文章目录
standalone模式
1.下载flink压缩包
点击下载:flink1.7.2
2.上传到机器
自己上传
3.解压
tar -zxvf flink-1.7.2-bin-hadoop27-scala_2.11.tgz -C /opt/
4.配置环境变量
vim /etc/profile
# 写入自己flink解压路径等
export FLINK_HOME=/opt/flink-1.7.2/
export PATH=${
FLINK_HOME}/bin:$PATH
保存退出,刷新环境变量
source /etc/profile
5.修改 ./conf/flink-conf.yaml 文件
cd /opt/flink-1.7.2/conf
vim flink-conf.yaml
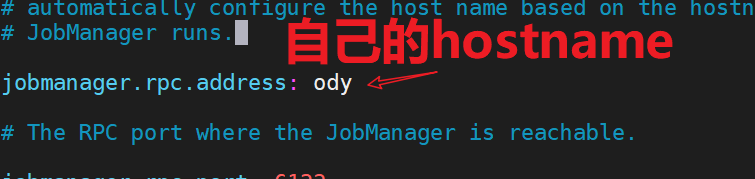
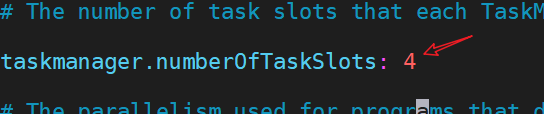
配置savepoint路径,可以本地路径或hdfs路径

6.修改 /conf/slave文件
vim slave
多节点,就指定多个

7.启动测试查看
start-cluster.sh
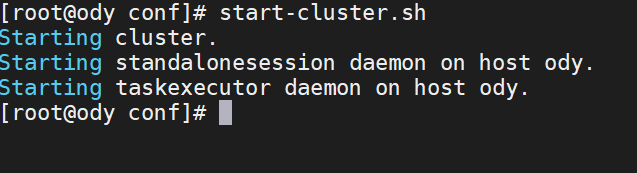
会启动两个服务:
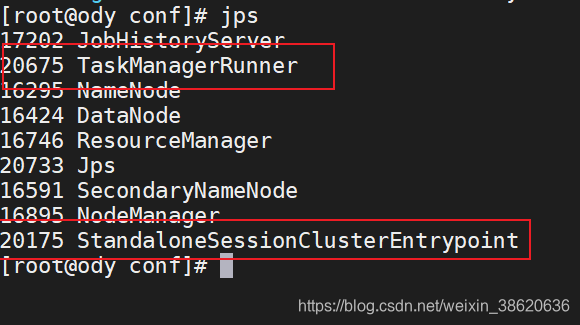
去flink页面看一下吧:
http://192.168.8.120自己的ip:8081/

Yarn模式
以Yarn模式部署Flink任务时,要求Flink是有Hadoop支持的版本,Hadoop环境需要保证版本在2.2以上,并且集群中安装有HDFS服务。
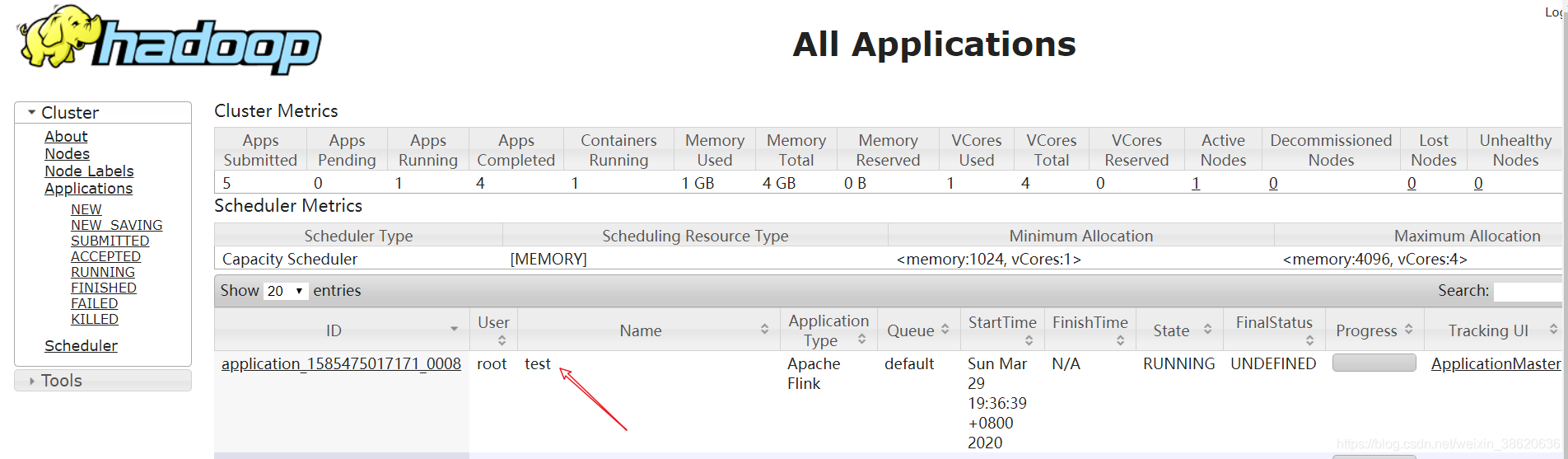
1)启动hadoop集群(略)
2)启动yarn-session
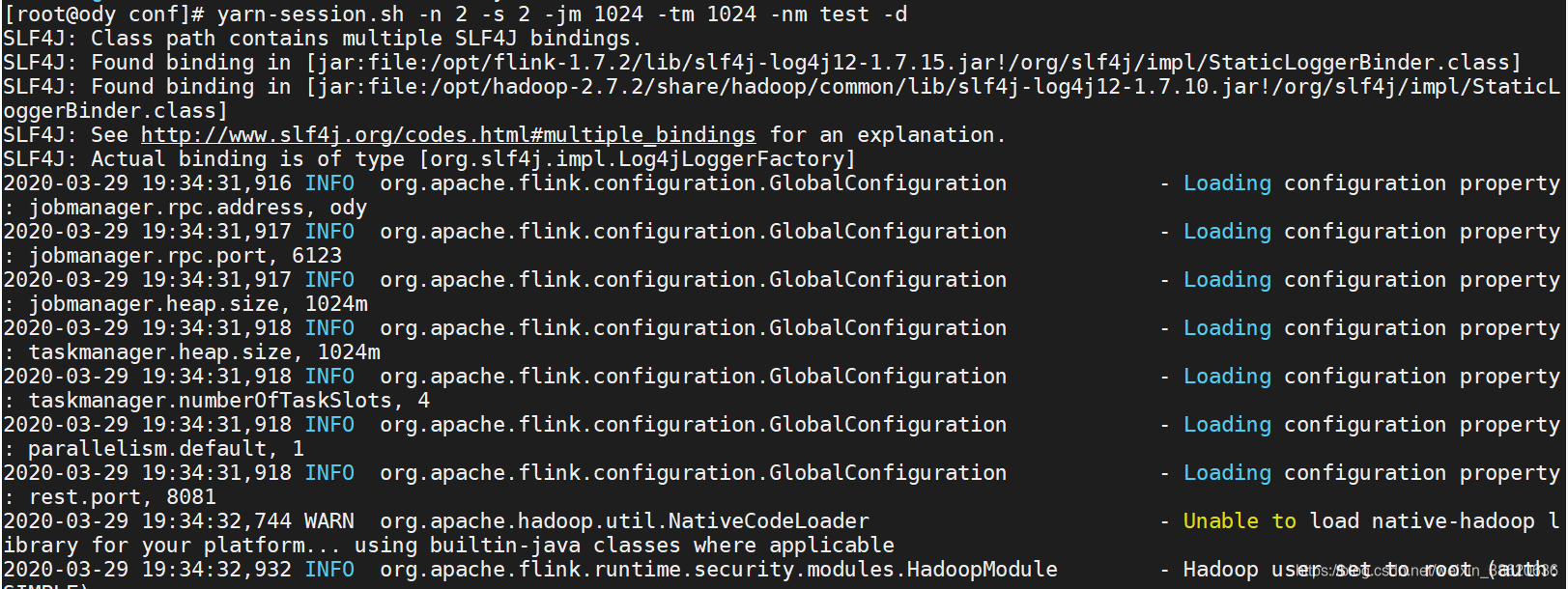
yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
参数解释:
-n(–container):TaskManager的数量。
-s(–slots): 每个TaskManager的slot数量,默认一个slot一个core,默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余。
-jm:JobManager的内存(单位MB)。
-tm:每个taskmanager的内存(单位MB)。
-nm:yarn 的appName(现在yarn的ui上的名字)。
-d:后台执行。