设置 Setup
产品评论文本
情感(正面/负面)Sentiment (positive/negative)
识别情绪类型
从客户评论中提取产品和公司名称
一次完成多项任务
Inferring topics 推断主题
为某些主题制作新闻提醒
Inferring 推理
在本课中,您将从产品评论和新闻文章中推断情绪和主题。
设置 Setup
import openai
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.getenv('OPENAI_API_KEY')
def get_completion(prompt, model="gpt-3.5-turbo"): # Andrew mentioned that the prompt/ completion paradigm is preferable for this class
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0, # this is the degree of randomness of the model's output
)
return response.choices[0].message["content"]产品评论文本
以下用三重反引号分隔的产品评论的情感是什么?
审查文本:```我的卧室需要一盏漂亮的灯,这盏灯有额外的储物空间,而且价格不太高。很快就知道了。我们的灯在运输过程中断了,公司很高兴地送来了一根新的。几天之内也来了。很容易放在一起。我有一个缺失的部分,所以我联系了他们的支持,他们很快就帮我找到了缺失的部分!在我看来,Lumina 是一家关心客户和产品的伟大公司!```
lamp_review = """
Needed a nice lamp for my bedroom, and this one had \
additional storage and not too high of a price point. \
Got it fast. The string to our lamp broke during the \
transit and the company happily sent over a new one. \
Came within a few days as well. It was easy to put \
together. I had a missing part, so I contacted their \
support and they very quickly got me the missing piece! \
Lumina seems to me to be a great company that cares \
about their customers and products!!
"""情感(正面/负面)Sentiment (positive/negative)
prompt = f"""
以下用三重反引号分隔的产品评论的情感是什么?
审查文本:'''{lamp_review}'''
"""
response = get_completion(prompt)
print(response)chatgpt 输出:
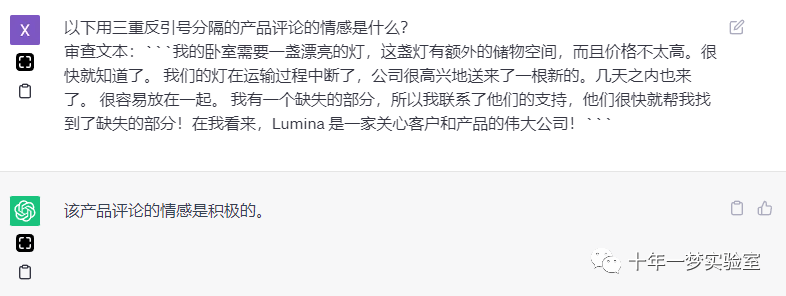
该产品评论的情感是积极的。
prompt = f"""
以下用三重反引号分隔的产品评论的情感是什么?
用一个词给出你的答案,“积极的”或“负面的”。
审查文本:: '''{lamp_review}'''
"""
response = get_completion(prompt)
print(response)chatgpt 输出:
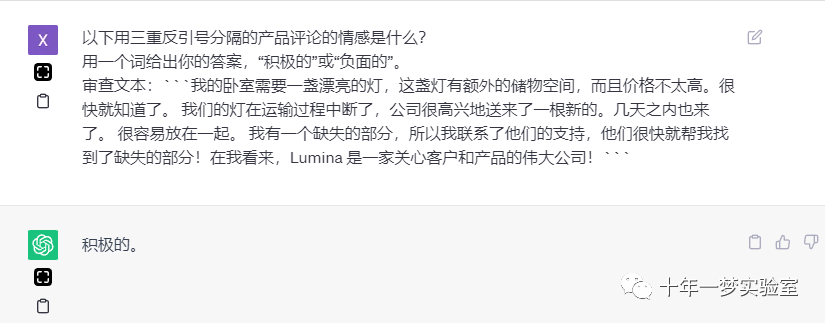
积极的。
识别情绪类型
确定以下评论的作者所表达的情绪列表。列表中包含的项目不超过五项。将您的答案格式化为以逗号分隔的词语列表。
审查文本:
prompt = f"""
Identify a list of emotions that the writer of the \
following review is expressing. Include no more than \
five items in the list. Format your answer as a list of \
lower-case words separated by commas.
Review text: '''{lamp_review}'''
"""
response = get_completion(prompt)
print(response)chatgpt 输出:
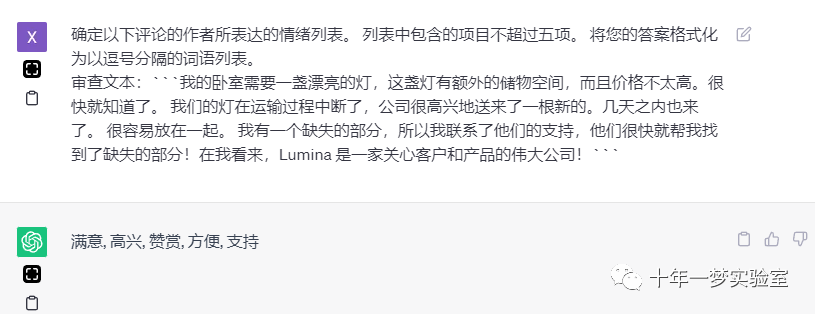
满意, 高兴, 赞赏, 方便, 支持
识别愤怒
以下评论的作者是否表达了愤怒?评论用三重反引号分隔。给出是或否的答案。
审查文本:
prompt = f"""
Is the writer of the following review expressing anger?\
The review is delimited with triple backticks. \
Give your answer as either yes or no.
Review text: '''{lamp_review}'''
"""
response = get_completion(prompt)
print(response)chatgpt 输出:
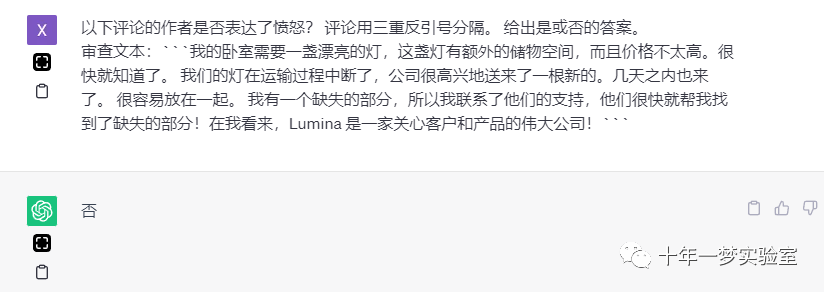
否
从客户评论中提取产品和公司名称
从评论文本中识别以下项目:
评论者购买的物品
制造该物品的公司
评论以三重反引号分隔。将您的回复格式化为以“商品”和“品牌”为键的 JSON 对象。如果信息不存在,请使用“未知”作为值。使您的响应尽可能简短。
审查文本:
prompt = f"""
Identify the following items from the review text:
- Item purchased by reviewer
- Company that made the item
The review is delimited with triple backticks. \
Format your response as a JSON object with \
"Item" and "Brand" as the keys.
If the information isn't present, use "unknown" \
as the value.
Make your response as short as possible.
Review text: '''{lamp_review}'''
"""
response = get_completion(prompt)
print(response)chatgpt 输出:

{
"商品": "灯",
"品牌": "Lumina"
}
一次完成多项任务
从评论文本中识别以下项目:
情绪(正面或负面)
审稿人是否表达了愤怒?(是或否)
评论者购买的物品
制造该物品的公司
评论用三重反引号分隔。将您的响应格式化为 JSON 对象,以“Sentiment”、“Anger”、“Item”和“Brand”作为键。
如果信息不存在,请使用“未知”作为值。使您的响应尽可能简短。将 Anger 值格式化为布尔值。
审查文本:
prompt = f"""
Identify the following items from the review text:
- Sentiment (positive or negative)
- Is the reviewer expressing anger? (true or false)
- Item purchased by reviewer
- Company that made the item
The review is delimited with triple backticks. \
Format your response as a JSON object with \
"Sentiment", "Anger", "Item" and "Brand" as the keys.
If the information isn't present, use "unknown" \
as the value.
Make your response as short as possible.
Format the Anger value as a boolean.
Review text: '''{lamp_review}'''
"""
response = get_completion(prompt)
print(response)chatgpt 输出:

{
"Sentiment": "正面",
"Anger": false,
"Item": "灯",
"Brand": "Lumina"
}
Inferring topics 推断主题
story = """
在政府最近进行的一项调查中,公共部门员工被要求对他们工作的部门的满意度进行评分。结果显示,NASA 是最受欢迎的部门,满意度为 95%。
美国国家航空航天局的一名员工约翰·史密斯对调查结果发表了评论,他说:“我对美国国家航空航天局名列前茅并不感到惊讶。这是一个与了不起的人和难以置信的机会一起工作的好地方。我很自豪能成为其中的一员 一个创新的组织。”
这一结果也受到了 NASA 管理团队的欢迎,主任汤姆约翰逊表示,“我们很高兴听到我们的员工对他们在 NASA 的工作感到满意。我们拥有一支才华横溢、敬业的团队,他们为实现我们的目标而不懈努力,很高兴看到他们的辛勤工作得到回报。”
调查还显示,社会保障局的满意度最低,只有 45% 的员工表示对自己的工作感到满意。政府已承诺解决员工在调查中提出的担忧,并努力提高所有部门的工作满意度。
"""
prompt = f"""
确定以下文本中正在讨论的五个主题,这些主题由三个反引号分隔。每个项目一两个词长。将您的回复格式化为以逗号分隔的项目列表。
文本示例:'''{story}'''
"""
response = get_completion(prompt)
print(response)chatgpt 输出:

NASA, 满意度, 员工评论, 管理团队, 社会保障局

为某些主题制作新闻提醒
topic_list = [
"nasa", "local government", "engineering",
"employee satisfaction", "federal government"
]“美国航空航天局”,“地方政府”,“工程”,
“员工满意度”、“联邦政府”
prompt = f"""
Determine whether each item in the following list of \
topics is a topic in the text below, which
is delimited with triple backticks.
Give your answer as list with 0 or 1 for each topic.\
List of topics: {", ".join(topic_list)}
Text sample: '''{story}'''
"""
response = get_completion(prompt)
print(response)确定以下主题列表中的每一项是否是以下由三个反引号分隔文本中的主题。
以列表的形式给出你的答案,每个主题用 0 或 1。
主题列表:['美国航空航天局',
'地方政府',
'工程',
'员工满意度',
'联邦政府']
文本示例:"""
在联邦政府最近进行的一项调查中,公共部门员工被要求对他们工作的部门的满意度进行评分。结果显示,NASA 是最受欢迎的部门,满意度为 95%。
美国国家航空航天局的一名员工约翰·史密斯对调查结果发表了评论,他说:“我对美国国家航空航天局名列前茅并不感到惊讶。这是一个与了不起的人和难以置信的机会一起工作的好地方。我很自豪能成为其中的一员 一个创新的组织。”
这一结果也受到了 NASA 管理团队的欢迎,主任汤姆约翰逊表示,“我们很高兴听到我们的员工对他们在 NASA 的工作感到满意。我们拥有一支才华横溢、敬业的团队,他们为实现我们的目标而不懈努力,很高兴看到他们的辛勤工作得到回报。”
调查还显示,社会保障局的满意度最低,只有 45% 的员工表示对自己的工作感到满意。政府已承诺解决员工在调查中提出的担忧,并努力提高所有部门的工作满意度。
chatgpt 输出:

[1, 0, 0, 1, 1]
python调用API返回值:
nasa: 1
local government: 0
engineering: o
employee satisfaction: 1
federal government: 1
topic_dict = {i.split(': ')[0]: int(i.split(': ')[1]) for i in response.split(sep='\n')}
if topic_dict['nasa'] == 1:
print("ALERT: New NASA story!")Output:
ALERT: New NASA story!
备注:用程序调用API(比如python)相对通过chatgpt对话会很灵活。可以定制各种需求。
The End