文章目录
今天详解一下SqueezeNet算法,SqueezeNet是一种轻量且高效的CNN模型,它参数比AlexNet少50倍,但模型性能(accuracy)与AlexNet接近。
本次实战还是一个经典的分类问题:鸟类分类。
本次项目实战鸟类数据集主要分为4类,分别为bananaquit(蕉林莺)、Black Skimmer (黑燕鸥类)、Black Throated Bushtiti (黑喉树莺)、Cockatoo (凤头鹦鹉或葵花鹦鹉),总计565张。

一、理论基础
1.前言
SqueezeNet算法,顾名思义,Squeeze的中文意思是压缩和挤压的意思,所以我们通过算法的名字就可以猜想到,该算法一定是通过解压模型来降低模型参数量的。当然任何算法的改进都是在原先的基础上提升精度或者降低模型参数,因此该算法的主要目的就是在于降低模型参数量的同时保持模型精度。
随着CNN卷积神经网络的研究发展,越来越多的模型被研发出来,而为了提高模型的精度,深层次的模型例如AlexNet和ResNet等得到了大家的广泛认可。但是由于应用场景的需求,许多模型因为参数量太大的原因而无法满足实际的应用场景需求,例如自动驾驶等技术。所以人们开始把注意力放在了轻量级模型上面,
SqueezeNet模型也因此“应时而生”。
SqueezeNet论文中对轻量级模型的优点做了以下几点总结:
● 更高效的分布式训练。服务器间的通信是分布式CNN训练可扩展性的限制因素。对于分布式数据并行训练,通信开销与模型中参数的数量成正比。简而言之,小模型训练更快,因为需要更少的交流。
● 在向客户导出新模型时减少开销。在自动驾驶方面,特斯拉(Tesla)等公司会定期将新车型从服务器复制到客户的汽车上。这种做法通常被称为无线更新。《消费者报告》发现,随着最近的无线更新,特斯拉Autopilot半自动驾驶功能的安全性得到了逐步提高(《消费者报告》,2016年)。然而,今天典型的CNN/DNN模型的无线更新可能需要大量的数据传输。使用AlexNet,这将需要从服务器到汽车的240MB通信。较小的模型需要较少的通信,使频繁更新更可行。
● 可行的FPGA和嵌入式部署。fpga的片内存储器通常小于10MB1,没有片外存储器或存储器。对于推理,足够小的模型可以直接存储在FPGA上,而不会受到内存带宽的瓶颈(Qiu et al ., 2016),而视频帧则实时通过FPGA。此外,当在专用集成电路(ASIC)上部署cnn时,足够小的模型可以直接存储在芯片上,而更小的模型可以使ASIC适合更小的芯片。

2.设计理念
减少模型参数的方法以往就有,一个明智的方法是采用现有的CNN模型并以有损方式压缩它。近年来围绕模型压缩的主题已经出现了一个研究社区,并且已经报道了几种方法。Denton等人的一种相当直接的方法是将奇异值分解(SVD)应用于预训练的CNN模型。Han等人开发了网络剪枝(Network Pruning),从预训练模型开始,将低于某阈值的参数替换为零,形成稀疏矩阵,最后在稀疏CNN上进行几次迭代训练。Han等人将网络修剪与量化(至8位或更少)和霍夫曼编码相结合,扩展了他们的工作,创建了一种称为深度压缩(Deep Compression)的方法,并进一步设计了一种称为EIE的硬件加速器,该加速器直接在压缩模型上运行,实现了显著的加速和节能。
而SqueezeNet算法的主要策略也是压缩策略,在模型压缩上,总共使用了三种方法策略,具体我们下面讲述。
2.1 CNN微架构(CNN MicroArchitecture)
同时,SqueezeNet论文作者考虑到随着设计深度CNN卷积神经网络的趋势,手动选择每层滤波器的尺寸变得非常麻烦。所以为了解决这个问题,网上已经有提出了由具有特定固定组织的多个卷积层组成的各种高级构建块或者模块。例如,GoogleNet的论文提出了Inception模块,它由许多不同维度的过滤器组成,通常包括 1 × 1 1\times1 1×1和 3 × 3 3\times3 3×3,有时候会加上 5 × 5 5\times5 5×5,有时加上 1 × 3 1\times3 1×3和 3 × 1 3\times1 3×1,可能还会加上额外的特设层,形成一个完整的网络。我们上一篇讲解的WideResNet算法中也曾讲解到一个类似的块,即残差块。SqueezeNet论文作者将这种各个模块的特定组织和维度统称为CNN微架构。
2.2 CNN宏架构(CNN MacroArchitecture)
CNN微架构指的是单独的层和模块,而CNN宏架构可以定义为多个模块的系统级组织,形成端到端的CNN体系结构。也许在最近的文献中,最广泛研究的CNN宏观架构主题是网络中深度(即层数)的影响。如VGG12-19层在ImageNet-1k数据集上产生更高的精度。选择跨多层或模块的连接是CNN宏观架构研究的一个新兴领域。例如残差网络(ResNet)和高速公路网络(Highway Network)中都建议采用跳过多层的连接,比如将第3层的激活附加地连接到第6层的激活,我们把这种连接称为旁路连接。ResNet的作者提供了一个34层CNN的A/B比较,有和没有旁路连接(即跳跃连接),实验对比发现添加旁路连接可将ImageNet前5名的精度提高2个百分点。
2.3 模型网络设计探索过程
论文作者认为,神经网络(包括深度神经网络DNN和卷积神经网络CNN)有很大的设计空间,有许多微体系结构、宏观体系结构、求解器和其他超参数的选择。很自然,社区想要获得关于这些因素如何影响神经网络准确性的直觉(即设计空间的形状)。神经网络的设计空间探索(DSE)的大部分工作都集中在开发自动化方法来寻找提供更高精度的神经网络架构。这些自动化的DSE方法包括贝叶斯优化(Snoek et al, 2012)、模拟退火(Ludermir et al, 2006)、随机搜索(Bergstra & Bengio, 2012)和遗传算法(Stanley & Miikkulainen, 2002)。值得赞扬的是,这些论文中的每一篇都提供了一个案例,其中提议的DSE方法产生了一个与代表性基线相比具有更高精度的NN架构。然而,这些论文并没有试图提供关于神经网络设计空间形状的直觉。在SqueezeNet论文的后面,作者避开了自动化的方法——相反,作者重构CNN,这样就可以进行有原则的a /B比较,以研究CNN架构决策如何影响模型的大小和准确性。
2.4 结构设计策略
SqueezeNet算法的主要目标是构建具有很少参数的CNN架构,同时保证具有其它模型也有的精度。为了实现这一目标,作者总共采用了三种策略来设计CNN架构,具体如下:
策略1: 将 3 × 3 3×3 3×3卷积替换成 1 × 1 1×1 1×1卷积:通过这一步,一个卷积操作的参数数量减少了 9 9 9倍;
策略2: 减少 3 × 3 3\times3 3×3卷积的通道数:一个 3 × 3 3\times3 3×3卷积的计算量是 3 × 3 × M × N 3\times3\times M\times N 3×3×M×N(其中M,N分别是输入特征图和输出特征图的通道数),作者认为这样一个计算量过于庞大,因此希望尽可能地将M和N减少以减少参数数量。
策略3: 在网络的后期进行下采样,这样卷积层就有了大的激活图。在卷积网络中,每个卷积层产生一个输出激活图,其空间分辨率至少为1x1,通常比1x1大得多。这些激活图的高度和宽度由:(1)输入数据的大小(例如256x256图像)和(2)在CNN体系结构中下采样层的选择。
其中策略1和策略2是关于明智地减少CNN中参数的数量,同时试图保持准确性。策略3是关于在有限的参数预算下最大化准确性。接下来,我们描述Fire模块,这是我们的CNN架构的构建块,使我们能够成功地采用策略1、2和3。
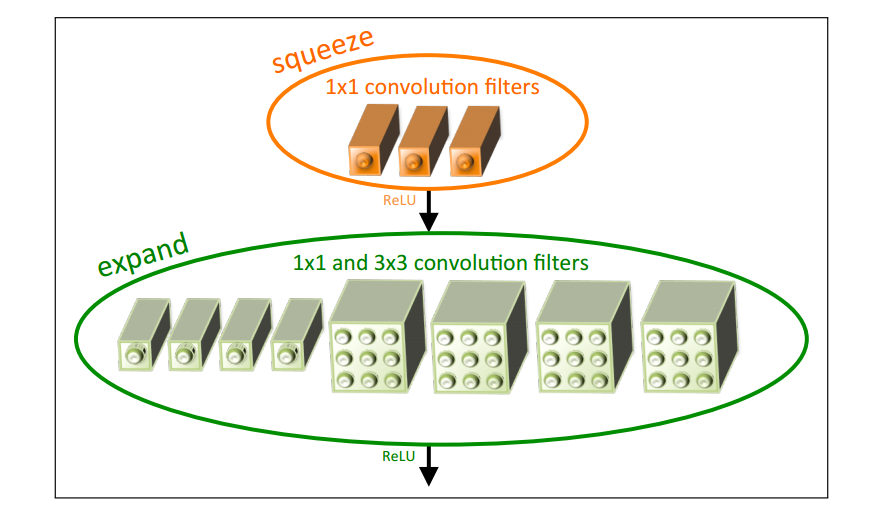
2.5 Fire模块
Fire模块包括:挤压卷积层(squeeze convolution),输入扩展层(expand),其中有 1 × 1 1\times1 1×1和 3 × 3 3\times3 3×3卷积滤波器的混合。在挤压卷积层中只有 1 × 1 1\times1 1×1卷积滤波器,而扩展层中混合有 1 × 1 1\times1 1×1和 3 × 3 3\times3 3×3卷积滤波器。同时该模块中引入了三个调节维度的超参数:
● s 1 x 1 s_{1x1} s1x1: squeeze 中 1 × 1 1 \times 1 1×1卷积滤波器个数 ;
● e 1 x 1 e_{1x1} e1x1: expand 中 1 × 1 1\times1 1×1 卷积滤波器个数 ;
● e 3 x 3 e_{3x3} e3x3: expand 中 3 × 3 3 \times 3 3×3 卷积滤波器个数 ;
3.网络结构
SqueezeNet的网络架构如下图所示:

● 左图:SqueezeNet ;
● 中图:带简单旁路的 SqueezeNet ;
● 右图:带复杂旁路的 SqueezeNet ;
由图1-2中的左图我们可以看出,SqueezeNet是先从一个独立的卷积层(Conv1)开始,然后经过8个Fire模块(fire2-9),最后以一个卷积层(Conv10)结束。从网络的开始到结束,我们逐渐增加每个fire模块的过滤器数量。在conv1、fire4、fire8和conv10层之后,SqueezeNet以2步长执行最大池化;这些相对较晚的池放置是根据2.4中的策略3。
而简单旁路架构在模块3、5、7和9周围增加了旁路连接,要求这些模块在输入和输出之间学习残差函数。与ResNet一样,为了实现绕过Fire3的连接,将Fire4的输入设置为(Fire2的输出+ Fire3的输出),其中+运算符是元素加法。这改变了应用于这些Fire模块参数的正则化,并且,根据ResNet,可以提高最终的准确性或训练完整模型的能力。
虽然简单的旁路“只是一根线”,但复杂的旁路包含1x1卷积层的旁路,其滤波器数量设置等于所需的输出通道数量。
注意:在简单的情况下,输入通道的数量和输出通道的数量必须相同。因此,只有一半的Fire模块可以进行简单的旁路连接,如图2中图所示。当不能满足“相同数量的通道”要求时,我们使用复杂的旁路连接,如图1-2右侧所示。复杂的旁路连接会向模型中添加额外的参数,而简单的旁路连接则不会。
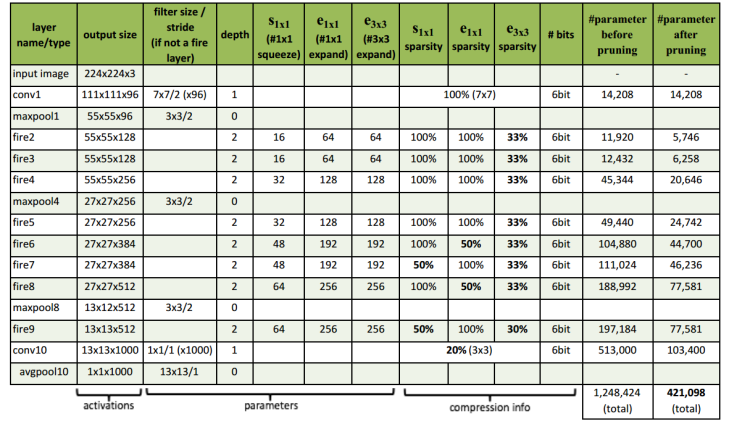
完整的SqueezeNet架构如下图所示:
4.评估分析
比较SqueezeNet和不同模型压缩方法结果图如下:

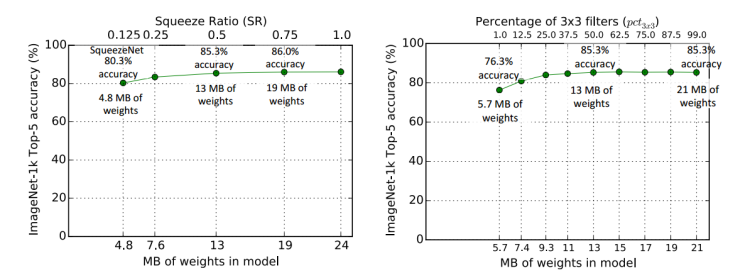
微架构下挤压比率(SR)对模型尺寸和精度的影响以及扩展层中 3 × 3 3\times3 3×3过滤器的比例对模型尺寸和精度的影响实验对比图如下所示:
宏架构中三种结构(普通架构、简单旁支架构和复杂旁支架构)精度对比图如下:

二、实战
1.数据预处理
!unzip /home/aistudio/data/data223822/bird_photos.zip -d /home/aistudio/work/dataset
由于我们处理数据集文件的时候,里面多一个ipynb_checkpoints文件,因此需要通过以下命令删除以下。切记!一定要删除~
%cd /home/aistudio/work
!rm -rf .ipynb_checkpoints
- 划分数据集
import os
import random
train_ratio = 0.7
test_ratio = 1-train_ratio
rootdata = "/home/aistudio/work/dataset"
train_list, test_list = [],[]
data_list = []
class_flag = -1
for a,b,c in os.walk(rootdata):
for i in range(len(c)):
data_list.append(os.path.join(a,c[i]))
for i in range(0, int(len(c)*train_ratio)):
train_data = os.path.join(a, c[i])+' '+str(class_flag)+'\n'
train_list.append(train_data)
for i in range(int(len(c)*train_ratio),len(c)):
test_data = os.path.join(a,c[i])+' '+str(class_flag)+'\n'
test_list.append(test_data)
class_flag += 1
random.shuffle(train_list)
random.shuffle(test_list)
with open('/home/aistudio/work/train.txt','w',encoding='UTF-8') as f:
for train_img in train_list:
f.write(str(train_img))
with open('/home/aistudio/work/test.txt', 'w', encoding='UTF-8') as f:
for test_img in test_list:
f.write(test_img)
2.数据读取
- 导入以下所需库
import paddle
import paddle.nn.functional as F
import numpy as np
import math
import random
import os
from paddle.io import Dataset # 导入Datasrt库
import paddle.vision.transforms as transforms
import paddle.nn as nn
import numpy as np
from PIL import Image
- 使用 paddle.io.DataLoader 定义数据读取器
# 归一化
transform_BZ = transforms.Normalize(
mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5]
)
class LoadData(Dataset):
def __init__(self, txt_path, train_flag=True):
self.imgs_info = self.get_images(txt_path)
self.train_flag = train_flag
self.train_tf = transforms.Compose([
transforms.Resize(224), # 调整图像大小为224x224
transforms.RandomHorizontalFlip(), # 随机左右翻转图像
transforms.RandomVerticalFlip(), # 随机上下翻转图像
transforms.ToTensor(), # 将 PIL 图像转换为张量
transform_BZ # 执行某些复杂变换操作
])
self.val_tf = transforms.Compose([
transforms.Resize(224), # 调整图像大小为224x224
transforms.ToTensor(), # 将 PIL 图像转换为张量
transform_BZ # 执行某些变换操作
])
def get_images(self, txt_path):
with open(txt_path, 'r', encoding='utf-8') as f:
imgs_info = f.readlines()
imgs_info = list(map(lambda x: x.strip().split(' '), imgs_info))
return imgs_info
def padding_black(self, img):
w, h = img.size
scale = 32. / max(w, h)
img_fg = img.resize([int(x) for x in [w * scale, h * scale]])
size_fg = img_fg.size
size_bg = 32
img_bg = Image.new("RGB", (size_bg, size_bg))
img_bg.paste(img_fg, ((size_bg - size_fg[0]) // 2,
(size_bg - size_fg[1]) // 2))
img = img_bg
return img
def __getitem__(self, index):
img_path, label = self.imgs_info[index]
img_path = os.path.join('',img_path)
img = Image.open(img_path)
img = img.convert("RGB")
img = self.padding_black(img)
if self.train_flag:
img = self.train_tf(img)
else:
img = self.val_tf(img)
label = int(label)
return img, label
def __len__(self):
return len(self.imgs_info)
- 加载训练集和测试集
train_data = LoadData("/home/aistudio/work/train.txt", True)
test_data = LoadData("/home/aistudio/work/test.txt", True)
#数据读取
train_loader = paddle.io.DataLoader(train_data, batch_size=32, shuffle=True)
test_loader = paddle.io.DataLoader(test_data, batch_size=32, shuffle=True)
3.导入模型
class Fire(nn.Layer):
def __init__(self, inplanes, squeeze_planes,
expand1x1_planes, expand3x3_planes):
super(Fire, self).__init__()
self.inplanes = inplanes
self.squeeze = nn.Conv2D(inplanes, squeeze_planes, kernel_size=1)
self.squeeze_activation = nn.ReLU()
self.expand1x1 = nn.Conv2D(squeeze_planes, expand1x1_planes,
kernel_size=1)
self.expand1x1_activation = nn.ReLU()
self.expand3x3 = nn.Conv2D(squeeze_planes, expand3x3_planes,
kernel_size=3, padding=1)
self.expand3x3_activation = nn.ReLU()
def forward(self, x):
x = self.squeeze_activation(self.squeeze(x))
return paddle.concat([
self.expand1x1_activation(self.expand1x1(x)),
self.expand3x3_activation(self.expand3x3(x))
], 1)
class SqueezeNet(nn.Layer):
def __init__(self, version='1_0', num_classes=1000):
super(SqueezeNet, self).__init__()
self.num_classes = num_classes
if version == '1_0':
self.features = nn.Sequential(
nn.Conv2D(3, 96, kernel_size=7, stride=2),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3, stride=2, ceil_mode=True),
Fire(96, 16, 64, 64),
Fire(128, 16, 64, 64),
Fire(128, 32, 128, 128),
nn.MaxPool2D(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 32, 128, 128),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
nn.MaxPool2D(kernel_size=3, stride=2, ceil_mode=True),
Fire(512, 64, 256, 256),
)
elif version == '1_1':
self.features = nn.Sequential(
nn.Conv2D(3, 64, kernel_size=3, stride=2),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3, stride=2, ceil_mode=True),
Fire(64, 16, 64, 64),
Fire(128, 16, 64, 64),
nn.MaxPool2D(kernel_size=3, stride=2, ceil_mode=True),
Fire(128, 32, 128, 128),
Fire(256, 32, 128, 128),
nn.MaxPool2D(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
Fire(512, 64, 256, 256),
)
else:
# FIXME: Is this needed? SqueezeNet should only be called from the
# FIXME: squeezenet1_x() functions
# FIXME: This checking is not done for the other models
raise ValueError("Unsupported SqueezeNet version {version}:"
"1_0 or 1_1 expected".format(version=version))
# Final convolution is initialized differently from the rest
final_conv = nn.Conv2D(512, self.num_classes, kernel_size=1)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
final_conv,
nn.ReLU(),
nn.AdaptiveAvgPool2D((1, 1))
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return paddle.flatten(x, 1)
4.打印输出模型的参数信息
import paddle
model = SqueezeNet("1_0", num_classes=4)
params_info = paddle.summary(model,(1, 3, 224, 224))
print(params_info)
``

## 5.模型训练
```python
epoch_num = 60 #训练轮数
learning_rate = 0.0001 #学习率
val_acc_history = []
val_loss_history = []
def train(model):
print('start training ... ')
# turn into training mode
model.train()
opt = paddle.optimizer.Adam(learning_rate=learning_rate,
parameters=model.parameters())
for epoch in range(epoch_num):
acc_train = []
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = paddle.to_tensor(data[1],dtype="int64")
y_data = paddle.unsqueeze(y_data, 1)
logits = model(x_data)
loss = F.cross_entropy(logits, y_data)
acc = paddle.metric.accuracy(logits, y_data)
acc_train.append(acc.numpy())
if batch_id % 100 == 0:
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, loss.numpy()))
avg_acc = np.mean(acc_train)
print("[train] accuracy: {}".format(avg_acc))
loss.backward()
opt.step()
opt.clear_grad()
# evaluate model after one epoch
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(test_loader()):
x_data = data[0]
y_data = paddle.to_tensor(data[1],dtype="int64")
y_data = paddle.unsqueeze(y_data, 1)
logits = model(x_data)
loss = F.cross_entropy(logits, y_data)
acc = paddle.metric.accuracy(logits, y_data)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
avg_acc, avg_loss = np.mean(accuracies), np.mean(losses)
print("[test] accuracy/loss: {}/{}".format(avg_acc, avg_loss))
val_acc_history.append(avg_acc)
val_loss_history.append(avg_loss)
model.train()
train(model)
paddle.save(model.state_dict(), "model.pdparams")
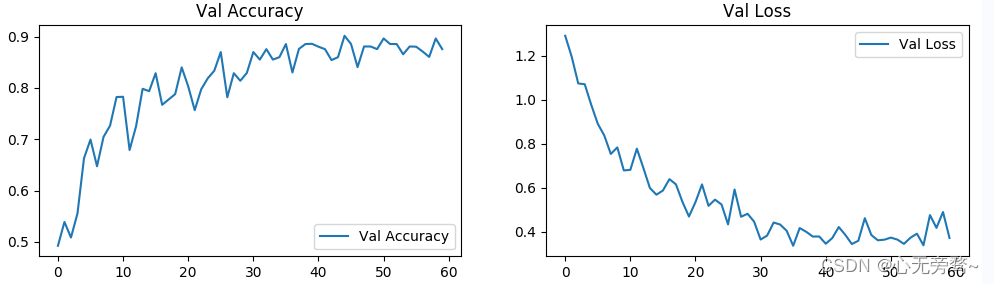
6.结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
epochs_range = range(epoch_num)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, val_acc_history, label='Val Accuracy')
plt.legend(loc='lower right')
plt.title('Val Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, val_loss_history, label='Val Loss')
plt.legend(loc='upper right')
plt.title('Val Loss')
plt.show()
7.个体预测结果展示
data_transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Resize((32, 32)),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
img = Image.open("/home/aistudio/work/dataset/Bananaquit/008.jpg")
plt.imshow(img)
image=data_transform(img)
plt.rcParams['font.sans-serif']=['FZHuaLi-M14S']
name=['风头鹦鹉','黑燕鸥类','黑喉树莺','蕉林莺']
image=paddle.reshape(image,[1,3,32,32])
model.eval()
predict=model(image)
print(predict.numpy())
plt.title(name[predict.argmax(1)])
plt.show()
总结
SqueezeNet是一种轻量级卷积神经网络,其设计目标是在保持高准确率的同时,尽量减小模型的大小和计算资源消耗。下面是关于SqueezeNet的总结:
-
轻量级设计:SqueezeNet采用了一种特殊的结构,即“Fire模块”,通过使用较少的参数来提取丰富的特征。这使得SqueezeNet相对于其他深层网络而言具有更小的模型大小。
-
参数压缩:SqueezeNet通过使用1x1卷积核来减小参数数量,同时使用通道压缩来减小计算量。这样的设计使得SqueezeNet在计算资源受限的环境中表现出色。
-
高准确率:尽管SqueezeNet是一种轻量级网络,但它在保持模型小型化的同时,仍能提供相对较高的准确率。通过合理的设计,SqueezeNet能够有效地提取和利用图像的特征信息。
-
适用场景:由于其小型化的特点,SqueezeNet特别适合在资源有限的环境下使用,如移动设备和嵌入式系统。它可以实现图像分类、目标检测和图像分割等计算密集型任务。
总的来说,SqueezeNet是一种在保持高准确率的同时尽量减小模型大小和计算资源消耗的轻量级网络。它的设计和参数压缩策略使其成为在资源受限环境下进行图像处理任务的有力选择。