一、基础概念
1.1. NLP 中的 Tokenization 是什么?
NLP技术中 Tokenization 也可以被称作是“word segmentation”,直译为中文是指 分词。
分词是NLP的基础任务,按照特定需求能把文本中的句子、段落切分成一个字符串序列(其中的元素通常称为token或叫词语)方便后续的处理分析工作。
1.2. formal language 和 natural language 有什么不同?
- 自然语言 (
natural language) 是人们交流所使用的语言。例如英语、汉语等。 它们不是人为设计出来的(尽管有人试图这样做),而是自然演变而来的。 - 形式语言 (
formal language) 是人类为了特殊用途而设计出来的。例如,数学家使用的记号(notation)就是形式语言,特别擅长表示数字和符号之间的关系。化学家使用形式语言表示分子的化学结构。最重要的是编程语言是被设计用于表达计算的形式语言。
1.3. stemming 和 lemmatization 有什么区别?
- 词干提取(
stemming)是抽取词的词干或词根形式(不一定能够表达完整语义) - 词形还原(
lemmatization),是把一个任何形式的语言词汇还原为一般形式(能表达完整语义)
词形还原和词干提取是词形规范化的两类重要方式,都能够达到有效归并词形的目的。
二者区别:
- 在原理上,词干提取主要是采用“缩减”的方法,将词转换为词干,如将“cats”处理为“cat”,将“effective”处理为“effect”。而词形还原主要采用“转变”的方法,将词转变为其原形,如将“drove”处理为“drive”,将“driving”处理为“drive”。
- 在复杂性上,词干提取方法相对简单,词形还原则需要返回词的原形,需要对词形进行分析,不仅要进行词缀的转化,还要进行词性识别,区分相同词形但原形不同的词的差别。词性标注的准确率也直接影响词形还原的准确率,因此,词形还原更为复杂。
- 在实现方法上,虽然词干提取和词形还原实现的主流方法类似,但二者在具体实现上各有侧重。词干提取的实现方法主要利用规则变化进行词缀的去除和缩减,从而达到词的简化效果。词形还原则相对较复杂,有复杂的形态变化,单纯依据规则无法很好地完成。其更依赖于词典,进行词形变化和原形的映射,生成词典中的有效词。
- 在结果上,词干提取和词形还原也有部分区别。词干提取的结果可能并不是完整的、具有意义的词,而只是词的一部分,如“revival”词干提取的结果为“reviv”,“ailiner”词干提取的结果为“airlin”。而经词形还原处理后获得的结果是具有一定意义的、完整的词,一般为词典中的有效词。
- 在应用领域上,同样各有侧重。虽然二者均被应用于信息检索和文本处理中,但侧重不同。词干提取更多被应用于信息检索领域,如Solr、Lucene等,用于扩展检索,粒度较粗。词形还原更主要被应用于文本挖掘、自然语言处理,用于更细粒度、更为准确的文本分析和表达。
1.4. NLU是什么?
- 自然语言理解(
Natural Language Understanding, NLU)是所有支持机器理解文本内容的方法模型或任务的总称。 NLU在文本信息处理处理系统中扮演着非常重要的角色,是推荐、问答、搜索等系统的必备模块。
NLP 是我们在让机器基于文本数据完成特定任务时使用的思想、方法和技术的总称——其中一部分支持机器理解文本数据的内容,因此统称 NLU、一部分支持机器生成人类可以理解的文本数据,因此统称NLG。换句话说,NLU 和 NLG 都是 NLP 的一部分。
…
二、机器学习
2.1. 什么是 GBDT 算法?
-
GBDT(Gradient Boosting Decision Tree) :梯度提升迭代决策树。 -
GBDT是Boosting算法的一种,但是和AdaBoost算法不同。AdaBoost算法是利用前一轮的弱学习器的误差来更新样本权重值,然后一轮一轮的迭代;GBDT也是迭代,但是GBDT要求弱学习器必须是 分类回归树(CART)模型,而且GBDT在模型训练的时候,是要求模型预测的样本损失尽可能的小。
GBDT 直观理解:每一轮预测和实际值有残差,下一轮根据残差再进行预测,最后将所有预测相加,就是结果。
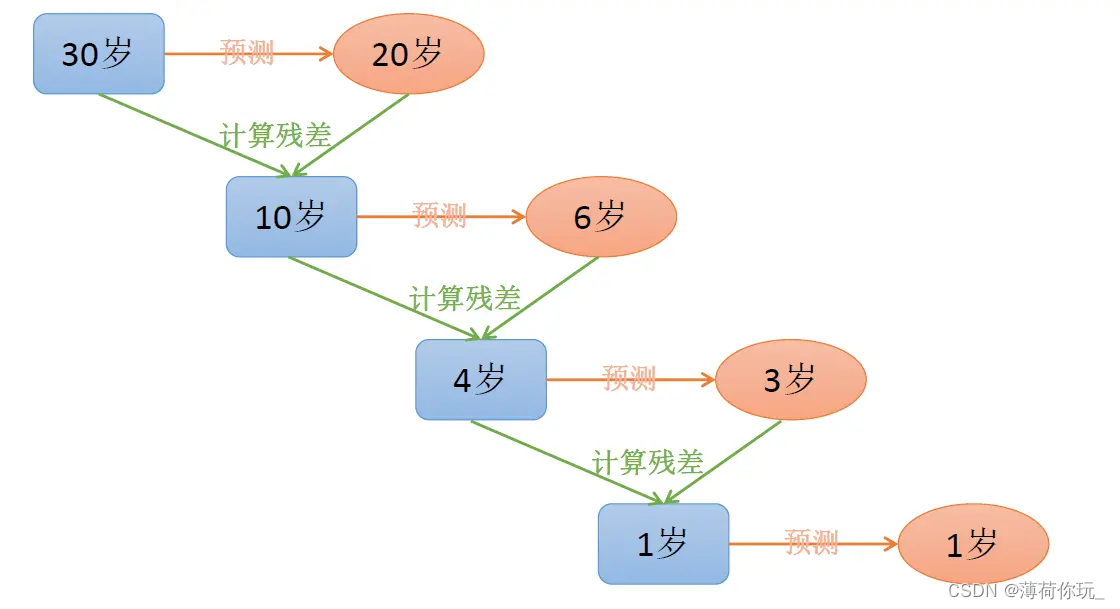
2.2. 什么是XGBoost算法?
XGBoost 本身就是 GBDT 算法,它是在 GBDT 算法的基础上进行了一系列的优化,从而使算法拥有了更好的性能。
GBDT是机器学习算法,XGBoost是该算法的工程实现。- 在使用
CART作为基分类器时,XGBoost显式地加入了正则项来控制模型的复杂度,有利于防止过拟合,从而提高模型的泛化能力。 GBDT在模型训练时只使用了代价函数的一阶导数信息,XGBoost对代价函数进行二阶泰勒展开,可以同时使用一阶和二阶导数。- 传统的
GBDT采用CART作为基分类器,XGBoost支持多种类型的基分类器,比如线性分类器。 - 传统的
GBDT在每轮迭代时使用全部的数据,XGBoost则采用了与随机森林相似的策略,支持对数据进行采样。 - 传统的
GBDT没有设计对缺失值进行处理,XGBoost能够自动学习出缺 失值的处理策略。
…
三、常用模型
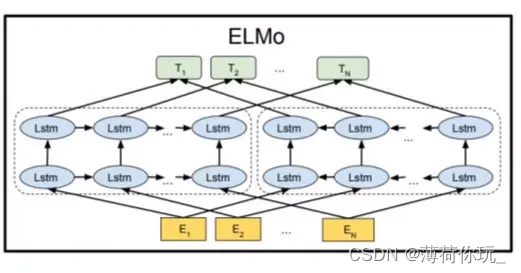
3.1. ELMo 模型
ELMo(Embeddings from Language Models),是allen NLP 在18年6月NAACL上发的一个词向量训练模型。
Elmo的作用是训练一个模型,用来表示某个词,换句话说,和word2vec和GloVe功能是一样的,这个新的训练方法有两点进步:
能够处理单词用法中的复杂特性(比如句法和语义)
有些用法在不同的语言上下文中如何变化(比如为词的多义性建模)
3.10. BERT 与 GPT 的区别?
时间线:Transformer → GPT → BERT → GPT2 → GPT3 → GPT3.5(ChatGPT) → GPT4 。
- GPT-1是OpenAI在2018年6月推出的第一个版本,共有12个Transformer编码器层,其中每个编码器层包含了768个隐藏层单元。GPT-1使用的预训练数据来自WebText,这是一个包含800万个网页的数据集。通过预训练后,GPT-1在多个下游任务上取得了较好的结果。
- GPT-2是在GPT-1的基础上进行改进,于2019年2月发布。GPT-2在架构上与GPT-1相似,但它具有更多的参数和更高的性能。GPT-2拥有1.5亿个参数,是GPT-1的10倍。GPT-2使用更大的文本数据集进行预训练,包括Common Crawl、WebText和BooksCorpus等。与GPT-1相比,GPT-2在文本生成和其他下游任务上的表现都有显著提升。
- GPT-3是于2020年6月发布。GPT-3具有1750亿个参数,是GPT-2的10倍以上。GPT-3使用更大规模的语料库进行预训练,包括Common Crawl、WebText、BooksCorpus、Wikipedia和其他大型数据集。此外,GPT-3采用了更复杂的架构和更多的技术改进,如动态控制模型大小、层级分解、流控制等。GPT-3在各种自然语言处理任务上取得了出色的表现。
- ChatGPT是一个基于GPT-3.5模型的应用,主要用于生成对话文本,包括聊天机器人、客服对话等场景。相比于GPT-3.5等通用语言模型,ChatGPT更加专注于对话场景,通过针对对话语境的优化,能够生成更加贴近对话场景的自然语言文本。
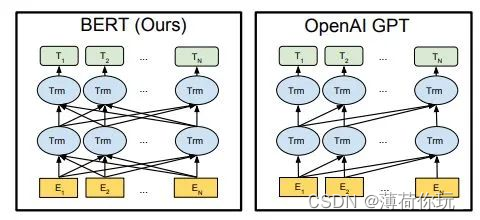
GPT(Generative Pre-trained Transformer)是由OpenAI团队于2018年提出的一种预训练语言模型。GPT是一个单向语言模型,其输入只能是文本的左侧部分。GPT使用Transformer模型,将大量无标注的文本数据预训练,然后可以用于各种下游NLP任务,如文本生成、机器翻译、问答系统等。
BERT(Bidirectional Encoder Representations from Transformers)由Google研发,于2018年首次发表。BERT是一个双向语言模型,采用的是双向的Transformer。BERT与GPT一样,采取了Pre-training + Fine-tuning的训练方式,在分类、标注等任务下都获得了更好的效果。
主要区别:
- GPT是单向模型,无法利用上下文信息,只能利用上文;而BERT是双向模型。
- GPT采用的是 Transformer 架构中的 Decoder 模块;BERT采用的是 Transformer 架构中的 Encoder 模块。
- GPT是基于自回归模型,可以应用在 NLU 和 NLG 两大任务;原生的BERT采用的基于自编码模型,只能完成 NLU 任务,无法直接应用在文本生成上面。
- 同等参数规模下,BERT的效果要好于GPT。
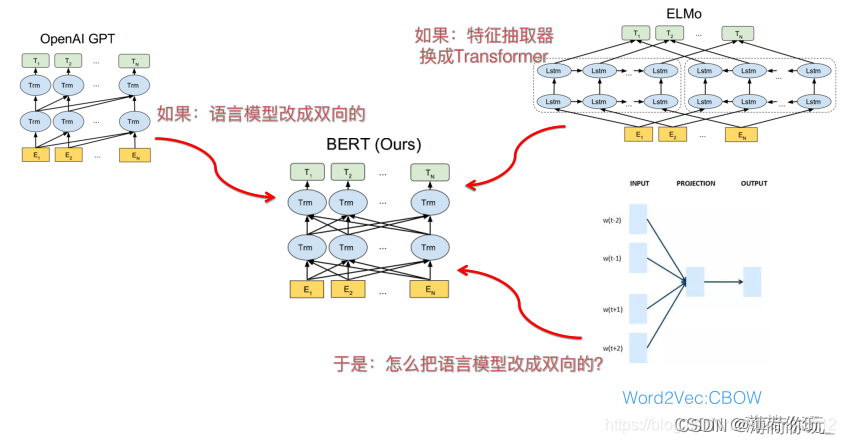
3.11. BERT、GPT、 ELMo 各自的优点和缺点?
① ELMo
优点:
- 从早期的 Word2Vec 预训练模型的最大缺点出发, 进行改进, 这一缺点就是无法解决多义词的问题。
- ELMo根据上下文动态调整word embedding, 可以解决多义词的问题.
缺点:
- ELMo使用LSTM提取特征的能力弱于Transformer。
- ELMo使用向量拼接的方式融合上下文特征的能力弱于Transformer。
② GPT
优点:
- GPT使用了Transformer提取特征, 使得模型能力大幅提升.
缺点:
- GPT只使用了单向Decoder, 无法融合未来的信息.
③ BERT
优点:
- BERT使用了双向Transformer提取特征, 使得模型能力大幅提升.
- 添加了两个预训练任务, MLM + NSP的多任务方式进行模型预训练.
缺点:
- 模型过于庞大, 参数量太多, 需要的数据和算力要求过高, 训练好的模型应用场景要求高。
- 更适合用于语言嵌入表达, 语言理解方面的任务, 不适合用于生成式的任务。
参考文章:
https://baijiahao.baidu.com/s?id=1739586850023759094
https://blog.csdn.net/ab153999/article/details/108306008
https://blog.csdn.net/m0_37870649/article/details/93341372
https://www.jianshu.com/p/405f233ed04b
https://www.jianshu.com/p/8cfd98e4e14c