MYSQL基本操作-select 查询语句
针对数据表里面的每条记录,select查询语句叫做数据查询语言(DQL)
select的语法格式
SELECT
{
* | <字段列名>}
[
FROM <表 1>, <表 2>…
[WHERE <表达式>
[GROUP BY <group by definition>
[HAVING <expression> [{
<operator> <expression>}…]]
[ORDER BY <order by definition>]
[LIMIT[<offset>,] <row count>]
]
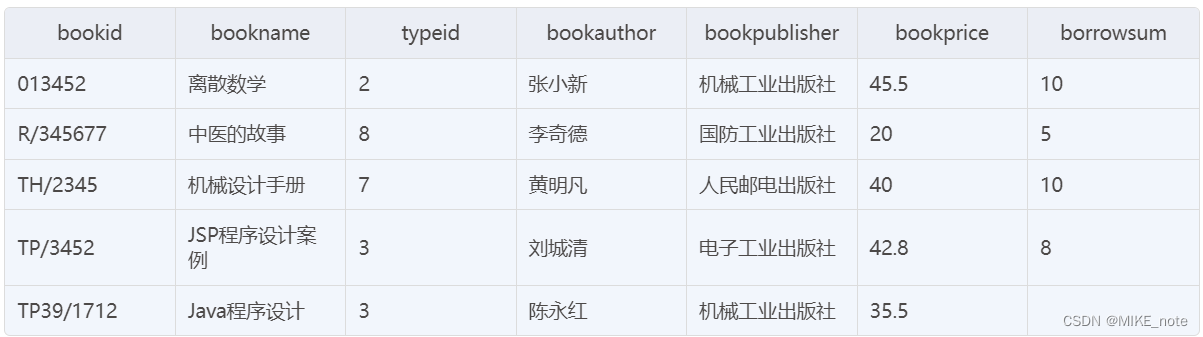
示例表:book
简单查询
查询表的所有字段
select * from book;
-
- 通配符,代表查询所有字段
- 使用 * 时,只能按照数据表中字段的顺序进行排列,不能自定义字段排序
- 建议:不知道所需查询的列名称时,才用 * ,否则获取不需要的列数据会降低查询和所使用应用程序的效率
查询表的部分字段
select bookid, bookname from book;
- 可以指定表的所有字段,然后更改字段顺序, 这种查询所有字段的写法比较灵活
- 也可以只指定某几个字段,多个字段用 , 隔开
查询表的字段并添加计算
select bookid, bookname,bookprice * borrowsum from book;
使用别名
谨记:as是可以忽略不写的哦
<表名> [AS] <别名>
<字段名> [AS] <别名>
select bookid as 图书ID, bookname 图书名称,bookprice * borrowsum as 图书总价 from book;
注意:表名取的别名不能和其他表名相同,字段名取的别名不能和其他字段名相同
消除重复行
- distinct只能在select语句中使用
- distinct必须在所有字段前面
- 如果有多个字段需要去重,则会对多个字段进行组合去重,即所有字段的数据重复才会被去重
SELECT DISTINCT <字段名>,<字段名>, FROM <表名>;
select distinct borrowsum from book;
select count(distinct typeid) from yyTest;
注意:当使用distinct的时候,只会返回指定的字段,其他字段都不会返回,所以查询语句就变成去重查询语句
条件查询
- 条件查询应该是作为测试平时用到最多的关键字了!!
- 它可以用来指定查询条件,减少不必要的查询时间
WHERE 查询条件
五种查询条件:
比较运算符、逻辑运算符
=:等于
<=>:安全等于
!=、<>:不等于
<、>、<=、>=:小于、大于、小于等于、大于等于
and、&&:所有查询条件均满足才会被查询出来
or、||:满足任意一个查询条件就会被查询出来
xor:满足其中一个条件,并且不满足另一个条件时,才会被查询出来
between and 关键字
is null 关键字
in、exist 关键字
like 关键字
单一条件的查询栗子
一般单一条件查询用的就是比较运算符
select * from book where borrowsum > 10;
select * from book where typeid = 1;
select * from book where typeid != 1;
select * from book where borrowsum > 8;
select * from book where borrowsum >= 10;
多条件的查询栗子
多条件的查询都需要使用逻辑运算符
select * from book where borrowsum >= 10 and typeid =3;
指定范围查询
- between and可以判断值是否在指定范围内,包含边界
- 取值1:范围的起始值
- 取指2:范围的终止值
- NOT:取反,不在取值范围内的值将被返回
select * from book where borrowsum < 10 or borrowsum > 30;
select * from book where borrowsum < 10 or borrowsum > 30;
select * from book where borrowsum between 10 and 30;
select * from book where borrowsum not between 10 and 30;
查询值为空的行
is null是一个关键字来的,用于判断字段的值是否为空值(NULL)
空值 ≠ 0,也 ≠ 空字符串""
select * from book where borrowsum is null;
指定集合查询
select * from book where bookname in ('离散数学','Java程序设计');
select * from book where bookname not in ('离散数学','Java程序设计');
模糊查询
LIKE '字符串'
NOT LIKE '字符串'
- NOT:取反,不满足指定字符串时匹配
- 字符串:可以是精确的字符串,也可以是包含通配符的字符串
- LIKE支持 % 和 _ 两个通配符
- % 应该是最常用的通配符了,它代表任意长度的字符串,包括0,如:a%b 表示以字母 a 开头,以字母 b 结尾的任意长度的字符串
_ 只能代表单个字符,字符的长度不能等于0,即字符长度必须等于1; - 如果查询的字符串包含%,可以使用 \ 转义符,如: like “%%”
- 如果需要区分大小写,需要加入 binary 关键字,如: like binary “TEST_”;
select * from book where bookname like 'java_';
select * from book where bookname like '%java';
select * from book where bookname like '%java%';
select * from book where bookname like 'java%';
查询排序
order by的语法格式
ORDER BY <字段名> [,<字段名>...] [ASC | DESC]
ASC:升序排序,默认值
DESC:降序排序
ASC
select * from book order by bookprice asc;
DESC
select * from book order by bookprice desc;
多字段排序
select * from book order by borrowsum asc ,typeid desc;
select * from book order by borrowsum, typeid desc;
- 如果字段值是NULL,则当最小值处理
- 如果指定多个字段排序,则按照字段的顺序从左往右依次排序
- 对多个字段排序时,只有第一个排序字段有相同的值,才会对第二个字段进行排序,以此类推
- 如果第一个排序字段的所有数据都是唯一的,将不会对第二个排序字段进行排序,以此类推
- 按字母(A-Z进行排序,大小写不敏感)
限制条数limit
limit的三种用法 - 指定初始位置
- 不指定初始位置
- 结合offset使用
limit指定初始位置
LIMIT 初始位置,记录数
select * from book limit 0, 3;
-- 从第1条记录开始,一共返回三条记录
select * from book limit 2, 2;
-- 从第3条记录开始,一共返回两条记录
注意:初始位置和记录数都必须为正整数
limit不指定初始位置的栗子
LIMIT 记录数
select * from book limit 3;
-- 一共返回3条记录
- 记录数 大于 表里总记录数的话,就返回所有记录
- 默认初始位置就是第1条记录
limit + offset组合使用的栗子
LIMIT 记录数 offset 初始位置
select * from book limit 5 offset 1;
-- 从第2条记录开始,一共返回五条记录
和 limit 初始位置, 记录数 用法一样,只是多了个offset,参数位置换了下而已