——————>> 二刷分界线。
以太坊中的数据结构
以太坊中的账户地址是160位(20个字节),一般表示成四十个十六进制的数。
简单的hash表来实现怎么样?
查询、更新都是在常数时间内完成的,另外这种结构无法很好的提供hash proof,比如要签署一个合约:需要提供一下账户余额,这将怎么提供呢:
-
一种方法是将哈希表中的元素组织成一棵Merkle tree,算出一个根哈希值保存在block header中,公布出去。
-
存在的问题:假如要产生新的区块,新的区块的到来必将引起哈希表中的内容发生变化,这样我们就需要重新计算一遍所有账户的内容生成一棵新的Merkle tree,这样的代价太大了(账户数量太多)。而实际上发生变化的账户只是一小部分,大部分用户的状态是不会发生改变的,所以每次都要重新构建一棵Merkle tree代价是很大的。
-
比特币系统中也是每出现一个区块就要构建一棵Merkle tree,但是为什么就没有这个问题?:比特币的Merkle tree是将交易组装成一棵Merkle tree,比特币的Merkle tree在每次重新构建完之后是不会更改的,区块里有多少交易呢:1m 每个交易250字节 所以最多4000个 实际上很多交易是几百个,所以我们每次发布一个区块都是要把几百个到几千个区块构建成一个新的Merkle tree。而我们如果在以太坊中使用这种方式,每次是将所有账户遍历一遍构建一个Merkle tree,Merkle tree的作用除了提供hash proof之外,还有一个重要的作用就是维护全节点之间状态的一致性:这也是比特币中为什么把根哈希值写在块头上的原因。
-
我有一个问题,为什么以太坊使用这种方式就需要遍历所有的账户生成Merkle tree呀,就不能像比特币一样只遍历有关的账户生成Merkle tree吗
-
上述方法不好的在于没有提供一个很好地查找和更新的方法,比特币中的Merkle tree是怎么构建的:最底下的一层是transaction,哈希值两两结合一直到根节点,而这个方法对于以太坊没有提供一个快速查找和更新的方法。除此之外,我们直接将账户放在一个Merkle tree里面,这个Merkle tree要不要排序?:1、要是不排序的话每个全节点不能统一维护一个统一的Merkle tree 2、比特币中不排序,为什么比特币中不存在这个问题:比特币中每个全节点中构建的Merkle tree也是不一样的,但是比特币中有这样一个区别:在比特币系统中是获得了记账权的节点说了算的,所以比特币系统中不会出现问题,但是在以太坊中要发布的是账户的状态(数量级很大,所以使用这种方法发布区块是不可行的)
-
上述说明了不排序的Merkle tree是不行的(树的形状不唯一),那使用sorted Merkle tree会有什么问题呢:新增一个账户怎么办(又变成了重新生成了一个Merkle tree)
-
使用trie(retrieval):好像是字典树
-
trie的特点
-
1
-
2
-
3 因为账户地址不一样,所以不会发生碰撞
-
4 在merkle tree中插入的方式不一样,得到的结构也不一样,在trie中就不会出现这样的问题。
-
5 每次发布一次区块,只有发生变化的账户需要改变,更新的局部性很重要,在trie中要更新一个账户,就访问相应的分支就可以,所以更新的局部性是很好的。
-
6 trie的缺点
-
存储有点浪费,对于一脉单传的节点,所以又引入了patricia tree(trie):压缩前缀树(如下图),这样,树的高度就变短,
-

-
MPT(Merkle Patricia tree) 这里就好像区块链中的一样,将普通指针换成了hash指针
这个结构能不能证明某个键值是不存在的:将分支作为Merkle proof发过去,就可以证明他是不存在的???不懂什么含义
-
以太坊中用的还不是原生的MPT,用的是Modified MPT对MPT结构进行修改如下:
-
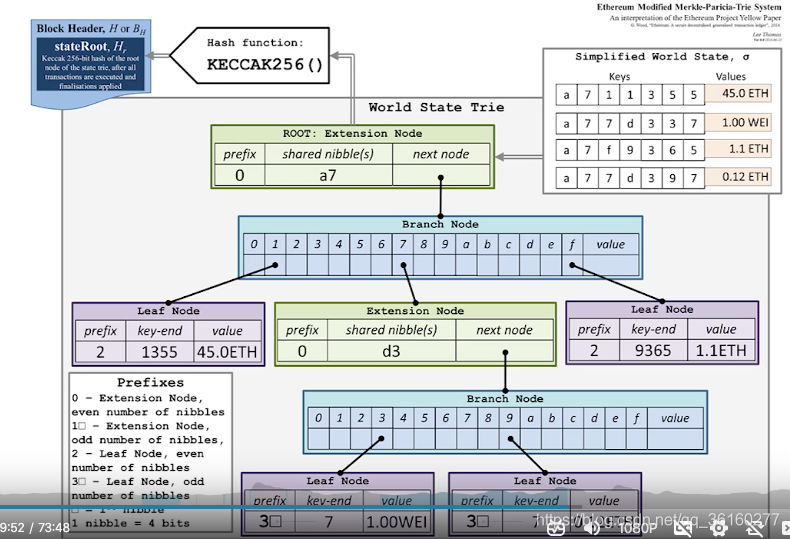
-
这里有四个账户(为了演示方便,账户状态只显示了余额,账户的地址也是比较短)
-
节点分类
-
extension node 用于路径压缩
-
branch node 分支节点
-
leaf node叶子节点
-
-
-
-
-
-
每次发布一个新的区块的过程中,这个状态树中有一些节点的值会发生变化,这些改变不是在原地改变的,而是新建一些分支,原来的状态其实是保留下来的,如下面的例子中是两个相邻的区块:
-
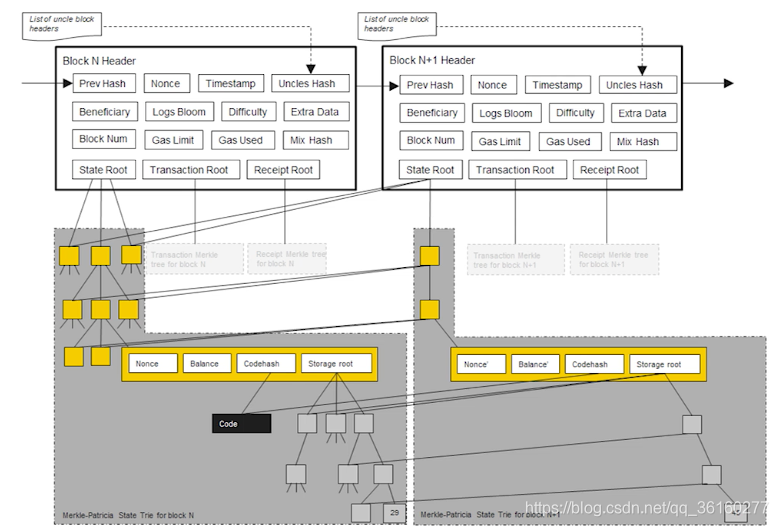 state root是状态树的根hash值,下面显示的是这课状态树,右边的state root是新发布的区块的状态树,我们可以看到,虽然这两棵树的有一些节点是不一样的,但是大部分节点是共享的,右边这棵树大部分节点指向的是左边的节点,只保存了发生改变节点的分支
state root是状态树的根hash值,下面显示的是这课状态树,右边的state root是新发布的区块的状态树,我们可以看到,虽然这两棵树的有一些节点是不一样的,但是大部分节点是共享的,右边这棵树大部分节点指向的是左边的节点,只保存了发生改变节点的分支-
可以看到上述图片中发生变化的账户是一个合约账户,有code代码,还有存储,合约账户的存储也是用MPT的形式保存下来的
-
这个变量的存储也是一个key value,维护着一个变量到变量存储的值,所以也是用了一棵MPT
-
在以太坊中,是大的MPT包含小的MPT,每一个合约账户的存储就是一个小的MPT
-
-
在上述图片中,改变的是存储中部分变量的值,可以看到其中一个变量的值由29变成了45
-
-
以太坊将出块时间变为十几秒,所以会造成分叉并成为常态。在以太坊中有智能合约,所以在以太坊中要是不保存之前的状态,要想像比特币一样推算出之前的状态是很难的(a转给b10个比特币,由当前的状态就知道在交易之前a与b账户之前的状态),但是在以太坊中是不行的,不可能根据智能合约推算出之前的状态,所以要想支持回滚,必须要保存之前的状态,下面是以太坊中块头的一些定义:

-
parenthash:前一个区块块头的hash值
-
unclehash:叔叔区块的hash值,注意:有可能叔父区块不是和父亲区块在同一个级别上,有可能叔父区块要比父亲区块大好几个级别
-
coinbase:挖出这个区块的矿工的地址
-
三棵树的根hash值
-
root 状态树的根hash值
-
txhash 交易树的根hash值:类似于比特币系统中的根hash值
-
receipthash 收据树的根hash值:
-
-
difficulty:挖矿的难度
-
number:
-
智能合约要消耗汽油费,类似与智能合约的交易税:
-
gaslimit:
-
gasused:
-
-
time:大致的产生时间
-
mixdigest:在挖矿中产生作用
-
nonce:类似与比特币中的随机数,以太坊中的挖矿也是要寻找随机数,写在块头中的nonce是最后找到的符合难度要求的
-
以下是块的结构:

-
header是指向块头的指针
-
uncles是指向叔父区块的块头的指针,一个区块可以有多个叔父的区块
-
以太坊系统中在网上真正发布的信息是前三项:

在状态树中保存的是key valve对,账户的状态是怎么存储在状态树当中的?:实际上的保存要经过一个序列化的过程,利用RLP进行一个序列化处理,(RLP:一个序列化的方法,特点就是简单,极简主义)
Protocol buffer:一个很常用的做序列化的库
在以太坊中的所有结构最后都要序列化为nested array of bytes,所以要实现一个RLP要比Protocol buffer容易很多,因为难的东西他都不做,都推给应用层做了。
