NLP知识点
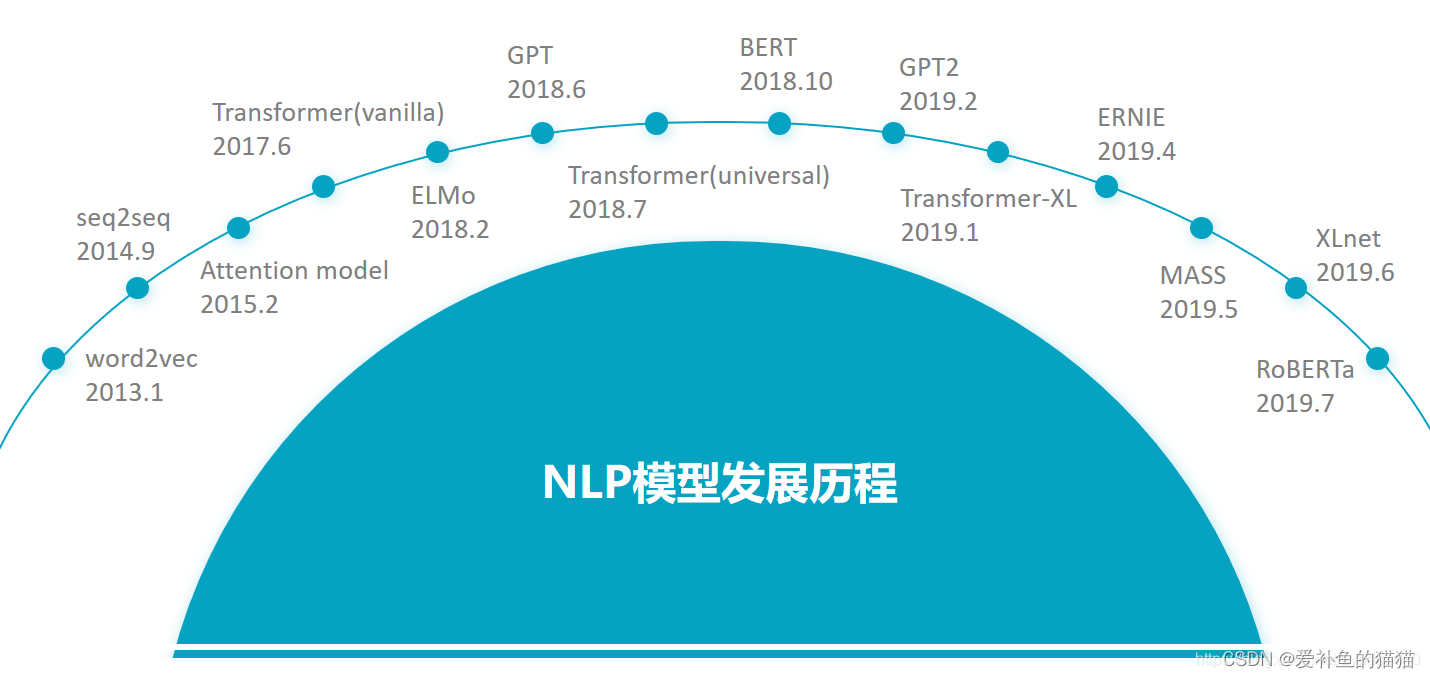
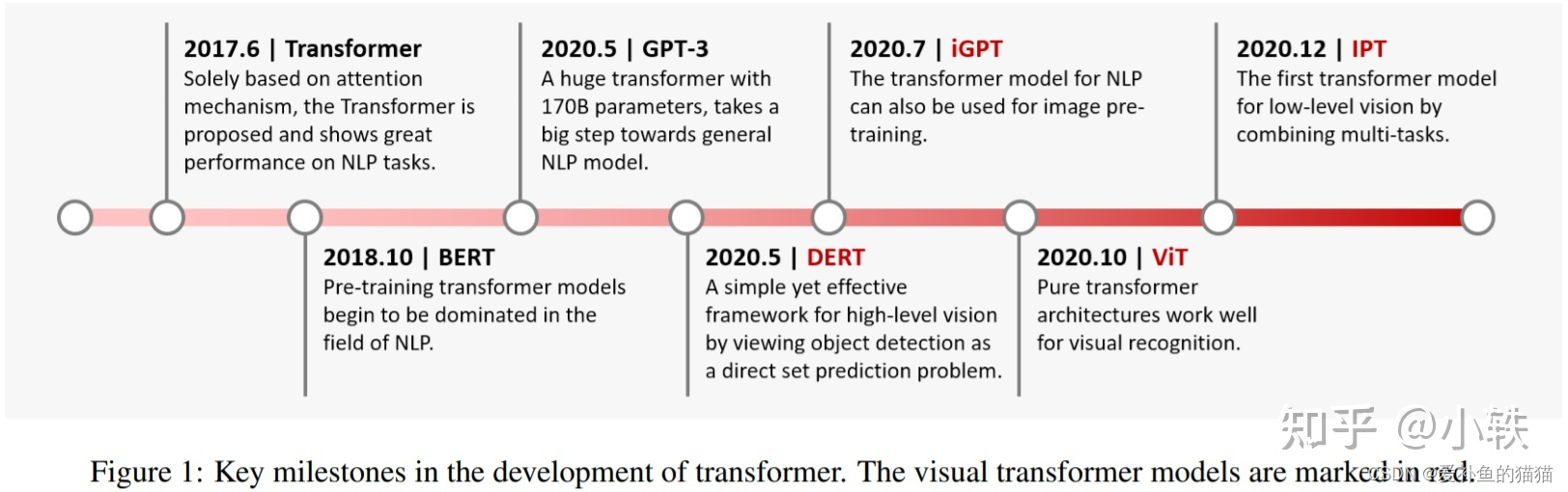
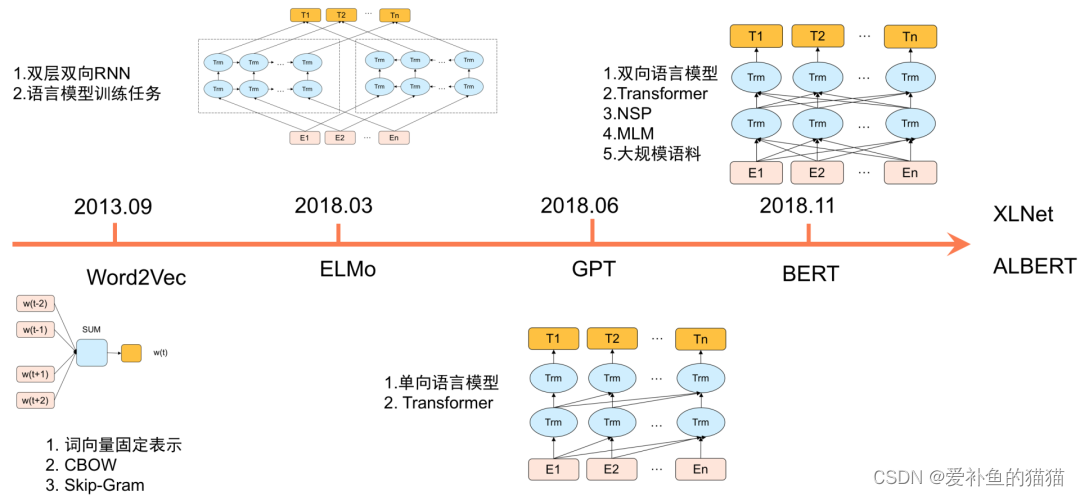
2013年,Google提出的 Word2vec[4]通过神经网络预训练方式来生成词向量(Word Embedding),极大地推动了深度自然语言处理的发展。针对Word2vec生成的固定词向量无法解决多义词的问题,2018年,Allen AI团队提出基于双向LSTM网络的ELMo[5]。ELMo根据上下文语义来生成动态词向量,很好地解决了多义词的问题。2017年底,Google提出了基于自注意力机制的Transformer[6]模型。相比RNN模型,Transformer语义特征提取能力更强,具备长距离特征捕获能力,且可以并行训练,在机器翻译等NLP任务上效果显著。Open AI团队的GPT[7]使用Transformer替换RNN进行深层单向语言模型预训练,并通过在下游任务上Fine-tuning验证了Pretrain-Finetune范式的有效性。在此基础上,Google BERT引入了MLM(Masked Language Model)及NSP(Next Sentence Prediction,NSP)两个预训练任务,并在更大规模语料上进行预训练,在11项自然语言理解任务上刷新了最好指标。
embedding 词向量
hugging、civiti
注意力机制:重构词向量
参考:https://www.bilibili.com/video/BV1v3411r78R?p=4&vd_source=38e7fc10713eca999c22c7ff25f6e6d2
数学
1、贝叶斯、奥姆剃刀、最大似然
2、马尔科夫
https://www.bilibili.com/video/BV1dR4y1R7an/?spm_id_from=333.337.search-card.all.click&vd_source=38e7fc10713eca999c22c7ff25f6e6d2


3、条件随机场CRF
4、大规模语言模型(LLM)
1、什么是NLP
自然语言处理,以人类的自然语言作为研究对象,希望让机器理解自然语言。
NLP有哪些核心任务?
分两大类:自然语言理解(NLU)和自然语言生成(NLG),前者侧重于「从自然语言(语音/文本))中抽取语义(人类希望借助语言表达的含义)」,如意图识别,后者侧重于「根据一定语义生成复合人类表达习惯的自然语言(语音/文本)」,如机器文学创作。
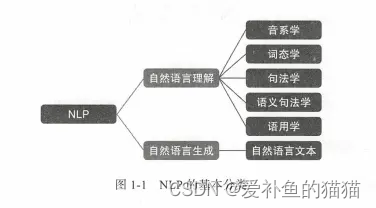
NLP有哪些应用场景?
问答系统
一个很经典的应用场景是问答系统,用户提出问题,机器给予回答。通常来说,问答系统的基本框架如图1所示。机器从大量的语料库(可能是某种百科)中抽取知识,构建知识库,然后针对用户提出的问题,根据其知识储备基于最合适的回答。比较有代表性的问答系统有IBM的Watson。
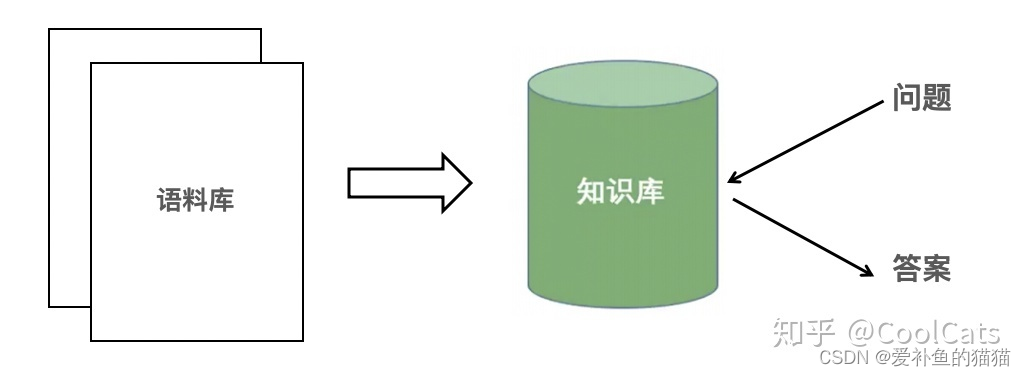
图1 问答系统基本pipeline
由于技术的瓶颈,要实现百问百知的问答系统还是很难,目前大多数问答系统都是针对某一特定领域或特定任务的问答系统。
情感分析
情感分析即分析某段文本具有什么样的情感类型,其应用案例较多,如舆情监控、事件监测、产品评论分析、股票趋势预测等。以外大多数情感分析都是粗粒度的分析,即指分析某一段文本/语音反映出的情感是正向、负向还是中性的,但对于某些场景而言,这种分析可能并不是很有意义。以用户评论为例,用户不一定会对全盘肯定或全盘否定某次购物体验,其对商城/餐馆/酒店的评价可能是多维度的,如肯定服务态度,否定整体环境。因此便有细粒度的情感分析,分析「某人对某事的哪些方面持何种态度」。
机器翻译
机器翻译也是经典的应用场景之一,已有许多出名的产品,如谷歌翻译、有道翻译、DeepL、有道翻译、DeepL等,可部署于桌面端、Web端和移动端,方便翻译。
前段时间,网易还推出了有道翻译笔(不是打广告),更加小的身躯容纳下了更为广阔的词库,亲身体验过感觉翻译质量也还OK。
自动摘要
自动摘要即将长句子浓缩成短句表达。
信息抽取
信息抽取其实就是上述图1中从语料库到知识库过程中的一项技术,所做的工作是从非结构化的文本数据提取信息,整理成结构化的知识库。
对话系统
对话系统与问答系统很像,实际上有观点认为问答系统是对话系统的一个特例,不过问答系统通常是为了回答某些事实性的问题,而对话系统则更为宽松,可以是无聊的对话,也可以是正经的围绕某项具体任务而开展的对话。
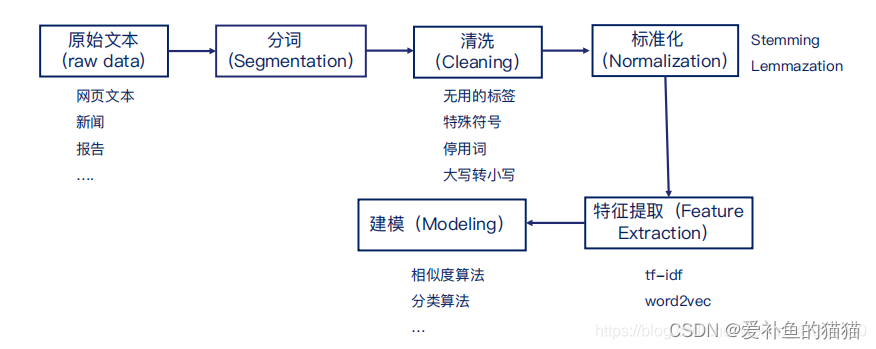
通用文本处理技术
通常而言,NLP的应用系统会包含一些通用流程:文本数据收集->文本预处理->特征提取->建模, 如图所示。
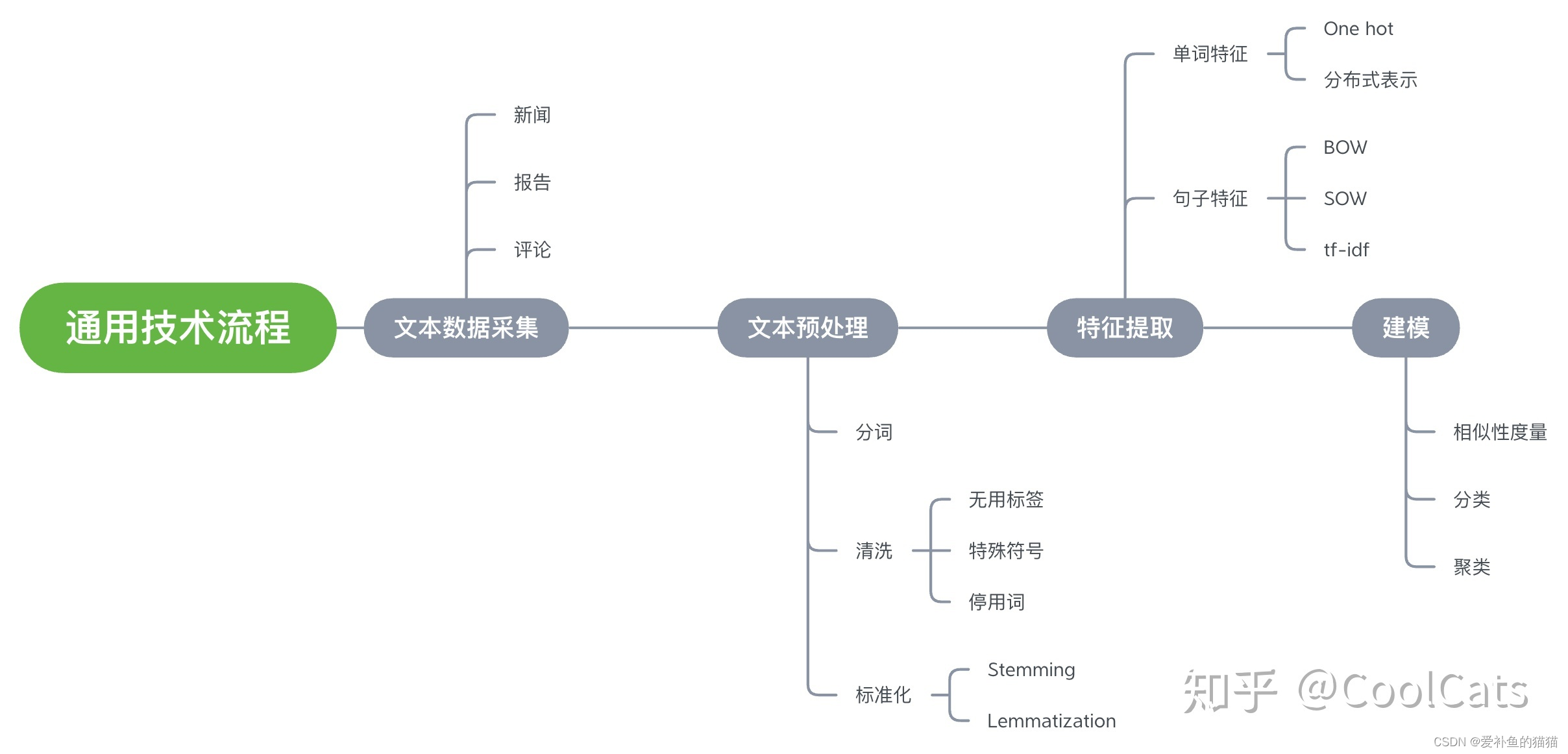
NLP项目主要流程
参考:
https://zhuanlan.zhihu.com/p/149752281
https://blog.csdn.net/weixin_41250910/article/details/99666809
文本预处理技术:在采集到文本数据之后,进行具体的分析之前,通常需要对文本进行预处理工作,包括分词、拼写纠正、停用词过滤、词的标准化等等。
特征提取:文本表示基础,文本表示是NLP领域的一大研究重点,主要指的是将文本表示成「向量」,以方便使用机器学习方法对文本进行分析。文本表示的研究中,比较重要的三个方面分别是单词表示、句子表示及相似度度量。
- 1.文本预处理
清洗数据、进行分词等 - 2.特征提取
(1)特征工程
把分词表示成计算机能够计算的类型,一般为向量
传统ML特征(如tf-idf特征, 主要集中于提取关键词)
语法、语义信息(词向量word embedding,句向量等).
(2) 特征选择
选择合适的、表达能力强的特征
常见的特征选择方法有 DF、 MI、 IG、 CHI、WLLR、WFO - 3.建立模型
机器学习模型:KNN、SVM、Naive Bayes、决策树、GBDT、K-means 等
深度模型: TextCNN, TextRNN, TextRCNN, Bert
2、统计语言模型
统计语言模型建模方法(怎么用统计学习的方法构建语言模型)
- 1.统计语言模型的基本思想:用句子S=w1,w2,…,wn 的概率 p(S) 刻画句子的合理性
- 2.使用最大似然估计进行参数学习
- 3.用马尔可夫假设和n-gram模型来解决统计语言模型参数过多的问题
- 4.用数据平滑解决样本少引起的零概率问题
参考链接:https://blog.csdn.net/AAArwei/article/details/128649938
统计语言模型
简单地说,语言模型就是用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率?
那么如何计算一个句子的概率呢?给定句子(词语序列)

它的概率可以表示为:
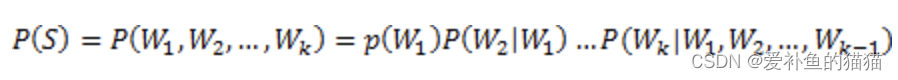
可是这样的方法存在两个致命的缺陷:
1.參数空间过大:条件概率P(wn|w1,w2,…,wn-1)的可能性太多,无法估算,不可能有用;
2.数据稀疏严重:对于非常多词对的组合,在语料库中都没有出现,依据最大似然估计得到的概率将会是0。
马尔科夫假设
为了解决參数空间过大的问题。引入了马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的一个或者几个词有关。
马尔科夫假设
为了解决參数空间过大的问题。引入了马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的一个或者几个词有关。
如果一个词的出现与它周围的词是独立的,那么我们就称之为unigram也就是一元语言模型: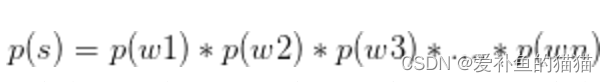
如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为bigram:

假设一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为trigram:
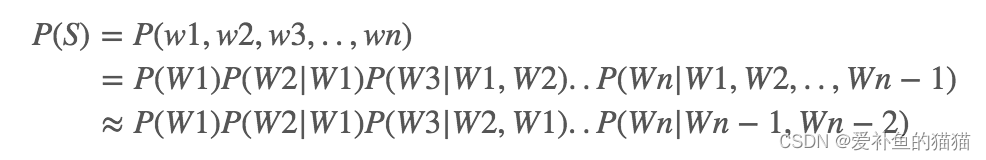
一般来说,N元模型就是假设当前词的出现概率只与它前面的N-1个词有关。而这些概率参数都是可以通过大规模语料库来计算
n-gram 语言模型
我们引入马尔可夫假设(Markov assumption),即假设当前词出现的概率只依赖于前 n-1 个词,可以得到
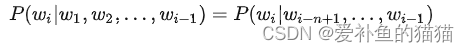
基于上式,定义 n-gram 语言模型如下:

参考:https://zhuanlan.zhihu.com/p/137866579
2、分词处理(Tokenize)
Tokenization – 将文本转化为tokens的过程
Tokens –在文本里的展示的单词或实体
Text object – 一个句子、短语、单词或文章
2.1 NLTK分词
2.2 结巴分词
2.3 正则表达式分词
2.4 词形处理
2.4.1 Inflection变化——Stemming
2.4.2 derivation引申——Lemmatization
2.5 处理StopWords
参考:https://www.jianshu.com/p/4ed41d0d41b6
4、词向量(embedding)
Embedding是数学领域的有名词,是指某个对象 X 被嵌入到另外一个对象 Y 中,映射 f : X → Y ,例如有理数嵌入实数。Word Embedding 是NLP中一组语言模型和特征学习技术的总称,把词汇表中的单词或者短语映射成由实数构成的向量上(映射)
一、词向量表示
各种词向量的特点
-
- One-hot表示:维度灾难、语义鸿沟
-
- 分布式表示:
矩阵分解(LSA):利用全局预料特征,但SVD求解计算复杂度大
基于NNML/RNNLM词向量:词向量为副产物,存在效率不高等问题
word2vec、fastText:优化效率高,但是基于局部语料
glove:基于全局语料,结合LSA和word2vec的优点
elmo、GPT、bert:动态特征
参考:https://blog.csdn.net/china1000/article/details/114994425
- 分布式表示:
One hot编码
最早采用One hot编码来表示单词,即用一个长度为词典大小的向量表示一个单词,向量的每一个维度表示某个单词是否出现,因此对于一个单词而言,整个向量只有一个维度为1(表示特点单词),其他维度均为0。
One hot编码一个典型特点是稀疏性很高,稀疏这一点有时候很好,有时候不好。极高的稀疏性给存储带来了一定的冗余性,明明只需要表示一个单词,在单词表示中却考虑了所有单词的状态。
One hot编码的一个明显缺陷是无法度量单词间的相似性。在我们的语言环境中,某些单词或表达可以很相近(如近义词、同义词的概念),某些单词或表达可以相差很远。如直觉上理解“like”和“love”要比“like”和“dog”更为相似。而采用One hot编码的单词表示,无论通过何种距离度量(余弦距离、欧式距离、曼哈顿距离等)所得到的任意两个单词间的距离都是同样的。
分布式表示(Distributed representation)
考虑到现实表达过程中一个单词可能具有多种语义,这种特点“语义”可以认为是单词的特征维度。Hinton由此提出了单词的分布式表示,认为可以把单词映射成一个固定长度的短向量,所有单词的向量构成低维的词向量空间,每个单词是空间中的一个点,空间的每一个维度可以表示单词的某一种语义。这种表示相比one hot编码得到的特征向量,明显具有低维、稠密的特性,另外还可以将点距离度量的方法用于单词间“距离“计算上。但是如何学习单词的分布式表示?有LSA、LDA、word2vec等方法。
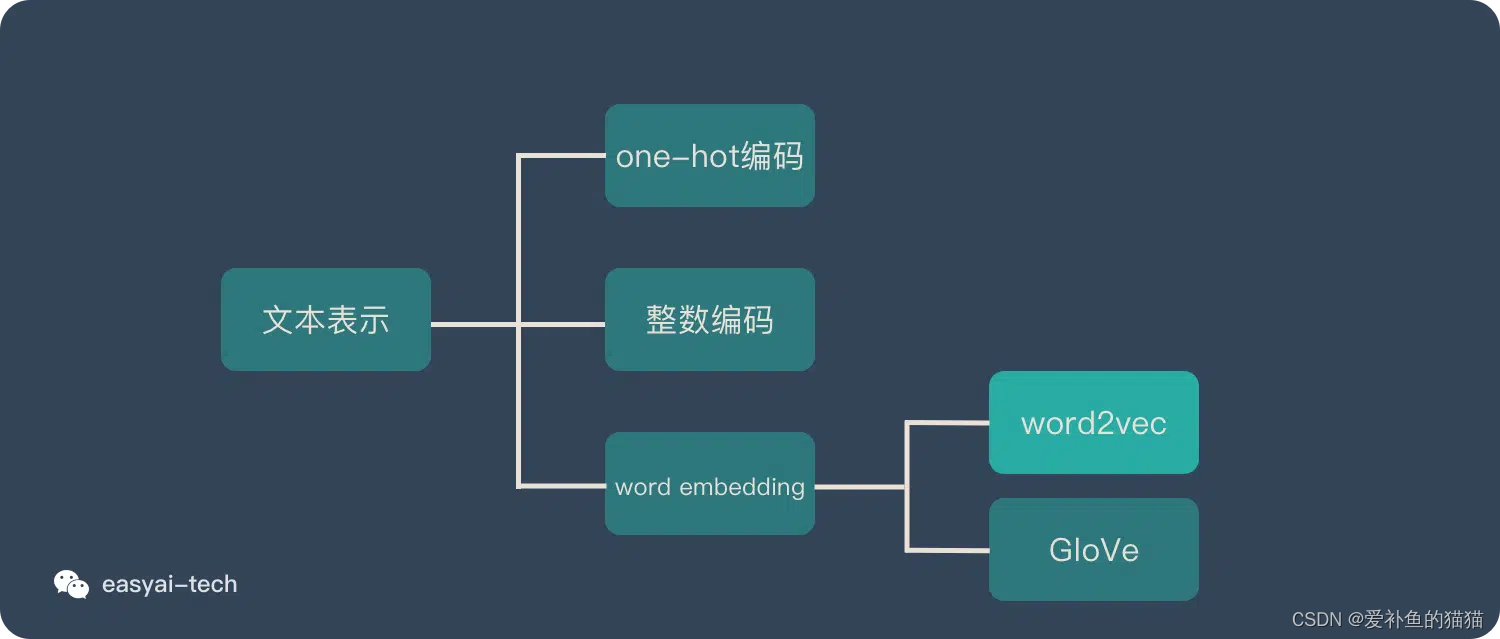
二、文本表示
文本表示可以分为:
-
离散式表示(Discrete Representation)
1.词向量的one-hot表示(独热编码)
2.文本表示:词袋模型(Bag Of Word)
3.文本表示:TF-IDF(词频-逆文本频率)
4.N-gram
参考:https://zhuanlan.zhihu.com/p/388907117 -
分布式表示(Distributed Representation);
矩阵分解(LSA):利用全局预料特征,但SVD求解计算复杂度大
基于NNML/RNNLM词向量:词向量为副产物,存在效率不高等问题
word2vec、fastText:优化效率高,但是基于局部语料
glove:基于全局语料,结合LSA和word2vec的优点
elmo、GPT、bert:动态特征
分词、词向量
三、各种表示方法
1.离散表示
1.One-Hot
One-Hot 编码又称为“独热编码”或“哑编码”,是最传统、最基础的词(或字)特征表示方法。这种编码将词(或字)表示成一个向量,该向量的维度是词典(或字典)的长度(该词典是通过语料库生成的),该向量中,当前词的位置的值为1,其余的位置为0。采用One-Hot编码方式来表示词向量非常简单,但缺点也是显而易见的,一方面我们实际使用的词汇表很大,经常是百万级以上,这么高维的数据处理起来会消耗大量的计算资源与时间。另一方面,One-Hot编码中所有词向量之间彼此正交,没有体现词与词之间的相似关系。
One-Hot独热编码的缺点:
维数过高:随着语料的增加,维数越来越大,导致维数灾难;
不保留语义:不考虑词与词之间的顺序问题,以及词之间的相互影响;
稀疏矩阵:得到的特征矩阵是离散的、稀疏的;
2.词集模型/词袋模型
词集(Set Of Word)模型:语料中单词构成的集合,每个单词只出现一次(一个词在文本中出现一次和出现多次是一样的)。
词袋(Bag Of Word)模型:顾名思义,将语料中所有单词装进一个袋子里,不考虑语法,统计每一个单词出现的次数。
词集模型仅考虑词是否在文本中出现,不考虑词频;词袋模型考虑了词频,但不考虑词与词之间的上下文关系,即仅考虑词在文本中出现的频率(权重)。

词袋模型缺点:
稀疏矩阵:与One-Hot编码一样,得到的特征矩阵是离散的、稀疏的;
不考虑词与词之间的关系:仅考虑词的权重;
3.TF-IDF(词频-逆文本频率)
TF-IDF是一种用于资讯检索和文本挖掘的常用加权技术。实际上是一种统计方法,通过一个词在文件和语料库中的出现的频率计算该词的重要性。
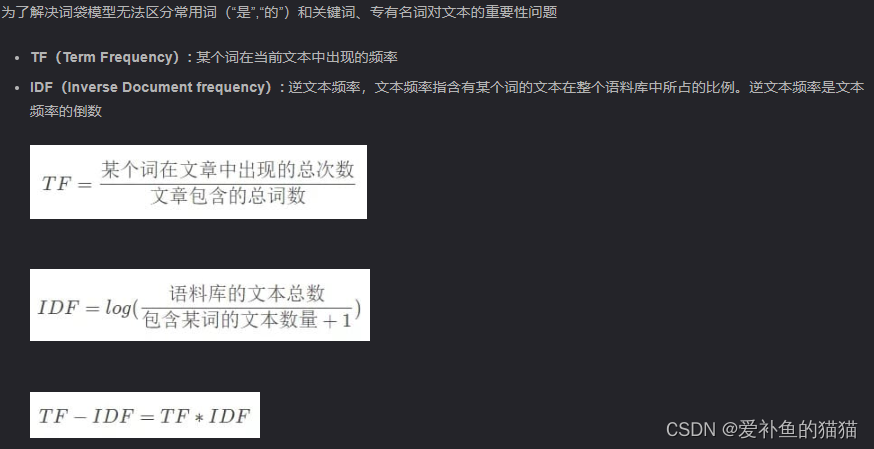
TF-IDF缺点:
不考虑词与词之间的关系:依然不能保留词语在句子中的位置;
易受数据集偏斜的影响:如某一类别的文档偏多,会导致IDF低估;
4.N-gram
使用TF-IDF可以表示一个词的重要性,但是无法表示词的顺序。举例来说:“我喜欢你”和“你喜欢我”两句话,其实是表达了两种完全不同的意义,但是TF-IDF会将这两句话表示成一样的向量。
如何引入句子的语序呢?N-gram模型基于马尔科夫假设提出,即下一个词的出现仅依赖前面的一个或n个词,而与其他任何词不相关。N-gram的基本思想是将文本里的内容按照字节大小为n的滑动窗口操作,形成长度是n的字节片段序列。假设有一个由m个词组成的文本,我们希望整个文本出现的概率等于文本中各个词出现的概率的乘积。
N-gram优点:比较好的记录了句子中词之间的联系;
N-gram缺点:n越大,句子的完整度越高,但是词的维度将指数级增长,所以一般情况下n值取2或3。
2. 分布式表示
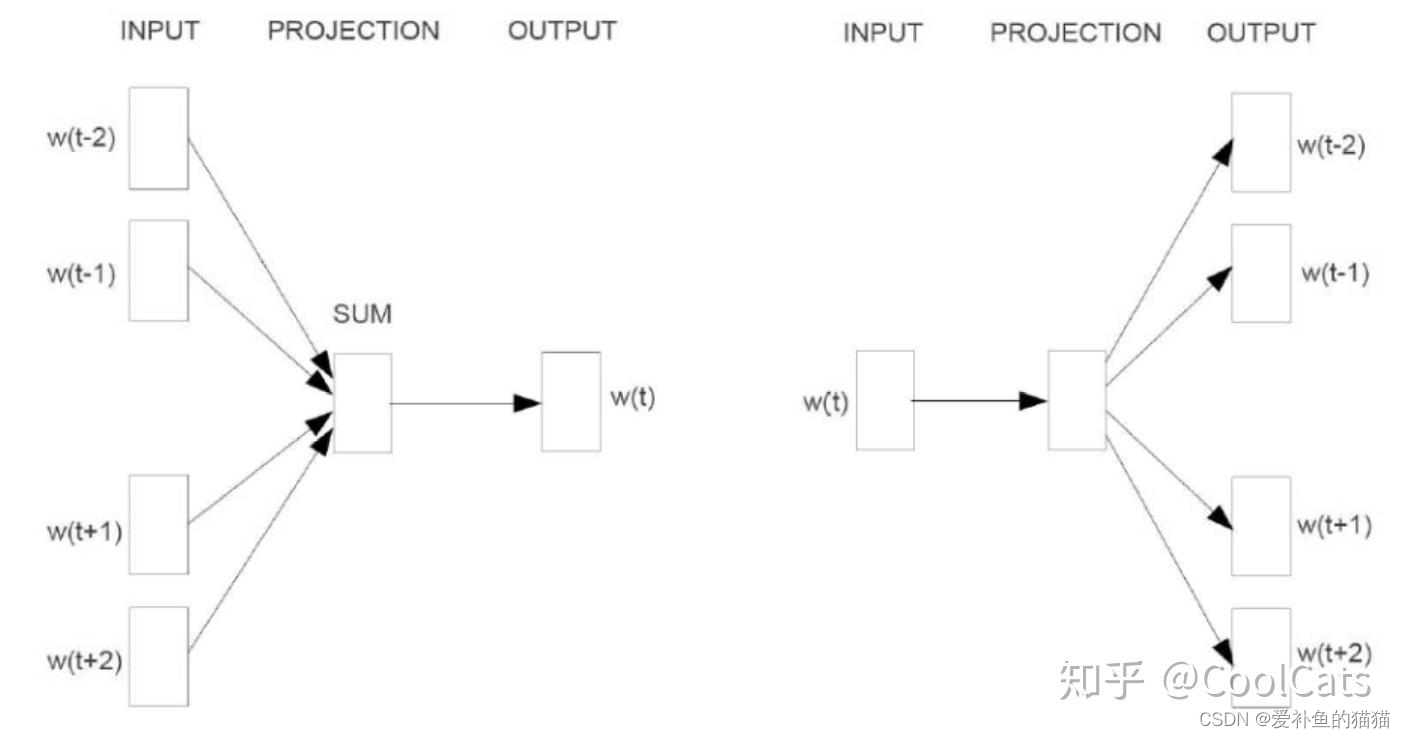
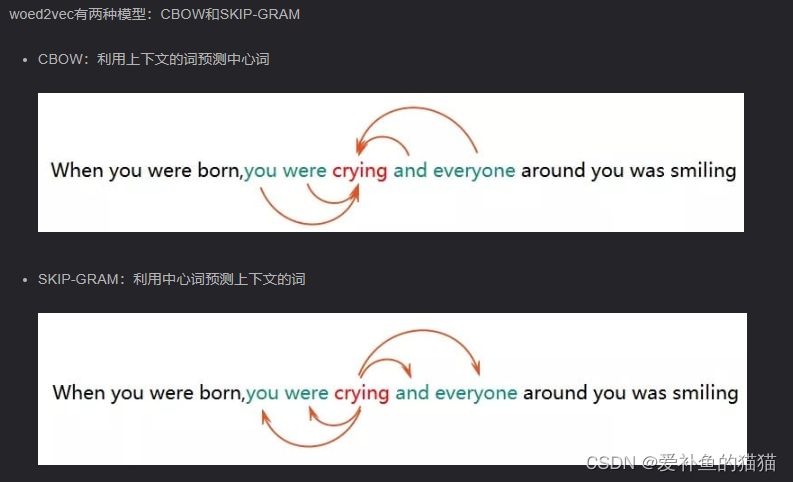
1.word2vec
word2vec的思路是,使用模型对one-hot词向量进行训练,将每个词都映射到较短的一个词向量上来,维度可通过训练时设置。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。
word2vec的基本思想正是分布式表示的思想,其有两类重要模型:CBOW和Skip-gram,如图3所示。两个模型都包含输入层、中间层、输出层,CBOW模型是在已知单词上下文的情况下预测当前单词 ,Skip-gram是在已知当前单词的情况下预测上下文。
在前面两节中我们介绍了CBOW和Skip-gram最理想情况下的实现,即训练迭代两个矩阵W和W’,之后在输出层采用softmax函数来计算输出各个词的概率。但在实际应用中这种方法的训练开销很大,不具有很强的实用性,为了使得模型便于训练,有学者提出了Hierarchical Softmax和Negative Sampling两种改进方法。
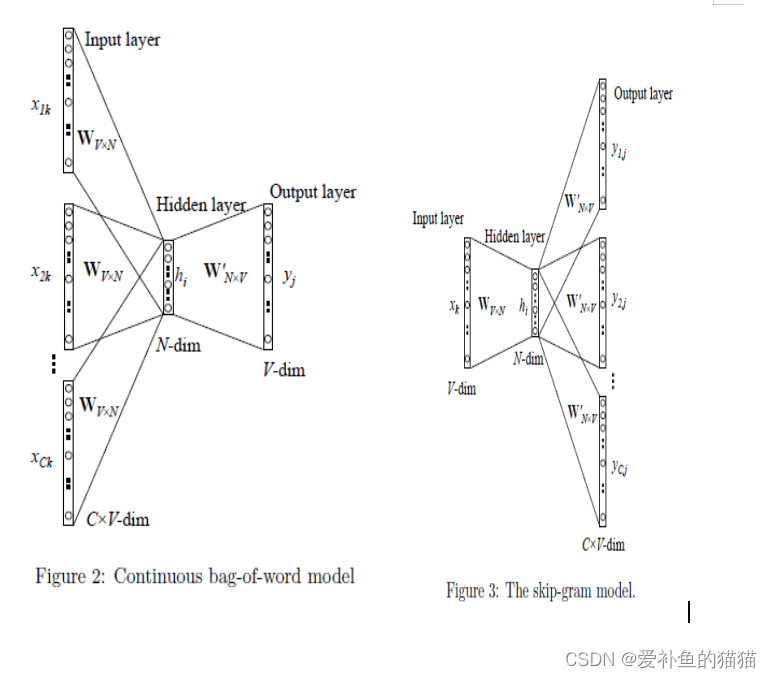
详细过程参考:
https://www.cnblogs.com/lfri/p/15032919.html
https://zhuanlan.zhihu.com/p/61635013
优点
考虑到词语的上下文,学习到了语义和语法的信息
得到的词向量维度小,节省存储和计算资源
通用性强,可以应用到各种NLP任务中
缺点
词与向量是一对一的关系,无法解决多义词的问题
word2vec是一种静态的模型,虽然通用性强,但无法做动态优化
2.CBOW
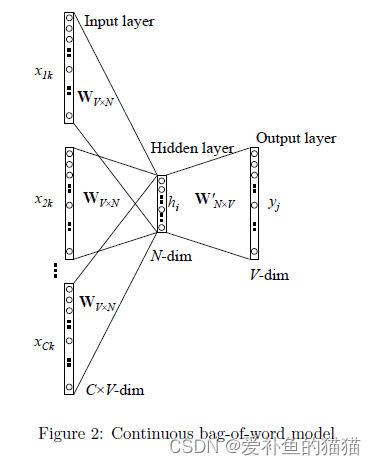

3.fastText
fastText是一个快速文本分类算法,与基于神经网络的分类算法相比有两大优点:
1、fastText在保持高精度的情况下加快了训练速度和测试速度
2、fastText不需要预训练好的词向量,fastText会自己训练词向量
3、fastText两个重要的优化:Hierarchical Softmax、N-gram
模型架构
之前提到过,fastText模型架构和word2vec的CBOW模型架构非常相似。下面是fastText模型架构图:
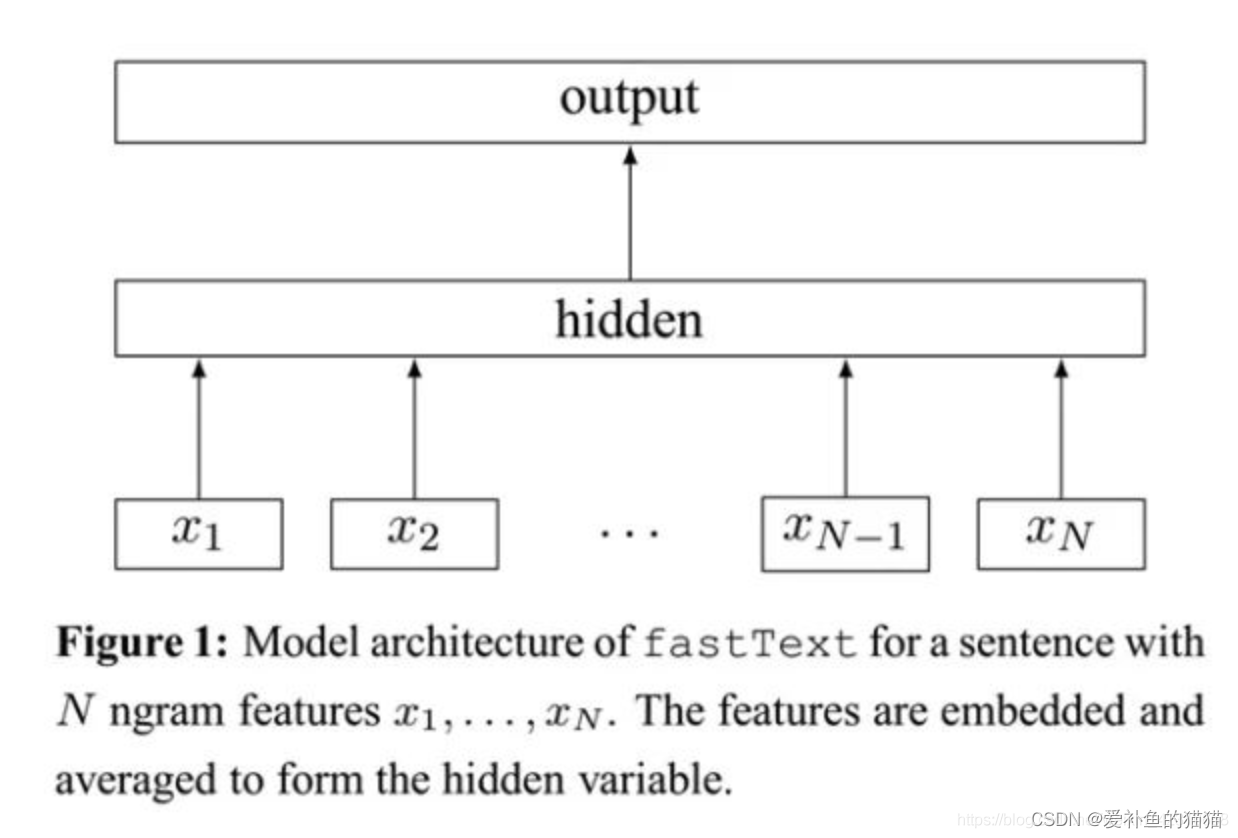
注意:此架构图没有展示词向量的训练过程。可以看到,和CBOW一样,fastText模型也只有三层:输入层、隐含层、输出层(Hierarchical Softmax),输入都是多个经向量表示的单词,输出都是一个特定的target,隐含层都是对多个词向量的叠加平均。不同的是,CBOW的输入是目标单词的上下文,fastText的输入是多个单词及其n-gram特征,这些特征用来表示单个文档;CBOW的输入单词被onehot编码过,fastText的输入特征是被embedding过;CBOW的输出是目标词汇,fastText的输出是文档对应的类标。
值得注意的是,fastText在输入时,将单词的字符级别的n-gram向量作为额外的特征;在输出时,fastText采用了分层Softmax,大大降低了模型训练时间。在标准的softmax中,计算一个类别的softmax概率时,我们需要对所有类别概率做归一化,在这类别很大情况下非常耗时,因此提出了分层softmax(Hierarchical Softmax),思想是根据类别的频率构造霍夫曼树来代替标准softmax,通过分层softmax可以将复杂度从N降低到logN,
参考链接:https://blog.csdn.net/feilong_csdn/article/details/88655927
fastText和cbow的区别
fastText和cbow的结构一样,都是n个输入单元,得到隐藏层,再得到一个输出单元,但fastText输出的是文本分类,而cbow输出的则是预测的中间词。
fastText和cbow的区别主要如下:
- 目的不一样,fastText是用来做文本分类的,虽然中间也会产生词向量,但词向量是一个副产物,而CBOW就是专门用来训练词向量的工具。
- cbow用单个词进行训练,而fastText则采用ngram训练。cbow不能引入词序信息,比如“我爱你”的词袋特征是“我”“爱”“你”,而“你爱我“的词袋特征是“你”“爱”“我”,这两个句子的特征是完全相同的。如果加入Ngram,这两个句子的特征就不同了,“我爱你”的特征由加入了“我爱”和“爱你”,你爱我的特征有加入了“你爱”和“爱我”,用Ngram得到的特征是完全不同的,这两句话就能区别开了。
- fastText的输入层是一个句子的每个词以及句子的ngram特征,而CBOW的输入层只是中间词的上下文,与完整句子没有关系。
- fastText是一个文本分类算法,是一个有监督模型,有额外标注的标签,CBOW是一个训练词向量的算法,是一个无监督模型,没有额外的标签,其标准是语料本身,无需额外标注。
四、发展史
2013年,Google提出的 Word2vec[4]通过神经网络预训练方式来生成词向量(Word Embedding),极大地推动了深度自然语言处理的发展。针对Word2vec生成的固定词向量无法解决多义词的问题,2018年,Allen AI团队提出基于双向LSTM网络的ELMo[5]。ELMo根据上下文语义来生成动态词向量,很好地解决了多义词的问题。2017年底,Google提出了基于自注意力机制的Transformer[6]模型。相比RNN模型,Transformer语义特征提取能力更强,具备长距离特征捕获能力,且可以并行训练,在机器翻译等NLP任务上效果显著。Open AI团队的GPT[7]使用Transformer替换RNN进行深层单向语言模型预训练,并通过在下游任务上Fine-tuning验证了Pretrain-Finetune范式的有效性。在此基础上,Google BERT引入了MLM(Masked Language Model)及NSP(Next Sentence Prediction,NSP)两个预训练任务,并在更大规模语料上进行预训练,在11项自然语言理解任务上刷新了最好指标。
5、句向量
句向量获取方式
NLP中获得句向量有两种方式:
(1) 通过词向量后处理得到句向量;
(2) 直接得到句向量
-
词向量获得句向量
1)累加法:
累加法是得到句子向量最简单的方法,累加法的做法是将句子中所有非停用词的词向量叠加。
2)平均词向量:
平均词向量就是将句子中所有词的word embedding相加取平均,得到的向量就当做最终的sentence embedding。这种方法的缺点是认为句子中的所有词对于表达句子含义同样重要。
3)TF-IDF加权平均词向量:
TFIDF加权平均词向量就是对每个词按照 TF-IDF 进行打分,然后进行加权平均,得到最终的句子表示。
4)SIF加权平均词向量:
ISF加权平均法和TF-IDF加权平均法类似,此方法可以很好的根据每个词词向量得到整个句子的句向量。SIF嵌入法需要利用主成分分析和每个词语的estimated probability。
链接:https://blog.csdn.net/Matrix_cc/article/details/105138478 -
直接得到句向量
上文介绍的通过对词向量后处理得到句向量的方法,有一个最大的缺陷,就是忽略了词语中间的顺序对整个句子的影响,所以有些学者提出了直接得到句向量的方法。常用的直接得到句向量方法为Doc2Vec和Bert。下面将分别简单介绍这两种方法。
1)Doc2Vec
Doc2vec是在Word2vec的基础上做出的改进,它不仅考虑了词和词之间的语义,也考虑了词序。Doc2Vec模型Doc2Vec有两种模型,分别为:
句向量的分布记忆模型(PV-DM)、句向量的分布词袋(PV-DBOW)PV-DM模型
注:Doc2vec的DM模型跟Word2vec的CBOW很像,DBOW模型跟Word2vec的Skip-gram很像。Doc2Vec为不同长度的段落训练出同一长度的向量;不同段落的词向量不共享;训练集训练出来的词向量意思一致,可以共享。DBOW模型在给定文档向量的情况下预测文档中一组随机抽样的单词的概率。
2)Bert
采用由词向量通过各种方法后处理得到句向量有一个最大的弊端——那就是无法理解上下文的语义,同一个词在不同的语境意思可能不一样,但是却会被表示成同样的词向量,这样对含多义词句子的语义计算产生不利的影响。而Bert生成的句向量没有上述的缺陷,同一个词语在不同语境下的向量是不同的,多义词因为上下文环境的不同而产生不同的向量,这样bert生产的句向量可以真正应用于语义计算中。BERT生成句向量的优点不仅在于可理解句意,并且排除了词向量加权引起的误差。
BERT是N层 transformer构成的,每一层transformer的输出值,理论上来说都可以作为句向量。但真正进行使用,选取倒数第二层来作为句向量的效果是最好的,因为Bert的最后一层的值太接近于训练任务目标,Bert前面几层transformer的可能还未充分的学习到语义特征 ,因此选择Bert倒数第二层作为句向量是比较合适的。
参考:https://juejin.cn/post/7007326439934525471、https://zhuanlan.zhihu.com/p/350957155
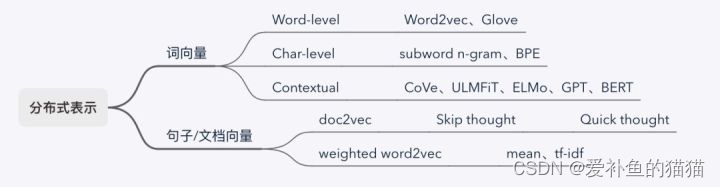
1.词带(袋)模型:词库有多少词,就用多长的向量记录句子中每个词出现的次数
2.TFidF模型:考虑词所占的权重
3.Word2vec模型:词向量模型将所有词分成相关的词向量(上下文),获得embedding,将句子所有词的向量相同位置相加求均值。
4、深度学习模型:考虑句子中词的先后顺序
文档/句子表示
词集模型
类似one hot编码。采用词典大小的向量表示句子,每一个维度表示某个单词是否是句子的组成部分。明显的不足在于,忽略了单词间的顺序,没有显式地把单词的上下文信息考虑进去。
词袋模型
将单词在句子中出现的频率信息也考虑上
tf-idf
基本思想是:某些出现次数重要的单词可能并不重要。具体来说,tf-idf认为在所有文档中都出现得多的单词不具有区分性,只在少数文档出现得多的单词具有较强的区分性。因此在表示句子时,综合考虑单词在该文档中的出现频率和单词在所有文档中出现的频率。tf(d,w)表示单词在当前文档d中出现的频率,idf(w)表示逆文档频率,如(8)所示,N是语料库中文档总数,N(w)表示词语w出现在多少个文档中。
平均池化
基于word2vec等方法可以得到单词的词向量表示,平均池化就是简单粗暴地将组成句子的所有单词的词向量进行平均。意外的是,据说这样做效果很好(对于文档分类、相似性度量等任务而言)
6、网络语言模型(NNLM)
统计和网络模型对比
-
统计语言模型
有了上面的基础,我们可以稍微总结下语言模型到底在建模什么,私以为可以看作是在给定一个序列的前提下,预测下一个词出现的概率,即

不论 n-gram 中的 n 怎么选取,实际上都是对上式的近似。理解了这点,就不难理解神经网络语言模型的本质。 -
网络语言模型
神经网络语言模型(NNLM)通过构建神经网络的方式来探索和建模自然语言内在的依赖关系。尽管与统计语言模型的直观性相比,神经网络的黑盒子特性决定了NNLM的可解释性较差,但这并不妨碍其成为一种非常好的概率分布建模方式。
优点:(1) 长距离依赖,具有更强的约束性;(2) 避免了数据稀疏所带来的OOV问题;(3) 好的词表征能够提高模型泛化能力。
缺点:(1) 模型训练时间长;(2) 神经网络黑盒子,可解释性较差。 -
从特性上可以将 n-gram 语言模型看作是基于词与词共现频次的统计,而神经网络语言模型则是给每个词分别赋予分布式向量表征,探索它们在高维连续空间中的依赖关系。实验证明,神经网络的分布式表征以及非线性映射更加适合对自然语言进行建模。 从n元模型到神经网络语言模型, 明显神经网络语言模型更胜一筹。 从深度学习方法在机器翻译领域获得突破后, 深度学习技术在NLP上已经几乎全面超过了传统的方法。
网络语言模型发展史
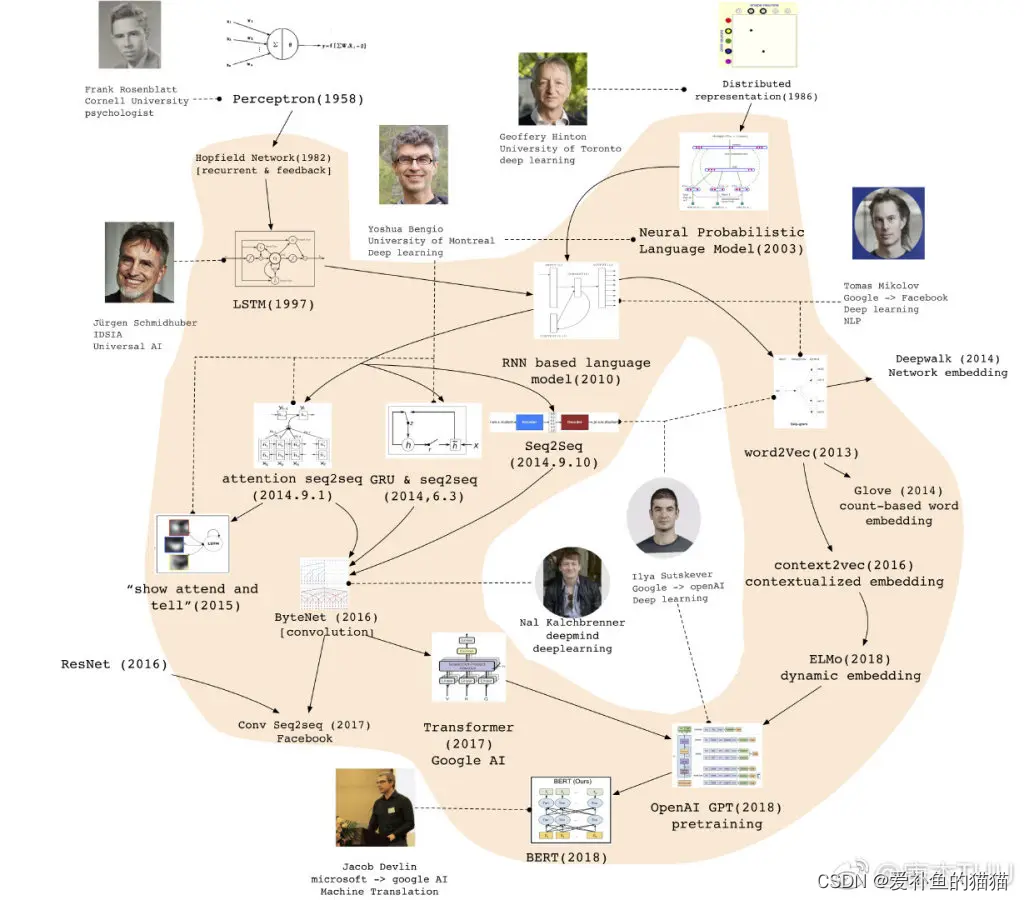
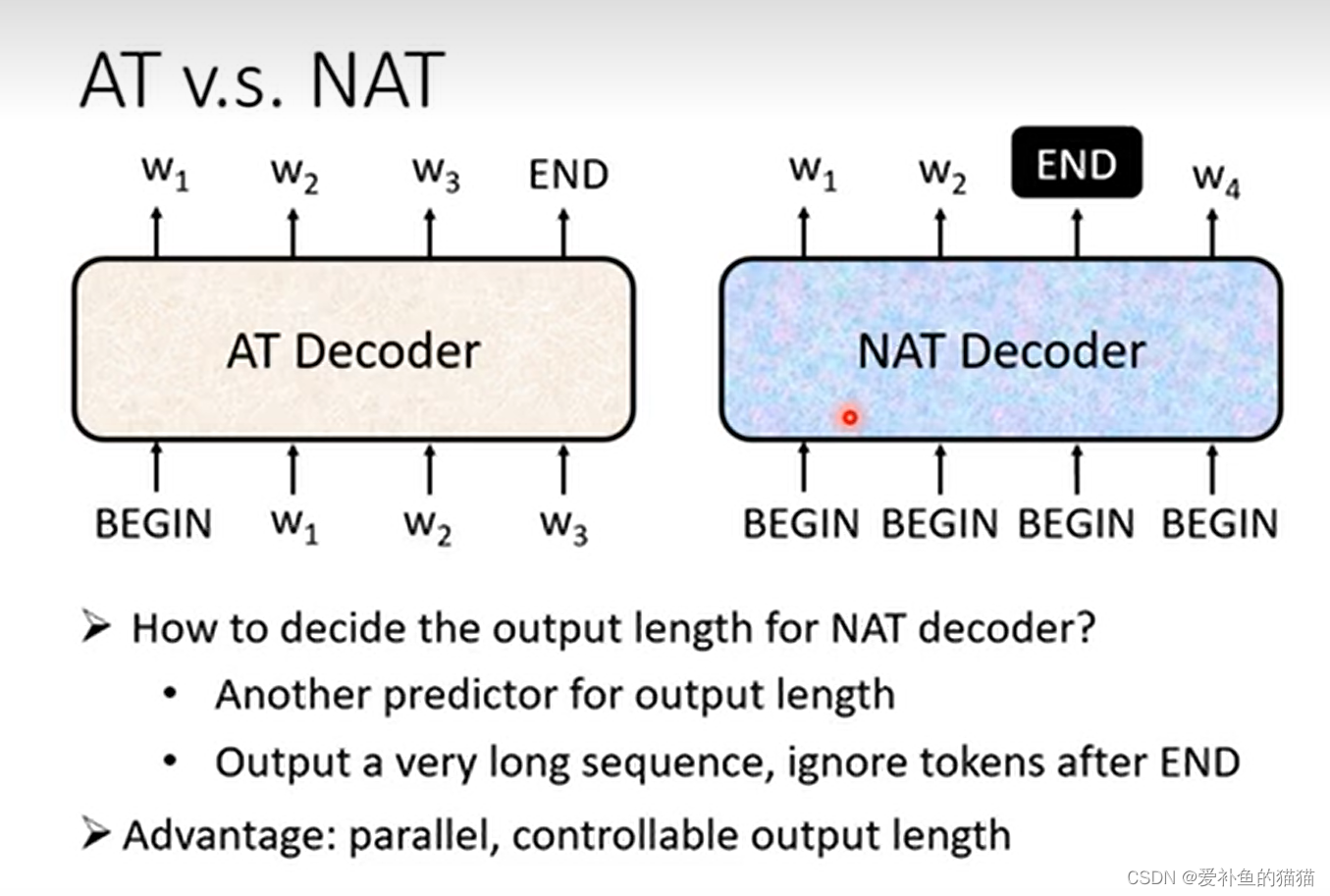
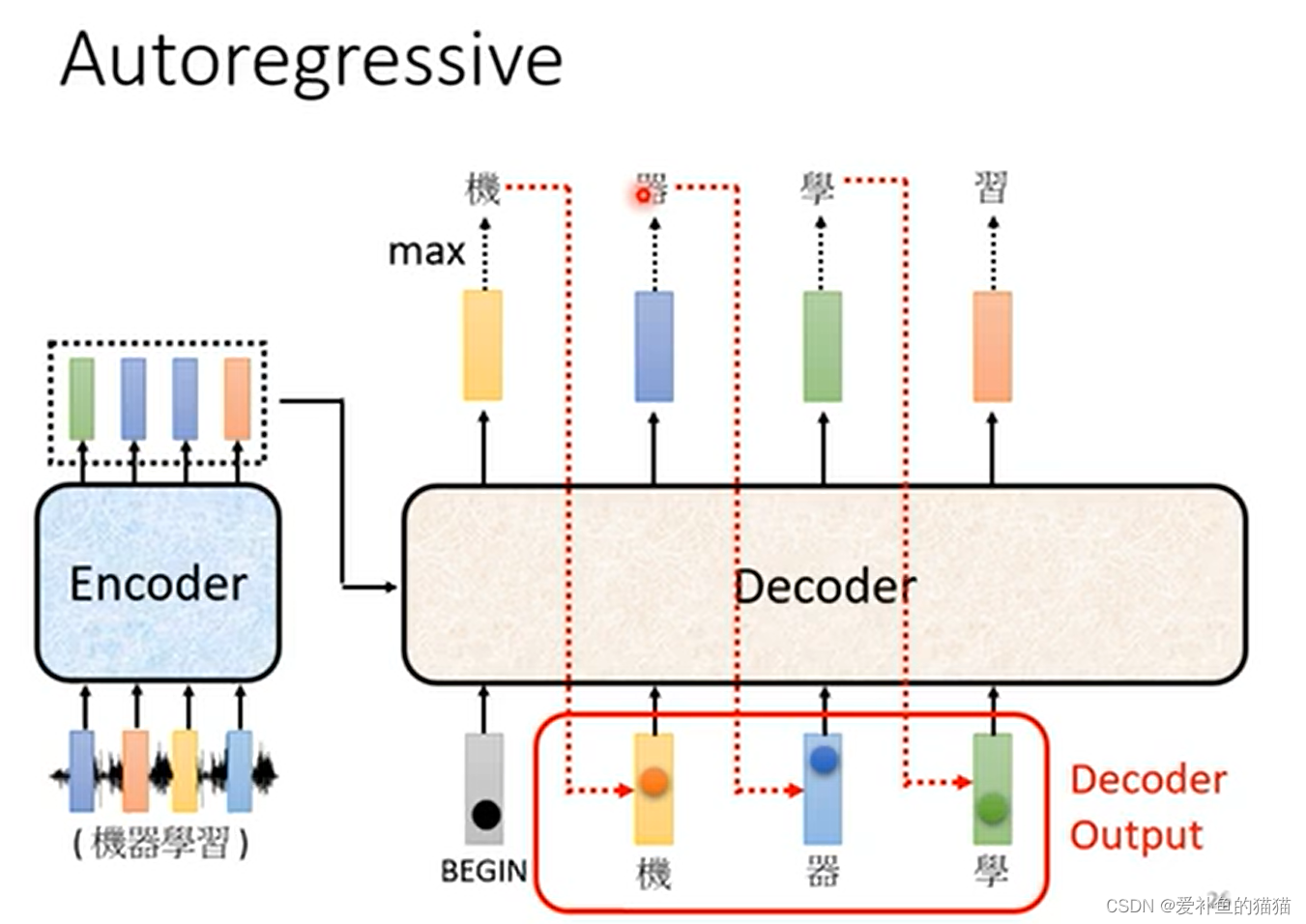
7、seq2seq
没时间写 待更新
8、Attention注意力机制
Attention相关
- Bahdanau attention
- Luong_attention
- Self_attention
- 其他attention
参考:https://blog.csdn.net/weixin_49528551/article/details/120802222
应用于seq2seq模型的两种attention机制:Bahdanau Attention和Luong Attention。
2.1 Attention 和 Self - Attention的区别
- Attention:
传统的Attention机制发生在 Target的元素 和 Source中的所有元素 之间。 在一般任务的Encoder-Decoder框架中,输入 Source 和输出 Target 内容是不一样的,比如对于英 - 中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子。 - Self - Attention
Self - Attention 顾名思义,指的不是 Target 和 Source 之间的 Attention 机制,而是 Source 内部元素之间或者 Target 内部元素之间发生的 Attention 机制,其具体计算过程是一样的,只是计算对象发生了变化而已,相当于是 Query=Key=Value,计算过程与attention一样。 (例如在Transformer中在计算权重参数时,将文字向量转成对应的 QKV,只需要在 Source 处进行对应的矩阵操作,用不到Target中的信息。)
总结区别: 1. Self-attention 关键点在于,规定K-Q-V三者都来源于 X。通过 X 找到 X 中的关键点。可以看作 QKV 相等,都是由词向量线性变换得到的,并不是 Q=V=K=X,而是 X 通过 Wk、Wq、Wv 线性变换而来。 2. Attention 是通过一个查询变量 Q 找到 V 里面重要信息,K 由 V 变幻而来,QK=A ,AV = Z(注意力值) ,Z 其实是 V 的另一种表示,也可以称为词向量,具有句法和语意特征的 V 3. 也就是说,self-attention 比 attention 约束条件多了两个: (1) Q=K=V(同源) (2) Q,K,V需要遵循attention的做法
9、transformer系列
1.文本领域
BERT 用于生成embedding词向量,transform编码encode部分,替代之前的Word2vec生成词向量
;
2.cv领域
VIT 图像分块注意力机制,用于分类
swin 窗口和分层结构backbone,目标检测
DETR VIT用于目标检测
Medical transformer 计算像素点行列注意力机制,qkv都加位置编码,图像分割
LoFTR 图像特征点匹配
bert和GPT的相同点和不同点
语言模型:Bert和GPT-2虽然都采用transformer,但是Bert使用的是transformer的encoder,即:Self Attention,是双向的语言模型;而GPT-2用的是transformer中去掉中间Encoder-Decoder Attention层的decoder,即:Masked Self Attention,是单向语言模型。
结构:Bert是pre-training + fine-tuning的结构;而GPT-2只有pre-training。
输入向量:GPT-2是token embedding + prosition embedding;Bert是 token embedding + position embedding + segment embedding。
参数量:Bert是3亿参数量;而GPT-2是15亿参数量。
Bert引入Masked LM和Next Sentence Prediction;而GPT-2只是单纯的用单向语言模型进行训练,没引入这两个。
Bert不能做生成式任务,而GPT-2可以。
————————————————
版权声明:本文为CSDN博主「ct5ctl」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/AAArwei/article/details/128649938
10、时间系列
RNN、LSTM、Informer
11、GPT
Bert完形填空上下文,GPT预测未来
NLP预训练模型:Word2Vec、ELMO、Attention、BERT、XLNet
11、NLP子任务:NER、情感分类、机器翻译、问答机器人
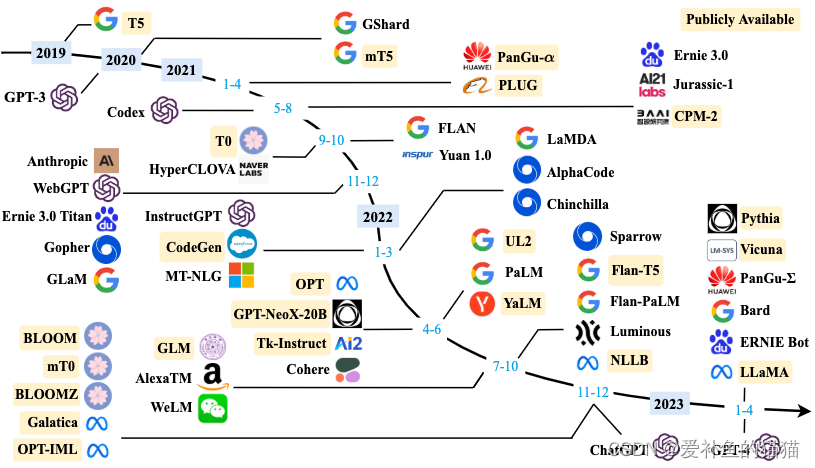
12、LLM
大型语言模型(LLM)的定义
大型语言模型(LLM) 是由大量的参数(十亿或更多)的神经网络组成的语言模型,使用无/半监督学习对大量样本进行训练。
目前,大型语言模型(LLM)已经改变了许多领域,包括自然语言处理、计算机视觉等。作为一个通用的语言模型,其用途广泛,而非针对一项特定任务(例如情感分析、命名实体识别或数学推理)进行训练。
语言模型的发展阶段
大型语言模型的发展,大概分成了三个阶段,第一个是序列模型用于NLP任务阶段,第二,以transformer为基础形成的GPT,BERT等大语言模型。第三,以GPT-3为基础的chatGPT的发布,目前GPT-4.5已经在bing和chatGPT中逐步使用。
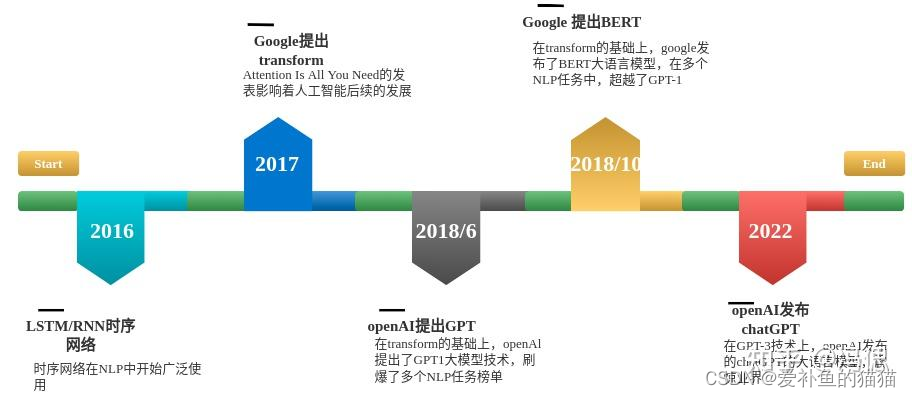
许多没时间写 待更新
各位成功人 有兴趣的可以补充提稿