前言
前段时候我收到了算法组的一个AI模型的落地请求. 这个模型是为了能在服务器实时推理, 在原始模型的基础上进行了裁剪, 运算量从7G Macs降低到了1G Macs, 但实际反映出来的速度提升只有30%.
这里就反应出了一个问题, 那就是AI算法的开发者对于模型落地硬件不熟悉, 只在他们的认知空间内对模型进行裁剪优化. 所以会出现这种落差很大的优化结果. 于是我给算法组提交了模型修改意见, 在他们修改以后模型运算量为8G Macs, 但是推理时间比1G Macs更要短.
如果你在训练AI模型, 而且是要部署在Nvidia的GPU上, 那么下面的内容或许会对你很有帮助.
正文
常理来讲, 模型的运算量是浮点数的乘加运算的个数, 这个如果在CPU上单核进行推理, 那基本上推理时间是随运算量一起增加的. 但是基本上较大的模型都是部署在GPU或者AI芯片上推理. 那这时候就要考虑模型并行化的问题. 但是这不是今天的主题, 今天的主题是关于NvidiaGPU上的矩阵计算核心, TensorCore.
从Volta架构开始, Nvidia在每个SM核心中除了INT运算模块和FLOAT运算模块以外, 新引入了Tensor Core模块, 如下图:

其中INT32 FP32 FP64这些就是数学运算模块, 用来进行通用计算的. 普通CUDA kernel里面的计算就是每个线程调用对应的模块来计算的. 而右边的Tensor Core则是用来进行矩阵计算的模块. 就Nvidia Ampere A100的手册数据来看TensorCore的算力是通用算力的4倍.
TensorCore
我之前在公司内部有做过相关的技术分享:
其中我主要就Nvidia的服务器GPU A100和Huawei Ascend910的架构进行了分析. 他们的核心模块都很接近, 那就是矩阵运算模块, NV叫TensorCore, 华为叫Cube.
它们的概念图大概是这样:

其中浅蓝色和紫色的就是两个4x4的矩阵, 灰色的则是计算核心, 每个核心完成两个矩阵对应位置的元素乘法, 乘法的结果最终累加到下面的绿色4x4的矩阵上.
AI里面什么层会用到这个专用于矩阵计算的TensorCore呢? 是Dense Layer, FC吗?
错了, 其实是卷积.
Dense Layer和FC也是矩阵计算, 但大多数情况下都是1 x ChannelIn x ChannelOut的矩阵计算, 所以对这个cube来讲实际只用到了A矩阵的一行数据, 并没有体现出TensorCore的算力优势.
卷积有两种方式可以转换成矩阵计算, 一种是Winograd, 一种是Gemm. 据我所知, Gemm在TensorCore的结构上的优势更大.
但是, 不同的卷积参数对于TensorCore来说利用率是很有大差异的.
卷积参数
首先, CUDA在调用TensorCore的时候对矩阵的形状是有一定要求的, 比如32x8x16的矩阵形状, 这是导致性能问题最大的因素. CUDA底层问题就不展开说明了.
这里先记住这几个诀窍:1. 输入输出的Tensor通道数最好是16的倍数, 最低不能低于8; 2.尽量避免使用depthwise卷积, 据我了解它是无法有效转换成矩阵计算, 即没法调用TensorCore来进行加速的; 3. 使用"两步卷积".
通道数是16的倍数主要是来源于CUDA调用TensorCore接口对于矩阵的形状要求.
两步卷积是我临时自创的一个词, 这个的意思是: 如果你想要用卷积把一个n通道的tensor变为m通道, 其中n小于8, 比如在输入的时候大部分不是1就是3. m很大, 比如32, 64 , 128 这种常见的初始通道数. 同样, m很小, n很大也是一样. 这时候直接用 mxnx3x3(比如3x3卷积)的卷积核运算是效率很低的, 这时候可以拆分为两个卷积完成, 取一个中间的通道数 k(8或者16), 先从n卷积到k,再从k卷积到m.
模型推理测试
先从模型结构图片来看看,两步卷积是在做什么:

上图的模型就是输入是1通道的tensor, 经过第一层卷积后变成64通道. 这就很复合我上面写的n,m的大小范围, 一个很小, 一个很大.
按照两部卷积的方法, 模型被修改成这样:
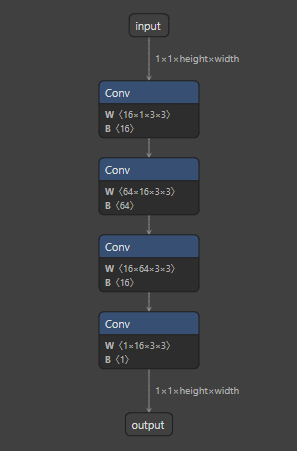
即模型先卷积到16通道, 然后再卷积成为64通道.
看看两个模型的运算量和参数量的对比:
直接卷积法: 1G Macs, 1217 params
两步卷积: 17G Macs, 18817 params
很明显, 不管从参数个数还是运算量来看, 两步卷积都比直接卷积要多了10倍以上, 但是实际的推理时间会相差这么多吗?
我使用了TensorRT7.2.2.3对这两个模型进行了速度测试, 其中输入tensor的shape为1x1x720x1280. 运行结果是:
直接卷积 2ms
两步卷积 2.5ms
也就是速度下降了25%.
在这个速度变化下, 首先网络层数增加了, 参数量也增加了, 对AI模型来说可以说是非常划算的生意. 而反过来, 为了去降低运算量, 把网络层数减少或者改为8以下的小通道网络结构, 这样的收益就显得很不划算.
钢要用在刀刃上.
总结
由于TensorCore的出现, 为AI模型的推理带了一些新的变化, 不同于CPU计算, 也不同于GPU的通用计算. 所以想要自己的AI模型能够利用好Nvidia的TensorCore推理性能, 我为大家在设计模型结构的时候提出了以下建议:
1. 输入输出的Tensor通道数最好是16的倍数, 最低不能低于8;
2.尽量避免使用depthwise卷积, 据我了解它是无法有效转换成矩阵计算, 即没法调用TensorCore来进行加速的;
3. 使用"两步卷积".
最后说一点, 目前能够完美发挥出TensorCore性能的引擎, 据我所知只有TensorRT. 一些训练推理平台(比如pytorch)底层实际调用的是cuDNN来完成模型的推理. 但据我的经验来看, 相同参数的卷积cuDNN的实现要比TensorRT的实现慢3倍以上. 我也尝试过实现基于TensorCore的卷积, 但最终还是会比TensorRT慢20%多的样子.
所以, 如果按照我的说法去修改模型结构, 也一定要用TensorRT来部署你模型, 这样才能实现最大的模型推理性能.
后话
很久没更新文章了, 主要还是不知道写啥. 因为工作内容专业性都太强了, 还是想写一些大众都能看了受益的文章. 预计等VS2022发布后我会规划一些新的要写的东西吧.