目录
转载处(个人用最新1.17.1测试)
http://www.mangod.top/articles/2023/07/26/1690349392449.html
依赖环境
操作系统:Rocky 8.8
提前安装JDK 8以上版本,JDK 只要不低于 1.8 就行。
https://mohen.blog.csdn.net/article/details/109465678
安装包下载地址
现在最新版本为 1.17.1
https://archive.apache.org/dist/flink/flink-1.17.1/flink-1.17.1-bin-scala_2.12.tgz
wget https://archive.apache.org/dist/flink/flink-1.17.1/flink-1.17.1-bin-scala_2.12.tgzFlink本地模式搭建
安装
解压安装包
tar -zxvf flink-1.17.1-bin-scala_2.12.tgz启动集群
进入到解压目录下,执行以下脚本
./bin/start-cluster.sh通过 jps 命令查询相关进程
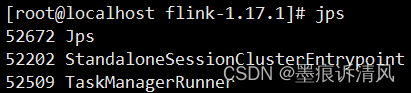
若出现上述进程,则代表启动成功。StandaloneSessionClusterEntrypoint为Flink主进程,即JobManager;TaskManagerRunner为Flink从进程,即TaskManager。
查看WebUI
在浏览器中访问服务器8081端口即可查看Flink的WebUI,比如http://10.20.0.93:8081/,从WebUI中可以看出,当前本地模式的Task Slot数量和TaskManager数量。访问结果如下图所示:

默认只允许本地访问
打开远程访问web
关闭防火墙
systemctl stop firewalld.service
修改配置
vim conf/flink-conf.yaml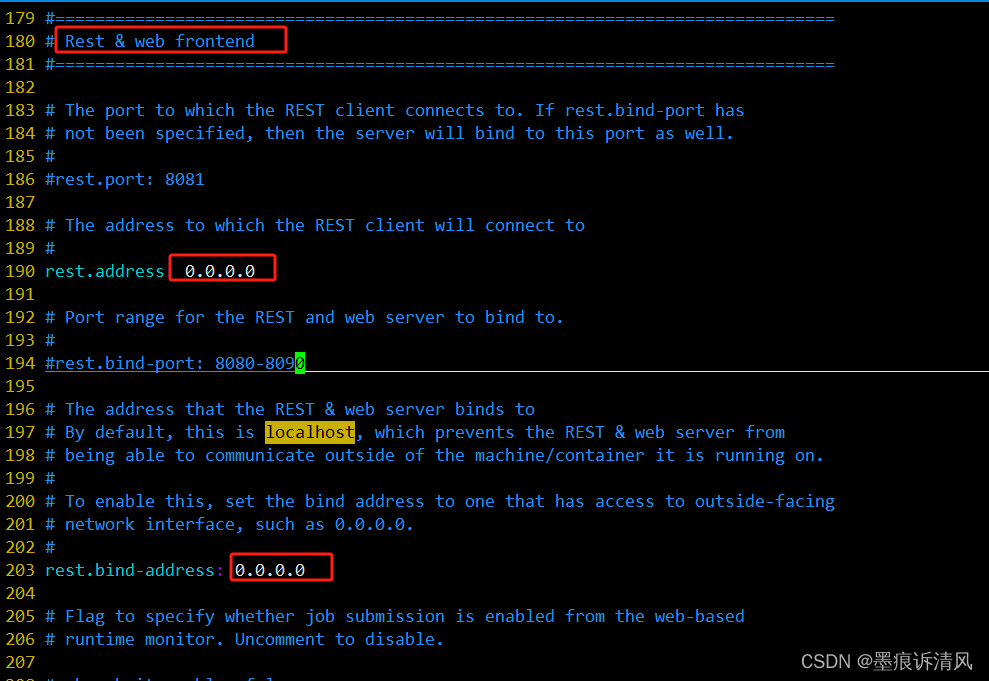
停止集群
./bin/stop-cluster.shFlink Standalone搭建
安装
搭建Flink Standalone模式,需要3台服务器。角色安排见下图:

在JobManager服务器下载安装包,解压安装包:
tar -xzf flink-1.17.1-bin-scala_2.12.tgz -C /data/software/修改flink-conf.yaml配置文件
Flink的配置文件都存放于安装目录下的conf目录。在JobManager服务器,进入该目录,执行以下操作。
vim conf/flink-conf.yaml将文件中jobmanager.rpc.address属性的值改为JobManager机器的ip地址,如下:
jobmanager.rpc.address: 10.20.0.93
jobmanager.bind-host: 0.0.0.0修改workers文件
workers文件必须包含所有需要启动的TaskManager节点的主机名,且每个主机名占一行。在JobManager服务器,执行以下操作
vim conf/workers修改为其余两台TaskManager的ip地址:
10.20.0.92
10.20.0.90复制Flink安装文件到其他服务器
在JobManager服务器执行命令,将安装文件复制到其余TaskManager服务器,命令如下:
scp -r /data/software/flink-1.17.1/ 10.20.0.92:/data/software/flink-1.17.1/
scp -r /data/software/flink-1.17.1/ 10.20.0.90:/data/software/flink-1.17.1/启动集群
在启动或关闭集群的时候应该会让你输入 Worker 节点的登陆密码,而且是每一个 Worker 节点都要输入一遍。显然这样就太麻烦了,因此我们可以提前配置一下。
# 生成私钥和公钥,一路回车即可
# 生成的私钥存放在 id_rsa 文件中、公钥则存放在 id_rsa.pub 文件中
ssh-keygen -t rsa
cd ~/.ssh # 进入到家目录的 .ssh 目录中
touch authorized_keys # 创建 authorized_keys 文件在每个节点上都执行上面几个步骤,那么所有节点的 .ssh 目录中都有 id_rsa、id_rsa.pub 和 authorized_keys 这三个文件。如果想要实现免登陆的话,假设在 A 节点中远程登陆 B 节点想不输入密码,那么就把 A 节点的 id_rsa.pub 里面的内容添加到 B 节点的 authorized_keys 文件中即可。但是注意,这个过程是单向的,如果在 B 节点中远程登陆 A 节点也不想输入密码的话,那么就把 B 节点的 id_rsa.pub 里面的内容添加到 A 节点的 authorized_keys 中。
# 可以通过 ssh-copy-id 命令帮助我们完成这一过程
[root@satori-001 .ssh]# ssh-copy-id -i id_rsa.pub [email protected]
...... 一堆输出 .......
...... 提示你输入 10.20.0.90 节点的密码 ......
...... 一堆输出 ......
[root@satori-001 .ssh]# ssh-copy-id -i id_rsa.pub [email protected]
...... 一堆输出 .......
...... 提示你输入 10.20.0.92 节点的密码 ......
...... 一堆输出 ......
[root@satori-001 .ssh]# 以上我们在 satori-001 节点远程登录 satori-002 和 satori-003 就无需再输入密码了,同理我们还要在 satori-002、satori-003 上也重复相同的操作,让集群中所有节点之间的通信都畅通无阻。
[root@satori-002 .ssh]# ssh-copy-id -i id_rsa.pub [email protected]
[root@satori-002 .ssh]# ssh-copy-id -i id_rsa.pub [email protected]
[root@satori-003 .ssh]# ssh-copy-id -i id_rsa.pub [email protected]
[root@satori-003 .ssh]# ssh-copy-id -i id_rsa.pub [email protected]在JobManager节点上进入Flink安装目录,执行以下命令启动Flink集群:
bin/start-cluster.sh启动完毕后,在集群各服务器上通过jsp命令查看Java进程。若各节点存在以下进程,则说明集群启动成功:
JobManager节点:StandaloneSessionClusterEntrypoint
TaskManager1节点:TaskManagerRunner
TaskManager2节点:TaskManagerRunner尝试提交一个简单任务,如果任务正常执行完毕,则集群一切正常。提交Flink自带的简单任务如下:
./bin/flink run examples/streaming/WordCount.jar查看WebUI
通过JobManager节点访问WebUI,可以看到此时是1个JobManager,2个TaskManager,也能以上执行完毕的任务,如下图:
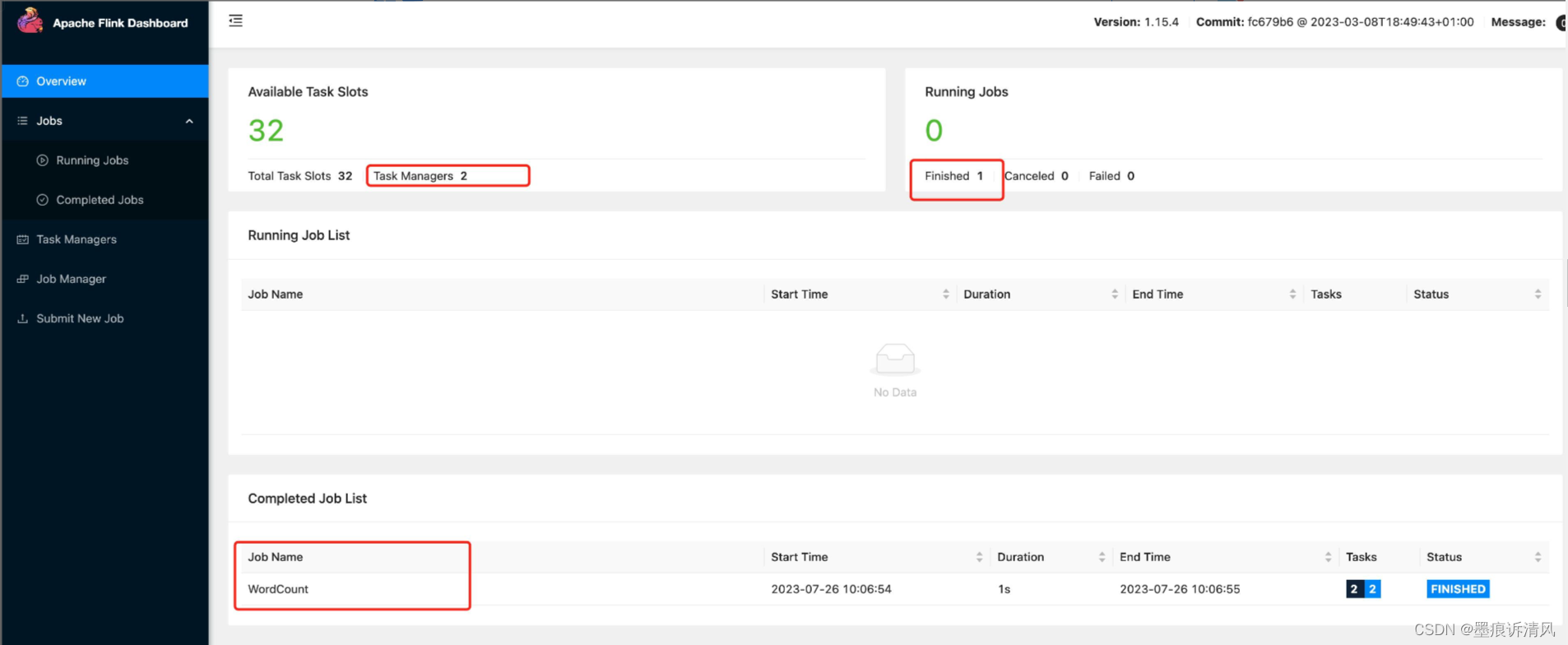


Flink Standalone HA搭建
HA模式介绍
在Flink Standalone模式下,实现HA的方式可以利用ZooKeeper在所有正在运行的JobManager实例之间进行分布式协调,实现多个JobManager无缝切换。Flink Standalone模式的HA架构如图:
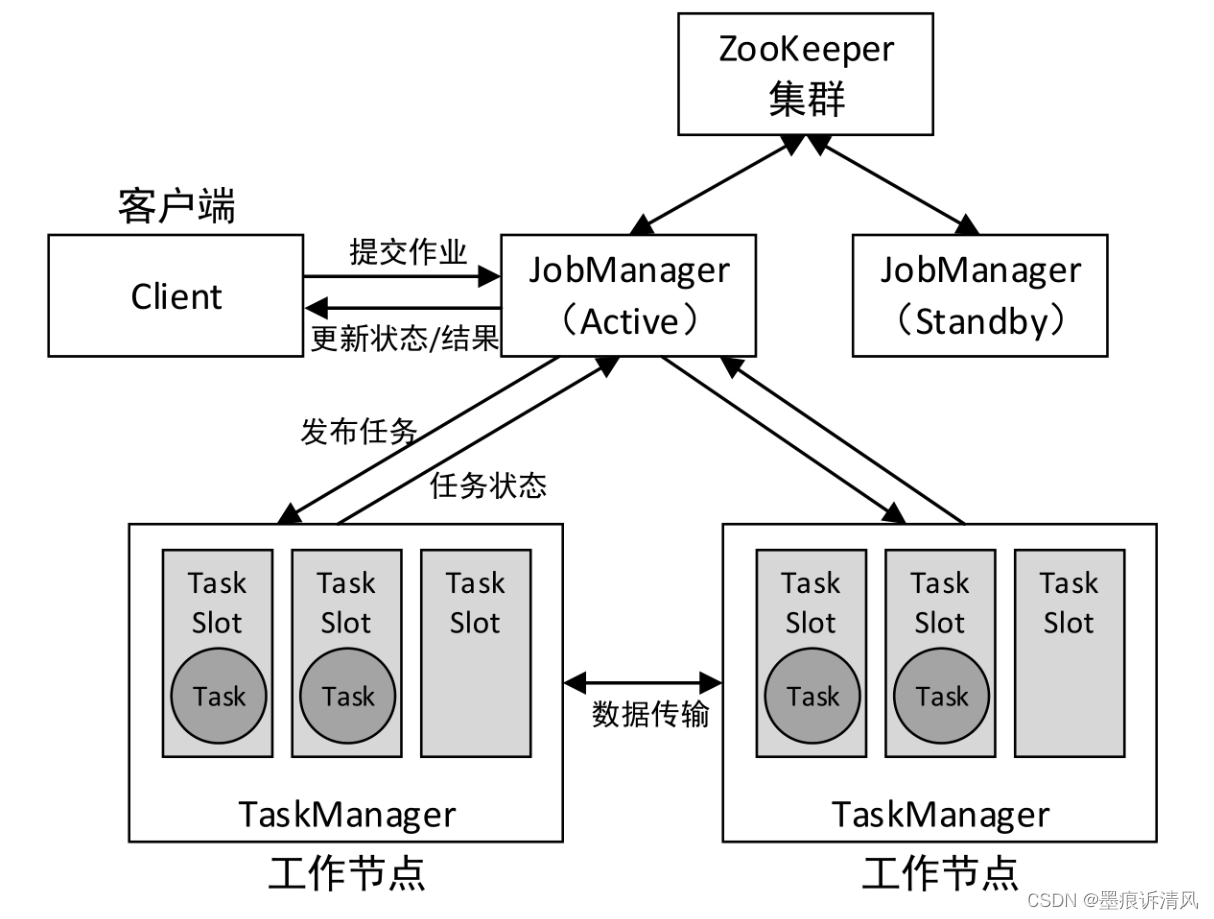
HA的核心就是:可以在集群中启动多个JobManager,并使它们都向ZooKeeper进行注册,ZooKeeper利用自身的选举机制保证同一时间只有一个JobManager是活动状态(Active)的,其他的都是备用状态(Standby)。当活动状态的JobManager出现故障时,ZooKeeper会从其他备用状态的JobManager选出一个成为活动JobManager。流程见下图:
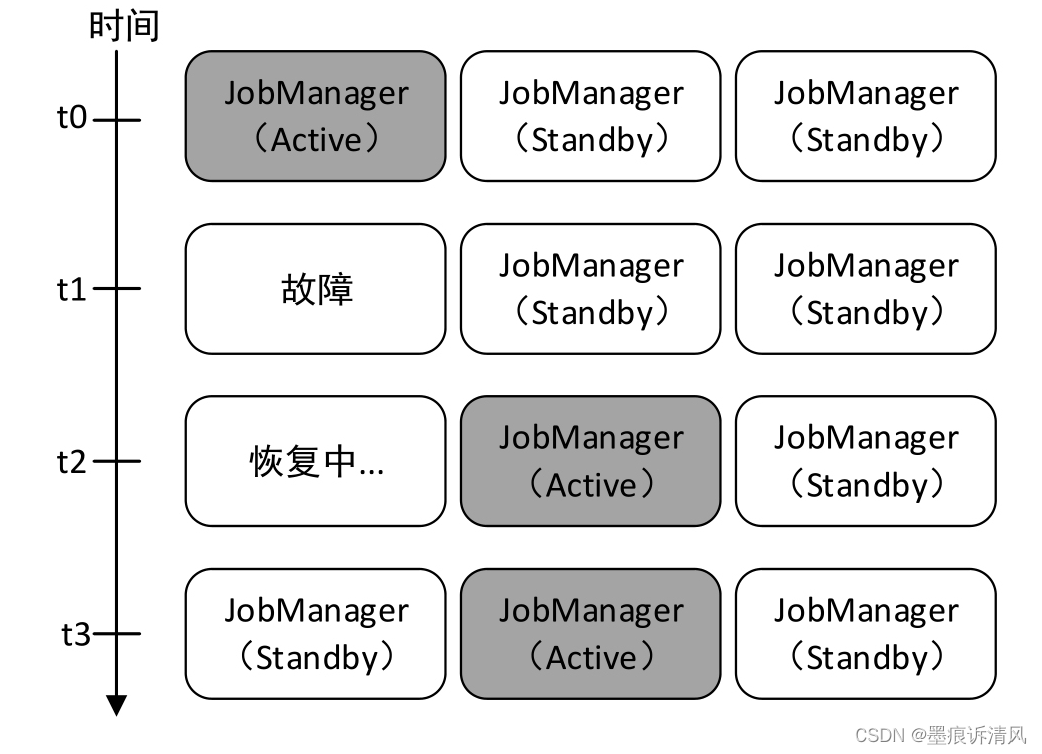
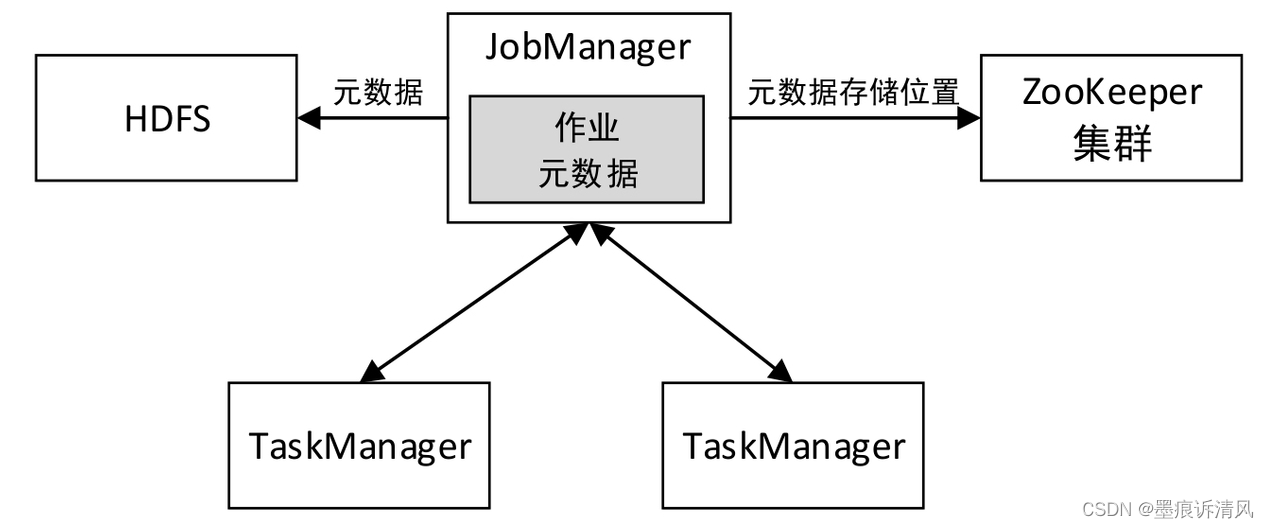
此外,活动状态的JobManager在工作时会将其元数据(JobGraph、应用程序JAR文件等)写入一个远程持久化存储系统(例如HDFS)中,还会将元数据存储的位置和路径信息写入ZooKeeper存储,以便能够进行故障恢复,如图下图所示:
角色分配
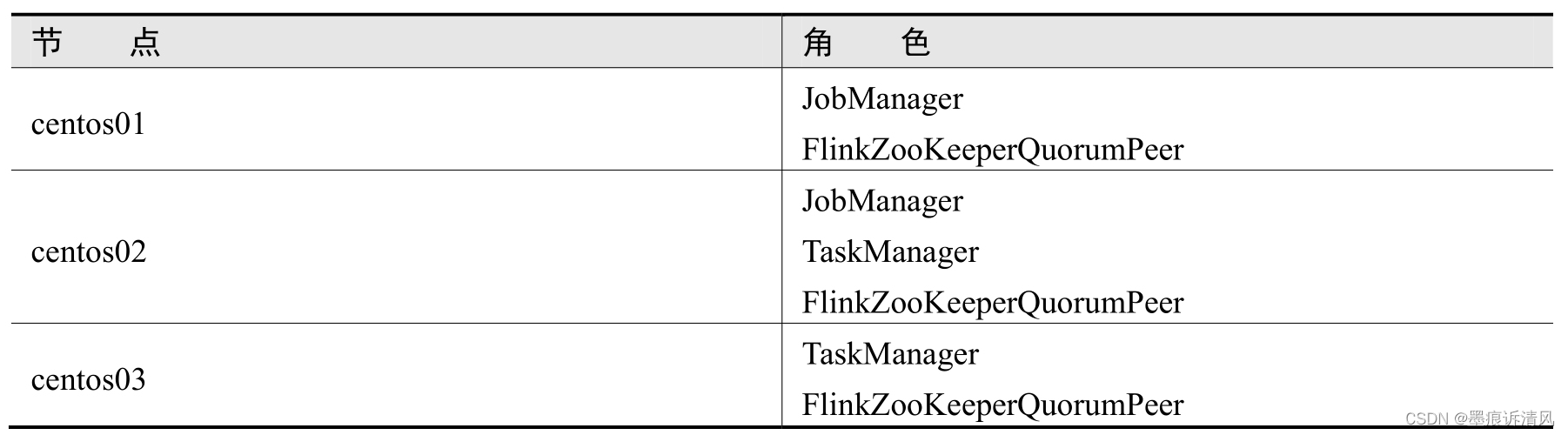
下面仍然采用前面的的3个节点,在前面已经搭建好的Flink Standalone集群上进行操作。集群角色分配如下图:
修改masters文件
Flink的masters文件用于配置所有需要启动的JobManager节点以及每个JobManager的WebUI绑定的端口。
进入centos01节点的Flink安装目录,修改conf/masters文件,修改内容如下:
centos01:8081
centos02:8082上述配置表示在集群centos01和centos02节点上启动JobManager,并且每个JobManager的WebUI访问端口分别为8081,8082。
修改flink-conf.yaml文件设置高可用模式
进入centos01节点的Flink安装主目录,修改conf/flink-conf.yaml文件,添加以下内容:
# 将高可用模式设置为ZooKeeper,默认集群不会开启高可用状态
high-availability: zookeeper
# ZooKeeper集群主机名(或IP)与端口列表,多个以逗号分隔
high-availability.zookeeper.quorum: centos01:2181,centos02:2181,centos03:2181
# 用于持久化JobManager元数据(JobGraph、应用程序JAR文件等)的HDFS地址,以便进行故障恢复,ZooKeeper上存储的只是元数据所在的位置路径信息
high-availability.storageDir: /data/software/flink-1.17.1/ha
# 获取storageDir也可用hdfs,如果使用hdfs的话,则需要单独安装hdfs,本文暂不使用
#high-availability.storageDir: hdfs://centos01:9000/flink/recovery修改zoo.cfg文件
Flink内置了ZooKeeper服务和相关脚本文件,如果你的集群中没有安装ZooKeeper,则可以通过修改zoo.cfg文件配置Flink内置的ZooKeeper。生产环境建议使用独立的外部ZooKeeper。
进入centos01节点的Flink安装主目录,修改conf/zoo.cfg文件,添加以下内容,配置ZooKeeper启动节点与选举相关端口:
server.1=centos01:2888:3888
server.2=centos02:2888:3888
server.3=centos03:2888:3888上述配置表示在centos01、centos02和centos03节点上启动ZooKeeper服务,其中1、2、3表示每个ZooKeeper服务器的唯一ID。
复制Flink安装文件到其他节点
继续采用scp命令,复制centos01的文件到其他节点,scp命令会把相同文件覆盖。
scp -r /data/software/flink-1.17.1/ centos02:/data/software/flink-1.17.1/
scp -r /data/software/flink-1.17.1/ centos03:/data/software/flink-1.17.1/启动ZooKeeper集群
如果使用Flink内置的ZooKeeper,在centos01节点执行以下命令,即可启动整个ZooKeeper集群:
./bin/start-zookeeper-quorum.sh启动过程见下图
启动成功后,在每个Flink节点上都会产生一个名为FlinkZooKeeperQuorumPeer的进程,该进程是ZooKeeper服务的守护进程。使用jsp可以查看到如下进程:

启动Flink Standalone HA集群
在centos01节点上执行以下命令,启动Flink Standalone HA集群:
bin/start-cluster.sh启动过程类似下图:
单独查看centos01的进程,如下图:

单独查看centos02的进程,如下图:
单独查看centos03的进程,如下图:

在查看/tmp目录,可以看到相关元数据信息:

访问WebUI
之前的防止,只有centos01可以访问dashboard,现在centos01、centos02都可以访问。
在提交一个测试,如果能正常执行,说明整个集群正常。
./bin/flink run examples/streaming/WordCount.jar停止集群
若要停止Flink Standalone HA集群,在centos01节点上首先执行以下命令停止整个Flink集群:
bin/stop-cluster.sh然后执行以下命令,停止ZooKeeper集群:
bin/stop-zookeeper-quorum.sh以上是Flink的安装步骤!下一篇介绍Flink DataStream的概念和使用案例。