲和性(CPU Affinity),又称 CPU 关联性,是一种调度属性(Scheduler Property),指定进程要在特定的 CPU 上尽量长时间地运行而不被迁移到其他 CPU 上的倾向性。Linux 内核调度器原生支持「软 CPU 亲和性」,调度器会积极的让进程在同一个 CPU 上运行。内核 2.6 版本引入了可供编程的「硬 CPU 亲和性」,意味着用户程序可以显式地指定进程在哪个(或哪些)处理器上运行。
进程描述符 task_struct 的 cpus_allowed 表示 CPU 亲和位掩码(BitMask)由 n 位组成,对应系统中的 n 个 Processor。最低位表示第一个 Processor,最高位表示最后一个 Processor,进程的 CPU 亲和特性会传递给子线程。通过为进程的 cpus_allowed 掩码位置 1 来指定进程的 Processors 亲和,当有多个掩码位被置 1 时表示运行进程在多个 Processor 间迁移,缺省为全部位置 1。
设定进程或线程的 CPU 亲和性
在多处理器计算平台中,尤其在 NUMA 架构体系中,设置 CPU 亲合能够有效提高 CPU Cache 的命中率,减少远程内存访问损耗,以获得更高的性能。Linux 内核提供了 API 接口,可以让用户查看和修改进程/线程的 CPI 亲和。通常的以下 2 种场景我们需要考虑手动设定 CPU 亲和:
- 计算量巨大(e.g. 人工智能,图形计算,超算)
- 进程任务对延时非常敏感(e.g. 运营商级别的 NFV,能支持千兆万兆网卡数据采集的 DPDK)
查看进程运行在哪个 Processor 上:
root@devstack:~# ps -eo pid,args,psr
PID COMMAND PSR
...
19153 python test.py 3
...
- pid:进程标识
- args:进程执行时传入的命令行参数
- psr:运行进程的 Processor ID
查看线程的 TID:上文我们提到过,Linux 的用户线程本质是 LWP,所以从操作层面上看到的 TID 其实就是用户线程真实的 PID。
注意,TID 并非编程接口 pthread_getaffinity_np(pthread_t thread, ...) 中的 pthread_t。
# test.py 是在终端运行的一个线程脚本
root@devstack:~# ps -efL | grep test
root 19153 18464 19153 0 2 03:47 pts/0 00:00:00 python test.py
root 19153 18464 19319 0 2 03:54 pts/0 00:00:00 python test.py
root 19323 18549 19323 0 1 03:54 pts/1 00:00:00 grep --color=auto test
root@devstack:~# ps -To 'pid,lwp,psr,cmd' -p 19153
PID LWP PSR CMD
19153 19153 3 python test.py
19153 19329 7 python test.py
# 一个线程脚本生成了两个 LWP,一个是主进程,一个是子进程(子线程)
C 语言调用接口设定 CPU 亲和
进程:
int sched_getaffinity(pid_t pid, size_t cpusetsize,cpu_set_t *mask); //查看 pid 绑定的 cpu。
int sched_setaffinity(pid_t pid, size_t cpusetsize,cpu_set_t *mask); //设定 pid 绑定的 cpu,
线程:
int pthread_setaffinity_np(pthread_t thread, size_t cpusetsize, onst cpu_set_t *cpuset); //查看 thread 绑定的 cpu。
int pthread_getaffinity_np(pthread_t thread, size_t cpusetsize, cpu_set_t *cpuset); //设定 thread 绑定的 cpu。
Linux 指令设定 CPU 亲和
taskset 指令用于根据 PID 显示、设定运行进程的 CPU 亲和性,还可以在启动进程的同时设定 CPU 亲和性,将指定的进程与指定的 CPU(或一组 CPU)绑定起来。但 taskset 指令不能保证内存分配,在 NUMA 结构体系的计算平台中可以使用 numactl 指令来完成本地内存分配。
为运行的进程设定 CPU 亲和:
taskset -p <mask> pid
在操作层面,CPU 亲和性使用十六进制的位掩码来表示。e.g. 0x00000001 代表 Processor0,0x00000003 代表 Processor3 和 Processor1。
为启动的进程设定 CPU 亲和:
taskset mask -- <program>
# e.g.
root@devstack:~# taskset -c 0 python test.py
root@devstack:~# ps -eo pid,args,psr | grep test
20277 python test.py 0
Python 语言设定进程的 CPU 亲和
Python 程序可以用个 cpu_affinity 库来实现设定进程的 CPU 亲和。cpu_affinity 提供了 3 个 method:
- 通过 PID 获取进程
_get_handle_for_pid(pid, ro=True)
- 通过 PID 获取进程的 CPU 亲和位掩码
get_process_affinity_mask(pid)
- 绑定 PID 的进程到指定的 CPU
set_process_affinity_mask(pid, cpu)
设定 NUMA 结构体系中的 CPU 亲和策略
首先,我们重申一些概念,线程是处理器调度运行的基本单位,进程是资源分配的基本单位;Linux 将所有可提供运算能力的单元统一抽象为 Processor;
numactl 指令可以用于设定进程的 CPU 亲和策略和 NUMA 节点内存分配策略。设定的策略会对进程及其所有子进程生效。
numactl 指令实际上是通过 /sys 文件系统来决定系统拓扑的,/sys 文件系统包含有关 CPU、内存和外设是如何通过 NUMA 互联的信息。特别是 /sys/devices/system/cpu 目录中包含有关 CPU 是如何互联的信息。/sys/devices/system/node 目录包含有关系统中 NUMA 节点以及节点间的相对距离信息。NUMA 系统中的处理器和内存条间的相对距离越大,处理器访问内存的速度就越慢。所以应该为性能敏感的应用程序设定从最接近运行程序进程的 NUMA 节点最接近的内存条分配内存,简单来说,让进程使用 NUMA 节点的本地内存。
除此之外,多线程应用程序在 NUMA 系统中还存在一个问题值得被关注。我们知道 CPU 的 Core 是直接访问 L1(或 L2、L3 视 CPU 模具设计而定)Cache 的。如果多线程运行在 NUMA 节点的多核 CPU 上,线程间可能不不断在同一个 CPU 的不同 Core 中切换并轮流使用 Core 的 Cache。假如现在 Core 的 L1 Cache 全部是 T1 的数据,那么当线程切换为 T2 时,就很可能会将 L1 Cache 的数据刷新为 T2 的数据。当再次线程切换为 T1 时,T1 又会重新把 L1 Cache 的数据刷新为 T1 的数据。周而复始,线程间不断的在破坏对方在 Core 上的缓存数据,每一次线程切换,当前线程都需要花费宝贵时间片从内存从加载数据到 Cache。这就是由「缓存交叉访问」导致的「缓存贬值」问题。
(Core 独占 L3)
所以,对于性能敏感的多线程应用程序,建议直接将线程绑定到一个或少数 Core 上,以此来充分发挥 Cache 的价值。最起码也应该将线程绑定到一个 NUMA 节点上,让线程在多个层级(L1、L2 以及 L3 Cache)间共享缓存。
(Core 共享 L3)
需要注意的是,根据每个 CPU 布局设计的不同存在不同的微观调整方案,但大体的原则是一致的:「线程绑定粒度越小,线程执行性能越高」。
使用 numastat 指令来查看 NUMA 节点的内存分配统计数据及分配情况:
Per-node numastat info (in MBs):
Node 0 Total
------ -----
Numa_Hit 25036 25036
Numa_Miss 0 0
Numa_Foreign 0 0
Interleave_Hit 115 115
Local_Node 25036 25036
Other_Node 0 0
- numa_hit:成功分配到本地内存访问的内存大小
- numa_miss:把内存分配到另一个节点的内存大小
- numa_foreign:另一个节点访问该节点本地内存的大小
- interleave_hit:成功分配到该节点的尝试交错策略数
- local_node:该节点上的进程成功分配本地内存的大小
- other_node:该节点上的进程从其他节点上分配远程内存的大小
显然,低 numa_miss 和 numa_foreign 值表示最佳 CPU 性能。反正,则需要考虑进行亲和性调整。
使用 numactl 指令可以将进程绑定到指定的 NUMA 节点,也可以将某个线程绑定到 NUMA 节点的指定 Cores 上。
--show:显示 NUMA 节点的进程策略
root@devstack:~# numactl --show
policy: default
preferred node: current
physcpubind: 0 1 2 3 4 5 6 7
cpubind: 0
nodebind: 0
membind: 0
--hardware:显示系统中可用的 NUMA 节点清单
root@devstack:~# numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1 2 3 4 5 6 7
node 0 size: 16046 MB
node 0 free: 11061 MB
node distances:
node 0
0: 10
--membind:限定从指定 NUMA 节点分配内存,如果这些节点中的内存不足则分配失败。
numactl --membind=<nodes> <program>
# nodes: NUMA 节点 ID,使用逗号隔开
# program: 应用程序
# e.g.
numactl --membind=0 python test.py
--cpunodebind:把进程及其子进程绑定到指定的 NUMA 节点
numactl --cpunodebind=nodes program
--physcpubind:将进程绑定到某个核心(Processor)上
numactl --physcpubind=<cpu> <program>
# cpu: /proc/cpuinfo 中的的 processor ID
# program: 应用程序
--localalloc:永久性严格指定只能在当前 NUMA 节点分配本地内存
numactl --localalloc python test.py
--preferred:在可能的情况下弹性从指定的 NUMA 几点上分配内存
numactl --preferred=<node>
# node: NUMA 节点 ID
# e.g.
numactl --preferred=0 python test.py
设定 SMP IRQ Affinity
中断处理也具有亲和性调度属性 smp_affinity,用于指定运行 IRP 对应的 ISR 的 CPU。smp_affinity 是一个十六进制位掩码,保存在 /proc/irq/IRQ_NUMBER/smp_affinity 文件中,可以以 root 用户权限查看并修改。
查看系统的中断处理状态:/proc/interrupts 文件列出了每个 I/O 设备对应到每个 Processor 上的中断次数、类型,以及接收中断的驱动程序列表。
[root@control01 ~]# cat /proc/interrupts
CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU7
0: 104 0 0 0 0 0 0 0 IO-APIC-edge timer
...
56: 10810 0 0 0 0 0 0 4060240 PCI-MSI-edge vmw_pvscsi
...
57: 20342 30923 33789 25533 46977 64504 78884 70780 PCI-MSI-edge ens192-rxtx-0
58: 5162 6797 10395 11019 17324 19285 21365 24282 PCI-MSI-edge ens192-rxtx-1
59: 14154 21925 28098 25550 48416 46239 59652 67793 PCI-MSI-edge ens192-rxtx-2
60: 429 836 924 1155 1917 2304 2227 3131 PCI-MSI-edge ens192-rxtx-3
61: 6667 16537 23922 20526 34824 38050 48226 43089 PCI-MSI-edge ens192-rxtx-4
62: 218 617 1149 1235 2559 2551 2098 3710 PCI-MSI-edge ens192-rxtx-5
63: 36892 78273 78853 27126 78559 55956 68976 107141 PCI-MSI-edge ens192-rxtx-6
64: 3027 6627 7506 6994 12081 13225 14441 19625 PCI-MSI-edge ens192-rxtx-7
65: 0 0 0 0 0 0 0 0 PCI-MSI-edge ens192-event-8
...
上面截选了计时器 timer、VMware PVSCSI 驱动程序以及 ens192 网卡设备驱动程序在每个 Processor 上的中断处理数据。可以看见,ens192 在 8 个 Processor 上都有中断处理,这是 IRQ 负载均衡器 irqbalance 在发生着作用,但是这种均衡在某些高性能应用场景中或许并不是一个好的现象。例如在 DPDK 场景中,应该将网卡设备绑定到指定的 CPU 核上,加快采集处理速度;又例如在数据库服务器场景中,应该把磁盘控制器驱动绑到一个 CPU 核上、加快数据库操作响应速度。
修改指定 IRQ Number 的 smp_affinity:
[root@control01 ~]# service irqbalance stop
[root@control01 ~]# cat /proc/irq/57/smp_affinity
04
[root@control01 ~]# echo 01 > /proc/irq/57/smp_affinity
[root@control01 ~]# cat /proc/irq/57/smp_affinity
01
手动指定 IRQ 亲和性首先需要关闭 irqbalance。但需要注意的是,在大部分场景中,irqbalance 提供的中断分配优化都是可以起到积极作用的。irqbalance 会自动收集系统数据来分析出使用模式,并依据系统负载状况将工作状态调整为以下两种模式:
- Performance mode:irqbalance 会将中断尽可能均匀地分发给各个 CPU 的 Core,以充分提升性能。
- Power-save mode:irqbalance 会将中断处理集中到第一个 CPU,保证其它空闲 CPU 的睡眠时间,降低能耗。
硬件中断处理
硬件中断是一种硬件设备(e.g. 网卡、磁盘控制器、鼠键、串行适配卡等)和 CPU 通信的方式,让 CPU 能够及时掌握硬件设备发生的事件,并视乎于中断类型决定是否放下当前任务,尽快处理紧急的硬件设备事件(e.g. 以太网数据帧到达,键盘输入)。
对于计算机系统而言,中断的本质是一个电信号,称为中断请求信号 IRQ。操作系统为每个硬件设备分配一个 IRQ Number,以此来区分发出中断的设备类型。IRQ Number 又会映射到内核中断服务路由列表(ISR)中的一个服务清单,操作系统就是通过这样的方式,将硬件设备和具体需要在处理器上运行的驱动程序服务关联起来。
硬件中断是内核调度优先级最高的任务类型之一,所以硬件中断通常都伴随着任务切换,将当前任务切换为中断上下文。显然,大量的中断处理,尤其是硬件中断处理会非常消耗 CPU 资源。并且在多处理器计算平台中,每个处理器都有机会处理硬件中断,所以将中断处理绑定到指定的处理器上,可以有效提高系统性能。详细内容我们在后面继续讨论。
上下文切换
你可能会认为使用多线程的系统一定会比使用单线程的系统执行速度快,其实未必,多处理器系统中的多线程同样会带来各种各样的性能开销问题,例如线程竞争(e.g. 竞争 I/O 设备,竞争锁)、例如频繁的线程上下文切换(Context Switch)。这些都是调度器无法处理的,应用多线程需要付出的代价。
如果当前进程(当前正在处理器上运行的进程)因为时间片用完、阻塞或被抢占,调度器会将处理器的使用权交给另一个进程,这个过程就叫做进程切换。
在处理器执行进程任务期间,当前进程的信息被存储在处理器的寄存器和高速缓存(Cache)中,当前进程被加载到寄存器的数据集被称为上下文(Context)。
一个进程的上下文可以分为以下三个部分:
- 用户级上下文: 正文、数据、用户堆栈以及共享存储区
- 寄存器上下文: 通用寄存器、程序寄存器、处理器状态寄存器、栈指针
- 系统级上下文: 进程描述符 task_struct、内存管理信息(mm_struct/vm_area_struct/pgd/pte)、内核堆栈
在进程切换过程中,会先当前进程的上下文会被存储在一个特定的区域(进程描述符或内核堆栈区域),然后把下一个要运行的进程的上下文恢复到寄存器。这个过程就是上下文切换。
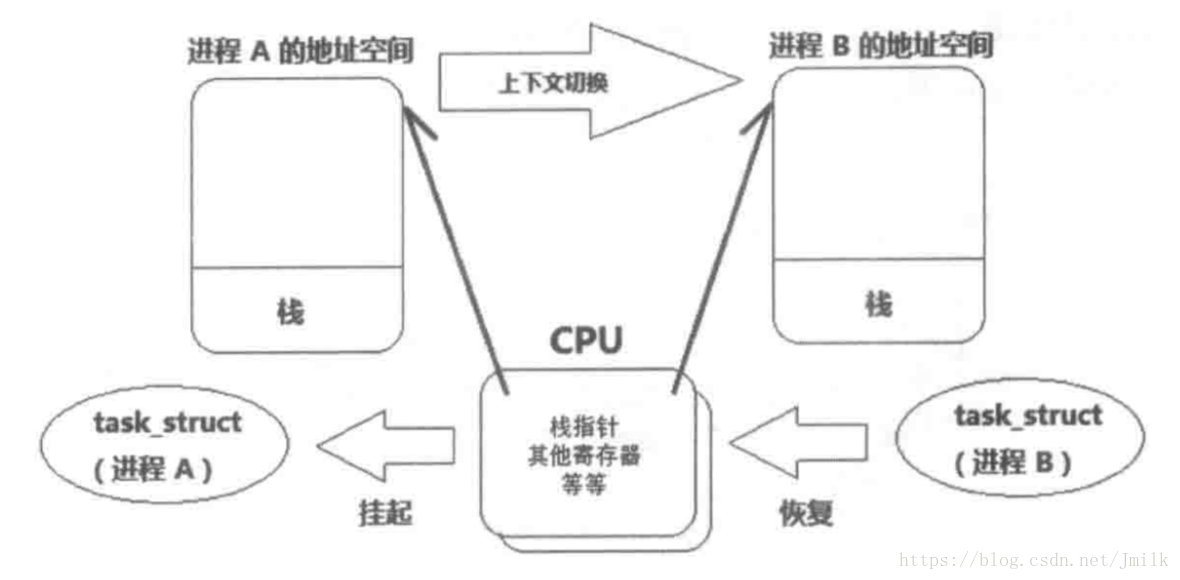
根据不同的应用程序会存在不同级别的进程上下文,但大致上每一次进程的上下文切换都会伴随着刷新处理器的寄存器和高速缓存以便释放空间给下一个进程,这样的动作势必会导致处理器性能的下降。如果切换的不是进程而是线程的话,因为线程的上下文不包括内存地址空间、MMU 等,所以线程的上下文切换只需要切换必要性奥寄存器即可,效率会比进程快上不少。
但需要注意的是,如果是同一进程内的多线程切换的开销,正如上面所说会比较低。但如果切换的对象是来自两个不同进程内的线程的话,就会发生由线程切换导致进程切换的情况。
运行模式切换
上文我们提到过,Linux 的线程模式是一个用户线程会映射到一个内核线程。又因为线程切换是只能在内核态进行,所以用户线程切换不仅仅会存在上下文切换,还存在线程的运行模式切换,即从用户态与内核态之间的切换。模式切换同样会对线程的执行性能造成影响,不过与上下文切换相比会更容易些,因为模式切换最主要的任务只是切换线程寄存器的上下文。
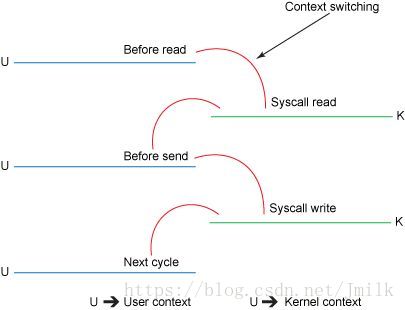
如何选择多线程的数量
设定线程池大小的核心原则是「在最大化利用 CPU(高吞吐)的同时尽量减少线程切换和管理的性能耗损(低延时)」。首先可以根据任务的执行时长,将任务划分为长任务与短任务两大类。
对于短任务,显然是要求线程数量尽量少,如果线程太多,那么线程切换和管理的开销就比较大了。如果这些开销的时间比任务本身执行的时间都要长的话,那么多线程反而让系统性能更加低了。要求线程数量尽量少,那多少为少?这取决于实际的业务情况,大体上有一些计算的公式,这里先不展开。
对于长任务,则还要再细分一下类型。我们知道进程的时间片大致可以分为 CPU 执行周期和 I/O 执行周期。一般高 I/O 的进程 CPU 周期就短,长 CPU 周期进程的 I/O 次数就少。所以可以将长任务再细分为:
-
I/O 消耗型(I/O 密集型):任务的大部分时间都在提交 I/O(例如:访问磁盘,访问内存,输入输出)请求或者等待 I/O 请求。
-
处理器消耗型(CPU 密集型):处理器的大部分时间都在做计算、逻辑判断等运算动作,任务没有太多的 I/O 需求,除非被处理器抢占,否则任务会不停地运行。
两种业务类型本质上是高吞吐和低延时的对立统一。如果想要高吞吐量,那就想办法让 Processor 的数量更多,任务的切换就更频繁;如果想要降低任务的延时,快速响应,那么必然要想办法让任务占用处理器的时间更长,减少任务切换等的无效耗时。对于 Linux 上的线程来说,假设拥有 N 个 Processor,可以按照下列常规原则来设置线程池:
- CPU 密集型场景,线程池大小设置为 N+1
- I/O 密集型场景,线程池大小设置为 2N+1
这里多说两句,将超线程的性能问题串联起来。在超线程的帮助下,两个被调度到同一个 Core 下不同 Siblings Thread 的 Worker,由于 Siblings Thread 共享 Cache 和 TLB(Translation Lookaside Buffer,转换检测缓冲区),所以能够有效降低 Workers 线程切换的开销。同时,在某个 Worker 不忙的时候,超线程允许其它的 Worker 先使用物理计算资源,以此来提升 Core 的整体吞吐量,非常适合应用到 I/O 密集型的场景。但由于 Workers 间会争抢 Core 的物理执行资源,导致单个 Worker 执行的延时增加,响应速度就不如当初了。在 CPU 密集型场景中,当发生了超线程竞争,超线程计算能力大概是关闭超线程的 60% 左右(个人数据,仅供参考)。

 博客专家
博客专家