目录

学习视频:
YOLOV7改进-添加注意力机制_哔哩哔哩_bilibili
yolov7各网络模型的结构图详解:
yolov7各个模型的网络结构图(最详细)_yolo网络结构图_Mrs.Gril的博客-CSDN博客
首先要了解网络结构对应部分
要知道哪里互相对应才方便改进,我用的是yolov7
那么下两张图相互对应,六个卷积,然后concat,然后一个卷积

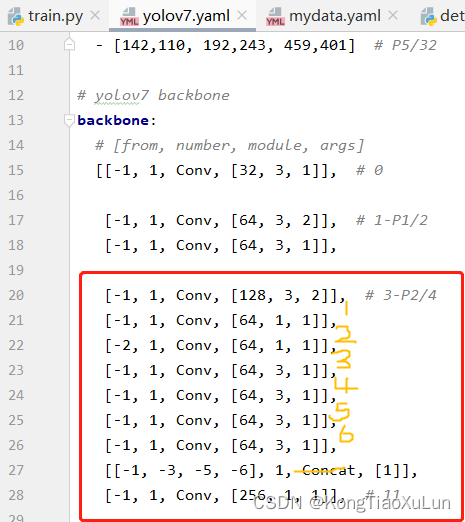
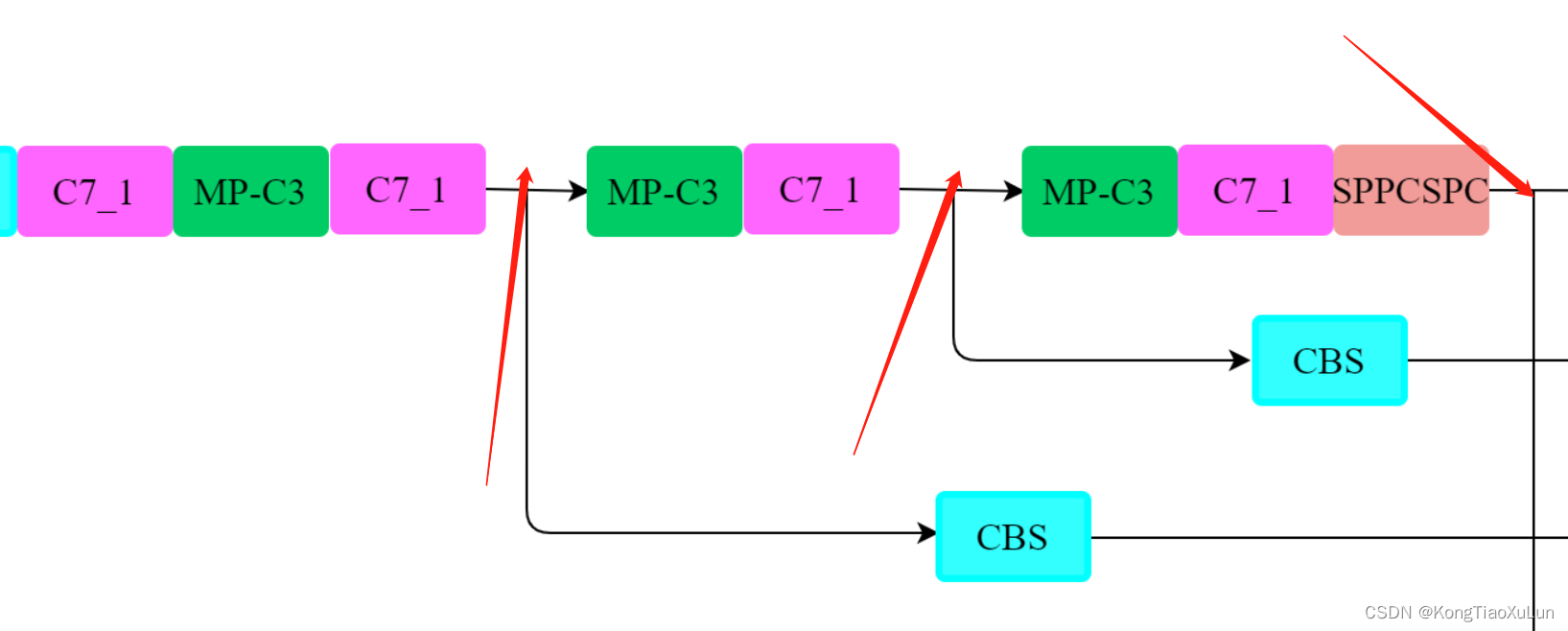
那么下图颜色框标注分别为颜色对应的层,对应网络结构图↓


1.添加注意力机制在卷积里面
添加到三个特征层输出的地方
添加注意力机制代码链接:
objectdetection_script/cv-attention at master · z1069614715/objectdetection_script (github.com)
步骤:
复制代码前40行,在models文件夹下新建SE.py文件,粘贴进去
对models文件夹下的common.py文件进行修改,在前面导入SE
from models.SE import SEAttention然后找到下图位置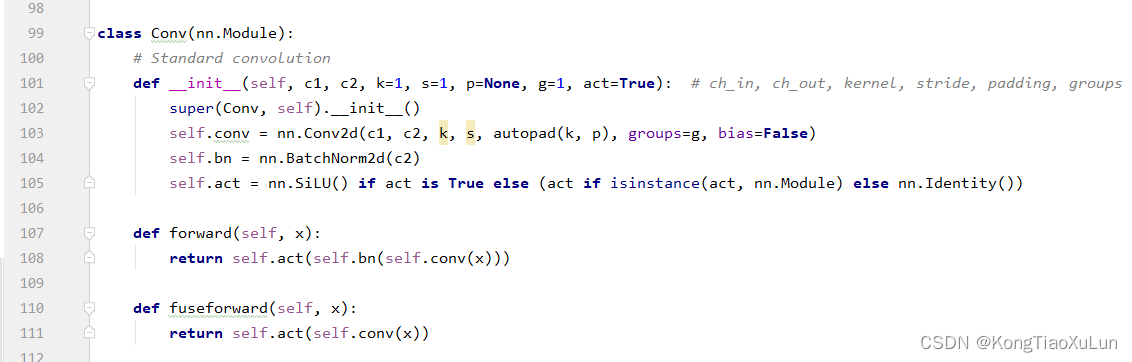
在这个类下面加上
class Conv_ATT(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv_ATT, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
self.att = SEAttention(c2)
def forward(self, x):
return self.att(self.act(self.bn(self.conv(x))))
def fuseforward(self, x):
return self.att(self.act(self.conv(x)))然后找到SPPCSPC类
 在这个类下面加上
在这个类下面加上
class SPPCSPC_ATT(nn.Module):
# CSP https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
super(SPPCSPC_ATT, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.cv7 = Conv(2 * c_, c2, 1, 1)
self.att = SEAttention(c2)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
y2 = self.cv2(x)
return self.att(self.cv7(torch.cat((y1, y2), dim=1)))这里self.att = SEAttention(c2),c2是通道数,如果是SimAM这种不需要通道数的,就用空括号,不写c2,各个注意力机制的通道数链接:
objectdetection_script/cv-attention at master · z1069614715/objectdetection_script · GitHub
然后
在cfg文件夹的training文件夹下,复制yolov7.yaml到新建的yolov7att.yaml文件中
修改第42行第56行,把Conv改为Conv_ATT
修改第75行将SPPCSPC换为SPPCSPC_ATT


然后在models文件夹下的yolo.py文件修改
在n = max(round(n * gd),1) if n>1 else n这段最后加上Conv_ATT, SPPCSPC_ATT记得加逗号
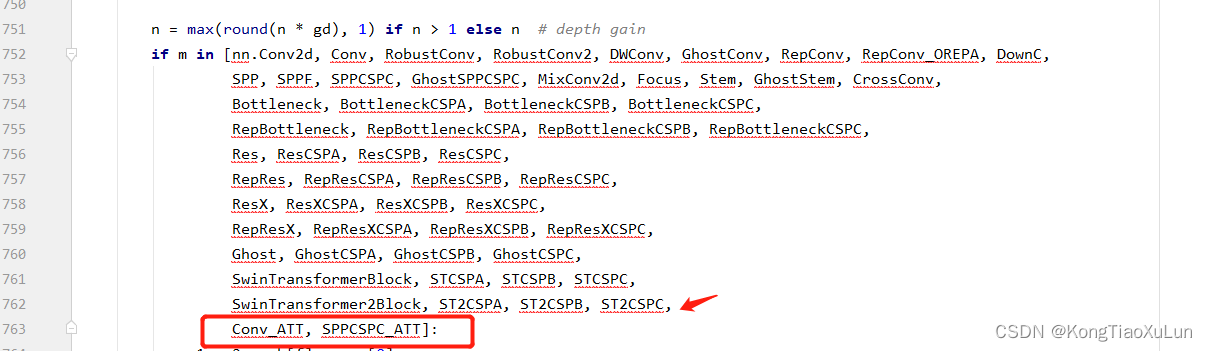
修改结束,可以训练了,记得改cfg用的是yolov7att.yaml
2.添加注意力机制在Concat里面

步骤
同样的道理,与添加1的前面步骤一样
复制代码前40行,在models文件夹下新建SE.py文件,粘贴进去
对models文件夹下的common.py文件进行修改,在前面导入SE
from models.SE import SEAttention在modles文件夹中找到common.py文件的class Concat类

在这类下面加上如下代码
class Concat_ATT(nn.Module):
def __init__(self, channel, dimension=1):
super(Concat_ATT, self).__init__()
self.d = dimension
self.att = SEAttention(channel)
def forward(self, x):
return self.att(torch.cat(x, self.d))
然后在models文件夹下的yolo.py文件中找到elif m is Concat:

在箭头所指这行下面 加入
elif m is Concat_ATT:
c2 = sum([ch[x] for x in f])
args = [c2]然后修改yolov7att.yaml文件中的头部,将四个Concat都改成Concat_ATT
进行训练即可