以太坊采用基于账户的模式,系统中显式记录每个账户的余额。本篇文章将学习以太坊这样一个大型分布式系统中,是采用的什么样的数据结构来实现对这些数据的管理的。
如何完成账户地址到账户状态的映射?
哈希表可以做到吗?
直观地来看,由账户地址找到账户状态其本质上为Key-value键值对,所以直观想法便用哈希表实现。若不考虑哈希碰撞,查询直接为常数级别的查询效率,但采用哈希表,难以提供Merkle proof。
能否像BTC中,将哈希表的内容组织为Merkle Tree?
这样做不好。因为在BTC中,是根据交易来组织Merkle Tree的,之前学习过,每个区块通常打包的交易量在4000以下。而以太坊如果讲哈希表的内容组织称树,那么每一次打包区块的时候都要遍历一边所有账户的状态,Merkle Tree来组织账户信息,很明显其会越来越庞大。实际中,发生变化的仅仅为很少一部分数据,我们每次重新构建Merkle Tree代价很大。
既然哈希表不太行,那能否直接用一颗Merkle Tree把所有的账户放进去?
实际中,Merkle Tree并未提供一个高效的查找和更新的方案。此外,将所有账户构建为一个大的Merkle Tree,为了保证所有节点的一致性和查找速度,必须进行排序。但是新增账户,由于其地址随机,插入Merkle Tree时候很大可能在Tree中间,发现其必须进行重构。所以Sorted Merkle Tree插入、删除(实际上可以不删除)的代价太大。
Trie树
Tire树本质上一个多叉树,如下为一个通过5个单词组成的trie数据结构(只画出key,未画出value)
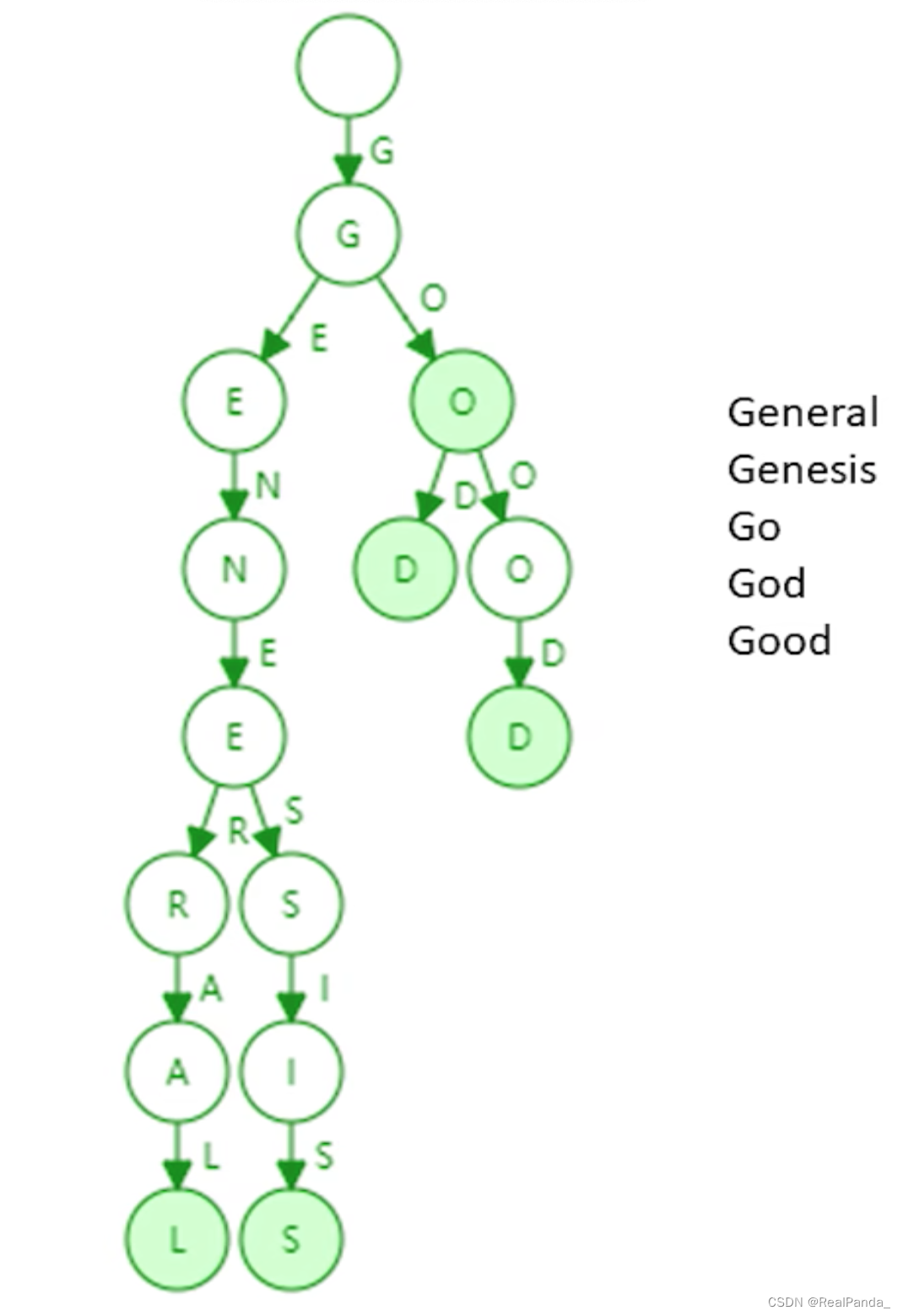
Trie树的优点
1.trie中每个节点的分支数目取决于Key值中每个元素的取值范围(图例中最多26个英文字母分叉+一个结束标志位)。
2.trie查找效率取决于key的长度。实际应用中(以太坊地址长度为160byte)。
3.理论上哈希会出现碰撞,而trie上面不会发生碰撞。
4.给定输入,无论如何顺序插入,构造的trie都是一样的。
5.更新操作局部性较好
Trie树的缺点
trie的存储浪费。很多节点只存储一个key,但其“儿子”只有一个,过于浪费。
因此,为了解决这一问题,我们引入Patricia tree/trie。
Patricia tree/trie
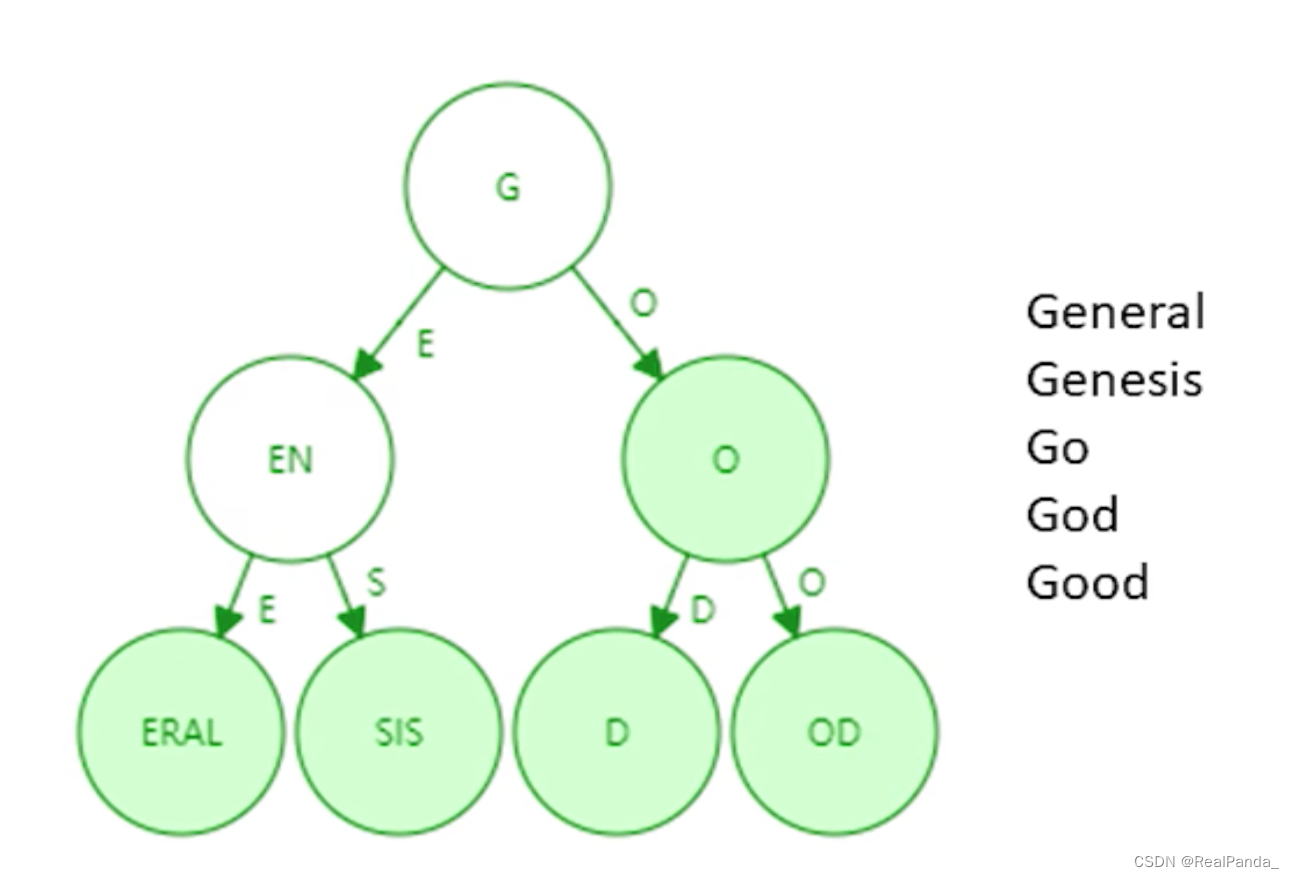
如上图所示,这就是一颗路径压缩的Trie树。直观上深度变浅了,路径访问所占内存空间会明显减少。但如果你新加入一个单词,那么已经压缩的节点会有可能扩展开。
MPT(Merkle Patricia tree)
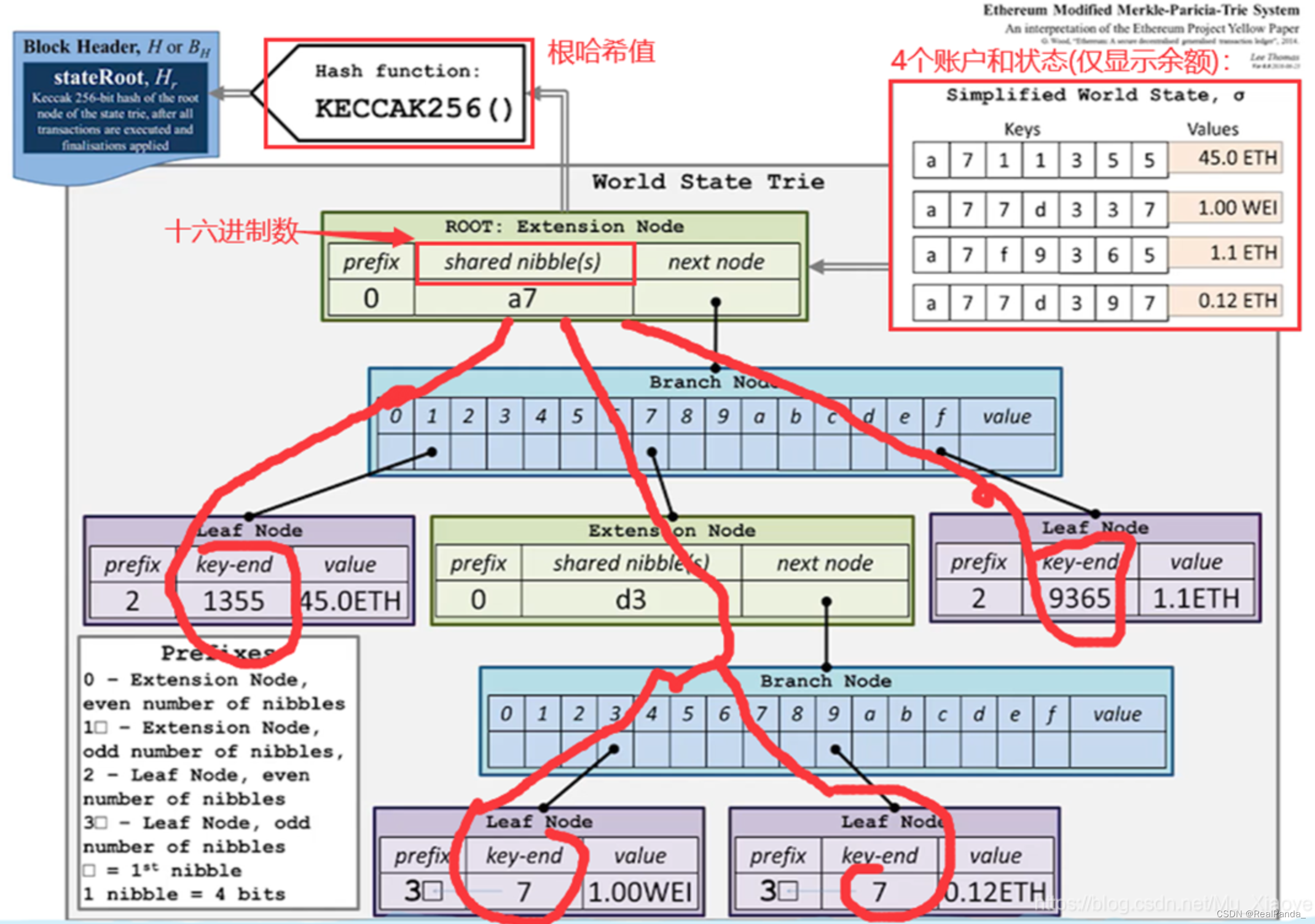
把所有的账户组织成一个 Trie 结构的Patricia tree,用路径压缩提高效率,然后把不同指针换成哈希指针,这样就可以得到一个根哈希值,这个根哈希值也是写在block header里(这里注意一点,比特币的block header里只有一个由Merkle tree组成的根哈希值,而以太坊中有3个根哈希值,本篇文章里讲的是用户状态组成的树的根哈希值)。
MPT(Modified Patricia tree)
以太坊中针对MPT(Merkle Patricia tree)进行了修改,我们称其为MPT(Modified Patricia tree),其实也只是略有修改,没什么本质的改造。
下图各节点之间的连线实际上是下一个节点的哈希值被存在了上层的对应位置。
每次发布新区块,状态树中部分节点状态会改变。但改变并非在原地修改,而是新建一些分支,保留原本状态。如下图中,仅仅有新发生改变的节点才需要修改,但凡没有修改的节点直接指向前一个区块中的对应节点。
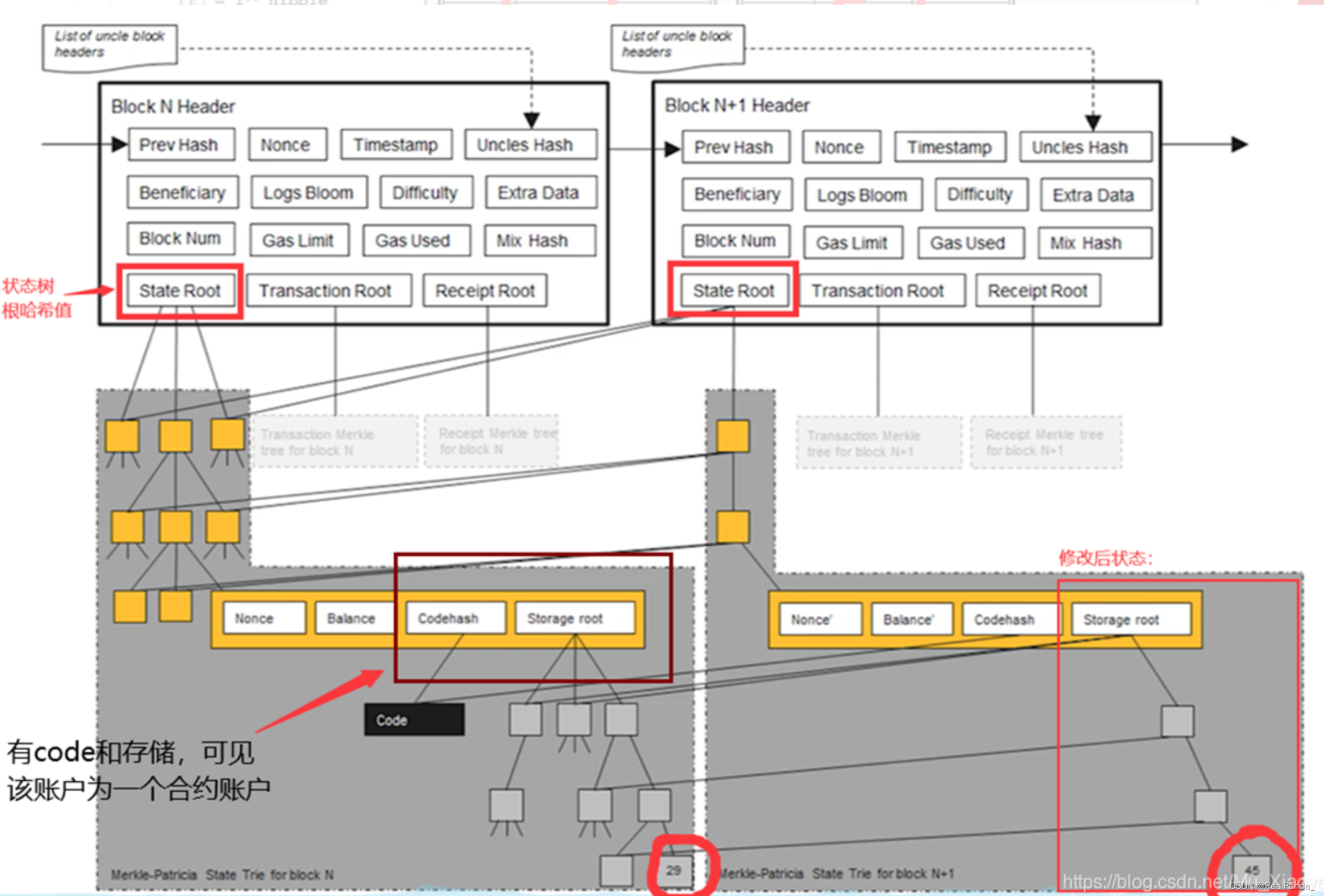
为什么以太坊中要如上图所示保存原本的状态?为何不直接修改?
在智能合约的应用中,如果遭遇了回滚,很难推算出智能合约前的账户状态。
以太坊中的数据结构代码
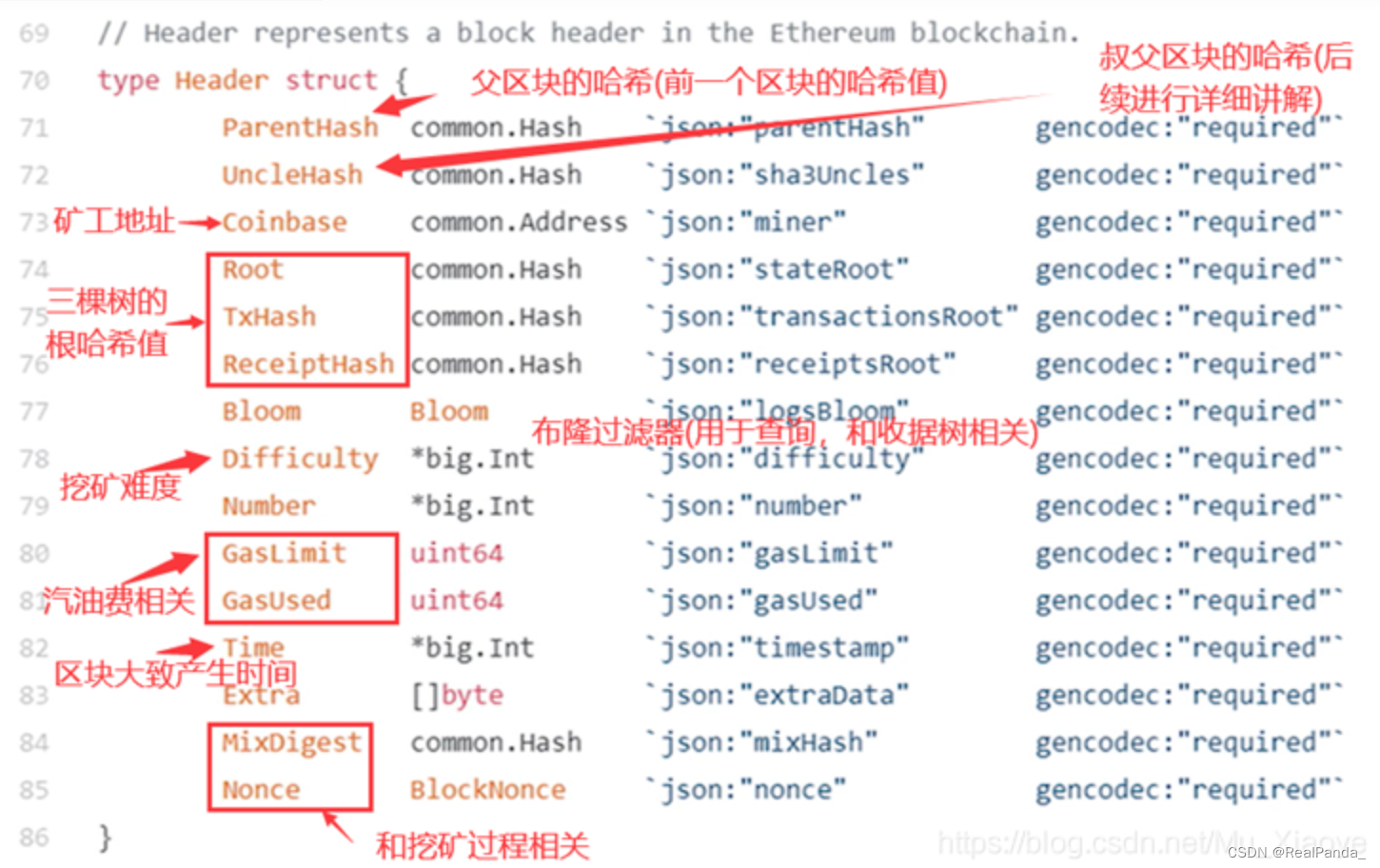
block header 中的数据结构:
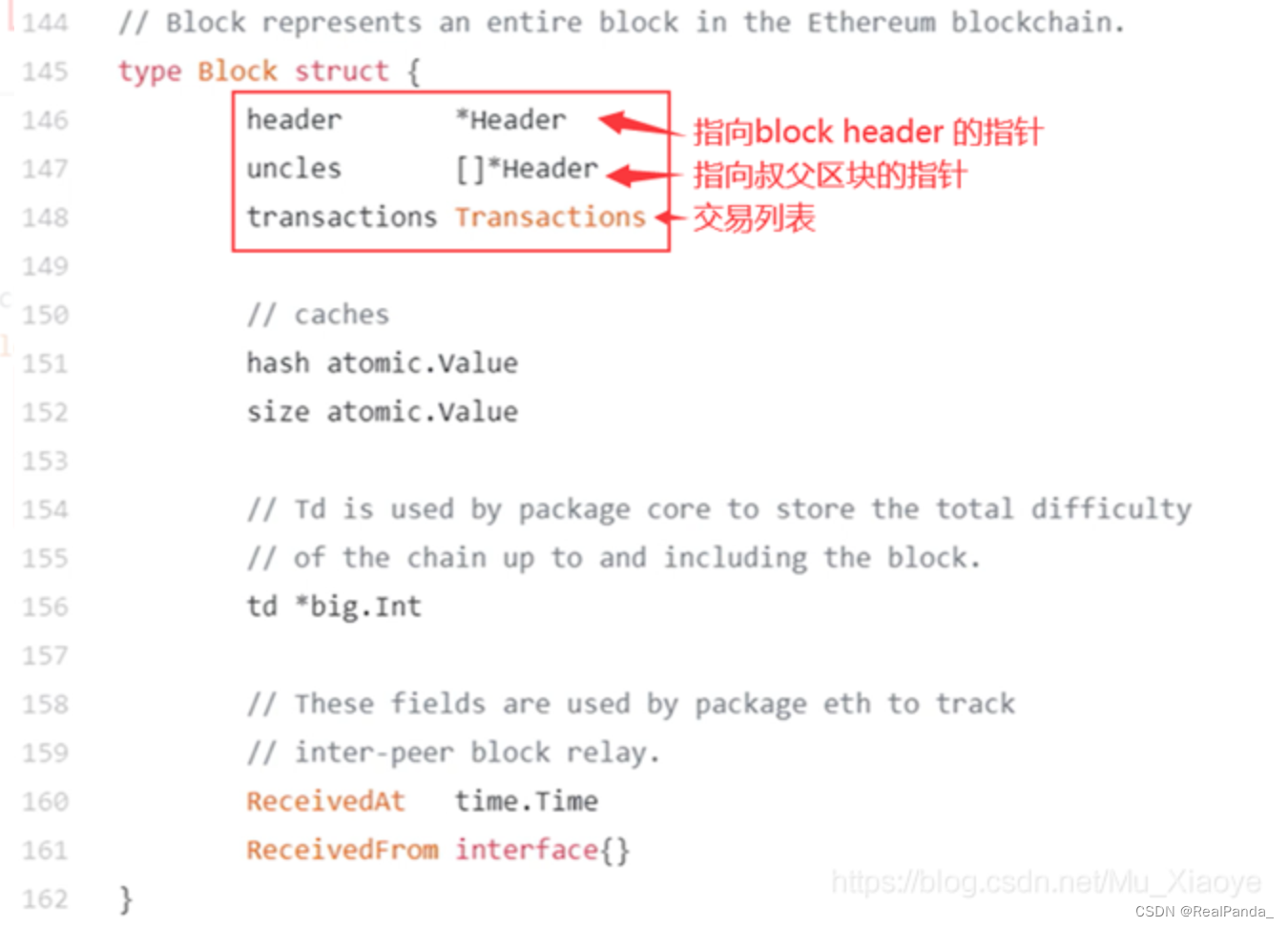
区块结构:
区块在网上真正发布时的信息:

状态树中保存Key-value对,key就是地址,而value状态通过RLP(Recursive Length Prefix,一种进行序列化的方法)编码序列号之后再进行存储。