【AI实战】快速搭建中文 33B 大模型 Chinese-Alpaca-33B
中文 33B 大模型 Chinese-Alpaca-33B
-
介绍
Chinese-Alpaca-33B 大模型在原版 LLaMA-33B 的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,中文Alpaca模型进一步使用了中文指令数据进行精调,显著提升了模型对指令的理解和执行能力。
官网:https://github.com/ymcui/Chinese-LLaMA-Alpaca
LLaMA模型禁止商用
-
训练数据
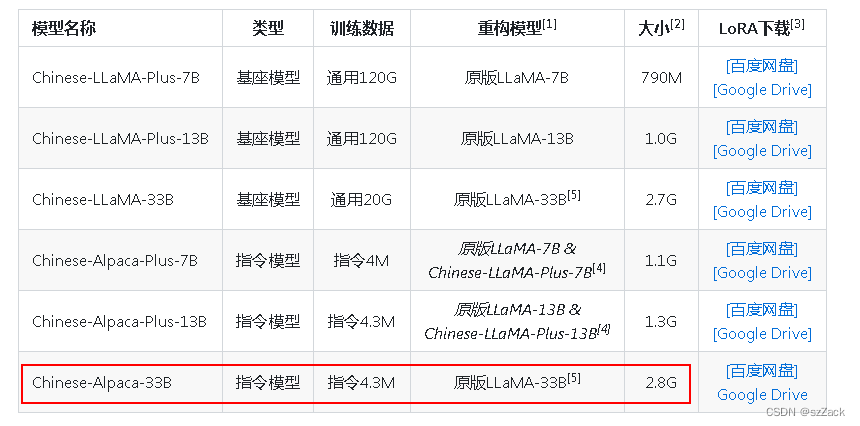
-
中文LLaMA VS 中文Alpaca
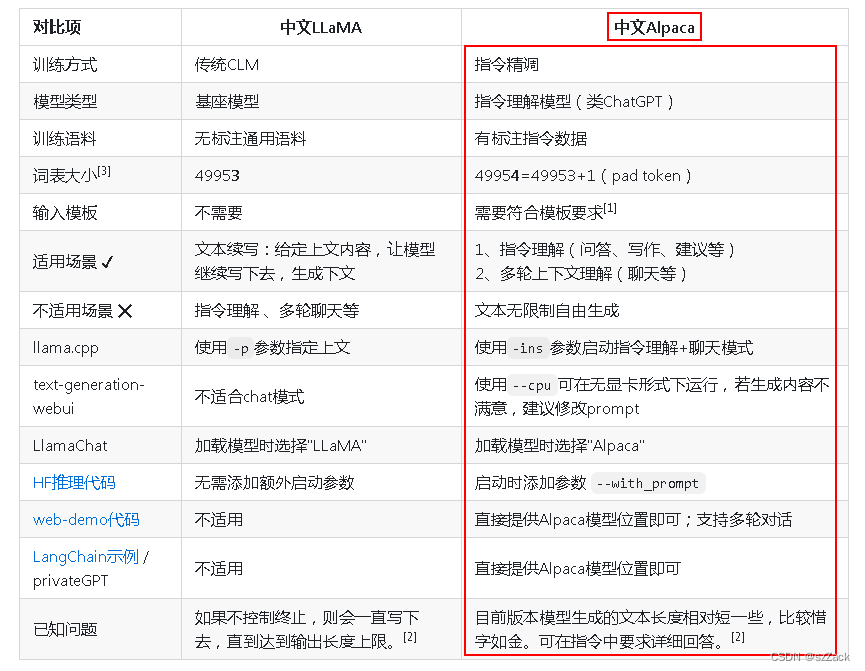
-
测试截图
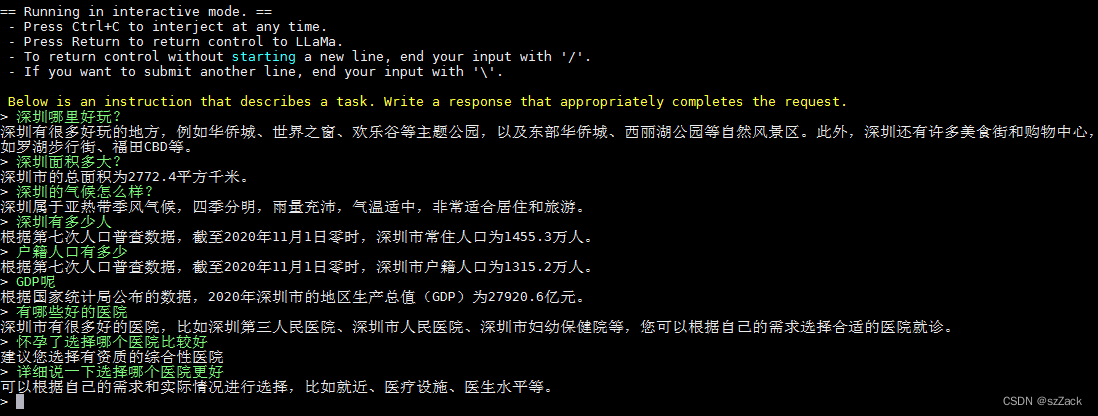
从测试结果来看,还可以吧,但是距离chatGPT有距离啊!
环境配置
环境配置过程详情参考我的这篇文章;
【AI实战】从零开始搭建中文 LLaMA-33B 语言模型 Chinese-LLaMA-Alpaca-33B
llama-33B 模型下载、合并方法也是参考这篇文章:
【AI实战】从零开始搭建中文 LLaMA-33B 语言模型 Chinese-LLaMA-Alpaca-33B
得到的模型保存路径:“./Chinese-LLaMA-33B”
llama.cpp 量化部署 llama-33B参考这篇文章:
【AI实战】llama.cpp 量化部署 llama-33B
搭建过程
首先按照上面的步骤已经获得:
./llama-30b-hf – llama-30b 原始模型
llama.cpp 已经编译好
1.拉取 chinese-alpaca-lora-33b
执行:
cd /notebooks
git clone https://huggingface.co/ziqingyang/chinese-alpaca-lora-33b
【】可能拉取失败,耐心尝试多次就会成功!!!
比如错误信息:
Cloning into 'chinese-alpaca-lora-33b'...
fatal: unable to access 'https://huggingface.co/ziqingyang/chinese-alpaca-lora-33b/': gnutls_handshake() failed: Error in the pull function.
也可能拉取到的文件太小:
# git clone https://huggingface.co/ziqingyang/chinese-alpaca-lora-33b
Cloning into 'chinese-alpaca-lora-33b'...
remote: Enumerating objects: 19, done.
remote: Total 19 (delta 0), reused 0 (delta 0), pack-reused 19
Unpacking objects: 100% (19/19), 2.58 KiB | 440.00 KiB/s, done.
# du -sh chinese-alpaca-lora-33b/
344K chinese-alpaca-lora-33b/
文件夹 chinese-alpaca-lora-33b/ 大小才 344K
执行:
rm -rf chinese-alpaca-lora-33b/
再拉取,执行:
git clone https://huggingface.co/ziqingyang/chinese-alpaca-lora-33b
正确拉取到的文件大小:
# du -sh chinese-llama-lora-33b/
2.8G chinese-llama-lora-33b/
2.合并lora权重
合并脚本:
merge_chinese-alpaca-33b.sh
cd /notebooks/Chinese-LLaMA-Alpaca
mkdir ./chinese-alpaca-33b-pth
python scripts/merge_llama_with_chinese_lora.py \
--base_model ../llama-30b-hf/ \
--lora_model ../chinese-alpaca-lora-33b/ \
--output_type pth \
--output_dir ./chinese-alpaca-33b-pth
执行合并:
sh merge_chinese-alpaca-33b.sh
输出结果到路径:./chinese-alpaca-33b-pth
输出信息:
# sh merge_chinese-alpaca-33b.sh
Base model: ../llama-30b-hf/
LoRA model(s) ['../chinese-alpaca-lora-33b/']:
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████| 61/61 [01:32<00:00, 1.51s/it]
Peft version: 0.3.0
Loading LoRA for 33B model
Loading LoRA ../chinese-alpaca-lora-33b/...
base_model vocab size: 32000
tokenizer vocab size: 49954
Extended vocabulary size to 49954
Loading LoRA weights
Merging with merge_and_unload...
Saving to pth format...
Processing tok_embeddings.weight
Processing layers.0.attention.wq.weight
Processing layers.0.attention.wk.weight
Processing layers.0.attention.wv.weight
Processing layers.0.attention.wo.weight
Processing layers.0.feed_forward.w1.weight
Processing layers.0.feed_forward.w2.weight
Processing layers.0.feed_forward.w3.weight
Processing layers.0.attention_norm.weight
Processing layers.0.ffn_norm.weight
Processing layers.1.attention.wq.weight
Processing layers.1.attention.wk.weight
Processing layers.1.attention.wv.weight
Processing layers.1.attention.wo.weight
Processing layers.1.feed_forward.w1.weight
Processing layers.1.feed_forward.w2.weight
Processing layers.1.feed_forward.w3.weight
Processing layers.1.attention_norm.weight
Processing layers.1.ffn_norm.weight
Processing layers.2.attention.wq.weight
Processing layers.2.attention.wk.weight
Processing layers.2.attention.wv.weight
Processing layers.2.attention.wo.weight
Processing layers.2.feed_forward.w1.weight
Processing layers.2.feed_forward.w2.weight
Processing layers.2.feed_forward.w3.weight
Processing layers.2.attention_norm.weight
Processing layers.2.ffn_norm.weight
Processing layers.3.attention.wq.weight
Processing layers.3.attention.wk.weight
Processing layers.3.attention.wv.weight
Processing layers.3.attention.wo.weight
Processing layers.3.feed_forward.w1.weight
Processing layers.3.feed_forward.w2.weight
Processing layers.3.feed_forward.w3.weight
Processing layers.3.attention_norm.weight
Processing layers.3.ffn_norm.weight
Processing layers.4.attention.wq.weight
Processing layers.4.attention.wk.weight
Processing layers.4.attention.wv.weight
Processing layers.4.attention.wo.weight
Processing layers.4.feed_forward.w1.weight
Processing layers.4.feed_forward.w2.weight
Processing layers.4.feed_forward.w3.weight
Processing layers.4.attention_norm.weight
Processing layers.4.ffn_norm.weight
Processing layers.5.attention.wq.weight
Processing layers.5.attention.wk.weight
Processing layers.5.attention.wv.weight
Processing layers.5.attention.wo.weight
Processing layers.5.feed_forward.w1.weight
Processing layers.5.feed_forward.w2.weight
Processing layers.5.feed_forward.w3.weight
Processing layers.5.attention_norm.weight
Processing layers.5.ffn_norm.weight
Processing layers.6.attention.wq.weight
Processing layers.6.attention.wk.weight
Processing layers.6.attention.wv.weight
Processing layers.6.attention.wo.weight
Processing layers.6.feed_forward.w1.weight
Processing layers.6.feed_forward.w2.weight
Processing layers.6.feed_forward.w3.weight
Processing layers.6.attention_norm.weight
Processing layers.6.ffn_norm.weight
Processing layers.7.attention.wq.weight
Processing layers.7.attention.wk.weight
Processing layers.7.attention.wv.weight
Processing layers.7.attention.wo.weight
Processing layers.7.feed_forward.w1.weight
Processing layers.7.feed_forward.w2.weight
Processing layers.7.feed_forward.w3.weight
Processing layers.7.attention_norm.weight
Processing layers.7.ffn_norm.weight
Processing layers.8.attention.wq.weight
Processing layers.8.attention.wk.weight
Processing layers.8.attention.wv.weight
Processing layers.8.attention.wo.weight
Processing layers.8.feed_forward.w1.weight
Processing layers.8.feed_forward.w2.weight
Processing layers.8.feed_forward.w3.weight
Processing layers.8.attention_norm.weight
Processing layers.8.ffn_norm.weight
Processing layers.9.attention.wq.weight
Processing layers.9.attention.wk.weight
Processing layers.9.attention.wv.weight
Processing layers.9.attention.wo.weight
Processing layers.9.feed_forward.w1.weight
Processing layers.9.feed_forward.w2.weight
Processing layers.9.feed_forward.w3.weight
Processing layers.9.attention_norm.weight
Processing layers.9.ffn_norm.weight
Processing layers.10.attention.wq.weight
Processing layers.10.attention.wk.weight
Processing layers.10.attention.wv.weight
Processing layers.10.attention.wo.weight
Processing layers.10.feed_forward.w1.weight
Processing layers.10.feed_forward.w2.weight
Processing layers.10.feed_forward.w3.weight
Processing layers.10.attention_norm.weight
Processing layers.10.ffn_norm.weight
Processing layers.11.attention.wq.weight
Processing layers.11.attention.wk.weight
Processing layers.11.attention.wv.weight
Processing layers.11.attention.wo.weight
Processing layers.11.feed_forward.w1.weight
Processing layers.11.feed_forward.w2.weight
Processing layers.11.feed_forward.w3.weight
Processing layers.11.attention_norm.weight
Processing layers.11.ffn_norm.weight
Processing layers.12.attention.wq.weight
Processing layers.12.attention.wk.weight
Processing layers.12.attention.wv.weight
Processing layers.12.attention.wo.weight
Processing layers.12.feed_forward.w1.weight
Processing layers.12.feed_forward.w2.weight
Processing layers.12.feed_forward.w3.weight
Processing layers.12.attention_norm.weight
Processing layers.12.ffn_norm.weight
Processing layers.13.attention.wq.weight
Processing layers.13.attention.wk.weight
Processing layers.13.attention.wv.weight
Processing layers.13.attention.wo.weight
Processing layers.13.feed_forward.w1.weight
Processing layers.13.feed_forward.w2.weight
Processing layers.13.feed_forward.w3.weight
Processing layers.13.attention_norm.weight
Processing layers.13.ffn_norm.weight
Processing layers.14.attention.wq.weight
Processing layers.14.attention.wk.weight
Processing layers.14.attention.wv.weight
Processing layers.14.attention.wo.weight
Processing layers.14.feed_forward.w1.weight
Processing layers.14.feed_forward.w2.weight
Processing layers.14.feed_forward.w3.weight
Processing layers.14.attention_norm.weight
Processing layers.14.ffn_norm.weight
Processing layers.15.attention.wq.weight
Processing layers.15.attention.wk.weight
Processing layers.15.attention.wv.weight
Processing layers.15.attention.wo.weight
Processing layers.15.feed_forward.w1.weight
Processing layers.15.feed_forward.w2.weight
Processing layers.15.feed_forward.w3.weight
Processing layers.15.attention_norm.weight
Processing layers.15.ffn_norm.weight
Processing layers.16.attention.wq.weight
Processing layers.16.attention.wk.weight
Processing layers.16.attention.wv.weight
Processing layers.16.attention.wo.weight
Processing layers.16.feed_forward.w1.weight
Processing layers.16.feed_forward.w2.weight
Processing layers.16.feed_forward.w3.weight
Processing layers.16.attention_norm.weight
Processing layers.16.ffn_norm.weight
Processing layers.17.attention.wq.weight
Processing layers.17.attention.wk.weight
Processing layers.17.attention.wv.weight
Processing layers.17.attention.wo.weight
Processing layers.17.feed_forward.w1.weight
Processing layers.17.feed_forward.w2.weight
Processing layers.17.feed_forward.w3.weight
Processing layers.17.attention_norm.weight
Processing layers.17.ffn_norm.weight
Processing layers.18.attention.wq.weight
Processing layers.18.attention.wk.weight
Processing layers.18.attention.wv.weight
Processing layers.18.attention.wo.weight
Processing layers.18.feed_forward.w1.weight
Processing layers.18.feed_forward.w2.weight
Processing layers.18.feed_forward.w3.weight
Processing layers.18.attention_norm.weight
Processing layers.18.ffn_norm.weight
Processing layers.19.attention.wq.weight
Processing layers.19.attention.wk.weight
Processing layers.19.attention.wv.weight
Processing layers.19.attention.wo.weight
Processing layers.19.feed_forward.w1.weight
Processing layers.19.feed_forward.w2.weight
Processing layers.19.feed_forward.w3.weight
Processing layers.19.attention_norm.weight
Processing layers.19.ffn_norm.weight
Processing layers.20.attention.wq.weight
Processing layers.20.attention.wk.weight
Processing layers.20.attention.wv.weight
Processing layers.20.attention.wo.weight
Processing layers.20.feed_forward.w1.weight
Processing layers.20.feed_forward.w2.weight
Processing layers.20.feed_forward.w3.weight
Processing layers.20.attention_norm.weight
Processing layers.20.ffn_norm.weight
Processing layers.21.attention.wq.weight
Processing layers.21.attention.wk.weight
Processing layers.21.attention.wv.weight
Processing layers.21.attention.wo.weight
Processing layers.21.feed_forward.w1.weight
Processing layers.21.feed_forward.w2.weight
Processing layers.21.feed_forward.w3.weight
Processing layers.21.attention_norm.weight
Processing layers.21.ffn_norm.weight
Processing layers.22.attention.wq.weight
Processing layers.22.attention.wk.weight
Processing layers.22.attention.wv.weight
Processing layers.22.attention.wo.weight
Processing layers.22.feed_forward.w1.weight
Processing layers.22.feed_forward.w2.weight
Processing layers.22.feed_forward.w3.weight
Processing layers.22.attention_norm.weight
Processing layers.22.ffn_norm.weight
Processing layers.23.attention.wq.weight
Processing layers.23.attention.wk.weight
Processing layers.23.attention.wv.weight
Processing layers.23.attention.wo.weight
Processing layers.23.feed_forward.w1.weight
Processing layers.23.feed_forward.w2.weight
Processing layers.23.feed_forward.w3.weight
Processing layers.23.attention_norm.weight
Processing layers.23.ffn_norm.weight
Processing layers.24.attention.wq.weight
Processing layers.24.attention.wk.weight
Processing layers.24.attention.wv.weight
Processing layers.24.attention.wo.weight
Processing layers.24.feed_forward.w1.weight
Processing layers.24.feed_forward.w2.weight
Processing layers.24.feed_forward.w3.weight
Processing layers.24.attention_norm.weight
Processing layers.24.ffn_norm.weight
Processing layers.25.attention.wq.weight
Processing layers.25.attention.wk.weight
Processing layers.25.attention.wv.weight
Processing layers.25.attention.wo.weight
Processing layers.25.feed_forward.w1.weight
Processing layers.25.feed_forward.w2.weight
Processing layers.25.feed_forward.w3.weight
Processing layers.25.attention_norm.weight
Processing layers.25.ffn_norm.weight
Processing layers.26.attention.wq.weight
Processing layers.26.attention.wk.weight
Processing layers.26.attention.wv.weight
Processing layers.26.attention.wo.weight
Processing layers.26.feed_forward.w1.weight
Processing layers.26.feed_forward.w2.weight
Processing layers.26.feed_forward.w3.weight
Processing layers.26.attention_norm.weight
Processing layers.26.ffn_norm.weight
Processing layers.27.attention.wq.weight
Processing layers.27.attention.wk.weight
Processing layers.27.attention.wv.weight
Processing layers.27.attention.wo.weight
Processing layers.27.feed_forward.w1.weight
Processing layers.27.feed_forward.w2.weight
Processing layers.27.feed_forward.w3.weight
Processing layers.27.attention_norm.weight
Processing layers.27.ffn_norm.weight
Processing layers.28.attention.wq.weight
Processing layers.28.attention.wk.weight
Processing layers.28.attention.wv.weight
Processing layers.28.attention.wo.weight
Processing layers.28.feed_forward.w1.weight
Processing layers.28.feed_forward.w2.weight
Processing layers.28.feed_forward.w3.weight
Processing layers.28.attention_norm.weight
Processing layers.28.ffn_norm.weight
Processing layers.29.attention.wq.weight
Processing layers.29.attention.wk.weight
Processing layers.29.attention.wv.weight
Processing layers.29.attention.wo.weight
Processing layers.29.feed_forward.w1.weight
Processing layers.29.feed_forward.w2.weight
Processing layers.29.feed_forward.w3.weight
Processing layers.29.attention_norm.weight
Processing layers.29.ffn_norm.weight
Processing layers.30.attention.wq.weight
Processing layers.30.attention.wk.weight
Processing layers.30.attention.wv.weight
Processing layers.30.attention.wo.weight
Processing layers.30.feed_forward.w1.weight
Processing layers.30.feed_forward.w2.weight
Processing layers.30.feed_forward.w3.weight
Processing layers.30.attention_norm.weight
Processing layers.30.ffn_norm.weight
Processing layers.31.attention.wq.weight
Processing layers.31.attention.wk.weight
Processing layers.31.attention.wv.weight
Processing layers.31.attention.wo.weight
Processing layers.31.feed_forward.w1.weight
Processing layers.31.feed_forward.w2.weight
Processing layers.31.feed_forward.w3.weight
Processing layers.31.attention_norm.weight
Processing layers.31.ffn_norm.weight
Processing layers.32.attention.wq.weight
Processing layers.32.attention.wk.weight
Processing layers.32.attention.wv.weight
Processing layers.32.attention.wo.weight
Processing layers.32.feed_forward.w1.weight
Processing layers.32.feed_forward.w2.weight
Processing layers.32.feed_forward.w3.weight
Processing layers.32.attention_norm.weight
Processing layers.32.ffn_norm.weight
Processing layers.33.attention.wq.weight
Processing layers.33.attention.wk.weight
Processing layers.33.attention.wv.weight
Processing layers.33.attention.wo.weight
Processing layers.33.feed_forward.w1.weight
Processing layers.33.feed_forward.w2.weight
Processing layers.33.feed_forward.w3.weight
Processing layers.33.attention_norm.weight
Processing layers.33.ffn_norm.weight
Processing layers.34.attention.wq.weight
Processing layers.34.attention.wk.weight
Processing layers.34.attention.wv.weight
Processing layers.34.attention.wo.weight
Processing layers.34.feed_forward.w1.weight
Processing layers.34.feed_forward.w2.weight
Processing layers.34.feed_forward.w3.weight
Processing layers.34.attention_norm.weight
Processing layers.34.ffn_norm.weight
Processing layers.35.attention.wq.weight
Processing layers.35.attention.wk.weight
Processing layers.35.attention.wv.weight
Processing layers.35.attention.wo.weight
Processing layers.35.feed_forward.w1.weight
Processing layers.35.feed_forward.w2.weight
Processing layers.35.feed_forward.w3.weight
Processing layers.35.attention_norm.weight
Processing layers.35.ffn_norm.weight
Processing layers.36.attention.wq.weight
Processing layers.36.attention.wk.weight
Processing layers.36.attention.wv.weight
Processing layers.36.attention.wo.weight
Processing layers.36.feed_forward.w1.weight
Processing layers.36.feed_forward.w2.weight
Processing layers.36.feed_forward.w3.weight
Processing layers.36.attention_norm.weight
Processing layers.36.ffn_norm.weight
Processing layers.37.attention.wq.weight
Processing layers.37.attention.wk.weight
Processing layers.37.attention.wv.weight
Processing layers.37.attention.wo.weight
Processing layers.37.feed_forward.w1.weight
Processing layers.37.feed_forward.w2.weight
Processing layers.37.feed_forward.w3.weight
Processing layers.37.attention_norm.weight
Processing layers.37.ffn_norm.weight
Processing layers.38.attention.wq.weight
Processing layers.38.attention.wk.weight
Processing layers.38.attention.wv.weight
Processing layers.38.attention.wo.weight
Processing layers.38.feed_forward.w1.weight
Processing layers.38.feed_forward.w2.weight
Processing layers.38.feed_forward.w3.weight
Processing layers.38.attention_norm.weight
Processing layers.38.ffn_norm.weight
Processing layers.39.attention.wq.weight
Processing layers.39.attention.wk.weight
Processing layers.39.attention.wv.weight
Processing layers.39.attention.wo.weight
Processing layers.39.feed_forward.w1.weight
Processing layers.39.feed_forward.w2.weight
Processing layers.39.feed_forward.w3.weight
Processing layers.39.attention_norm.weight
Processing layers.39.ffn_norm.weight
Processing layers.40.attention.wq.weight
Processing layers.40.attention.wk.weight
Processing layers.40.attention.wv.weight
Processing layers.40.attention.wo.weight
Processing layers.40.feed_forward.w1.weight
Processing layers.40.feed_forward.w2.weight
Processing layers.40.feed_forward.w3.weight
Processing layers.40.attention_norm.weight
Processing layers.40.ffn_norm.weight
Processing layers.41.attention.wq.weight
Processing layers.41.attention.wk.weight
Processing layers.41.attention.wv.weight
Processing layers.41.attention.wo.weight
Processing layers.41.feed_forward.w1.weight
Processing layers.41.feed_forward.w2.weight
Processing layers.41.feed_forward.w3.weight
Processing layers.41.attention_norm.weight
Processing layers.41.ffn_norm.weight
Processing layers.42.attention.wq.weight
Processing layers.42.attention.wk.weight
Processing layers.42.attention.wv.weight
Processing layers.42.attention.wo.weight
Processing layers.42.feed_forward.w1.weight
Processing layers.42.feed_forward.w2.weight
Processing layers.42.feed_forward.w3.weight
Processing layers.42.attention_norm.weight
Processing layers.42.ffn_norm.weight
Processing layers.43.attention.wq.weight
Processing layers.43.attention.wk.weight
Processing layers.43.attention.wv.weight
Processing layers.43.attention.wo.weight
Processing layers.43.feed_forward.w1.weight
Processing layers.43.feed_forward.w2.weight
Processing layers.43.feed_forward.w3.weight
Processing layers.43.attention_norm.weight
Processing layers.43.ffn_norm.weight
Processing layers.44.attention.wq.weight
Processing layers.44.attention.wk.weight
Processing layers.44.attention.wv.weight
Processing layers.44.attention.wo.weight
Processing layers.44.feed_forward.w1.weight
Processing layers.44.feed_forward.w2.weight
Processing layers.44.feed_forward.w3.weight
Processing layers.44.attention_norm.weight
Processing layers.44.ffn_norm.weight
Processing layers.45.attention.wq.weight
Processing layers.45.attention.wk.weight
Processing layers.45.attention.wv.weight
Processing layers.45.attention.wo.weight
Processing layers.45.feed_forward.w1.weight
Processing layers.45.feed_forward.w2.weight
Processing layers.45.feed_forward.w3.weight
Processing layers.45.attention_norm.weight
Processing layers.45.ffn_norm.weight
Processing layers.46.attention.wq.weight
Processing layers.46.attention.wk.weight
Processing layers.46.attention.wv.weight
Processing layers.46.attention.wo.weight
Processing layers.46.feed_forward.w1.weight
Processing layers.46.feed_forward.w2.weight
Processing layers.46.feed_forward.w3.weight
Processing layers.46.attention_norm.weight
Processing layers.46.ffn_norm.weight
Processing layers.47.attention.wq.weight
Processing layers.47.attention.wk.weight
Processing layers.47.attention.wv.weight
Processing layers.47.attention.wo.weight
Processing layers.47.feed_forward.w1.weight
Processing layers.47.feed_forward.w2.weight
Processing layers.47.feed_forward.w3.weight
Processing layers.47.attention_norm.weight
Processing layers.47.ffn_norm.weight
Processing layers.48.attention.wq.weight
Processing layers.48.attention.wk.weight
Processing layers.48.attention.wv.weight
Processing layers.48.attention.wo.weight
Processing layers.48.feed_forward.w1.weight
Processing layers.48.feed_forward.w2.weight
Processing layers.48.feed_forward.w3.weight
Processing layers.48.attention_norm.weight
Processing layers.48.ffn_norm.weight
Processing layers.49.attention.wq.weight
Processing layers.49.attention.wk.weight
Processing layers.49.attention.wv.weight
Processing layers.49.attention.wo.weight
Processing layers.49.feed_forward.w1.weight
Processing layers.49.feed_forward.w2.weight
Processing layers.49.feed_forward.w3.weight
Processing layers.49.attention_norm.weight
Processing layers.49.ffn_norm.weight
Processing layers.50.attention.wq.weight
Processing layers.50.attention.wk.weight
Processing layers.50.attention.wv.weight
Processing layers.50.attention.wo.weight
Processing layers.50.feed_forward.w1.weight
Processing layers.50.feed_forward.w2.weight
Processing layers.50.feed_forward.w3.weight
Processing layers.50.attention_norm.weight
Processing layers.50.ffn_norm.weight
Processing layers.51.attention.wq.weight
Processing layers.51.attention.wk.weight
Processing layers.51.attention.wv.weight
Processing layers.51.attention.wo.weight
Processing layers.51.feed_forward.w1.weight
Processing layers.51.feed_forward.w2.weight
Processing layers.51.feed_forward.w3.weight
Processing layers.51.attention_norm.weight
Processing layers.51.ffn_norm.weight
Processing layers.52.attention.wq.weight
Processing layers.52.attention.wk.weight
Processing layers.52.attention.wv.weight
Processing layers.52.attention.wo.weight
Processing layers.52.feed_forward.w1.weight
Processing layers.52.feed_forward.w2.weight
Processing layers.52.feed_forward.w3.weight
Processing layers.52.attention_norm.weight
Processing layers.52.ffn_norm.weight
Processing layers.53.attention.wq.weight
Processing layers.53.attention.wk.weight
Processing layers.53.attention.wv.weight
Processing layers.53.attention.wo.weight
Processing layers.53.feed_forward.w1.weight
Processing layers.53.feed_forward.w2.weight
Processing layers.53.feed_forward.w3.weight
Processing layers.53.attention_norm.weight
Processing layers.53.ffn_norm.weight
Processing layers.54.attention.wq.weight
Processing layers.54.attention.wk.weight
Processing layers.54.attention.wv.weight
Processing layers.54.attention.wo.weight
Processing layers.54.feed_forward.w1.weight
Processing layers.54.feed_forward.w2.weight
Processing layers.54.feed_forward.w3.weight
Processing layers.54.attention_norm.weight
Processing layers.54.ffn_norm.weight
Processing layers.55.attention.wq.weight
Processing layers.55.attention.wk.weight
Processing layers.55.attention.wv.weight
Processing layers.55.attention.wo.weight
Processing layers.55.feed_forward.w1.weight
Processing layers.55.feed_forward.w2.weight
Processing layers.55.feed_forward.w3.weight
Processing layers.55.attention_norm.weight
Processing layers.55.ffn_norm.weight
Processing layers.56.attention.wq.weight
Processing layers.56.attention.wk.weight
Processing layers.56.attention.wv.weight
Processing layers.56.attention.wo.weight
Processing layers.56.feed_forward.w1.weight
Processing layers.56.feed_forward.w2.weight
Processing layers.56.feed_forward.w3.weight
Processing layers.56.attention_norm.weight
Processing layers.56.ffn_norm.weight
Processing layers.57.attention.wq.weight
Processing layers.57.attention.wk.weight
Processing layers.57.attention.wv.weight
Processing layers.57.attention.wo.weight
Processing layers.57.feed_forward.w1.weight
Processing layers.57.feed_forward.w2.weight
Processing layers.57.feed_forward.w3.weight
Processing layers.57.attention_norm.weight
Processing layers.57.ffn_norm.weight
Processing layers.58.attention.wq.weight
Processing layers.58.attention.wk.weight
Processing layers.58.attention.wv.weight
Processing layers.58.attention.wo.weight
Processing layers.58.feed_forward.w1.weight
Processing layers.58.feed_forward.w2.weight
Processing layers.58.feed_forward.w3.weight
Processing layers.58.attention_norm.weight
Processing layers.58.ffn_norm.weight
Processing layers.59.attention.wq.weight
Processing layers.59.attention.wk.weight
Processing layers.59.attention.wv.weight
Processing layers.59.attention.wo.weight
Processing layers.59.feed_forward.w1.weight
Processing layers.59.feed_forward.w2.weight
Processing layers.59.feed_forward.w3.weight
Processing layers.59.attention_norm.weight
Processing layers.59.ffn_norm.weight
Processing norm.weight
Processing output.weight
Saving shard 1 of 4 into ./chinese-alpaca-33b-pth/consolidated.00.pth
Saving shard 2 of 4 into ./chinese-alpaca-33b-pth/consolidated.01.pth
Saving shard 3 of 4 into ./chinese-alpaca-33b-pth/consolidated.02.pth
Saving shard 4 of 4 into ./chinese-alpaca-33b-pth/consolidated.03.pth
Saving params.json into ./chinese-alpaca-33b-pth/params.json
3.llaa.cpp量化
模型准备
cd /notebooks/llama.cpp
mkdir zh-models/
cp /notebooks/Chinese-LLaMA-Alpaca/chinese-alpaca-33b-pth/tokenizer.model zh-models
mkdir zh-models/33B
cp /notebooks/Chinese-LLaMA-Alpaca/chinese-alpaca-33b-pth/consolidated.0* zh-models/33B/
cp /notebooks/Chinese-LLaMA-Alpaca/Chinese-alpaca-33B-pth/params.json zh-models/33B/
模型权重转换为ggml的FP16格式
执行:
python convert.py zh-models/33B/
输出信息:
# python convert.py zh-models/33B/
Loading model file zh-models/33B/consolidated.00.pth
Loading model file zh-models/33B/consolidated.01.pth
Loading model file zh-models/33B/consolidated.02.pth
Loading model file zh-models/33B/consolidated.03.pth
Loading vocab file zh-models/tokenizer.model
params: n_vocab:49954 n_embd:6656 n_mult:256 n_head:52 n_layer:60
Writing vocab...
[ 1/543] Writing tensor tok_embeddings.weight | size 49954 x 6656 | type UnquantizedDataType(name='F16')
[ 2/543] Writing tensor norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 3/543] Writing tensor output.weight | size 49954 x 6656 | type UnquantizedDataType(name='F16')
[ 4/543] Writing tensor layers.0.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 5/543] Writing tensor layers.0.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 6/543] Writing tensor layers.0.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 7/543] Writing tensor layers.0.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 8/543] Writing tensor layers.0.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 9/543] Writing tensor layers.0.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 10/543] Writing tensor layers.0.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[ 11/543] Writing tensor layers.0.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 12/543] Writing tensor layers.0.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 13/543] Writing tensor layers.1.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 14/543] Writing tensor layers.1.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 15/543] Writing tensor layers.1.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 16/543] Writing tensor layers.1.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 17/543] Writing tensor layers.1.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 18/543] Writing tensor layers.1.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 19/543] Writing tensor layers.1.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[ 20/543] Writing tensor layers.1.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 21/543] Writing tensor layers.1.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 22/543] Writing tensor layers.2.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 23/543] Writing tensor layers.2.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 24/543] Writing tensor layers.2.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 25/543] Writing tensor layers.2.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 26/543] Writing tensor layers.2.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 27/543] Writing tensor layers.2.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 28/543] Writing tensor layers.2.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[ 29/543] Writing tensor layers.2.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 30/543] Writing tensor layers.2.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 31/543] Writing tensor layers.3.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 32/543] Writing tensor layers.3.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 33/543] Writing tensor layers.3.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 34/543] Writing tensor layers.3.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 35/543] Writing tensor layers.3.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 36/543] Writing tensor layers.3.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 37/543] Writing tensor layers.3.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[ 38/543] Writing tensor layers.3.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 39/543] Writing tensor layers.3.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 40/543] Writing tensor layers.4.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 41/543] Writing tensor layers.4.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 42/543] Writing tensor layers.4.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 43/543] Writing tensor layers.4.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 44/543] Writing tensor layers.4.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 45/543] Writing tensor layers.4.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 46/543] Writing tensor layers.4.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[ 47/543] Writing tensor layers.4.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 48/543] Writing tensor layers.4.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 49/543] Writing tensor layers.5.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 50/543] Writing tensor layers.5.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 51/543] Writing tensor layers.5.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 52/543] Writing tensor layers.5.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 53/543] Writing tensor layers.5.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 54/543] Writing tensor layers.5.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 55/543] Writing tensor layers.5.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[ 56/543] Writing tensor layers.5.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 57/543] Writing tensor layers.5.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 58/543] Writing tensor layers.6.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 59/543] Writing tensor layers.6.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 60/543] Writing tensor layers.6.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 61/543] Writing tensor layers.6.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 62/543] Writing tensor layers.6.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 63/543] Writing tensor layers.6.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 64/543] Writing tensor layers.6.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[ 65/543] Writing tensor layers.6.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 66/543] Writing tensor layers.6.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 67/543] Writing tensor layers.7.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 68/543] Writing tensor layers.7.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 69/543] Writing tensor layers.7.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 70/543] Writing tensor layers.7.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 71/543] Writing tensor layers.7.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 72/543] Writing tensor layers.7.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 73/543] Writing tensor layers.7.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[ 74/543] Writing tensor layers.7.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 75/543] Writing tensor layers.7.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 76/543] Writing tensor layers.8.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 77/543] Writing tensor layers.8.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 78/543] Writing tensor layers.8.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 79/543] Writing tensor layers.8.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 80/543] Writing tensor layers.8.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 81/543] Writing tensor layers.8.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 82/543] Writing tensor layers.8.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[ 83/543] Writing tensor layers.8.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 84/543] Writing tensor layers.8.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 85/543] Writing tensor layers.9.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 86/543] Writing tensor layers.9.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 87/543] Writing tensor layers.9.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 88/543] Writing tensor layers.9.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 89/543] Writing tensor layers.9.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 90/543] Writing tensor layers.9.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 91/543] Writing tensor layers.9.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[ 92/543] Writing tensor layers.9.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[ 93/543] Writing tensor layers.9.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 94/543] Writing tensor layers.10.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 95/543] Writing tensor layers.10.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 96/543] Writing tensor layers.10.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 97/543] Writing tensor layers.10.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[ 98/543] Writing tensor layers.10.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[ 99/543] Writing tensor layers.10.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[100/543] Writing tensor layers.10.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[101/543] Writing tensor layers.10.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[102/543] Writing tensor layers.10.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[103/543] Writing tensor layers.11.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[104/543] Writing tensor layers.11.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[105/543] Writing tensor layers.11.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[106/543] Writing tensor layers.11.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[107/543] Writing tensor layers.11.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[108/543] Writing tensor layers.11.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[109/543] Writing tensor layers.11.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[110/543] Writing tensor layers.11.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[111/543] Writing tensor layers.11.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[112/543] Writing tensor layers.12.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[113/543] Writing tensor layers.12.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[114/543] Writing tensor layers.12.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[115/543] Writing tensor layers.12.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[116/543] Writing tensor layers.12.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[117/543] Writing tensor layers.12.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[118/543] Writing tensor layers.12.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[119/543] Writing tensor layers.12.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[120/543] Writing tensor layers.12.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[121/543] Writing tensor layers.13.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[122/543] Writing tensor layers.13.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[123/543] Writing tensor layers.13.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[124/543] Writing tensor layers.13.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[125/543] Writing tensor layers.13.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[126/543] Writing tensor layers.13.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[127/543] Writing tensor layers.13.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[128/543] Writing tensor layers.13.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[129/543] Writing tensor layers.13.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[130/543] Writing tensor layers.14.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[131/543] Writing tensor layers.14.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[132/543] Writing tensor layers.14.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[133/543] Writing tensor layers.14.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[134/543] Writing tensor layers.14.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[135/543] Writing tensor layers.14.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[136/543] Writing tensor layers.14.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[137/543] Writing tensor layers.14.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[138/543] Writing tensor layers.14.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[139/543] Writing tensor layers.15.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[140/543] Writing tensor layers.15.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[141/543] Writing tensor layers.15.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[142/543] Writing tensor layers.15.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[143/543] Writing tensor layers.15.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[144/543] Writing tensor layers.15.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[145/543] Writing tensor layers.15.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[146/543] Writing tensor layers.15.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[147/543] Writing tensor layers.15.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[148/543] Writing tensor layers.16.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[149/543] Writing tensor layers.16.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[150/543] Writing tensor layers.16.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[151/543] Writing tensor layers.16.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[152/543] Writing tensor layers.16.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[153/543] Writing tensor layers.16.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[154/543] Writing tensor layers.16.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[155/543] Writing tensor layers.16.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[156/543] Writing tensor layers.16.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[157/543] Writing tensor layers.17.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[158/543] Writing tensor layers.17.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[159/543] Writing tensor layers.17.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[160/543] Writing tensor layers.17.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[161/543] Writing tensor layers.17.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[162/543] Writing tensor layers.17.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[163/543] Writing tensor layers.17.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[164/543] Writing tensor layers.17.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[165/543] Writing tensor layers.17.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[166/543] Writing tensor layers.18.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[167/543] Writing tensor layers.18.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[168/543] Writing tensor layers.18.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[169/543] Writing tensor layers.18.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[170/543] Writing tensor layers.18.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[171/543] Writing tensor layers.18.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[172/543] Writing tensor layers.18.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[173/543] Writing tensor layers.18.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[174/543] Writing tensor layers.18.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[175/543] Writing tensor layers.19.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[176/543] Writing tensor layers.19.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[177/543] Writing tensor layers.19.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[178/543] Writing tensor layers.19.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[179/543] Writing tensor layers.19.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[180/543] Writing tensor layers.19.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[181/543] Writing tensor layers.19.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[182/543] Writing tensor layers.19.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[183/543] Writing tensor layers.19.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[184/543] Writing tensor layers.20.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[185/543] Writing tensor layers.20.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[186/543] Writing tensor layers.20.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[187/543] Writing tensor layers.20.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[188/543] Writing tensor layers.20.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[189/543] Writing tensor layers.20.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[190/543] Writing tensor layers.20.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[191/543] Writing tensor layers.20.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[192/543] Writing tensor layers.20.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[193/543] Writing tensor layers.21.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[194/543] Writing tensor layers.21.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[195/543] Writing tensor layers.21.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[196/543] Writing tensor layers.21.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[197/543] Writing tensor layers.21.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[198/543] Writing tensor layers.21.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[199/543] Writing tensor layers.21.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[200/543] Writing tensor layers.21.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[201/543] Writing tensor layers.21.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[202/543] Writing tensor layers.22.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[203/543] Writing tensor layers.22.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[204/543] Writing tensor layers.22.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[205/543] Writing tensor layers.22.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[206/543] Writing tensor layers.22.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[207/543] Writing tensor layers.22.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[208/543] Writing tensor layers.22.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[209/543] Writing tensor layers.22.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[210/543] Writing tensor layers.22.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[211/543] Writing tensor layers.23.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[212/543] Writing tensor layers.23.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[213/543] Writing tensor layers.23.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[214/543] Writing tensor layers.23.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[215/543] Writing tensor layers.23.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[216/543] Writing tensor layers.23.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[217/543] Writing tensor layers.23.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[218/543] Writing tensor layers.23.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[219/543] Writing tensor layers.23.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[220/543] Writing tensor layers.24.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[221/543] Writing tensor layers.24.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[222/543] Writing tensor layers.24.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[223/543] Writing tensor layers.24.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[224/543] Writing tensor layers.24.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[225/543] Writing tensor layers.24.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[226/543] Writing tensor layers.24.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[227/543] Writing tensor layers.24.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[228/543] Writing tensor layers.24.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[229/543] Writing tensor layers.25.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[230/543] Writing tensor layers.25.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[231/543] Writing tensor layers.25.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[232/543] Writing tensor layers.25.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[233/543] Writing tensor layers.25.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[234/543] Writing tensor layers.25.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[235/543] Writing tensor layers.25.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[236/543] Writing tensor layers.25.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[237/543] Writing tensor layers.25.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[238/543] Writing tensor layers.26.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[239/543] Writing tensor layers.26.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[240/543] Writing tensor layers.26.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[241/543] Writing tensor layers.26.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[242/543] Writing tensor layers.26.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[243/543] Writing tensor layers.26.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[244/543] Writing tensor layers.26.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[245/543] Writing tensor layers.26.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[246/543] Writing tensor layers.26.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[247/543] Writing tensor layers.27.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[248/543] Writing tensor layers.27.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[249/543] Writing tensor layers.27.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[250/543] Writing tensor layers.27.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[251/543] Writing tensor layers.27.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[252/543] Writing tensor layers.27.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[253/543] Writing tensor layers.27.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[254/543] Writing tensor layers.27.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[255/543] Writing tensor layers.27.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[256/543] Writing tensor layers.28.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[257/543] Writing tensor layers.28.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[258/543] Writing tensor layers.28.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[259/543] Writing tensor layers.28.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[260/543] Writing tensor layers.28.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[261/543] Writing tensor layers.28.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[262/543] Writing tensor layers.28.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[263/543] Writing tensor layers.28.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[264/543] Writing tensor layers.28.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[265/543] Writing tensor layers.29.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[266/543] Writing tensor layers.29.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[267/543] Writing tensor layers.29.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[268/543] Writing tensor layers.29.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[269/543] Writing tensor layers.29.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[270/543] Writing tensor layers.29.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[271/543] Writing tensor layers.29.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[272/543] Writing tensor layers.29.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[273/543] Writing tensor layers.29.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[274/543] Writing tensor layers.30.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[275/543] Writing tensor layers.30.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[276/543] Writing tensor layers.30.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[277/543] Writing tensor layers.30.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[278/543] Writing tensor layers.30.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[279/543] Writing tensor layers.30.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[280/543] Writing tensor layers.30.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[281/543] Writing tensor layers.30.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[282/543] Writing tensor layers.30.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[283/543] Writing tensor layers.31.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[284/543] Writing tensor layers.31.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[285/543] Writing tensor layers.31.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[286/543] Writing tensor layers.31.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[287/543] Writing tensor layers.31.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[288/543] Writing tensor layers.31.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[289/543] Writing tensor layers.31.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[290/543] Writing tensor layers.31.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[291/543] Writing tensor layers.31.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[292/543] Writing tensor layers.32.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[293/543] Writing tensor layers.32.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[294/543] Writing tensor layers.32.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[295/543] Writing tensor layers.32.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[296/543] Writing tensor layers.32.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[297/543] Writing tensor layers.32.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[298/543] Writing tensor layers.32.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[299/543] Writing tensor layers.32.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[300/543] Writing tensor layers.32.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[301/543] Writing tensor layers.33.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[302/543] Writing tensor layers.33.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[303/543] Writing tensor layers.33.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[304/543] Writing tensor layers.33.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[305/543] Writing tensor layers.33.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[306/543] Writing tensor layers.33.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[307/543] Writing tensor layers.33.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[308/543] Writing tensor layers.33.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[309/543] Writing tensor layers.33.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[310/543] Writing tensor layers.34.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[311/543] Writing tensor layers.34.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[312/543] Writing tensor layers.34.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[313/543] Writing tensor layers.34.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[314/543] Writing tensor layers.34.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[315/543] Writing tensor layers.34.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[316/543] Writing tensor layers.34.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[317/543] Writing tensor layers.34.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[318/543] Writing tensor layers.34.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[319/543] Writing tensor layers.35.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[320/543] Writing tensor layers.35.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[321/543] Writing tensor layers.35.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[322/543] Writing tensor layers.35.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[323/543] Writing tensor layers.35.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[324/543] Writing tensor layers.35.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[325/543] Writing tensor layers.35.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[326/543] Writing tensor layers.35.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[327/543] Writing tensor layers.35.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[328/543] Writing tensor layers.36.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[329/543] Writing tensor layers.36.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[330/543] Writing tensor layers.36.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[331/543] Writing tensor layers.36.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[332/543] Writing tensor layers.36.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[333/543] Writing tensor layers.36.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[334/543] Writing tensor layers.36.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[335/543] Writing tensor layers.36.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[336/543] Writing tensor layers.36.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[337/543] Writing tensor layers.37.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[338/543] Writing tensor layers.37.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[339/543] Writing tensor layers.37.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[340/543] Writing tensor layers.37.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[341/543] Writing tensor layers.37.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[342/543] Writing tensor layers.37.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[343/543] Writing tensor layers.37.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[344/543] Writing tensor layers.37.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[345/543] Writing tensor layers.37.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[346/543] Writing tensor layers.38.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[347/543] Writing tensor layers.38.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[348/543] Writing tensor layers.38.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[349/543] Writing tensor layers.38.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[350/543] Writing tensor layers.38.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[351/543] Writing tensor layers.38.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[352/543] Writing tensor layers.38.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[353/543] Writing tensor layers.38.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[354/543] Writing tensor layers.38.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[355/543] Writing tensor layers.39.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[356/543] Writing tensor layers.39.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[357/543] Writing tensor layers.39.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[358/543] Writing tensor layers.39.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[359/543] Writing tensor layers.39.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[360/543] Writing tensor layers.39.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[361/543] Writing tensor layers.39.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[362/543] Writing tensor layers.39.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[363/543] Writing tensor layers.39.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[364/543] Writing tensor layers.40.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[365/543] Writing tensor layers.40.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[366/543] Writing tensor layers.40.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[367/543] Writing tensor layers.40.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[368/543] Writing tensor layers.40.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[369/543] Writing tensor layers.40.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[370/543] Writing tensor layers.40.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[371/543] Writing tensor layers.40.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[372/543] Writing tensor layers.40.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[373/543] Writing tensor layers.41.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[374/543] Writing tensor layers.41.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[375/543] Writing tensor layers.41.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[376/543] Writing tensor layers.41.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[377/543] Writing tensor layers.41.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[378/543] Writing tensor layers.41.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[379/543] Writing tensor layers.41.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[380/543] Writing tensor layers.41.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[381/543] Writing tensor layers.41.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[382/543] Writing tensor layers.42.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[383/543] Writing tensor layers.42.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[384/543] Writing tensor layers.42.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[385/543] Writing tensor layers.42.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[386/543] Writing tensor layers.42.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[387/543] Writing tensor layers.42.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[388/543] Writing tensor layers.42.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[389/543] Writing tensor layers.42.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[390/543] Writing tensor layers.42.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[391/543] Writing tensor layers.43.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[392/543] Writing tensor layers.43.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[393/543] Writing tensor layers.43.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[394/543] Writing tensor layers.43.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[395/543] Writing tensor layers.43.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[396/543] Writing tensor layers.43.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[397/543] Writing tensor layers.43.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[398/543] Writing tensor layers.43.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[399/543] Writing tensor layers.43.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[400/543] Writing tensor layers.44.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[401/543] Writing tensor layers.44.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[402/543] Writing tensor layers.44.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[403/543] Writing tensor layers.44.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[404/543] Writing tensor layers.44.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[405/543] Writing tensor layers.44.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[406/543] Writing tensor layers.44.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[407/543] Writing tensor layers.44.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[408/543] Writing tensor layers.44.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[409/543] Writing tensor layers.45.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[410/543] Writing tensor layers.45.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[411/543] Writing tensor layers.45.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[412/543] Writing tensor layers.45.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[413/543] Writing tensor layers.45.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[414/543] Writing tensor layers.45.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[415/543] Writing tensor layers.45.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[416/543] Writing tensor layers.45.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[417/543] Writing tensor layers.45.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[418/543] Writing tensor layers.46.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[419/543] Writing tensor layers.46.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[420/543] Writing tensor layers.46.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[421/543] Writing tensor layers.46.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[422/543] Writing tensor layers.46.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[423/543] Writing tensor layers.46.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[424/543] Writing tensor layers.46.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[425/543] Writing tensor layers.46.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[426/543] Writing tensor layers.46.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[427/543] Writing tensor layers.47.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[428/543] Writing tensor layers.47.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[429/543] Writing tensor layers.47.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[430/543] Writing tensor layers.47.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[431/543] Writing tensor layers.47.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[432/543] Writing tensor layers.47.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[433/543] Writing tensor layers.47.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[434/543] Writing tensor layers.47.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[435/543] Writing tensor layers.47.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[436/543] Writing tensor layers.48.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[437/543] Writing tensor layers.48.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[438/543] Writing tensor layers.48.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[439/543] Writing tensor layers.48.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[440/543] Writing tensor layers.48.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[441/543] Writing tensor layers.48.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[442/543] Writing tensor layers.48.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[443/543] Writing tensor layers.48.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[444/543] Writing tensor layers.48.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[445/543] Writing tensor layers.49.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[446/543] Writing tensor layers.49.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[447/543] Writing tensor layers.49.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[448/543] Writing tensor layers.49.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[449/543] Writing tensor layers.49.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[450/543] Writing tensor layers.49.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[451/543] Writing tensor layers.49.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[452/543] Writing tensor layers.49.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[453/543] Writing tensor layers.49.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[454/543] Writing tensor layers.50.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[455/543] Writing tensor layers.50.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[456/543] Writing tensor layers.50.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[457/543] Writing tensor layers.50.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[458/543] Writing tensor layers.50.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[459/543] Writing tensor layers.50.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[460/543] Writing tensor layers.50.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[461/543] Writing tensor layers.50.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[462/543] Writing tensor layers.50.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[463/543] Writing tensor layers.51.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[464/543] Writing tensor layers.51.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[465/543] Writing tensor layers.51.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[466/543] Writing tensor layers.51.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[467/543] Writing tensor layers.51.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[468/543] Writing tensor layers.51.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[469/543] Writing tensor layers.51.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[470/543] Writing tensor layers.51.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[471/543] Writing tensor layers.51.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[472/543] Writing tensor layers.52.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[473/543] Writing tensor layers.52.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[474/543] Writing tensor layers.52.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[475/543] Writing tensor layers.52.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[476/543] Writing tensor layers.52.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[477/543] Writing tensor layers.52.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[478/543] Writing tensor layers.52.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[479/543] Writing tensor layers.52.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[480/543] Writing tensor layers.52.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[481/543] Writing tensor layers.53.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[482/543] Writing tensor layers.53.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[483/543] Writing tensor layers.53.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[484/543] Writing tensor layers.53.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[485/543] Writing tensor layers.53.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[486/543] Writing tensor layers.53.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[487/543] Writing tensor layers.53.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[488/543] Writing tensor layers.53.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[489/543] Writing tensor layers.53.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[490/543] Writing tensor layers.54.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[491/543] Writing tensor layers.54.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[492/543] Writing tensor layers.54.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[493/543] Writing tensor layers.54.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[494/543] Writing tensor layers.54.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[495/543] Writing tensor layers.54.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[496/543] Writing tensor layers.54.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[497/543] Writing tensor layers.54.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[498/543] Writing tensor layers.54.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[499/543] Writing tensor layers.55.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[500/543] Writing tensor layers.55.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[501/543] Writing tensor layers.55.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[502/543] Writing tensor layers.55.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[503/543] Writing tensor layers.55.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[504/543] Writing tensor layers.55.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[505/543] Writing tensor layers.55.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[506/543] Writing tensor layers.55.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[507/543] Writing tensor layers.55.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[508/543] Writing tensor layers.56.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[509/543] Writing tensor layers.56.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[510/543] Writing tensor layers.56.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[511/543] Writing tensor layers.56.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[512/543] Writing tensor layers.56.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[513/543] Writing tensor layers.56.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[514/543] Writing tensor layers.56.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[515/543] Writing tensor layers.56.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[516/543] Writing tensor layers.56.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[517/543] Writing tensor layers.57.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[518/543] Writing tensor layers.57.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[519/543] Writing tensor layers.57.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[520/543] Writing tensor layers.57.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[521/543] Writing tensor layers.57.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[522/543] Writing tensor layers.57.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[523/543] Writing tensor layers.57.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[524/543] Writing tensor layers.57.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[525/543] Writing tensor layers.57.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[526/543] Writing tensor layers.58.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[527/543] Writing tensor layers.58.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[528/543] Writing tensor layers.58.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[529/543] Writing tensor layers.58.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[530/543] Writing tensor layers.58.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[531/543] Writing tensor layers.58.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[532/543] Writing tensor layers.58.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[533/543] Writing tensor layers.58.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[534/543] Writing tensor layers.58.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[535/543] Writing tensor layers.59.attention.wq.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[536/543] Writing tensor layers.59.attention.wk.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[537/543] Writing tensor layers.59.attention.wv.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[538/543] Writing tensor layers.59.attention.wo.weight | size 6656 x 6656 | type UnquantizedDataType(name='F16')
[539/543] Writing tensor layers.59.attention_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
[540/543] Writing tensor layers.59.feed_forward.w1.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[541/543] Writing tensor layers.59.feed_forward.w2.weight | size 6656 x 17920 | type UnquantizedDataType(name='F16')
[542/543] Writing tensor layers.59.feed_forward.w3.weight | size 17920 x 6656 | type UnquantizedDataType(name='F16')
[543/543] Writing tensor layers.59.ffn_norm.weight | size 6656 | type UnquantizedDataType(name='F32')
Wrote zh-models/33B/ggml-model-f16.bin
对FP16模型进行4-bit量化
执行:
./quantize ./zh-models/33B/ggml-model-f16.bin ./zh-models/33B/ggml-model-q4_0.bin q4_0
输出信息:
ggml_init_cublas: found 4 CUDA devices:
Device 0: Tesla P40, compute capability 6.1
Device 1: Tesla P40, compute capability 6.1
Device 2: Tesla P40, compute capability 6.1
Device 3: Tesla P40, compute capability 6.1
main: build = 796 (31cfbb1)
main: quantizing './zh-models/33B/ggml-model-f16.bin' to './zh-models/33B/ggml-model-q4_0.bin' as Q4_0
llama.cpp: loading model from ./zh-models/33B/ggml-model-f16.bin
llama.cpp: saving model to ./zh-models/33B/ggml-model-q4_0.bin
[ 1/ 543] tok_embeddings.weight - 6656 x 49954, type = f16, quantizing .. size = 634.18 MB -> 178.36 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 2/ 543] norm.weight - 6656, type = f32, size = 0.025 MB
[ 3/ 543] output.weight - 6656 x 49954, type = f16, quantizing .. size = 634.18 MB -> 178.36 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.112 0.118 0.112 0.097 0.076 0.056 0.038 0.025 0.020
[ 4/ 543] layers.0.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.018 0.028 0.043 0.060 0.077 0.094 0.106 0.111 0.106 0.094 0.077 0.059 0.042 0.028 0.022
[ 5/ 543] layers.0.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.013 0.021 0.033 0.050 0.072 0.099 0.124 0.136 0.124 0.099 0.072 0.050 0.033 0.021 0.017
[ 6/ 543] layers.0.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.055 0.076 0.097 0.113 0.120 0.113 0.097 0.076 0.055 0.038 0.025 0.020
[ 7/ 543] layers.0.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.035 0.012 0.020 0.032 0.049 0.073 0.100 0.126 0.137 0.126 0.100 0.073 0.049 0.032 0.020 0.016
[ 8/ 543] layers.0.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 9/ 543] layers.0.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.077 0.097 0.113 0.118 0.113 0.097 0.077 0.056 0.038 0.025 0.020
[ 10/ 543] layers.0.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 11/ 543] layers.0.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.113 0.119 0.113 0.097 0.076 0.056 0.038 0.025 0.020
[ 12/ 543] layers.0.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 13/ 543] layers.1.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.113 0.120 0.113 0.097 0.076 0.056 0.038 0.025 0.020
[ 14/ 543] layers.1.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.113 0.120 0.113 0.097 0.076 0.056 0.038 0.025 0.020
[ 15/ 543] layers.1.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.038 0.025 0.021
[ 16/ 543] layers.1.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.014 0.023 0.036 0.054 0.075 0.098 0.117 0.124 0.117 0.098 0.075 0.054 0.036 0.023 0.019
[ 17/ 543] layers.1.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 18/ 543] layers.1.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 19/ 543] layers.1.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 20/ 543] layers.1.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 21/ 543] layers.1.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 22/ 543] layers.2.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.096 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 23/ 543] layers.2.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.113 0.119 0.113 0.097 0.076 0.056 0.038 0.025 0.020
[ 24/ 543] layers.2.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.118 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 25/ 543] layers.2.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 26/ 543] layers.2.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 27/ 543] layers.2.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 28/ 543] layers.2.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 29/ 543] layers.2.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 30/ 543] layers.2.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 31/ 543] layers.3.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 32/ 543] layers.3.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.112 0.119 0.112 0.097 0.076 0.056 0.038 0.025 0.021
[ 33/ 543] layers.3.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.118 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 34/ 543] layers.3.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.056 0.039 0.025 0.021
[ 35/ 543] layers.3.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 36/ 543] layers.3.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 37/ 543] layers.3.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 38/ 543] layers.3.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 39/ 543] layers.3.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 40/ 543] layers.4.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 41/ 543] layers.4.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 42/ 543] layers.4.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 43/ 543] layers.4.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 44/ 543] layers.4.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 45/ 543] layers.4.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 46/ 543] layers.4.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 47/ 543] layers.4.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 48/ 543] layers.4.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 49/ 543] layers.5.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 50/ 543] layers.5.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.056 0.039 0.025 0.021
[ 51/ 543] layers.5.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 52/ 543] layers.5.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 53/ 543] layers.5.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 54/ 543] layers.5.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 55/ 543] layers.5.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 56/ 543] layers.5.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 57/ 543] layers.5.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 58/ 543] layers.6.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 59/ 543] layers.6.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 60/ 543] layers.6.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 61/ 543] layers.6.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 62/ 543] layers.6.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 63/ 543] layers.6.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 64/ 543] layers.6.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 65/ 543] layers.6.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 66/ 543] layers.6.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 67/ 543] layers.7.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 68/ 543] layers.7.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.097 0.111 0.117 0.112 0.096 0.077 0.056 0.039 0.025 0.021
[ 69/ 543] layers.7.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 70/ 543] layers.7.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 71/ 543] layers.7.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 72/ 543] layers.7.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 73/ 543] layers.7.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 74/ 543] layers.7.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 75/ 543] layers.7.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 76/ 543] layers.8.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 77/ 543] layers.8.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.112 0.097 0.077 0.057 0.039 0.025 0.021
[ 78/ 543] layers.8.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 79/ 543] layers.8.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 80/ 543] layers.8.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 81/ 543] layers.8.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 82/ 543] layers.8.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 83/ 543] layers.8.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 84/ 543] layers.8.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 85/ 543] layers.9.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 86/ 543] layers.9.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 87/ 543] layers.9.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 88/ 543] layers.9.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 89/ 543] layers.9.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 90/ 543] layers.9.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 91/ 543] layers.9.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 92/ 543] layers.9.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 93/ 543] layers.9.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 94/ 543] layers.10.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 95/ 543] layers.10.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 96/ 543] layers.10.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 97/ 543] layers.10.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 98/ 543] layers.10.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 99/ 543] layers.10.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 100/ 543] layers.10.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 101/ 543] layers.10.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 102/ 543] layers.10.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 103/ 543] layers.11.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 104/ 543] layers.11.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 105/ 543] layers.11.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 106/ 543] layers.11.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 107/ 543] layers.11.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 108/ 543] layers.11.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 109/ 543] layers.11.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 110/ 543] layers.11.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 111/ 543] layers.11.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 112/ 543] layers.12.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 113/ 543] layers.12.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 114/ 543] layers.12.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 115/ 543] layers.12.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 116/ 543] layers.12.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 117/ 543] layers.12.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 118/ 543] layers.12.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 119/ 543] layers.12.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 120/ 543] layers.12.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 121/ 543] layers.13.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 122/ 543] layers.13.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 123/ 543] layers.13.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 124/ 543] layers.13.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 125/ 543] layers.13.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 126/ 543] layers.13.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 127/ 543] layers.13.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 128/ 543] layers.13.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 129/ 543] layers.13.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 130/ 543] layers.14.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 131/ 543] layers.14.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 132/ 543] layers.14.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 133/ 543] layers.14.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 134/ 543] layers.14.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 135/ 543] layers.14.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 136/ 543] layers.14.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 137/ 543] layers.14.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 138/ 543] layers.14.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 139/ 543] layers.15.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 140/ 543] layers.15.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 141/ 543] layers.15.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 142/ 543] layers.15.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 143/ 543] layers.15.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 144/ 543] layers.15.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 145/ 543] layers.15.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 146/ 543] layers.15.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 147/ 543] layers.15.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 148/ 543] layers.16.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 149/ 543] layers.16.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 150/ 543] layers.16.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 151/ 543] layers.16.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 152/ 543] layers.16.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 153/ 543] layers.16.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 154/ 543] layers.16.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 155/ 543] layers.16.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 156/ 543] layers.16.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 157/ 543] layers.17.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 158/ 543] layers.17.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.056 0.039 0.025 0.021
[ 159/ 543] layers.17.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 160/ 543] layers.17.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 161/ 543] layers.17.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 162/ 543] layers.17.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 163/ 543] layers.17.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 164/ 543] layers.17.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 165/ 543] layers.17.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 166/ 543] layers.18.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 167/ 543] layers.18.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.097 0.077 0.056 0.039 0.025 0.021
[ 168/ 543] layers.18.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 169/ 543] layers.18.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 170/ 543] layers.18.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 171/ 543] layers.18.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 172/ 543] layers.18.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 173/ 543] layers.18.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 174/ 543] layers.18.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 175/ 543] layers.19.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 176/ 543] layers.19.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 177/ 543] layers.19.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 178/ 543] layers.19.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 179/ 543] layers.19.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 180/ 543] layers.19.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 181/ 543] layers.19.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 182/ 543] layers.19.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 183/ 543] layers.19.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 184/ 543] layers.20.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 185/ 543] layers.20.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 186/ 543] layers.20.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 187/ 543] layers.20.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 188/ 543] layers.20.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 189/ 543] layers.20.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 190/ 543] layers.20.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 191/ 543] layers.20.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 192/ 543] layers.20.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 193/ 543] layers.21.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 194/ 543] layers.21.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 195/ 543] layers.21.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 196/ 543] layers.21.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 197/ 543] layers.21.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 198/ 543] layers.21.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 199/ 543] layers.21.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 200/ 543] layers.21.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 201/ 543] layers.21.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 202/ 543] layers.22.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 203/ 543] layers.22.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 204/ 543] layers.22.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 205/ 543] layers.22.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 206/ 543] layers.22.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 207/ 543] layers.22.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 208/ 543] layers.22.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 209/ 543] layers.22.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 210/ 543] layers.22.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 211/ 543] layers.23.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 212/ 543] layers.23.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 213/ 543] layers.23.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 214/ 543] layers.23.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 215/ 543] layers.23.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 216/ 543] layers.23.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 217/ 543] layers.23.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 218/ 543] layers.23.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 219/ 543] layers.23.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 220/ 543] layers.24.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 221/ 543] layers.24.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.097 0.077 0.056 0.039 0.025 0.021
[ 222/ 543] layers.24.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 223/ 543] layers.24.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 224/ 543] layers.24.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 225/ 543] layers.24.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 226/ 543] layers.24.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 227/ 543] layers.24.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 228/ 543] layers.24.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 229/ 543] layers.25.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 230/ 543] layers.25.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.056 0.039 0.025 0.021
[ 231/ 543] layers.25.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 232/ 543] layers.25.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 233/ 543] layers.25.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 234/ 543] layers.25.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 235/ 543] layers.25.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 236/ 543] layers.25.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 237/ 543] layers.25.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 238/ 543] layers.26.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 239/ 543] layers.26.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 240/ 543] layers.26.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 241/ 543] layers.26.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 242/ 543] layers.26.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 243/ 543] layers.26.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 244/ 543] layers.26.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 245/ 543] layers.26.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 246/ 543] layers.26.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 247/ 543] layers.27.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.096 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 248/ 543] layers.27.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.096 0.112 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 249/ 543] layers.27.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 250/ 543] layers.27.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 251/ 543] layers.27.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 252/ 543] layers.27.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 253/ 543] layers.27.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 254/ 543] layers.27.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 255/ 543] layers.27.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 256/ 543] layers.28.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.097 0.077 0.056 0.039 0.025 0.021
[ 257/ 543] layers.28.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 258/ 543] layers.28.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 259/ 543] layers.28.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 260/ 543] layers.28.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 261/ 543] layers.28.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 262/ 543] layers.28.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 263/ 543] layers.28.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 264/ 543] layers.28.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 265/ 543] layers.29.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.112 0.117 0.112 0.096 0.077 0.056 0.039 0.025 0.021
[ 266/ 543] layers.29.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.112 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 267/ 543] layers.29.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 268/ 543] layers.29.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 269/ 543] layers.29.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 270/ 543] layers.29.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 271/ 543] layers.29.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 272/ 543] layers.29.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 273/ 543] layers.29.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 274/ 543] layers.30.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.111 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 275/ 543] layers.30.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.111 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 276/ 543] layers.30.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 277/ 543] layers.30.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 278/ 543] layers.30.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 279/ 543] layers.30.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 280/ 543] layers.30.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 281/ 543] layers.30.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 282/ 543] layers.30.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 283/ 543] layers.31.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 284/ 543] layers.31.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 285/ 543] layers.31.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 286/ 543] layers.31.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 287/ 543] layers.31.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 288/ 543] layers.31.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 289/ 543] layers.31.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 290/ 543] layers.31.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 291/ 543] layers.31.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 292/ 543] layers.32.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.096 0.077 0.056 0.039 0.025 0.021
[ 293/ 543] layers.32.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 294/ 543] layers.32.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 295/ 543] layers.32.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 296/ 543] layers.32.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 297/ 543] layers.32.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 298/ 543] layers.32.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 299/ 543] layers.32.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 300/ 543] layers.32.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 301/ 543] layers.33.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.112 0.096 0.077 0.056 0.039 0.025 0.021
[ 302/ 543] layers.33.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.096 0.112 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 303/ 543] layers.33.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 304/ 543] layers.33.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 305/ 543] layers.33.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 306/ 543] layers.33.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 307/ 543] layers.33.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 308/ 543] layers.33.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 309/ 543] layers.33.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 310/ 543] layers.34.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.096 0.112 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 311/ 543] layers.34.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 312/ 543] layers.34.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 313/ 543] layers.34.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 314/ 543] layers.34.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 315/ 543] layers.34.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 316/ 543] layers.34.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 317/ 543] layers.34.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 318/ 543] layers.34.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 319/ 543] layers.35.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.097 0.077 0.057 0.039 0.025 0.021
[ 320/ 543] layers.35.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.076 0.096 0.112 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 321/ 543] layers.35.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 322/ 543] layers.35.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 323/ 543] layers.35.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 324/ 543] layers.35.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 325/ 543] layers.35.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 326/ 543] layers.35.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 327/ 543] layers.35.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 328/ 543] layers.36.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.097 0.111 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 329/ 543] layers.36.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 330/ 543] layers.36.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 331/ 543] layers.36.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 332/ 543] layers.36.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 333/ 543] layers.36.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 334/ 543] layers.36.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 335/ 543] layers.36.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 336/ 543] layers.36.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 337/ 543] layers.37.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.096 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 338/ 543] layers.37.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 339/ 543] layers.37.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 340/ 543] layers.37.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 341/ 543] layers.37.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 342/ 543] layers.37.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 343/ 543] layers.37.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 344/ 543] layers.37.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 345/ 543] layers.37.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 346/ 543] layers.38.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.076 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 347/ 543] layers.38.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 348/ 543] layers.38.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 349/ 543] layers.38.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.026 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 350/ 543] layers.38.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 351/ 543] layers.38.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 352/ 543] layers.38.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 353/ 543] layers.38.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 354/ 543] layers.38.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 355/ 543] layers.39.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 356/ 543] layers.39.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 357/ 543] layers.39.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 358/ 543] layers.39.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 359/ 543] layers.39.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 360/ 543] layers.39.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 361/ 543] layers.39.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 362/ 543] layers.39.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 363/ 543] layers.39.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 364/ 543] layers.40.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.097 0.112 0.117 0.112 0.096 0.077 0.056 0.039 0.025 0.021
[ 365/ 543] layers.40.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 366/ 543] layers.40.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 367/ 543] layers.40.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 368/ 543] layers.40.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 369/ 543] layers.40.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 370/ 543] layers.40.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 371/ 543] layers.40.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 372/ 543] layers.40.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 373/ 543] layers.41.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.096 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 374/ 543] layers.41.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 375/ 543] layers.41.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 376/ 543] layers.41.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 377/ 543] layers.41.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 378/ 543] layers.41.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 379/ 543] layers.41.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 380/ 543] layers.41.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 381/ 543] layers.41.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 382/ 543] layers.42.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 383/ 543] layers.42.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.038 0.025 0.021
[ 384/ 543] layers.42.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 385/ 543] layers.42.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 386/ 543] layers.42.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 387/ 543] layers.42.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 388/ 543] layers.42.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 389/ 543] layers.42.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 390/ 543] layers.42.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 391/ 543] layers.43.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 392/ 543] layers.43.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 393/ 543] layers.43.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 394/ 543] layers.43.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 395/ 543] layers.43.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 396/ 543] layers.43.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 397/ 543] layers.43.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 398/ 543] layers.43.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 399/ 543] layers.43.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 400/ 543] layers.44.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.076 0.096 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 401/ 543] layers.44.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.038 0.025 0.020
[ 402/ 543] layers.44.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 403/ 543] layers.44.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 404/ 543] layers.44.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 405/ 543] layers.44.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 406/ 543] layers.44.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 407/ 543] layers.44.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 408/ 543] layers.44.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 409/ 543] layers.45.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 410/ 543] layers.45.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.076 0.056 0.038 0.025 0.020
[ 411/ 543] layers.45.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 412/ 543] layers.45.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 413/ 543] layers.45.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 414/ 543] layers.45.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 415/ 543] layers.45.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 416/ 543] layers.45.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 417/ 543] layers.45.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 418/ 543] layers.46.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.076 0.096 0.112 0.118 0.112 0.097 0.076 0.056 0.039 0.025 0.021
[ 419/ 543] layers.46.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 420/ 543] layers.46.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 421/ 543] layers.46.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 422/ 543] layers.46.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 423/ 543] layers.46.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 424/ 543] layers.46.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 425/ 543] layers.46.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 426/ 543] layers.46.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 427/ 543] layers.47.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.076 0.097 0.112 0.118 0.112 0.097 0.076 0.056 0.039 0.025 0.021
[ 428/ 543] layers.47.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.112 0.118 0.112 0.097 0.076 0.056 0.038 0.025 0.020
[ 429/ 543] layers.47.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 430/ 543] layers.47.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 431/ 543] layers.47.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 432/ 543] layers.47.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 433/ 543] layers.47.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 434/ 543] layers.47.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 435/ 543] layers.47.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 436/ 543] layers.48.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 437/ 543] layers.48.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.038 0.025 0.021
[ 438/ 543] layers.48.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 439/ 543] layers.48.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 440/ 543] layers.48.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 441/ 543] layers.48.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 442/ 543] layers.48.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 443/ 543] layers.48.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 444/ 543] layers.48.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 445/ 543] layers.49.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.096 0.077 0.056 0.039 0.025 0.021
[ 446/ 543] layers.49.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.076 0.056 0.038 0.025 0.021
[ 447/ 543] layers.49.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 448/ 543] layers.49.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 449/ 543] layers.49.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 450/ 543] layers.49.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 451/ 543] layers.49.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 452/ 543] layers.49.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 453/ 543] layers.49.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 454/ 543] layers.50.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 455/ 543] layers.50.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 456/ 543] layers.50.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 457/ 543] layers.50.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 458/ 543] layers.50.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 459/ 543] layers.50.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 460/ 543] layers.50.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 461/ 543] layers.50.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 462/ 543] layers.50.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 463/ 543] layers.51.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.076 0.056 0.039 0.025 0.021
[ 464/ 543] layers.51.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 465/ 543] layers.51.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 466/ 543] layers.51.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 467/ 543] layers.51.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 468/ 543] layers.51.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 469/ 543] layers.51.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 470/ 543] layers.51.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 471/ 543] layers.51.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 472/ 543] layers.52.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.076 0.097 0.112 0.118 0.112 0.097 0.076 0.056 0.038 0.025 0.021
[ 473/ 543] layers.52.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.112 0.118 0.112 0.097 0.076 0.056 0.038 0.025 0.021
[ 474/ 543] layers.52.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 475/ 543] layers.52.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 476/ 543] layers.52.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 477/ 543] layers.52.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 478/ 543] layers.52.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 479/ 543] layers.52.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 480/ 543] layers.52.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 481/ 543] layers.53.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.112 0.118 0.112 0.097 0.076 0.056 0.038 0.025 0.021
[ 482/ 543] layers.53.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.112 0.119 0.112 0.097 0.076 0.056 0.038 0.025 0.020
[ 483/ 543] layers.53.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 484/ 543] layers.53.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 485/ 543] layers.53.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 486/ 543] layers.53.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 487/ 543] layers.53.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 488/ 543] layers.53.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 489/ 543] layers.53.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 490/ 543] layers.54.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 491/ 543] layers.54.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.112 0.118 0.112 0.097 0.076 0.056 0.038 0.025 0.020
[ 492/ 543] layers.54.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 493/ 543] layers.54.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 494/ 543] layers.54.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 495/ 543] layers.54.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 496/ 543] layers.54.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 497/ 543] layers.54.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 498/ 543] layers.54.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 499/ 543] layers.55.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.076 0.056 0.039 0.025 0.021
[ 500/ 543] layers.55.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.076 0.056 0.038 0.025 0.020
[ 501/ 543] layers.55.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.056 0.039 0.025 0.021
[ 502/ 543] layers.55.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 503/ 543] layers.55.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 504/ 543] layers.55.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 505/ 543] layers.55.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 506/ 543] layers.55.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 507/ 543] layers.55.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 508/ 543] layers.56.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 509/ 543] layers.56.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.077 0.097 0.113 0.119 0.112 0.097 0.076 0.056 0.038 0.025 0.020
[ 510/ 543] layers.56.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 511/ 543] layers.56.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 512/ 543] layers.56.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 513/ 543] layers.56.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 514/ 543] layers.56.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 515/ 543] layers.56.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 516/ 543] layers.56.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 517/ 543] layers.57.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.112 0.118 0.112 0.097 0.076 0.056 0.038 0.025 0.021
[ 518/ 543] layers.57.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.113 0.119 0.113 0.097 0.076 0.056 0.038 0.025 0.020
[ 519/ 543] layers.57.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.056 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 520/ 543] layers.57.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.026 0.021
[ 521/ 543] layers.57.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 522/ 543] layers.57.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 523/ 543] layers.57.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 524/ 543] layers.57.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 525/ 543] layers.57.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 526/ 543] layers.58.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.113 0.120 0.113 0.097 0.076 0.055 0.038 0.024 0.020
[ 527/ 543] layers.58.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.024 0.038 0.055 0.076 0.097 0.114 0.121 0.114 0.097 0.076 0.055 0.038 0.024 0.020
[ 528/ 543] layers.58.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.112 0.118 0.112 0.096 0.077 0.056 0.039 0.025 0.021
[ 529/ 543] layers.58.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 530/ 543] layers.58.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 531/ 543] layers.58.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 532/ 543] layers.58.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.077 0.097 0.112 0.118 0.112 0.097 0.077 0.056 0.038 0.025 0.021
[ 533/ 543] layers.58.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 534/ 543] layers.58.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
[ 535/ 543] layers.59.attention.wq.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.055 0.076 0.097 0.113 0.121 0.113 0.097 0.076 0.055 0.038 0.024 0.020
[ 536/ 543] layers.59.attention.wk.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.038 0.056 0.076 0.097 0.113 0.119 0.113 0.097 0.076 0.056 0.038 0.025 0.020
[ 537/ 543] layers.59.attention.wv.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.097 0.112 0.118 0.112 0.096 0.077 0.056 0.039 0.025 0.021
[ 538/ 543] layers.59.attention.wo.weight - 6656 x 6656, type = f16, quantizing .. size = 84.50 MB -> 23.77 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.026 0.021
[ 539/ 543] layers.59.attention_norm.weight - 6656, type = f32, size = 0.025 MB
[ 540/ 543] layers.59.feed_forward.w1.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.097 0.112 0.117 0.111 0.097 0.077 0.056 0.039 0.025 0.021
[ 541/ 543] layers.59.feed_forward.w2.weight - 17920 x 6656, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.015 0.024 0.037 0.055 0.076 0.097 0.114 0.121 0.114 0.097 0.076 0.055 0.037 0.024 0.020
[ 542/ 543] layers.59.feed_forward.w3.weight - 6656 x 17920, type = f16, quantizing .. size = 227.50 MB -> 63.98 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.056 0.039 0.025 0.021
[ 543/ 543] layers.59.ffn_norm.weight - 6656, type = f32, size = 0.025 MB
llama_model_quantize_internal: model size = 62501.44 MB
llama_model_quantize_internal: quant size = 17580.74 MB
llama_model_quantize_internal: hist: 0.036 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.117 0.111 0.096 0.077 0.057 0.039 0.025 0.021
main: quantize time = 132816.29 ms
main: total time = 132816.29 ms
测试
执行:
./main -m zh-models/33B/ggml-model-q4_0.bin --color -f prompts/alpaca.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.1
测试:
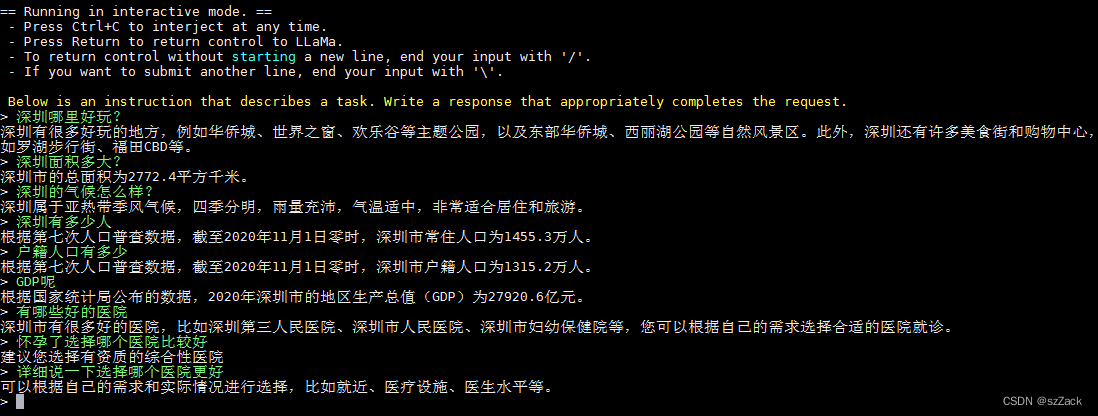
参考
1.【AI实战】从零开始搭建中文 LLaMA-33B 语言模型 Chinese-LLaMA-Alpaca-33B
2.https://github.com/ymcui/Chinese-LLaMA-Alpaca
3.【AI实战】llama.cpp 量化部署 llama-33B