目录
前言:
MySQL数据库是一种免费的数据库,我们可以通过官网去下载mysql服务器到本地,其中sql指令非常重要,我们可以去通过sql指令来操作数据库,那今天我们就学习sql指令中的查询操作(select)。
操作之前,先通过cmd管理员身份进入DOS指令窗口,然后输入net start mysql 指令打开服务器,然后就是登陆你的mysql。
select 查询的大致框架:
select 后面跟字段或者*(意思是全部) from 跟表名 后面就是条件了;
单表查询
当前表数据如图所示:(表名为user)
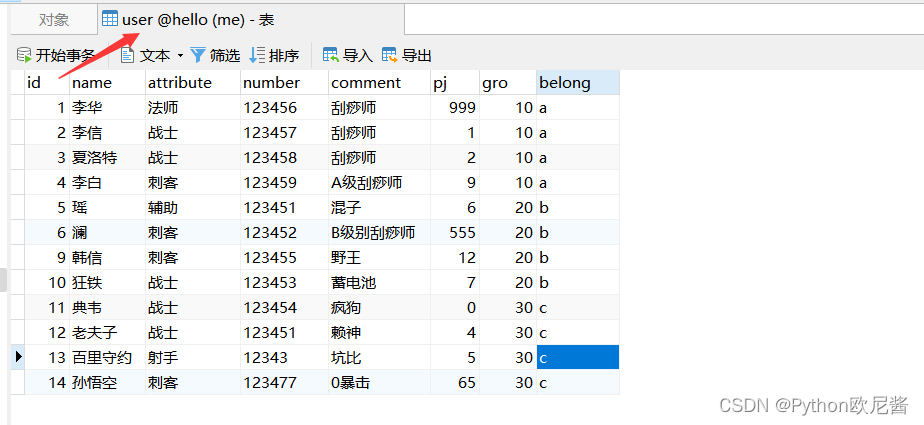
1.查询当前所在数据库
select database();

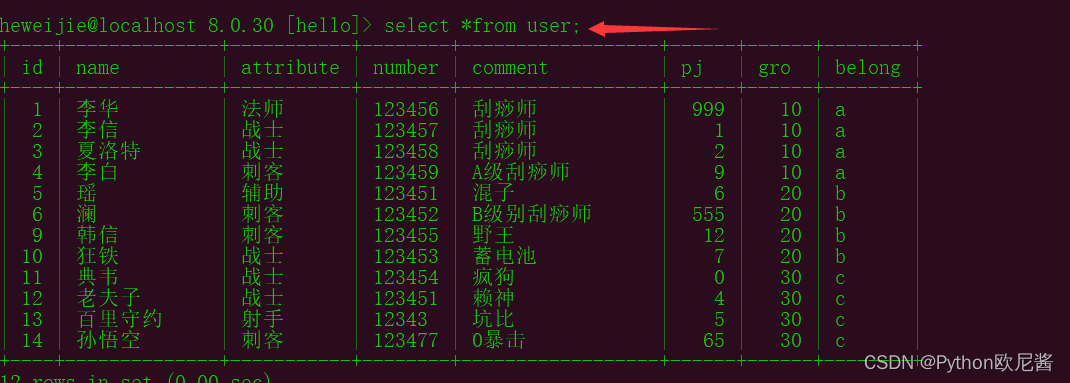
2.查询整个表数据
select *from 表名;
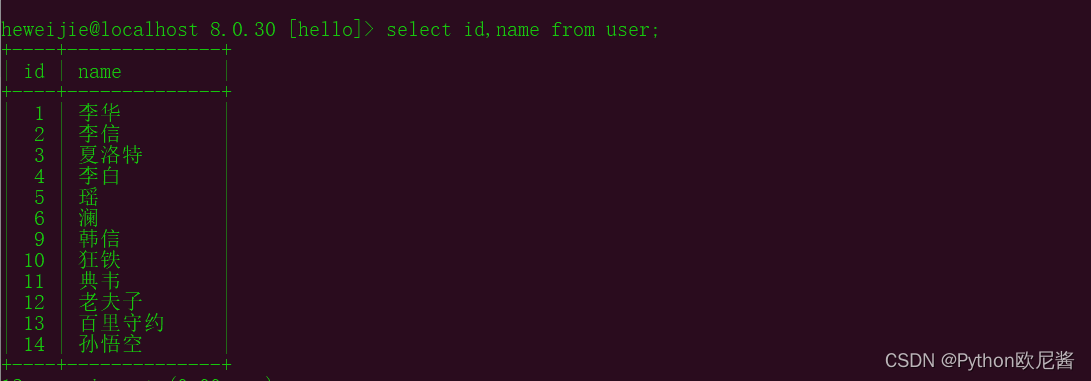
3.查询某字段
select 字段1,字段2…… from 表名;
4.条件查询
条件查询要使用到where去实现,其中条件包含以下运算符:
比较符号
=
!=
>
<
<=
>=逻辑运算符号
and
or
not范围数据
between 两个值之间
not between
in 在指定集合之间
not in
select 字段…… from 表名 where 条件;
示例1:

示例2:
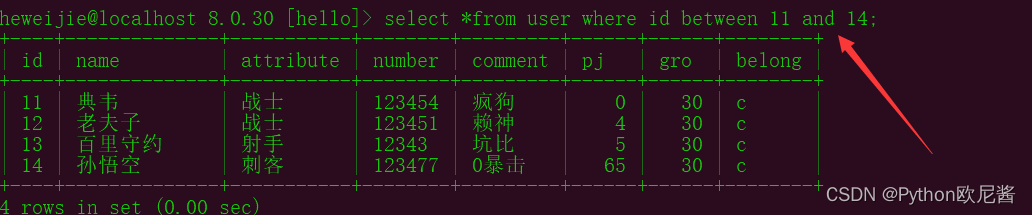
示例3:
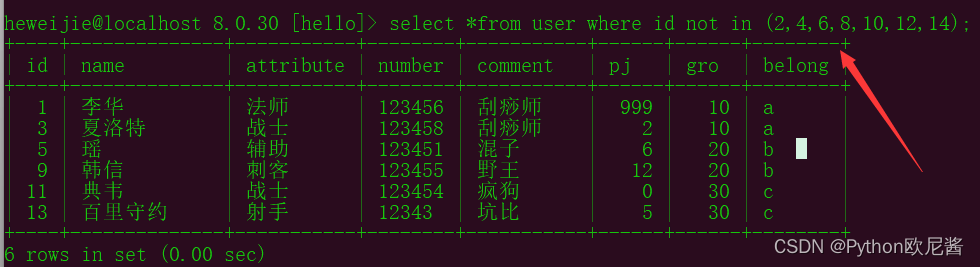
5.单行处理函数(聚合函数)
我们可以去通过mysql中的内置函数去实现一些函数功能,比如统计,去平均值,最大值小值等等。其单行处理函数如下所示:
sum(字段) 求和
upper(字段) 转大写
lower(字段) 转小写
max(字段) 取最大值
min(字段) 取最小值
avg(字段) 取平均值
count(*) 获取总条数
示例1: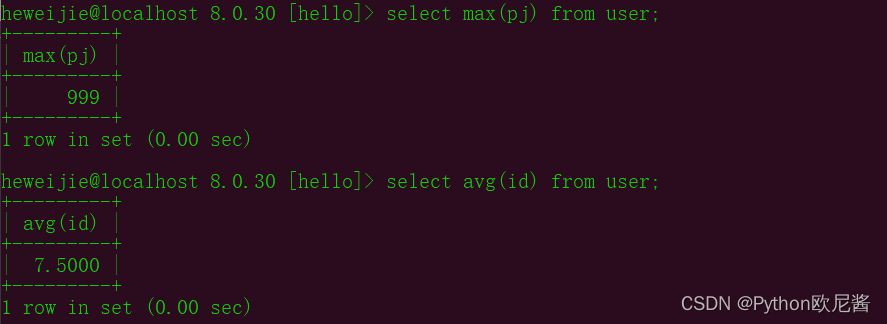
示例2: 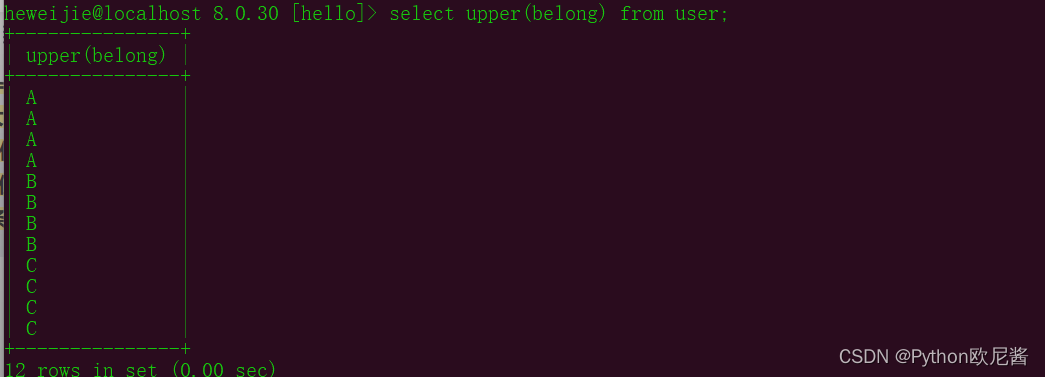
示例3:

6.查询时给字段取别名
select 字段 as 别名 from 表名 ……
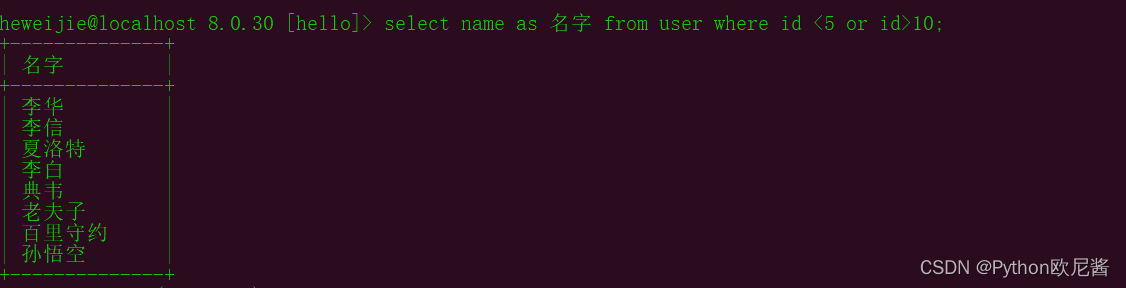
7.模糊查询
关键字:
%: 匹配0个或者多个字符(null除外)
_: 匹配任意一个字符(多个_,就匹配对应的字符)
select 字段 from 表名 where 字段 like '%……';
示例:
查询名字带有 信 字的
select *from user where name like '%信%';
查询姓李的,而且名字只有两个字
select *from user where name like '李_';
示例1:

示例2:
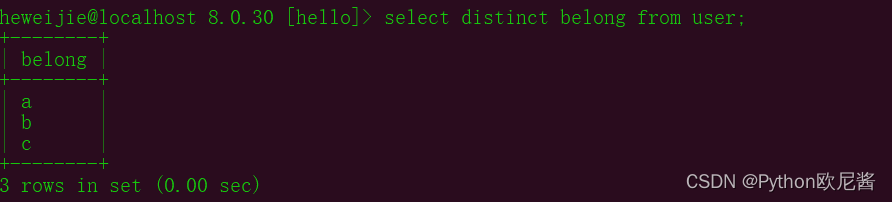
8.查询结果去除重复项
select distinct 字段 from 表名 ……;
示例:
select distinct belong from user;
(原来abc是多个的,查询去重)
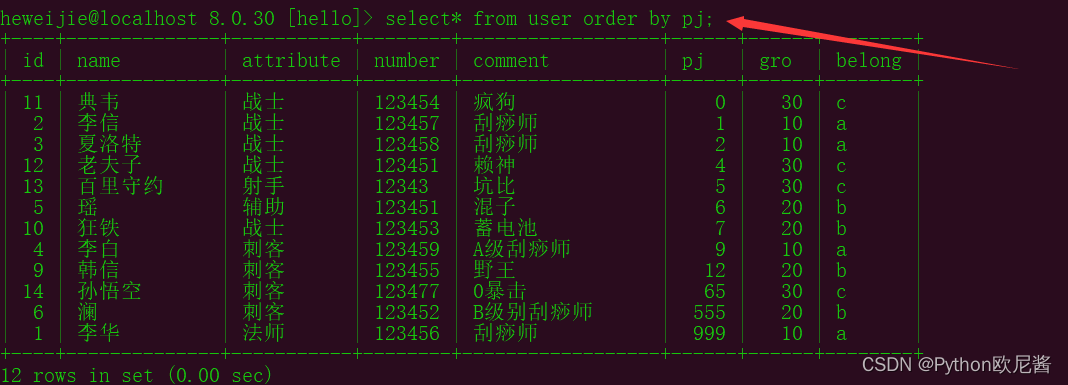
9.排序(升序和降序)
一般来说sql查询的结果都是升序的,我们也可以去通过一些指令去控制升序/降序要求
升序:
select *from 表名 order by 字段;
降序:
select *from 表名 order by 字段 desc;
示例1:
示例2: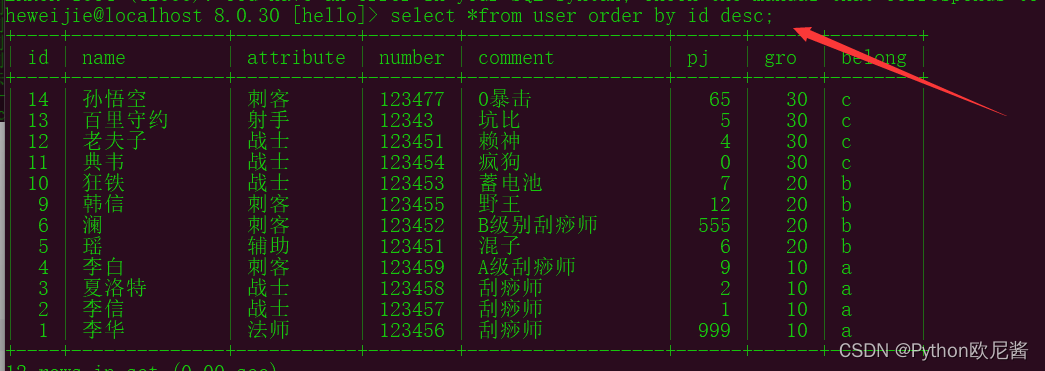
示例3: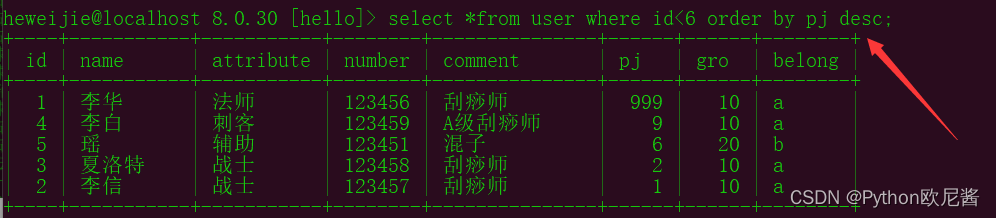
10. 分组查询
关键字:group by 组
select count(*),belong from user group by belong;
注意:分组查询的查询字段也必须是具有分组性质的,比如上面所说的单行处理函数

11.分页查询
select …… from 表名 where 条件 limit 起点,返回条数;
示例:select *from user where pj> 10 limit 1,5;
如果返回的条数大于最大条数,结果就直接返回最大的条数;如果起点大于最大的条数就返回空
联表查询
联表查询可以实现两张或两张以上的表之间进行关系查询
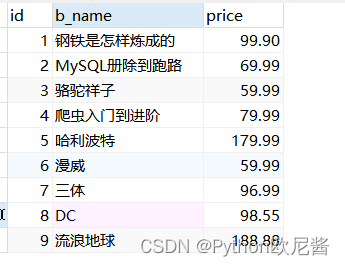 表1:book
表1:book
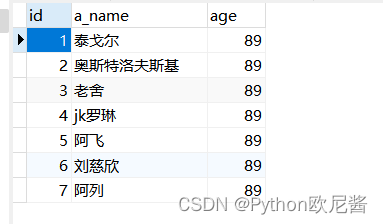 表2:author
表2:author
1.笛卡尔积现象
select *from book,author;
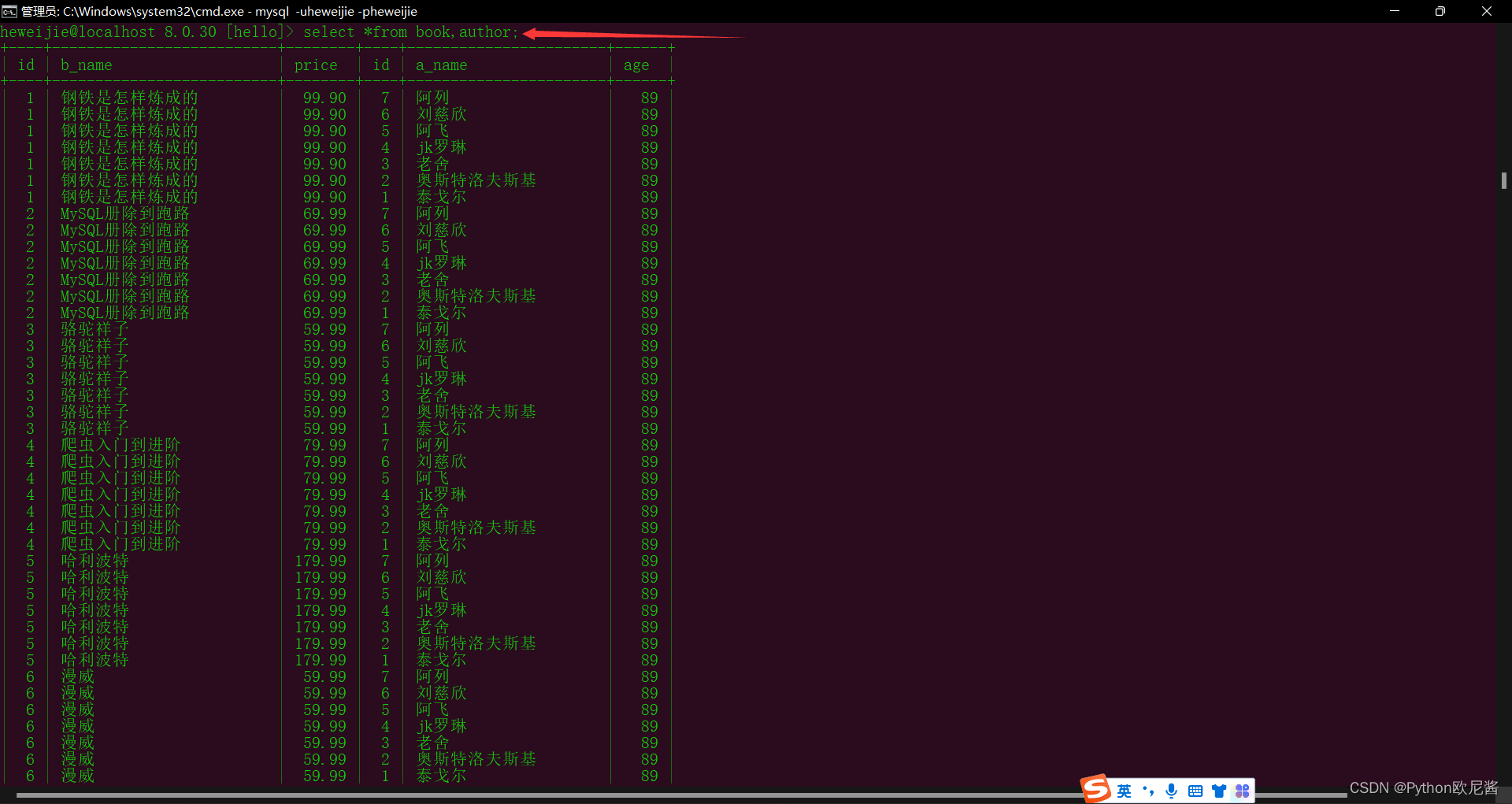
查询结果一共有63条也就是,book表中9条数据与author表中7条数据的乘积,这就是笛卡尔积现象,这种查询效率非常低下,而且需要的结果非常少,也就是说我只想要某一条结果,实际上查询出了全部结果,那我还要在这些结果找我想要的,所以千万别用这种指令!!!!!
2.内连接查询
select *from 表1 inner join 表2 on 连接条件;
示例:select book.b_name, author.a_name from book inner join author on book.id = author.id;
内连接返回的条数是按照其中一个表最短的条数返回的查询结果,遵循木桶效应

3.左连接查询
select *from 表1 left join 表2 on 条件;
(查询结果最大的条数是按照表1为标准)
示例:select *from author left join book on book.id = author.id;
select *from book left join author on book.id=author.id;
示例1:

示例2: 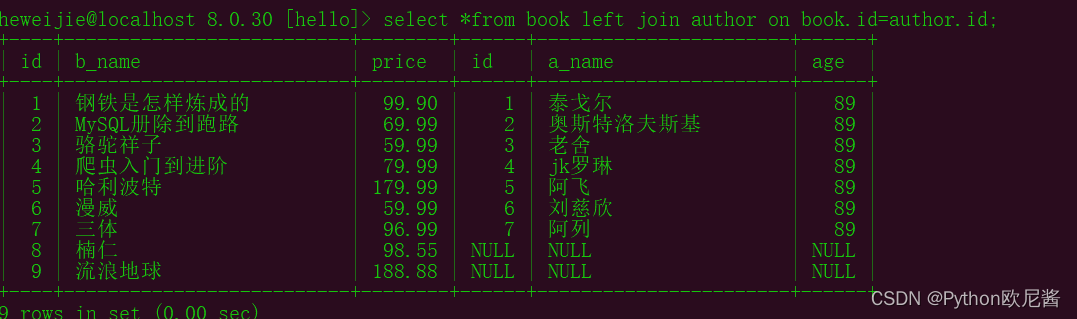
4.右连接查询
右连接就跟左连接反过来,那就是以表2为标准
select *from 表1 right join 表2 on 条件;
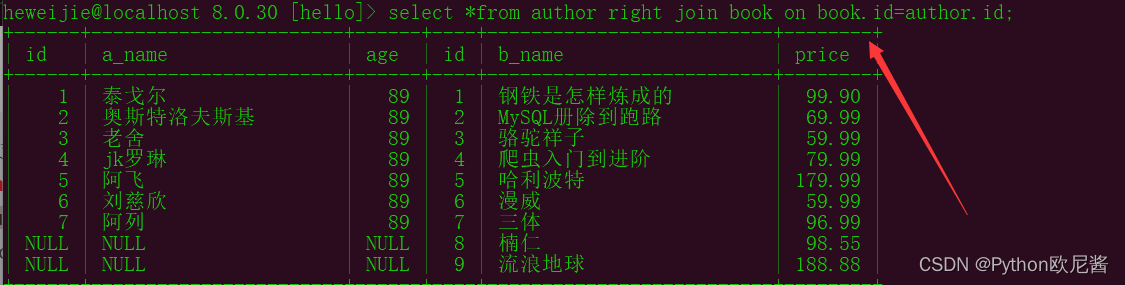
示例:select *from author right join book on book.id=author.id;
select *from book right join author on book.id=author.id;
示例1:
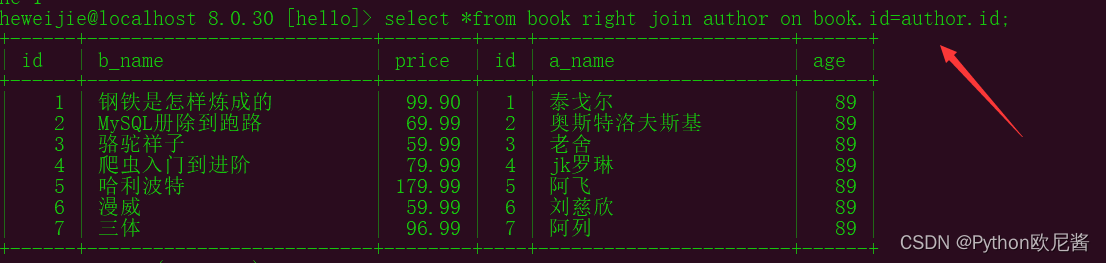
示例2:
今天就先讲这么多吧,后面还有很多我会边学习边补充的。
分享一张壁纸:
