文章目录
前言
内容:MYSQL基本操作-select 查询语句【续】
聚合函数
最大值(max)
select max(bookprice) as '最贵的书' from book;
最小值(min)
select min(borrowsum) as '最受嫌弃的书...' from book;
数量(count)
select count(bookid) from book;
总和(sum)
select sum(borrowsum) from book;
平均值(avg)
select avg(bookprice) from book;
分组查询
- group by 关键字可以根据一个或多个字段对查询结果进行分组
- group by 一般都会结合Mysql聚合函数来使用
- 如果需要指定条件来过滤分组后的结果集,需要结合 having 关键字;原因:where不能与聚合函数联合使用 并且where 是在 group by 之前执行的
GROUP BY <字段名>[,<字段名>,<字段名>]
简单分组
select borrowsum, count(bookid) from book group by borrowsum;
筛选分组结果
having关键字对group by分组后的数据进行过滤
having支持where的所有操作符和语法
select borrowsum, count(bookid) from book group by borrowsum having count(bookid) = 1;
分组排序
select borrowsum, count(bookid) from book group by borrowsum order by count(bookid) desc;
统计功能分组查询
select
borrowsum,group_concat(bookname)
from book
group by borrowsum
order by borrowsum desc;
– group_concat将group by产生的同一个分组中的值连接起来 返回一个字符串结果,将分组后每个组内的值都显示出来
多个分组查询
建表语句以及插入数据
-- ----------------------------
-- Table structure for choose_course
-- ----------------------------
DROP TABLE IF EXISTS `choose_course`;
CREATE TABLE `choose_course` (
`course_name` char(10) DEFAULT NULL,
`semester_number` int(11) DEFAULT NULL,
`student_name` char(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of choose_course
INSERT INTO `choose_course` VALUES ('语文', '1', '李雷');
INSERT INTO `choose_course` VALUES ('语文', '1', '韩梅梅');
INSERT INTO `choose_course` VALUES ('语文', '1', '露西');
INSERT INTO `choose_course` VALUES ('语文', '2', '莉莉');
INSERT INTO `choose_course` VALUES ('语文', '2', '格林');
INSERT INTO `choose_course` VALUES ('数学', '1', '李雷');
INSERT INTO `choose_course` VALUES ('数学', '1', '名字真难起...');
SELECT
course_name,
semester_number,
count('hello')
FROM
choose_course
GROUP BY
course_name,
semester_number;
- 多个字段分组查询时,先按照第一个字段分组,如果第一个字段有相同值,则把分组结果再按第二个字段进行分组,以此类推
- 如果第一个字段每个值都是唯一的,则不会按照第二个字段再进行分组了
group by 字句也和where条件语句结合在一起使用。当结合在一起时,where在前,group by 在后。即先对select xx from xx的记录集合用where进行筛选,然后再使用group by 对筛选后的结果进行分组 使用having字句对分组后的结果进行筛选
需要注意having和where的用法区别:
-
having只能用在group by之后,对分组后的结果进行筛选(即使用having的前提条件是分组)。
-
where肯定在group by 之前
-
where后的条件表达式里不允许使用聚合函数,而having可以。
当一个查询语句同时出现了where,group by,having,order by的时候,执行顺序和编写顺序是: -
执行where xx对全表数据做筛选,返回第1个结果集。
-
针对第1个结果集使用group by分组,返回第2个结果集。
-
针对第2个结果集中的每1组数据执行select xx,有几组就执行几次,返回第3个结果集。
-
针对第3个结集执行having xx进行筛选,返回第4个结果集。
-
针对第4个结果集排序。
多表查询
多表查询的区别 -
cross join:交叉连接
-
inner join:内连接
-
left join:左外连接
-
right join:右外连接
-
union、union all:全连接
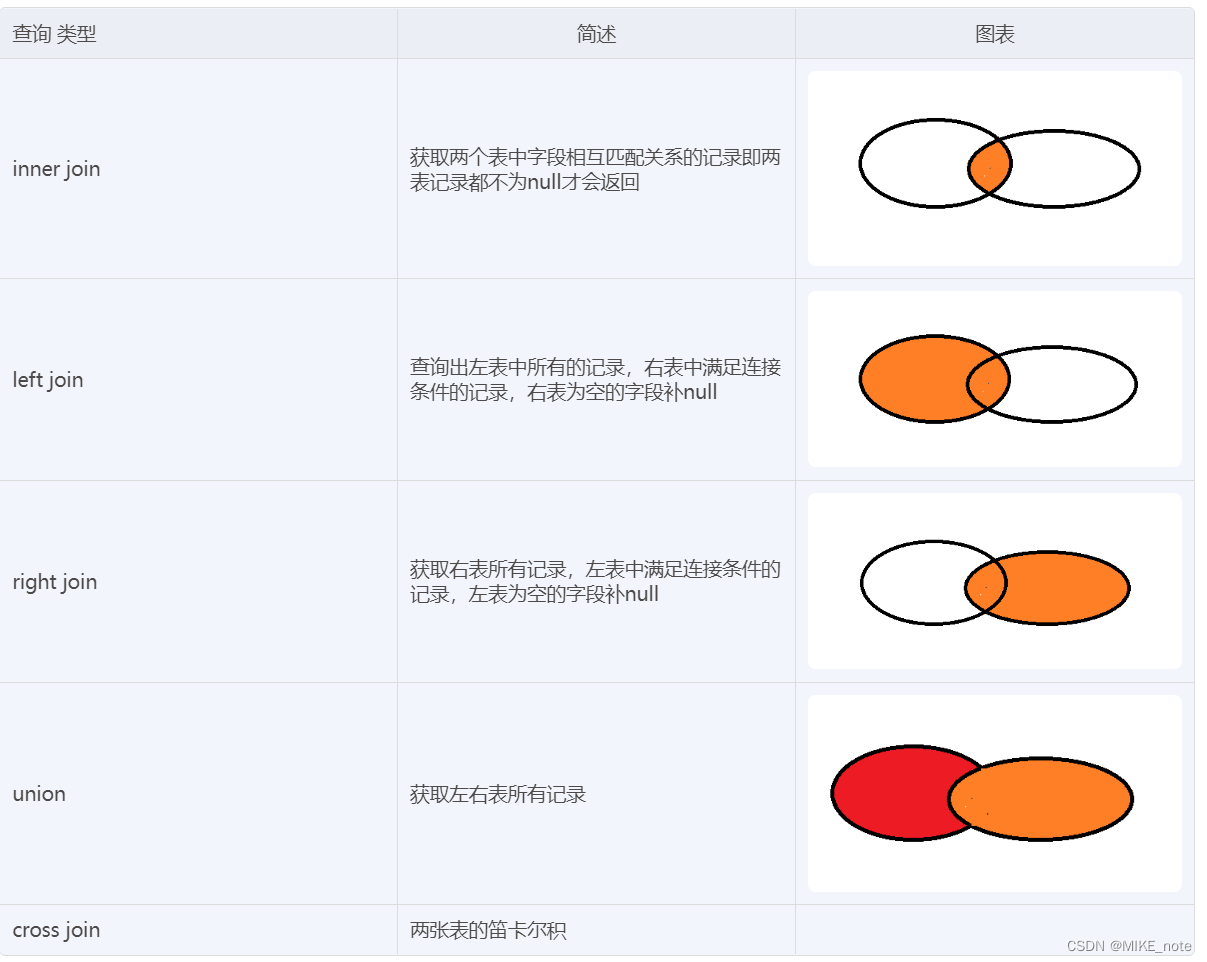
内连接
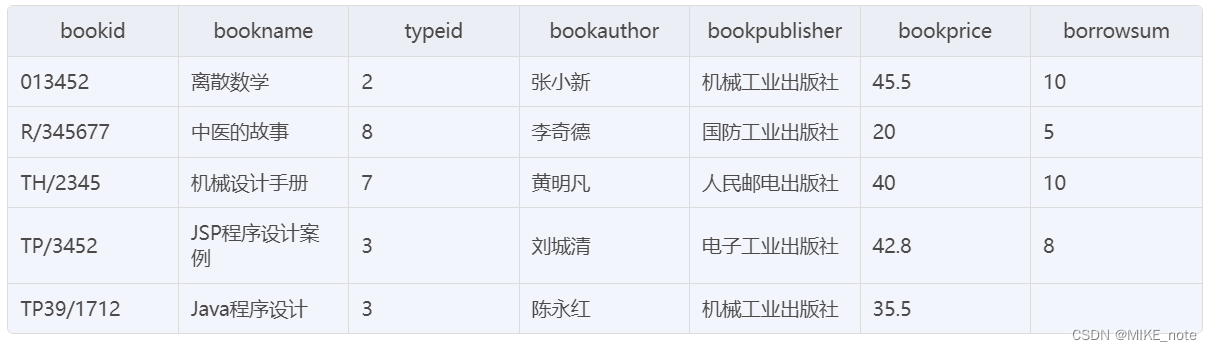
示例表:book
示例表:readertype
retypeid typename borrowquantity borrowday
1 学生 10 30
2 教师 20 60
3 管理员 15 30
4 职工 15 20
使用from子句
SELECT * FROM book, reader;
– 将两个表合并成一张表返回
select book.bookid,book.bookname,reader.readerid,reader.readername from book,reader;
– 将两张表的指定字段合并返回
在where中指定连接条件
SELECT * FROM readertype, reader
WHERE reader.retypeid = readertype.retypeid;
使用join关键字连接—使用inner join
SELECT <字段名> FROM <表1> INNER JOIN <表2> [ON子句]
– inner join通过 on 来设置条件表达式,如果没有加on的话,inner join和cross join是相同的
– cross join … on 和 inner join … on 其实效果也是一样的(但在标准sql中,cross join是不支持on的,只是Mysql支持)
– inner join 可以连接 ≥ 两个的表
– inner join 也可以使用 where 来指定连接条件,但是 inner join … on 是官方标准写法,而且 where 可能会影响查询性能
– inner join 也可以只写 join 不加 inner
select * from readertype join reader on reader.retypeid = readertype.retypeid;
select * from readertype inner join reader on reader.retypeid = readertype.retypeid;
为数据表使用别名
select readertype.retypeid,readertype.borrowquantity,reader.readerstatus
from readertype join reader on reader.retypeid = readertype.retypeid;
select a.retypeid,a.borrowquantity,b.readerstatus
from readertype as a join reader as b on b.retypeid = a.retypeid;
外连接
示例表:user
user_id user_name user_sex
1 张三 1
2 李四 1
3 王五 1
4 赵六 1
5 钱七 1
6 孙八 1
7 周老九 1
8 吴老十 1
示例表:user_detail
user_detail_id user_detail_address user_detail_phone user_detail_uid
1 河南平顶山 15639279531 1
2 河南平顶山 15639279532 2
3 河南平顶山 15639279533 3
4 河南平顶山 15639279534 4
11 河南平顶山 15639279521 11
12 河南平顶山 15639279522 12
13 河南平顶山 15639279523 13
14 河南平顶山 15639279524 14
外连接分为两种:left join、right join
外连接显示的内容要比内连接多,是对内连接的补充
left join的主表是左表,从表是右表
right join的主表是右表,从表是左表
外连接会返回主表的所有数据,无论在从表是否有与之匹配的数据,若从表没有匹配的数据则默认为空值(NULL)
外连接只返回从表匹配上的数据
重点:在使用外连接时,要分清查询的结果,是需要显示左表的全部记录,还是右表的全部记录
SELECT <字段名> FROM <表1> LEFT OUTER JOIN <表2> <ON子句>
SELECT <字段名> FROM <表1> RIGHT OUTER JOIN <表2> <ON子句>
outer可以省略,只写 left join 、 right join
on是设置左连接的连接条件,不能省略
left join 的栗子
select * from user left join user_detail on user.user_id = user_detail.user_detail_uid;
左连接后的检索结果是显示 user的所有数据和 user_detail中满足where 条件的数据。
right join 的栗子
select * from user right join user_detail on user.user_id = user_detail.user_detail_uid;
右连接后的检索结果是user_detail的所有数据和user中满足where 条件的数据。
交叉连接 cross join
笛卡尔积
假设,有两个集合A、B
A = {1,2}B = {3,4}
集合A和集合B的笛卡尔积 = 集合A * 集合B;即,两表相乘,如下:
AxB = {(1,3),(1,4),(2,3),(2,4)}
在Mysql中,表与表之间的笛卡尔积不建议使用,会产生大量不合理的数据;
SELECT <字段名> FROM <表1> CROSS JOIN <表2>
[WHERE]SELECT <字段名> FROM <表1>, <表2> [WHERE子句]
以下两句, 效果一样
select * from user cross join user_detail ;
select * from user,user_detail;
以下两句, 效果一样
select * from user cross join user_detail on user_detail.user_detail_uid = user.user_id;
select * from user,user_detail where user.user_id = user_detail.user_detail_uid;
自连接
一张表假设为 两张一样的表,分别对两张表(一样的两张表)进行联结得到笛卡儿积,再对笛卡尔积中的结果根据where进行 行过滤。
自连接是同一个表不同实例的连接操作
自连接必须指定别名(aliasName)区分不同实例
SELECT b2.bookname,b2.borrowsum
FROM book AS b2,book AS b1
WHERE b2.borrowsum > b1.borrowsum AND b1.bookname = '中医的故事'
ORDER BY b2.borrowsum DESC,b2.bookname;
SELECT b2.bookname,b2.borrowsum
FROM book AS b2 join book AS b1 on b2.borrowsum > b1.borrowsum
where b1.bookname = '中医的故事'
ORDER BY b2.borrowsum DESC,b2.bookname;
先复制出两张一样的表
在对第一张表进行where过滤,得到bookname 等于中医的故事的borrowsum
将表一与表二进行联结得到borrowsum 大于中医的故事的borrowsum
再将表二中的bookname和borrowsum的信息展示出来
别名:此查询中两张表其实是一样的表,DBMS并不知道你要引用的是哪张表,所以解决这个问题需要用到别名
联合查询
其实Mysql并没有全连接,Oracle才有全连接(full join)
但是在MySQL中,union关键字可以达到同样的效果,所以这里也要介绍下union
[sql1]UNION [ALL | DISTINCT][sql2]UNION [ALL | DISTINCT][sql3]....
sql1、sql2、sql3:平时写的查询 sql,可以连接很多条 sql
ALL:可选参数,返回所有结果集,包含重复数据
distinct:可选参数,删除结果集中重复的数据(默认只写 union 也会删除重复数据,所以不加也没事)
select * from user left join user_detail on user.user_id = user_detail.user_detail_uid
union
select * from user right join user_detail on user.user_id = user_detail.user_detail_uid;
使用 union 连接的多条sql,每个 sql 查询出来的结果集的字段名称要一致**【只需要名称一致即可,顺序可以不同,但建议相同】**,可以看看下面的栗子
最终 union 连接查询的结果集的字段顺序会以第一个 sql 查出来结果集的字段顺序为基准
子查询
子查询在我们查询方法中是比较常用的,通过子查询可以实现多表查询
子查询是指:将一个查询语句嵌套在另一个查询语句中
子查询可以在select、update、delete语句中使用,还可以进行多层嵌套
WHERE <表达式> <操作符> (子查询)
操作符可以是比较运算符、in、not in、exists、not exists
not 当然就是取反啦
使用比较运算符的子查询
查询价格高于机械设计手册的书籍的书籍号, 书籍名称, 书籍单价, 价格从高到低排序
SELECT bookid, bookname,bookprice
FROM book
WHERE bookprice > ( SELECT bookprice FROM book WHERE bookname = '机械设计手册' )
ORDER BY bookprice DESC;
查询类别是学生的读者信息, 包括读者编号, 读者姓名, 发证日期
SELECT readerid,readername,readerdate
FROM reader
WHERE retypeid = ( SELECT retypeid FROM readertype WHERE typename = '学生' );
也可以使用连表查询…
SELECT readerid,readername,readerdate
FROM reader JOIN readertype ON readertype.retypeid = reader.retypeid AND typename = '学生';
子查询的功能其实通过表连接(join)也可以完成
一般来说,表连接(内连接、外连接等)都可以用子查询查询,但反过来却不一定,有的子查询不能用表连接来替换
子查询比较灵活,适合作为查询的筛选条件
表连接更适合查看连接表之后的数据集
[not] in 子查询
查询已经借出的书籍id, 书籍名称
SELECT bookid, bookname
FROM book
WHERE bookid IN ( SELECT bookid FROM bookstorage WHERE bookstatus = '借出' );
查询没有借出(在馆)的书籍id, 书籍名称
SELECT booki, bookname
FROM book
WHERE bookid NOT IN ( SELECT bookid FROM bookstorage WHERE bookstatus = '借出' );
SELECT bookid, bookname
FROM book
WHERE bookid IN ( SELECT bookid FROM bookstorage WHERE bookstatus != '借出' );
any 子查询
any 大于最小的 < any 小于最大的 = any 相当于in();
选择book表中, 价格大于机械工业出版社最便宜价格的图书(图书ID, 图书名称, 出版社, 价格)
SELECT booki, bookname,bookpublisher, bookprice
FROM book
WHERE bookprice > ANY ( SELECT bookprice FROM book WHERE bookpublisher = '机械工业出版社' );
all 子查询
all 大于最大的
< all 小于最小的
选择book表中, 价格大于机械工业出版社最贵价格的图书(图书ID, 图书名称, 出版社, 价格)
SELECT bookid, bookname,bookpublisher, bookprice
FROM book
WHERE bookprice > all ( SELECT bookprice FROM book WHERE bookpublisher = '机械工业出版社' );
[not] exists子查询
查看图书类别表中没有图书的类别id和类别名称
SELECT typeid, typename
FROM booktype
WHERE NOT EXISTS ( SELECT * FROM book WHERE booktype.typeid = book.typeid );
查看图书类别表中有图书的类别id和类别名称
SELECT typeid, typename
FROM booktype
WHERE EXISTS ( SELECT * FROM book WHERE booktype.typeid = book.typeid );
in 和 exists的一个比较
in exists
当表达式与子查询返回的结果集中的某个值相等时,返回 TRUE,否则返回 FALSE; 用于判断子查询的结果集是否为空,若子查询的结果集不为空,返回 TRUE,否则返回 FALSE;
适合外表大而内表小的情况 适合内表大而外表小的情况
无论哪个表大,用 not exists 都比 not in 速度快
1、A是表达式,B是子查询结果集2、若A在B里面,则返回True
总结
子查询语句可以嵌套在 sql 语句中任何表达式出现的位置
字段、表名、查询条件都可以嵌套子查询!
select <子查询> from <表名> where <查询条件>
select <字段> from <子查询> as <别名> where <查询条件>
select <字段> from <表名> where <子查询>
常见错误写法
select * from (select * from emp);
这样写是会报错的,因为没有给子查询指定别名
正确写法
select * from (select * from emp) as t;
如果<表名>嵌套的是子查询,必须给表指定别名,一般会返回多行多列的结果集,当做一张新的临时表
只出现在子查询中而没有出现在父查询中的表不能包含在输出列中
多层嵌套子查询的最终结果集只包含父查询(最外层的查询)的select 语句中出现的字段
子查询的结果集通常会作为其外层查询的数据源或用于条件判断