一、什么是NoSQL
要介绍Redis前必须要先介绍下NoSQL,这两者间密不可分。什么是NoSQL?
NoSQL即(not only SQL)不仅仅是SQL,泛指非关系数据库/技术。非关系数据库在高并发的场景下有巨大优势,这点MySQL等关系型数据库是无法相比的。另外NoSQL在数据分析数据挖掘也更胜一筹。Redis和MongoDB是当前较流行的NoSQL。
二、Redis和MySQL的区别
两者间外在的区别主要体现在性能的差别:Redis的单位时间内的读/写速度往往是MySQL几倍到十几倍。
之所以两者有这么大性能差异主要因为两方面:
- MySQL数据持久化时面向硬盘,而Redis面向内存,所以读写更快
- MySQL存储和查询都更加复杂,要考虑索引、范式等,Redis存储和查询都更加简单,且Redis是单线程的非阻塞IO(IO多路复用)处理那么多的并发客户端连接多路复用IO,单线程避免了线程切换的开销,而多路复用IO避免了IO等待的开销。
Redis确实有很多优点,但是目前不能完全替代Mysql等关系型数据库,因为Redis也有很多的缺点,比如存储在内存上如果掉电就会丢失,内存相较硬盘代价高昂,虽然有事务但确实只能覆盖简单场景等,现实中往往是MySQL和Redis结合使用。
举个例子:在整点秒杀商品时,大量请求到来时,Mysql要在短时间内执行大量的SQL,很容易造成数据库“罢工”,这样的场景一般会考虑异步写入数据库,而在高速读写时使用Redis来抵挡这些大量请求,在满足一定的条件时,触发这些缓存在Redis中的数据写入数据库。
也就是请求到达时都是在redis中进行写,没有进行数据库的写操作,由于redis的高性能这样保证快速响应。当请求不在那么多时,或者业务已经结束时(比如商品秒杀完了,红包抢完了),将Redis缓存的数据写入数据库进行持久化。
同理,在读取的时候也可以优先读取Redis缓存,在Redis读取失败是再从MySQL等数据读取,如下:

三、什么场景下考虑使用Redis?
上面说了Redis往往和MySQL结合使用,那么到底什么时候考虑使用Redis?主要从下面3个方面考虑:
- 要操作的数据命中率(是否经常使用)高不高,如果命中率低没必要使用Redis;
- 读写谁更多?若写操作多于读操作,也没有必要使用Redis;
- 数据大小如何?若较大会给内存带来很大压力,也没必要使用Redis
四、Redis支持的6种数据类型
| 类型 | 存储的值 | 说明 |
|---|---|---|
| String | 字符串、整数、浮点数 | 可以对字符串做增加或求子串,整数和浮点数可以实现简单计算 |
| List |
它是链表,它的每个节点都包含一个字符串
|
Red 支持从链表(双向)的两端插入或者弹出节点,或在通过偏移对'8 进行裁剪;还可以读取一个或者多个节点,根据条件删除或者查找节点等
|
|
Set
|
它里面每个元素都是个字符串,且是各不相同、无序的,Set是string类型的无序集合。
|
可以新增、读取、删除单个元素,检测一个元索是否在集合中,计算它和 集合的交集、并集和差集等;
|
| Hash |
类似Map ,是个键值对应的无序列表
|
参见Map集合 |
|
ZSet
|
有序集合,可以包含字符串、整数、浮点数、分值(score),排序依据分值的大小决定。 zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。 |
可以地、删、查、改元素,根据分值 泡因或者成员来获取对应的元素
|
| HyperLogLog | 基数,计算重复的值, 确定存储数量 |
只提供基数的运饵,不提供返回的功能
|
补充说明:
基数是一种算法。举个例子 一本英文著作由数百万个单词组成,你的内存却不足以存储它们,那么我们先分析下业务。英文单词本身是有限的,在这本书的几百万个单词中有许许多多重复单词,扣去重复的单词,这本书中也就 千到 万多个单词而己,那么内存就足够存储它 了。比如数字集合{ l,2,5 1,5,9 }的基数集合为{ 1,2,5 }那么 基数(不重复元素)就是基数的作用是评估大约需要准备多少个存储单元去存储数据,基数并不是存储元素,存储元素消耗内存空间比较大,而是给某个有重复元素的数据集合( 般是很大的数据集合〉评估需要的空间单元数。
五、Spring中集成Redis
添加依赖
<!-- Redis依赖 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.1</version>
</dependency>做个简单的性能测试:
public void performance() {
Jedis jedis = new Jedis("localhost", 6379);
int i = 0;
long start = System.currentTimeMillis();
while (true) {
long end = System.currentTimeMillis();
if (end - start >= 1000) {
break;
}
i++;
jedis.set("key" + i, "value" +i);
}
System.out.println("redis每秒写入" + i + "次");
}结果:redis每秒写入19023次。这里是自测结果,是串行执行,是一条条执行的,若采用流水线技术则会高得多。
六、获取Redis连接的两种方式 及 两种操作方式
获取Redis连接有两种方式:
- 通过jedisPool
- 通过JedisConnectionFactory连接工厂
两种方式也分别对应两种操作方式:
-
Jedis
-
RedisTemplate
下面分别介绍
七、通过jedisPool获取redis连接
上面的redis是单个链接,实际中更多的会使用连接池。主要是Jedis jedis = jedisPool.getResource();
public void pool() {
JedisPoolConfig poolConfig = new JedisPoolConfig();
// 最大空闲数 控制一个pool最多有多少个状态为idle的jedis实例;
poolConfig.setMaxIdle(50);
// 最大连接数
poolConfig.setMaxTotal(100);
// 当池内没有返回对象时,最大等待时间
poolConfig.setMaxWaitMillis(20000);
// 创建连接池
JedisPool pool = new JedisPool(poolConfig, "localhost");
// 从连接池获取一个链接
Jedis jedis = pool.getResource();
int i = 0;
long start = System.currentTimeMillis();
while (true) {
long end = System.currentTimeMillis();
if (end - start >= 1000) {
break;
}
i++;
jedis.set("key" + i, "value" +i);
}
System.out.println("redis每秒写入" + i + "次");
}redis每秒写入16794次八、通过JedisConnectionFactory连接工厂获取Redis连接
为了方便的进行Redis的读写Spring给我们提供了RedisTemplate类,但在使用该类之前先要选择一种连接工厂,共有2种(原来是4种,其中两个已过时)连接工厂:
-
JedisConnectionFactory
-
LettuceConnectionFactory
这2个都是RedisConnectionFactory接口的实现类,以JedisConnectionFactory为例,它的源码如下:

如果我们想从jedisConnectionFactory获取Jedis实例又想使用连接池。可以这样:
private Jedis getJedis() {
if (jedis == null) {
jedisConnection = jedisConnectionFactory.getConnection();
jedis = jedisConnection.getNativeConnection();
return jedis;
}
return jedis;
}九、Jedis 和 RedisTemplate
Jedis是Redis官方推荐的面向Java的操作Redis的客户端,而RedisTemplate是spring-data-redis.jar包中对JedisApi的高度封装。
spring-data-redis.jar相对于Jedis来说可以方便地更换Redis的Java客户端,比Jedis多了自动管理连接池的特性,方便与其他Spring框架进行搭配使用如:SpringCache
十、RedisTemplate
有了 RedisConnectionFactory 工厂,就可以使用 RedisTemplate了。RedisTemplate是Spring封装的来进行对Redis的各种操作的类,它支持所有的Redis原生的api。RedisTemplate位于spring-data-redis包下。我们以短信验证码为例,产生验证码,将该验证码存储到Redis:
@ApiOperation(value = "生成并发送短信验证码")
@PostMapping("sendVerificationCode")
public JsonResult sendVerificationCode(@RequestBody SendMessageRequest sendMessageRequest) throws ApiException {
// 生成4位验证码并存储到Redis缓存(缓存有效时长5分钟)
String verifyCode = RandomStringUtils.randomNumeric(4);
String key = KEY_PREFIX + "-" + sendMessageRequest.getPhoneNo();
redisTemplate.opsForValue().set(key, verifyCode, 300L);
System.out.println("SERVER_URL: " + SEND_SERVER_URL);
// 发送生成的短信验证码
.....................
return isSuccess ? JsonResult.ok("发送短信成功!") : JsonResult.error("手机号" + sendMessageRequest.getPhoneNo() + "发送短信失败!");
}这里的存储操作是redisTemplate.opsForValue().set(key, verifyCode, 300L);
为什么说有了 RedisConnectionFactory 工厂才能进行RedisTemplate的操作?我去看追踪一下 opsForValue() 这个方法的源码:
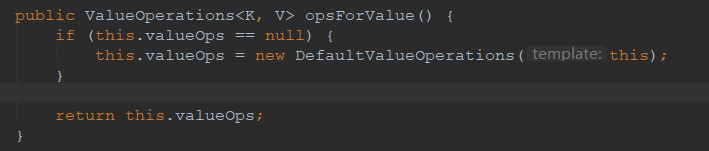
再看 ValueOperations<K, V> 这个类,看它的 set(K key, V value)方法:



这里有个 execute()方法,


这里就明白了为啥说:有了 RedisConnectionFactory 工厂,才可以使用 RedisTemplate了,因RedisTemplate对象在操作前先要获取与Redis的连接。
十一、RedisSerializer

以 StringRedisSerializer 为例,首先被存储的对象需要实现序列化接口 :
public class User implements Serializable {
private int id;
private String name;
private String phone;
public int getId() {
return id;
}
public String getName() {
return name;
}
public String getPhone() {
return phone;
}
public void setId(int id) {
this.id = id;
}
public void setName(String name) {
this.name = name;
}
public void setPhone(String phone) {
this.phone = phone;
}
@Override
public String toString() {
return "User [id=" + id + ", name=" + name + ", phone=" + phone + "]";
}
} public void test(RedisTemplate redisTemplate) {
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new JdkSerializationRedisSerializer());
User user = new User();
user.setId(1);
user.setName("dsds");
user.setPhone("110");
redisTemplate . opsForValue() .set ("user1 ", user);
User user1 = (User) redisTemplate . opsForValue() . get ("user1 ") ;
System.out.println(user1.getName()) ;
}十二、SessionCallback 和 RedisCallback
public void test(RedisTemplate redisTemplate) {
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new JdkSerializationRedisSerializer());
User user = new User();
user.setId(1);
user.setName("dsds");
user.setPhone("110");
SessionCallback callBack = new SessionCallback<User>() {
@Override
public User execute(RedisOperations ops) throws DataAccessException {
ops.boundValueOps("user1 ").set(user);
return (User) ops.boundValueOps("user1 ").get();
}
};
User savedUser = (User) redisTemplate.execute(callBack);
}十三、Redis的事务
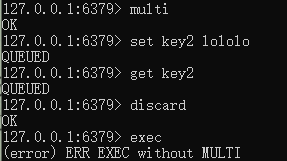
在Redis 开启事务是 multi 命令,而执行事务是 exec 命令。multi 和 exec 命令之间的 Redis 令将采取进入队列的形式,直至exec 命令的出现,才会 次性发送队列里的命令 去执行,而在执行这些命令的时候其他客户端就不能再插入任何命令了,这就是 Redis 事务机制。

十四、发布订阅
这里涉及到一个模式:观察者模式,可以参考:https://blog.csdn.net/weixin_41231928/article/details/105037562

这个过程可以使用redis客户端模拟一下:

14.1 监听类
public class Demo1 implements MessageListener {
@Override
public void onMessage(Message message, byte[] pattern) {
// 获取消息
byte[] body= message . getBody() ;
// 获取 channel
byte[] channel = message . getChannel();
}
}这里你肯定想知道Message类有啥,它实际是个接口,源码如下:


14.2 怎么发布?
public void publishMessage(){
String channel = "chat";
redisTemplate.convertAndSend(channel, "Hello");
}十五、Redis 内存回收策略

-
olatil -lru: 采用最近使用最少的淘汰策略, 只淘汰那些超时(仅仅是超时的)的键值对
-
allkey-lru: 采用淘汰最少使用的策略, 将对所有的(不仅仅是超时的)键值对采用最近使用最少的淘汰策略
-
olatil-random :采用随机淘汰策略删除超时的(仅仅是超时的)键值对
-
allkeys- random : 采用随机、淘汰策略删除所有的(不仅仅是超时的)键值对,这个策 略不常用
-
volatile-ttl: 采用删除存活时间最短的键值对策略
-
noeviction: 根本就不淘汰任何键值对 当内存己满时 如果做读操作,例如 get 它将正常工作,而做写操作,它将返回错误 也就是说 Redis 采用这个策略内存达最大时, 它就只能读而不能写了。
-
volatile-lru:加入键的时候如果过限,首先从设置了过期时间的键集合中驱逐最久没有使用的键
-
volatile-lfu:从所有配置了过期时间的键中驱逐使用频率最少的键
-
allkeys-lfu:从所有键中驱逐使用频率最少的键
十六、Redis的持久化机制
redis是一个内存数据库,数据保存在内存中,但是我们都知道内存的数据变化是很快的,也容易发生丢失。但Redis为我们提供了持久化的机制,分别是RDB(Redis DataBase)和AOF(Append Only File)。所有的配置都是在redis.conf文件中,里面保存了RDB和AOF两种持久化机制的各种配置。先看下Redis的持久化流程。
16.1 Redis持久化流程
-
客户端向服务端发送写操作(数据在客户端的内存中)。
-
数据库服务端接收到写请求的数据(数据在服务端的内存中)。
-
服务端调用write这个系统调用,将数据往磁盘上写(数据在系统内存的缓冲区中)。
-
操作系统将缓冲区中的数据转移到磁盘控制器上(数据在磁盘缓存中)。
-
磁盘控制器将数据写到磁盘的物理介质中(数据真正落到磁盘上)。
16.2 RDB机制
RDB其实就是把数据以快照的形式保存在磁盘上。什么是快照呢,你可以理解成把当前时刻的数据拍成一张照片保存下来。
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。也是默认的持久化方式,这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。
既然RDB机制是通过把某个时刻的所有数据生成一个快照来保存,那么就应该有一种触发机制,是实现这个过程。对于RDB来说,提供了三种触发机制:save、bgsave、自动化。
16.2.1 save触发方式
该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,即不能响应其他客户端的请求,直到RDB过程完成为止。
16.2.2 bgsave触发方式
Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。

具体操作是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令。
16.2.3 自动触发
自动触发是由我们的配置文件来完成的。在redis.conf配置文件中,里面有如下配置,我们可以去设置:
①save:这里是用来配置触发 Redis的 RDB 持久化条件,也就是什么时候将内存中的数据保存到硬盘。比如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。表示60 秒内如果至少有 10000 个 key 的值变化,则保存save 60 10000。
②stop-writes-on-bgsave-error :默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始接收数据了
③rdbcompression ;默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。
④rdbchecksum :默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
⑤dbfilename :设置快照的文件名,默认是 dump.rdb
⑥dir:设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。
RDB 的优势和劣势:
①、优势
(1)RDB文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。
(2)生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
(3)RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
②、劣势
RDB快照是一次全量备份,存储的是内存数据的二进制序列化形式,存储上非常紧凑。当进行快照持久化时,会开启一个子进程专门负责快照持久化,子进程会拥有父进程的内存数据,父进程修改内存子进程不会反应出来,所以在快照持久化期间修改的数据不会被保存,可能丢失数据。
16.3 AOF机制
全量备份总是耗时的,有时候我们提供一种更加高效的方式AOF,工作机制很简单,redis会将每一个收到的“写”命令都通过write函数追加到文件中。通俗的理解就是日志记录。每当有一个写命令过来时,就直接保存在我们的AOF文件中。如果 appendonly 配置为 no ,则不启用 AOF 方式进行备份。
16.3.1 AOF原理
AOF的方式也同时带来了另一个问题。持久化文件会变的越来越大。为了压缩aof的持久化文件。redis提供了bgrewriteaof命令。将内存中的数据以命令的方式保存到临时文件中,同时会fork出一条新进程来将文件重写。

重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
AOF也有三种触发机制
(1)每修改同步always:同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
(2)每秒同步everysec:异步操作,每秒记录 如果一秒内宕机,有数据丢失
(3)不同no:从不同步

16.3.2 AOF优缺点
优点:
(1)AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。(2)AOF日志文件没有任何磁盘寻址的开销,写入性能非常高,文件不容易破损。
(3)AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。
(4)AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据
缺点:
(1)对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大
(2)AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的
(3)以前AOF发生过bug,就是通过AOF记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。
16.4 RDB和AOF到底该如何选择
选择的话,两者加一起才更好。因为两个持久化机制你明白了,剩下的就是看自己的需求了,需求不同选择的也不一定,但是通常都是结合使用。有一张图可供总结:

十七、Redis 部署架构
17.1 单机版

17.2 主从复制

Redis 的复制(replication)功能允许用户根据一个 Redis 服务器来创建任意多个该服务器的复制品,其中被复制的服务器为主服务器(master),而通过复制创建出来的服务器复制品则为从服务器(slave)。只要主从服务器之间网络连接正常,主从服务器两者会具有相同数据,主服务器就会一直将发生在自己身上的数据更新同步给从服务器,从而一直保证主从服务器的数据相同。
1、master/slave 角色
2、master/slave 数据相同
3、降低 master 读压力在转交给从库
17.3 哨兵

- 通过发送命令,让Redis务器返回监测其运行状态,包括主服务器和从服务器。
-
当哨兵监测到 master 宕机, 会自动在slave中选举新的master,将这个被选举的slave 切换成 master ,然后通过发布订阅模式通知到其他的从服务器,修改配置文件,让它们切换主机
Redis sentinel 是一个分布式系统中监控 redis 主从服务器,并在主服务器下线时自动进行故障转移。其中三个特性:
监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作。
特点:
1、保证高可用
2、监控各个节点
3、自动故障迁移
问题:主从模式,切换需要时间丢数据,没有解决 master 写的压力。
17.4 集群(proxy型)

特点:
2、支持失败节点自动删除
3、后端 Sharding 分片逻辑对业务透明,业务方的读写方式和操作单个 Redis 一致
问题:
17.5 集群(直连型)

特点:
1、无中心架构(不存在哪个节点影响性能瓶颈),少了 proxy 层。
2、数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布。
3、可扩展性,可线性扩展到 1000 个节点,节点可动态添加或删除。
4、高可用性,部分节点不可用时,集群仍可用。通过增加 Slave 做备份数据副本
5、实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave到 Master 的角色提升。
问题:
1、资源隔离性较差,容易出现相互影响的情况。
2、数据通过异步复制,不保证数据的强一致性
补充 - 1:redis的通信协议
redis的通信协议是Redis Serialization Protocol,简称RESP,有如下特性:
- 是二进制安全的
- 使用TCP
- 基于请求-响应的模式
需注意的是:RESP是redis客户端和服务端通信的协议,节点交互不使用这个协议。
补充 - 2:什么是缓存穿透?什么是缓存雪崩?什么是缓存穿透?何如避免?
1、缓存穿透:
一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去后端系统查找(比如DB)。一些恶意的请求会故意查询不存在的key,请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。
如何避免?
- 对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert了之后清理缓存。
- 对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该bitmap过滤。
2、缓存雪崩
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,会给后端系统带来很大压力。导致系统崩溃。
产生雪崩的原因之一,比如马上就要到双十二零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。
在同一分类中的商品,加上一个随机因子。这样能尽可能分散缓存过期时间,而且,热门类目的商品缓存时间长一些,冷门类目的商品缓存时间短一些,也能节省缓存服务的资源。
如何避免?
- 在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
- 做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期
- 不同的key,缓存失效时间加入随机因子,尽量让失效时间点均匀分布,设置不同的过期时间。
2、缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
如何避免?
- 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
补充 - 3:热点数据 和 冷数据 是什么
热数据:是需要被计算节点频繁访问的在线类数据。
冷数据:是对于离线类不经常访问的数据,比如企业备份数据、业务与操作日志数据、话单与统计数据。
热数据就近计算,冷数据集中存储。热数据因为访问频次需求大,效率要求高,所以就近计算和部署;冷数据访问频次低,效率要求慢,可以做集中化部署,而基于大规模存储池里,可以对数据进行压缩、去重等降低成本的方法。
从数据分析的层面来看,不仅有冷热两种数据,还有温数据。而提出这个概念的是个灯,个灯是这么介绍的:
- 冷数据——性别、兴趣、常住地、职业、年龄等数据画像,表征“这是什么样的人”;
- 温数据——近期活跃应用、近期去过的地方等具有一定时效性的行为数据,表征“最近对什么感兴趣”;
- 热数据——当前地点、打开的应用等场景化明显的、稍纵即逝的营销机会,表征“正在哪里干什么”
为了处理冷热数据识别与交换,阿里云自主研发了Redis混合存储产品,是的完全兼容Redis协议和特性的混合存储产品。通过将部分冷数据存储到磁盘,在保证绝大部分访问性能不下降的基础上,大大降低了用户成本并突破了内存对Redis单实例数据量的限制。
Redis混合存储实例将所有的Key都认为是热数据,以少量的内存为代价保证所有Key的访问请求的性能是高效且一致的。而对于Value部分,在内存不足的情况下,实例本身会根据最近访问时间,访问频度,Value大小等维度选取出部分value作为冷数据后台异步存储到磁盘上直到内存小于制定阈值为止。
在Redis混合存储实例中,我们将所有的Key都认为是热数据保存在内存中是出于以下两点考虑:
1、Key的访问频度比Value要高很多。
作为KV数据库,通常的访问请求都需要先查找Key确认Key是否存在,而要确认一个key不存在,就需要以某种形式检查所有Key的集合。在内存中保留所有Key,可以保证key的查找速度与纯内存版完全一致。
2、Key的大小占比很低。
即使是普通字符串类型,通常的业务模型里面Value比Key要大几倍。而对于Set,List,Hash等集合对象,所有成员加起来组成的Value更是比Key大了好几个数量级。
因此,Redis混合存储实例的适用场景主要有以下两种:
- 数据访问不均匀,存在热点数据;
- 内存不足以放下所有数据,且Value较大(相对于Key而言)
冷热数据识别:
当内存不足时的情况下,实例会按照最近访问时间,访问频度,value大小等维度计算出value的权重,将权重最低的value存储到磁盘上并从内存中删除。
补充 - 4:为什么Redis是单线程的,优势
Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
具体的原因:
1)不需要各种锁的性能消耗
在单线程的情况下,就不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。
2)CPU消耗
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU。
Redis单线程的优劣势
1.单进程单线程优势
- 代码更清晰,处理逻辑更简单
- 不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗
- 不存在多进程或者多线程导致的切换而消耗CPU
2.单进程单线程弊端
- 无法发挥多核CPU性能,不过可以通过在单机开多个Redis实例来完善;
以上也是Redis能够支持高并发的原因。
补充 - 5:如何解决redis的并发竞争key问题?
这个问题大致就是,同时有多个子系统去set一个key。
方案:
(1)如果对这个key操作,不要求顺序
这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可,比较简单。
(2)如果对这个key操作,要求顺序
假设有一个key1,系统A需要将key1设置为valueA,系统B需要将key1设置为valueB,系统C需要将key1设置为valueC.
期望按照key1的value值按照 valueA-->valueB-->valueC的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳如下:
系统A key 1 {valueA 3:00}
系统B key 1 {valueB 3:05}
系统C key 1 {valueC 3:10}那么,假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。以此类推。
其他方法,比如利用队列,将set方法变成串行访问也可以。
补充 - 6:如何保证Redis与数据库的数据一致性?
一般来说,只要你用到了缓存,不管是Redis还是memcache,就可能会涉及到数据库缓存与数据的一致性问题。
首先考虑清楚一点:那就是到底是更新DB还是更新缓存更合适?这个很关键,目前来讲更新缓存是一件赔本买卖,原因是:
- 大多数情况下,redis缓存中的数据并不是完全copy db中的数据,而是将db中多张表的数据进行了重新计算,筛选后更新到redis。如果在db某一张表的数据发生了变化的情况下,需要同步重新计算redis中的值,成本过高。
- 缓存更新后的新值,无法保证一定会有读请求命中,如果一直没有请求命中该部分冷数据,其实是产生了一定的资源浪费(计算成本+存储成本)。
所以首先的出的结论就是:最好不要更新缓存,因为代价高昂,能删除则删除。
那么删除缓存和更新DB谁先谁后呢?首先想到的可能就是:
- 更新的时候,先更新数据库,然后再删除缓存;
- 读的时候,先读缓存;如果没有的话,就读数据库,同时将数据放入缓存,并返回响应。
但这样会有一个问题:若先更新了数据库,删除缓存的时候失败了怎么办?那么数据库中是新数据,缓存中是老数据,数据出现就出现了不一致。那么先删除缓存,后更新数据库呢,因为即使后面更新数据库失败了,缓存是空的,读的时候会从数据库中重新拉,虽然都是旧数据,但数据是一致的,即:
- 更新的时候,先删除缓存,然后再更新数据库。
- 读的时候,先读缓存;如果没有的话,就读数据库,同时将数据放入缓存,并返回响应。
到这里是不是问题就得到了彻底的解决了呢?其实并没有,在高并发的场景下,会出现这样的情况:数据发生了变更,先删除了缓存,然后去修改数据库。此时还没来得及修改,一个请求过来了,去读缓存,发现缓存空了,去读数据库,读到了准备修改前的旧数据,并且把旧数据放到了缓存。随后,数据变更程序完成了数据库的修改。那么现在数据又不一致了。
所以有了下面几种方案:
(1)串行队列方案:
可以先把“修改DB”的操作放到一个JVM队列,后面读请求过来之后,“更新缓存”的操作也放进同一个JVM队列,每个队列,对于一个作业线程,按照队列的顺序,依次执行相关操作。也就是通过队列使得“修改DB”一定是在“更新缓存”之前。当然这个方案还可以优化:
- 读请求过多的时候,队列里面会有多个“更新缓存”操作串在一起,其实是没有意义的,往队列里面塞数据的时候可以先判断一下,有的话就不用再塞进去
- 遇到更新DB比较频繁的业务场景时,可能会导致读请求长时间阻塞,这个时候可以通过扩机器增加吞吐量,或者可以先返回一个旧的值。
(2)延时双删策略:
在写库前后都进行redis.del(key)操作,并且设定合理的超时时间。伪代码:
public void write( String key, Object data )
{
redis.delKey( key );
db.updateData( data );
Thread.sleep( );
redis.delKey( key );
}步骤:
- 先删除缓存
- 再写数据库
- 休眠500毫秒
- 再次删除缓存
实际过程:
- A请求进行写操作,先淘汰缓存
- B请求进行读操作,由于A请求已将缓存淘汰,B请求没有在redis中发现所需数据,因此从数据库中读取数据,并更新缓存到redis中。注意,此时redis中被更新的依然是老数据,A请求的数据库更新操作尚未完成。假设该步骤耗时N秒
- A请求进行数据库更新操作。
- 由于此时redis中写入了老数据,因此A请求在休眠M秒后(M略大于N),再次对redis进行淘汰缓存操作
- 该方案虽然解决了数据不一致的问题,但是由于请求A在更新完数据库之后,需要休眠M秒再次淘汰缓存,一定程度上影响了数据更新操作的吞吐量。可以尝试将等待M秒更新redis的操作放到另一个单独的线程(比如消息队列 + 重试机制)。可以有效缓解吞吐量降低的问题。
(3)异步更新缓存(基于订阅binlog的同步机制)
MySQL binlog增量订阅消费+消息队列+增量数据更新到redis。
流程:
- 更新数据库数据;
- 数据库会将操作信息写入binlog日志当中;
- 订阅程序提取出所需要的数据以及key;
- 另起一段非业务代码,获得该信息;
- 尝试删除缓存操作,发现删除失败;
- 将这些信息发送至消息队列;
- 重新从消息队列中获得该数据,重试操作;
一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新。上述的订阅binlog程序在mysql中有现成的中间件叫canal(阿里的一款开源框架)通过该框架可以对MySQL的binlog进行订阅,而canal正是模仿了mysql的slave数据库的备份请求,使得Redis的数据更新达到了相同的效果,可以完成订阅binlog日志的功能,也可以使用定时任务等去控制删除失败重试次数、时间、频率。
总结:
一般来说,若不是系统需要严格要求缓存和数据库必须一致的话,缓存可以允许稍微的跟数据库偶尔有不一致的情况,上面的更新DB和更新缓存的串行话可以防止不一致的产生,但是串行后系统的吞吐量就会大幅降低,需要比正常情况下多几倍的机器去支持。