学习视频:https://www.bilibili.com/video/BV1Y7411d7Ys?p=8&spm_id_from=pageDriver&vd_source=2314316d319741d0a2bc13b4ca76fae6
本节内容是在pytorch里怎么构造Dataset和DataLoader?
Dataset和DataLoader是帮助我们加载数据的两个重要工具类
Dataset是构造数据集【应支持索引,用下标操作把数据集里的样本快速拿出】;
DataLoader的目标是拿出一个mini-batch这样一组数据来供我们训练时快速使用。
xy = np.loadtxt('diabeters.csv.gz', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:,:-1])
y_data = torch.from_numpy(xy[:,[-1]])
.....
for epoch in range(100):
# 1.forward
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
# 2.backward
optimizer.zero_grad()
loss.backward()
# 3.update
optimizer.step()
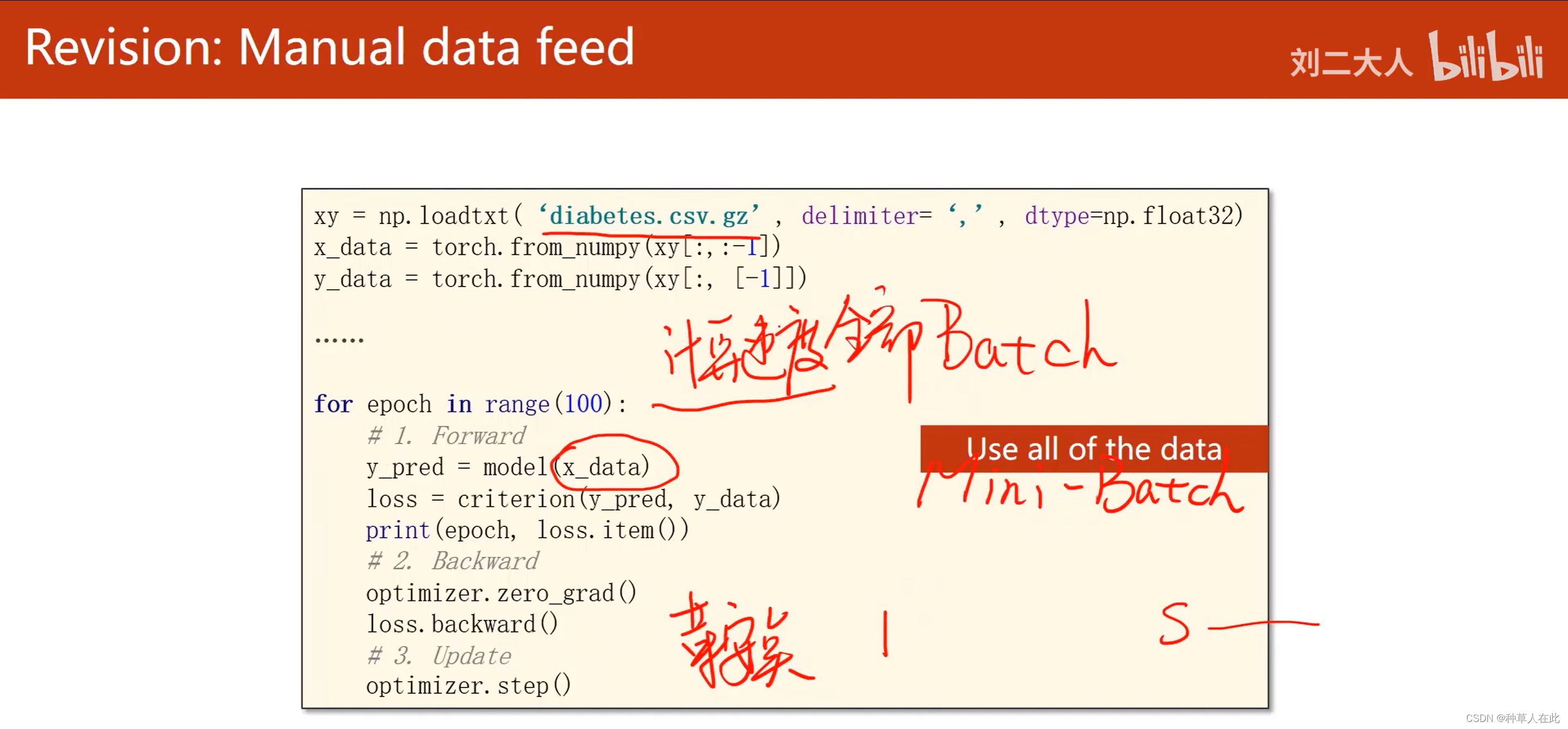
之前讲过梯度下降时有几种选择:1.使用Batch 全部数据都用,这样会得到比较好的计算速度,但是性能上会遇到一些问题;2.只用一个样本SGD,这样会得到比较好的随机性,会帮助我们跨越优化中所遇到的鞍点,性能好但时间长。
所以,在神经网络中会用mini-batch来均衡性能和时间上的平衡。
在使用mini-batch时需要明白的几个概念:Epoch、Batch-size、iteration

在使用mini-batch的训练方法后,训练循环变成嵌套循环,外层用来表示epoch训练的周期,内层对batch进行迭代。epoch:当所有的训练样本都进行一次前向、反向传播,整个过程就叫一个epoch,即把所有样本都参与训练就叫做一个epoch。batch-size:每次训练时,所用的样本数【进行一次前向、反向、更新的样本数量】。iteration:batch分了多少个,内层迭代一共执行了多少次。比如,现有10000样本,假如每次mini-batch的batch-size是1000个,则iteration=10.
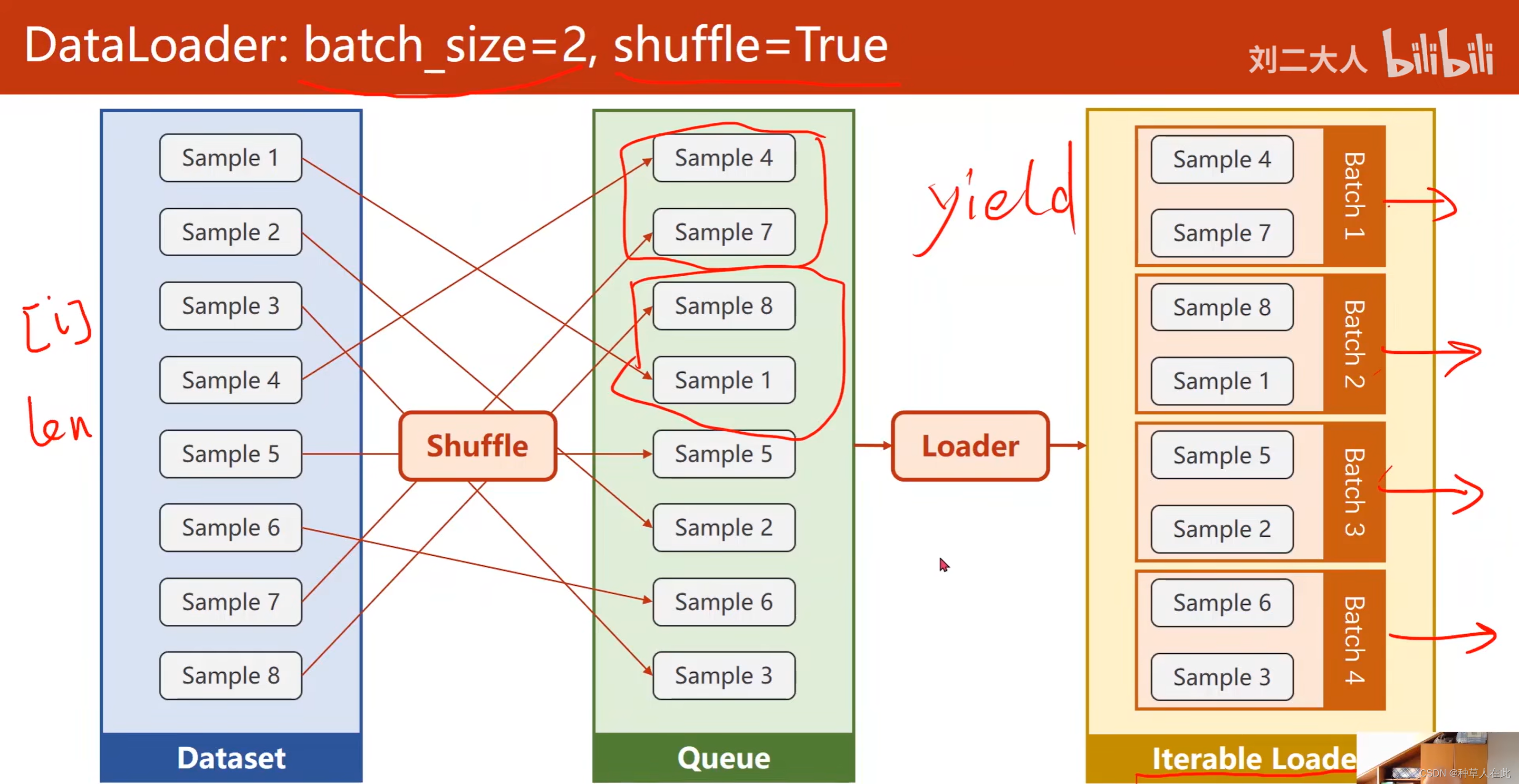 mini-batch训练要确定一些重要的参数,batch_size是必须指定的,另外,为了提高数据样本的随机性,可以选择对数据集shuffle(打乱顺序),这样每次生成mini-batch里的数据集里面的数据样本都是有随机性的。即每一次epoch拿到的训练数据集都是打乱顺序的。
mini-batch训练要确定一些重要的参数,batch_size是必须指定的,另外,为了提高数据样本的随机性,可以选择对数据集shuffle(打乱顺序),这样每次生成mini-batch里的数据集里面的数据样本都是有随机性的。即每一次epoch拿到的训练数据集都是打乱顺序的。
DataLoader的工作是数据集需要支持索引操作,即DataLoader能访问到里面的每一个元素,还需要知道它的长度。
只要Dataset能提供这样两个信息,将来DataLoader就可以对Dataset进行自动的小批量的数据集生成。
第一步是做shuffle(打乱),就是打乱顺序,增加随机性,第二步是进行分组,Loader,因为batch_size设为2,所以就是2个为一组,分成若干个组,然后做成可迭代的Loader。 iterable Loader 将来可用for- in 循环把其中每一个batch用循环依次拿出来。以上就是DataLoader 的功能。
如何代码实现Dataset和DataLoader
import torch
from torch.utils,data import Dataset
from torch.utils.data import DataLoader
# 自己定义的类 Diabetes 糖尿病
class DiabetesDataset(Dataset): # 类DiabetesDataset是继承Dataset
def __init__(self):
pass
def __getitem__(self, index):
pass
def __len__(self):
pass
dataset = DiabetesDataset()
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
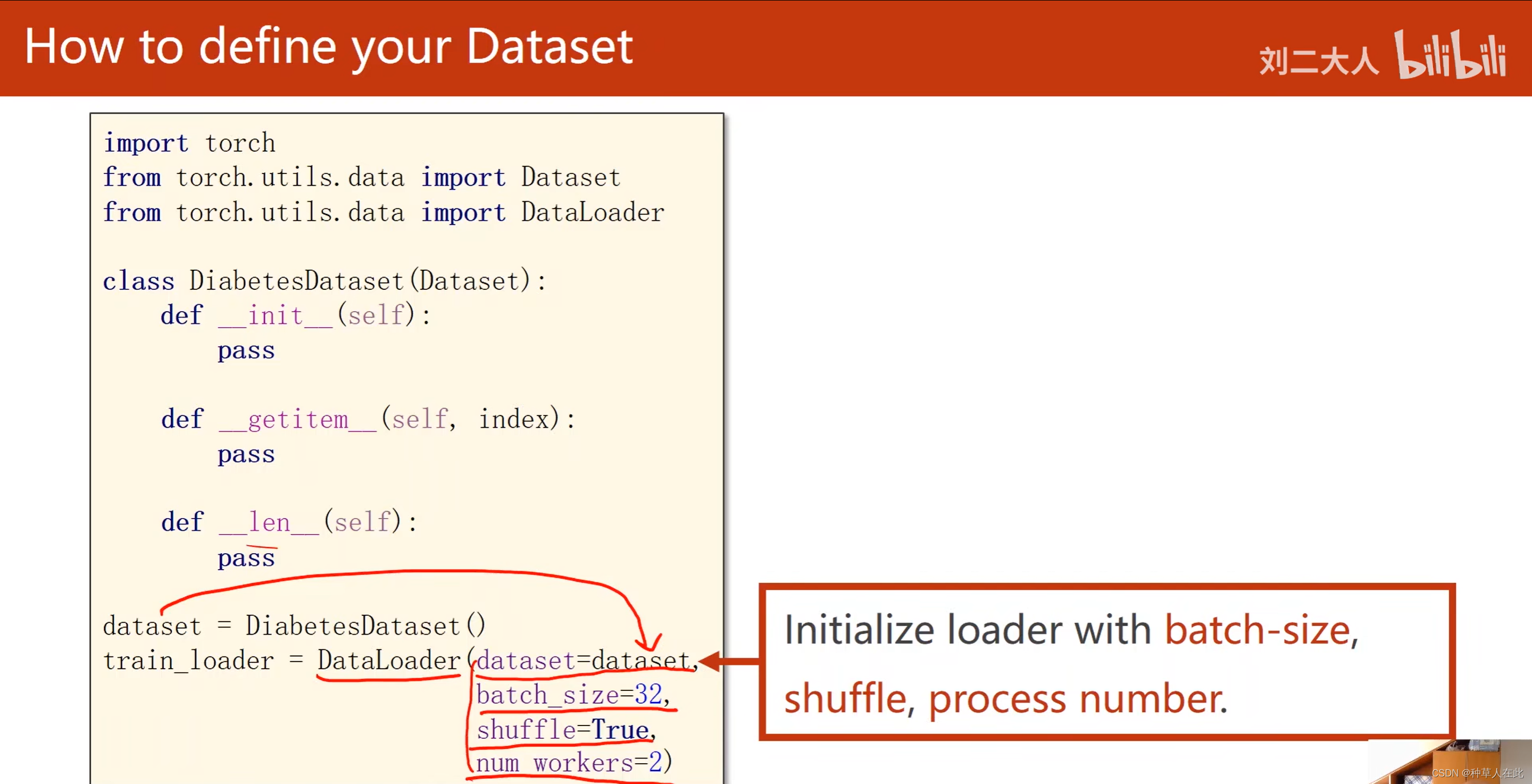
1.torch的utils【工具】下的data【数据工具】提供了两个类:Dataset、DataLoader;Dataset【抽象类】,不能实例化,只能被其他子类继承。所以要想定义Dataset,必须要由dataset来继承构造自己的自定义的类。DataLoader,可以实例化,这个类是用来加载数据的,比如,shuffle、做batch-size。
2.魔法方法getitem是实例化DiabetesDataset这个类后,这个对象能支持下标操作,通过一个索引把index条数据拿出来。魔法方法len,使用len(数据集)将数据条数进行返回。
3.定义好DiabetesDataset,就用自定义的类把它实例化成一个数据对象dataset,它包含我们的数据集,它的功能是getitem ,用索引将数据集的某一个数据拿出来。
4.在构造数据集时,一般来说有两种选择:1.把所有数据都加载进来,读到内存里,每次使用getitem时,把构造好的数据集【如矩阵、张量】的第i个样本传出去,这种方法适合数据集本身容量不大。比如糖尿病的数据集。2.x和y都是大矩阵如图像、语音这种无结构数据。数据大,需要考虑能否全部加载到内存中。
5.DataLoader是pytorch提供的一个加载器(传送数据集,一个小批量的容量多少,shuffle(是否打乱),读数据时是否使用多线程)
注意:0.4时多进程出错问题;如果这样设置了num_workers后,它在window下会遇到一些问题,直接用train_loader去训练,会出现报错。因为在windows下和linux下多进程的库不一样,windows下用spawn创建新进程,linux下用fork创建新进程。所以需要把loader迭代代码封装起来,封装到if语句或函数里,但不能顶格写程序里

train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
......
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
......
由上改下:

train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
......
if __name__=='__main__':
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
# 1.prepare data
接下来看一下Diabetes Dataset的实现
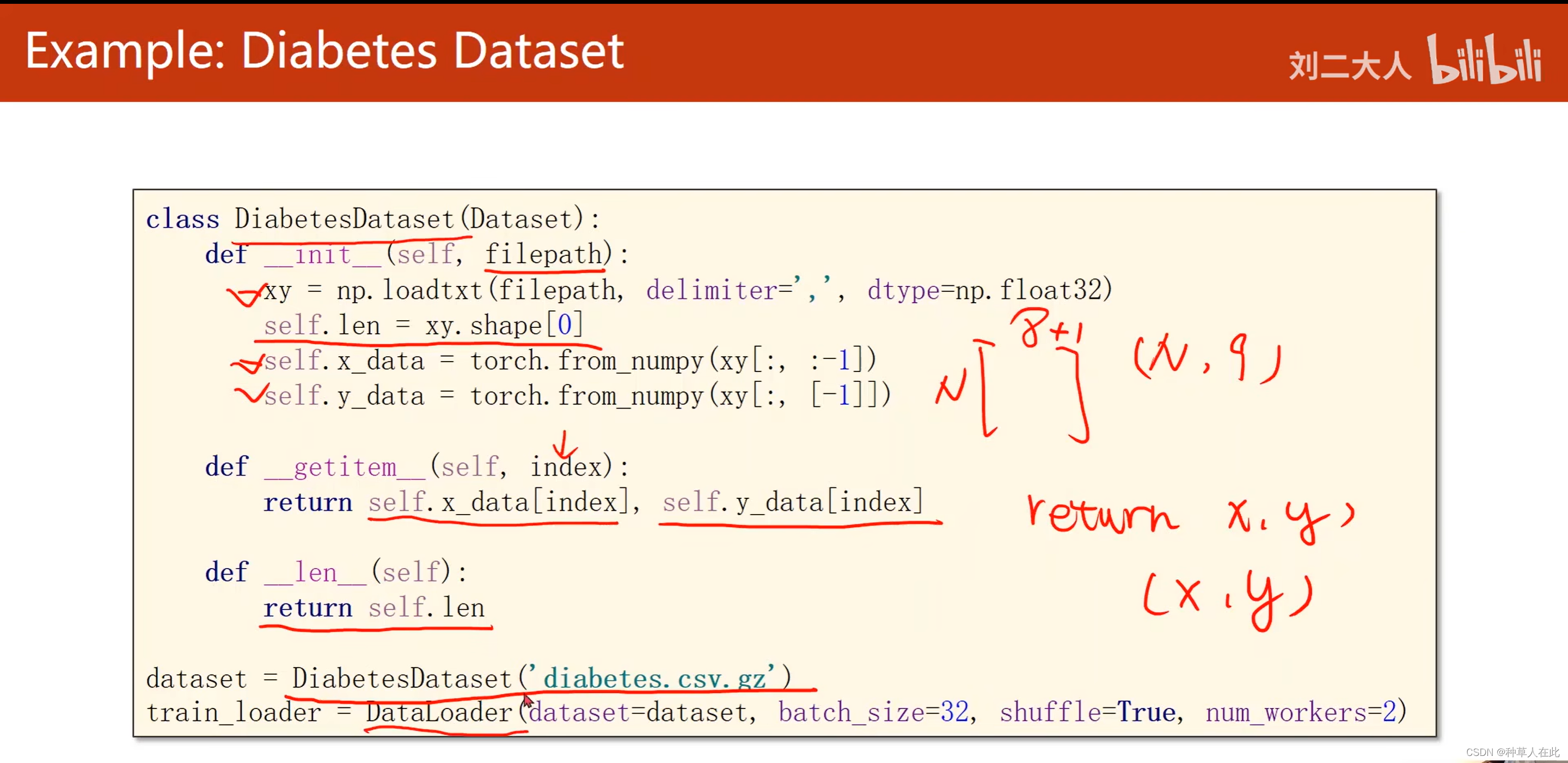
# 自己定义的类 Diabetes 糖尿病
class DiabetesDataset(Dataset): # 类DiabetesDataset是继承Dataset
def __init__(self,filepath):
#把filepath读进来,然后用逗号作为分隔符,然后读取一个32位的浮点数
xy = np.loadtxt(filepath, delimiter=',',dtype=np.float32)
#xyS是N行9列,通过shape得到的就是(N,9)的元组,然后通过取它第0个元素,把N的值拿出来,就知道数据集有多少个了
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1]) # x_data要前八列
eslf.y_data = torch.from_numpy(xy[:, [-1]])# y_data要最后一列
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
# 接下来就是构造数据对象
dataset = DiabetesDataset('diabetes.csv.gz')#把数据路径送过去
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)# 用DataLoader构造加载器,起名 train_loader
首先构造函数需要filepath【你的文件来自什么地方】,然后把N的值拿出来,就知道数据集有多少个了,所以后满len函数里把len返回即可,getitem函数实现也容易,因为在实现DiabetesDataset数据集时,因为数据集很小,所以把它全部加载到内存里,所以数据一直保存在内存的x_data、y_data里,所以根据索引返回数据样本时,只需把x对应样本和y对应样本返回就行。returnx,y表示返回的是元组(x,y),x和y分开,后面训练时方便。构造数据对象把数据文件的路径送过去,然后用DataLoader构造加载器。
data_loader在训练周期里的使用
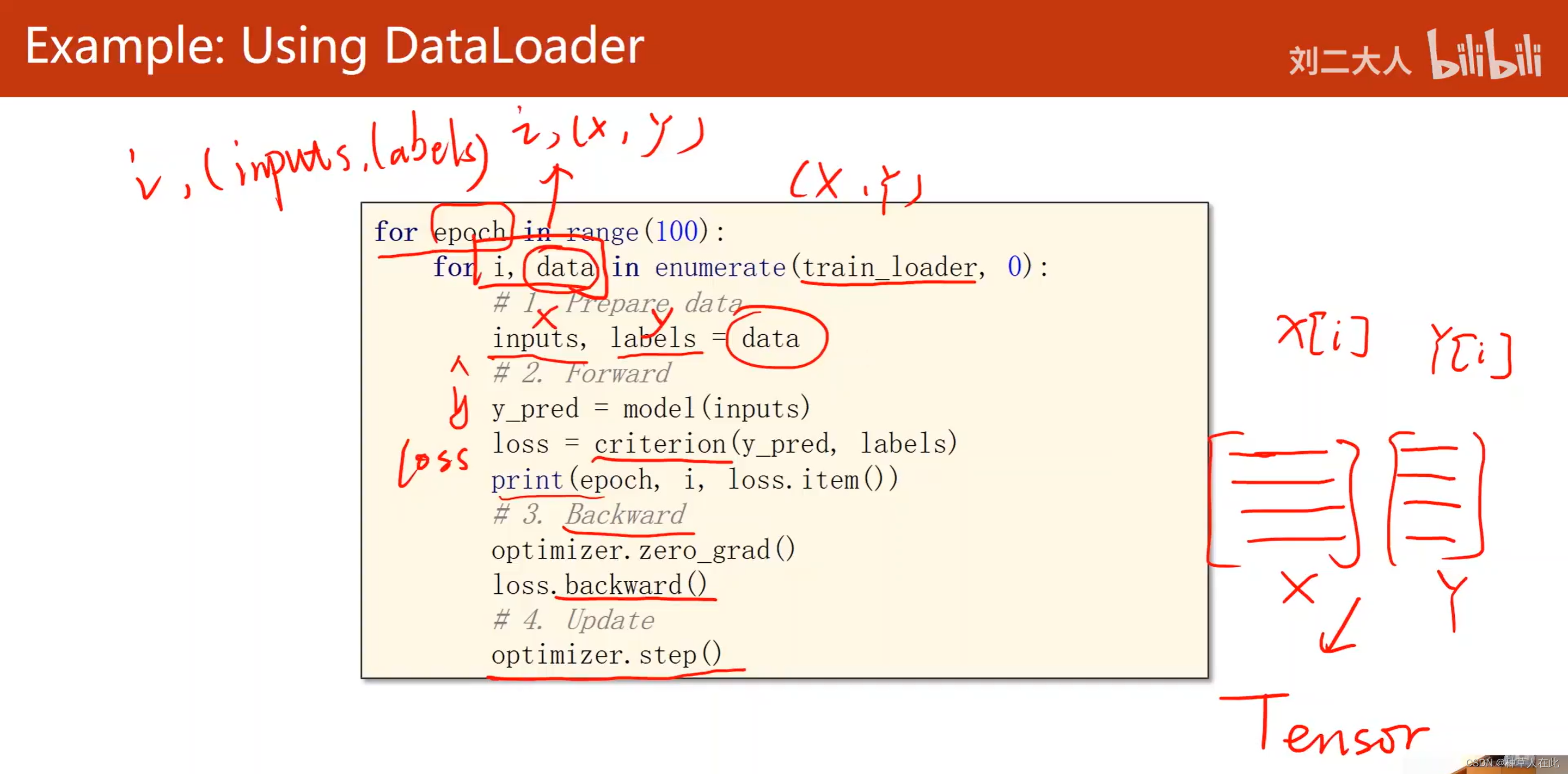
training cycle变成了两重循环,外重循环主要做epoch【所有数据跑一遍】,里面循环是直接对train_loader做迭代,用enumerate是为了获得当前是第几次迭代,train_loader
里面拿出来的是(x,y)元组,放到data里,训练开始之前先把输入x和标签y从data拿出来。
注意:因为dataset每次拿过来的都是 x[i]【x的第i行】,y[i],所以data_loader拿到一组后,dataset每次能拿到一个数据样本,dataloader每次根据mini-batch的数量,把x、y变成矩阵,然后loader里面会自动地把他们转为Tensor,所以在这里不需要转Tensor,直接拿来用就行,这时地inputs、labels都是张量。
next,前馈,先把优化器权重都清零,然后做反向传播,最后进行一次优化更新。
注意:它和之前的训练周期没大区别,唯一区别就是在一开始要把loader里的数据解成x和y。
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
# 1.prepare data
inputs, labels = data
# 2.Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
#3.Backward
optimizer.zero_grad()
# 4.Update
optimizer.step()
完整代码:
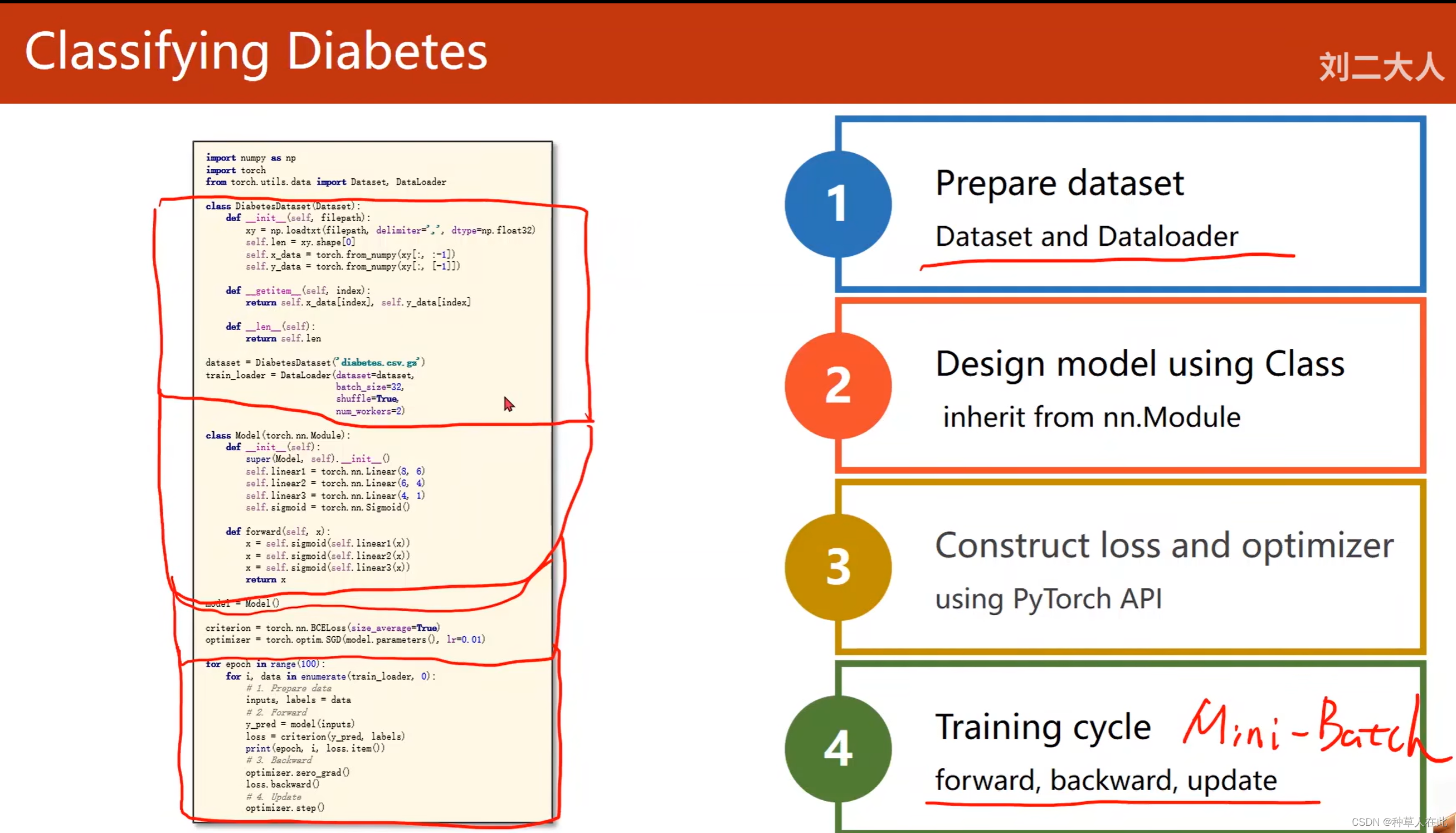
用之前训练的架构【四步走】,进行扩充之后,就能使用mini-batch对数据集里的数据进行数据训练。准备数据集——设计模型——构造损失和优化器——训练。主要改动就是第一步、第四步。
第一步:不再是加载全部数据,而是构造了dataset和data_loader。
第四步:把原来的一次循环变成嵌套的循环,以使用mini-batch。
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
# 1.准备数据集
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv')
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
# 2.构造模型[就是上一讲构造的模型]
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
# 3.构造损失和优化器
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
#4.训练周期
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
# 1.prepare data
inputs, labels = data
# 2.forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
# 3backward
optimizer.zero_grad()
loss.backward()
#4.update
optimizer.step()
在我运行时出现了如下错误:

这是在准备数据集时,num_workers=2 并行处理出现的问题,如果你的电脑没有并行跑程序,应该不会出错;如果你电脑正在并行计算,它会报错,只需要将num_workers=0即可。
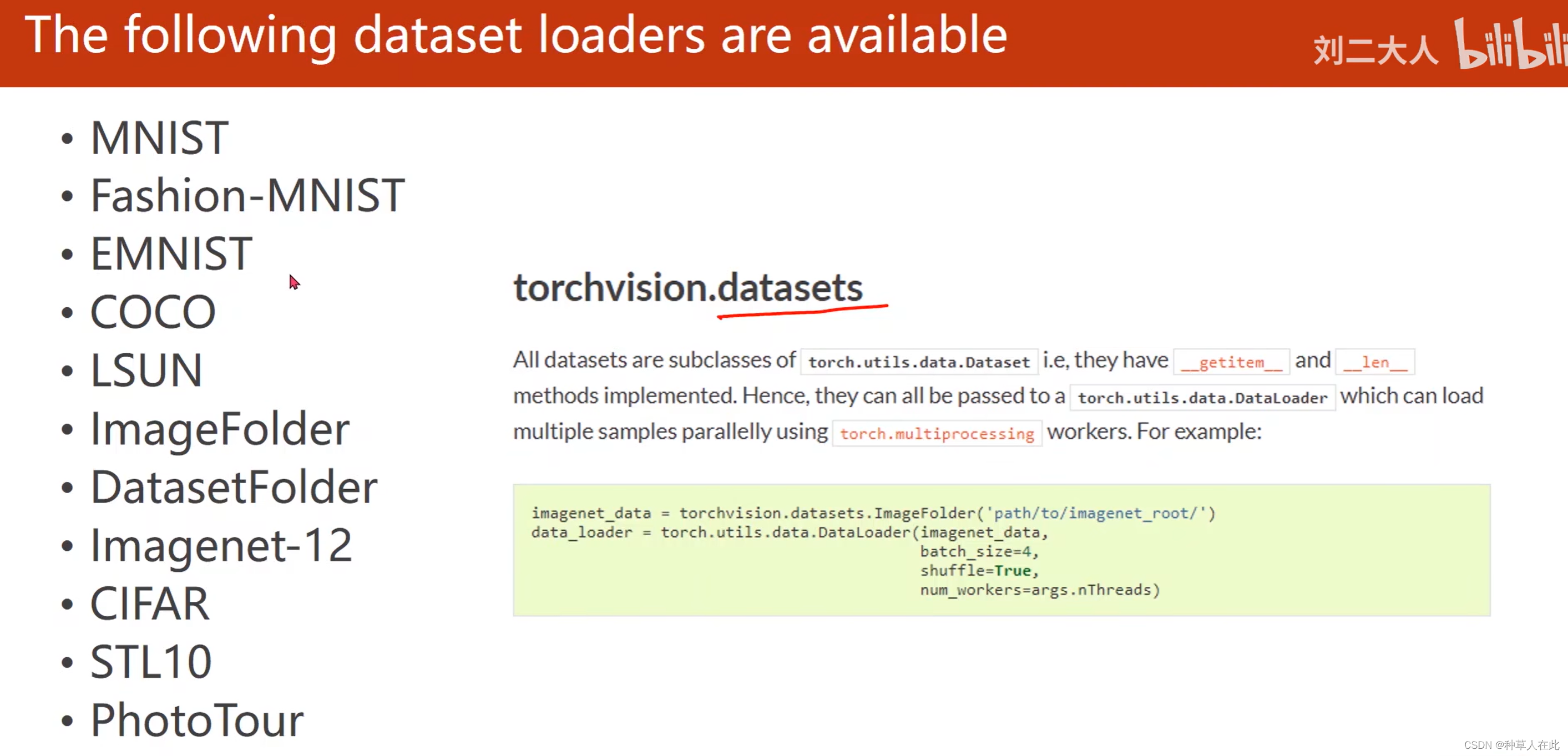
torch.vision里内置了好多数据集,都可使用,torchvision.datasets里提供的所有数据集都是Dataset的子类,所以它们有__getitem__() len()这些方法的实现,所以它们可用DataLoader进行加载,并用多线程加速。
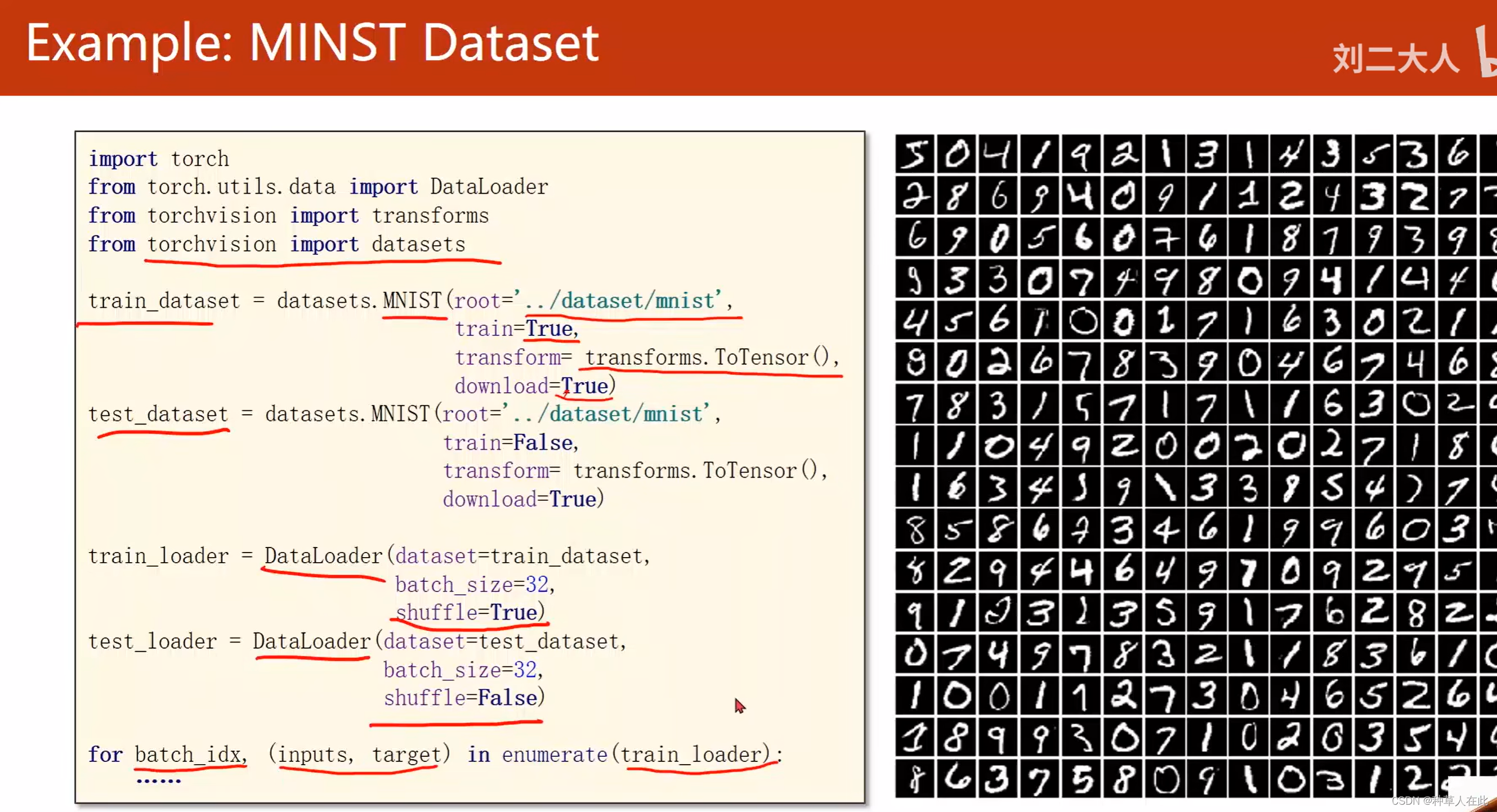
要使用MNIST数据集,只需从torchvision里把dataset导入进来,dataset里就有一个MNIST类,可用这个类来构造MNIST实例。构造两个DataLoader,其中之一的数据集来自训练集;另一个来自测试集,然后循环。
作业:
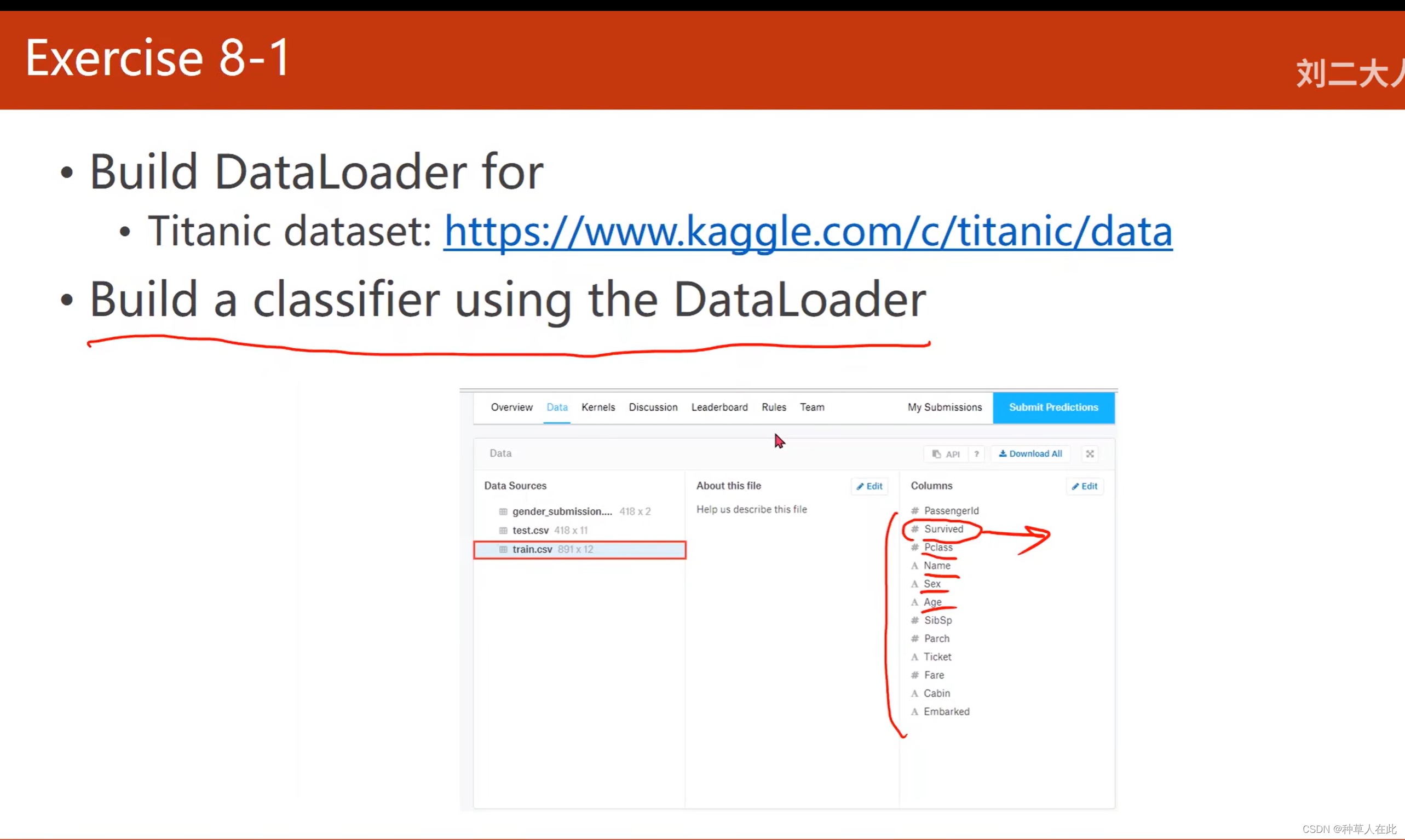
去kaggle网站,最基本的泰坦尼克数据集,建立分类器,使用DataLoader分类,训练目标:这个乘客是否存活,测试机无标签。上传要求格式文件,获得评分。加油!!!
