我看是废话少说,直接上干货吧,毕竟大家时间都宝贵!

原理
MySQL索引下推的原理可以简单地概括为:在执行查询语句时,MySQL优化器将WHERE条件中可下推到存储引擎层的部分下推到存储引擎进行过滤,只将满足条件的数据返回给MySQL服务器,从而减少MySQL服务器的工作量,提高查询效率。通常情况下,只有使用索引的查询才能利用索引下推功能。
在MySQL中,存储引擎层负责实际的数据存储和检索工作,而MySQL服务器则负责处理SQL语句、解析查询语句、优化查询计划等任务。当MySQL服务器收到一条SELECT语句时,它会先解析查询语句,确定查询条件和需要查询的数据表,然后生成一个查询计划,最后将查询计划发送给存储引擎层进行实际的数据检索。
在生成查询计划的过程中,MySQL优化器会根据查询条件和数据表的结构选择最优的索引来进行查询。如果查询条件中包含可下推的条件,MySQL优化器会将这些条件下推到存储引擎层进行过滤,只将满足条件的数据返回给MySQL服务器。
例如,假设我们有一个名为employees的数据表,其中包含员工的信息,如姓名、工号、入职日期等。如果我们要查询入职日期在2022年1月1日之后的员工信息,可以使用以下SQL语句:
SELECT * FROM employees WHERE hire_date > '2022-01-01';在执行这条查询语句时,MySQL优化器会选择一个合适的索引来查询hire_date列,并将查询条件hire_date > '2022-01-01'下推到存储引擎层进行过滤,只将满足条件的数据返回给MySQL服务器。
示例
没有使用ICP
在MySQL 5.6之前,存储引擎根据通过联合索引找到name likelike '张%' 的主键id(1、4),逐一进行回表扫描,去聚簇索引找到完整的行记录,server层再对数据根据age=10进行筛选。
我们看一下示意图:
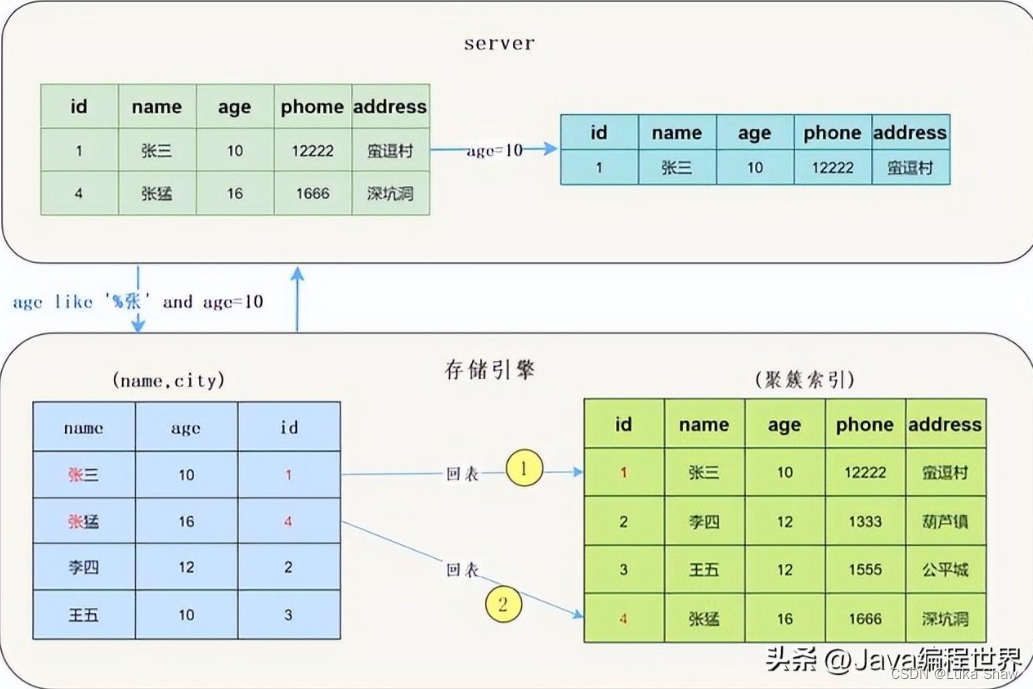
可以看到需要回表两次,把我们联合索引的另一个字段age浪费了。
使用ICP
而MySQL 5.6 以后, 存储引擎根据(name,age)联合索引,找到,由于联合索引中包含列,所以存储引擎直接再联合索引里按照age=10过滤。按照过滤后的数据再一一进行回表扫描。
我们看一下示意图:
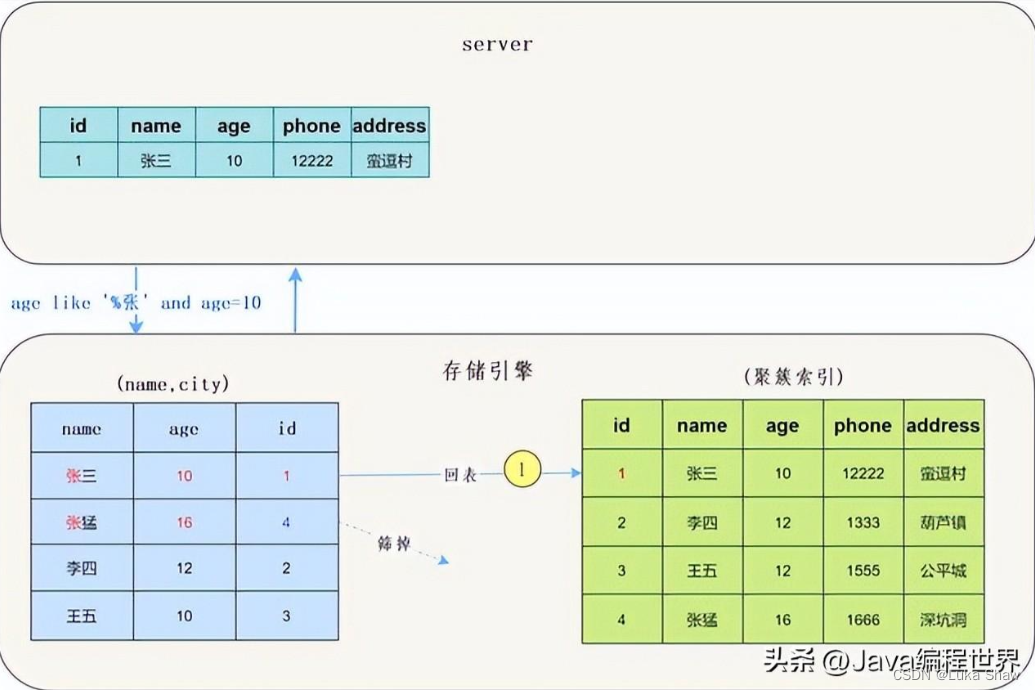
可以看到只回表了一次。
为了更好地理解MySQL索引下推的原理,我们可以通过一个简单的示例来演示它的使用。
假设我们有一个名为orders的数据表,其中包含订单的信息,如订单编号、订单日期、订单金额等。该表中有一个索引idx_order_date_amount,包含order_date和order_amount两列。我们要查询订单日期在2022年1月1日之后,且订单金额大于100元的订单信息,可以使用以下SQL语句:
SELECT * FROM orders WHERE order_date > '2022-01-01' AND order_amount > 100;在执行这条查询语句时,MySQL优化器会选择`idx_order_date_amount`索引来查询`order_date`和`order_amount`列,并将查询条件`order_date > '2022-01-01'`下推到存储引擎层进行过滤。存储引擎层会先使用`order_date`列进行过滤,只返回订单日期在2022年1月1日之后的数据,然后再使用`order_amount`列进行过滤,只返回订单金额大于100元的数据。最终,只有满足条件的数据才会返回给MySQL服务器,提高查询效率。 为了验证MySQL索引下推的效果,我们可以使用EXPLAIN语句来查看查询计划。在MySQL命令行中输入以下语句:
EXPLAIN SELECT * FROM orders WHERE order_date > '2022-01-01' AND order_amount > 100; 执行后,可以得到如下查询计划:
+----+-------------+-------+------------+------+--------------------------+--------------------------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+--------------------------+--------------------------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | orders| NULL | ref | idx_order_date_amount | idx_order_date_amount | 7 | NULL | 1000 | 10.00 | Using where; Using index |
+----+-------------+-------+------------+------+--------------------------+--------------------------+---------+------+------+----------+-----------------------------+其中,possible_keys列显示了可能使用的索引,key列显示了实际使用的索引,filtered列显示了过滤后的行数占比。可以看到,查询计划中使用了idx_order_date_amount索引,并且filtered列的值为10.00,表示只有10%的数据需要被过滤。这证明了MySQL索引下推的效果。
需要注意的是,MySQL索引下推并不适用于所有情况。如果查询条件中包含了不可下推的条件,MySQL优化器就无法将查询条件下推到存储引擎层进行过滤,这时就不能使用索引下推功能。另外,在某些情况下,索引下推可能会导致查询性能变差,因此需要根据具体情况进行评估和优化。