常用内建模块
datetime
Python处理日期和时间的标准库
datetime表示的时间需要时区信息才能确定一个特定的时间,否则只能视为本地时间。如果要存储
datetime,最佳方法是将其转换为timestamp再存储,因为timestamp的值与时区完全无关。
获取当前日期和时间
我们先看如何获取当前日期和时间:
>>> from datetime import datetime
>>> now = datetime.now() # 获取当前datetime
>>> print(now)
2015-05-18 16:28:07.198690
>>> print(type(now))
<class 'datetime.datetime'>
获取指定日期和时间
要指定某个日期和时间,我们直接用参数构造一个datetime:
>>> from datetime import datetime
>>> dt = datetime(2015, 4, 19, 12, 20) # 用指定日期时间创建datetime
>>> print(dt)
2015-04-19 12:20:00
datetime与timestamp互换
在计算机中,时间实际上是用数字表示的。我们把1970年1月1日 00:00:00 UTC+00:00时区的时刻称为epoch time,记为0(1970年以前的时间timestamp为负数),当前时间就是相对于epoch time的秒数,称为timestamp。
timestamp = 0 = 1970-1-1 00:00:00 UTC+0:00
# 对应的北京时间是
timestamp = 0 = 1970-1-1 08:00:00 UTC+8:00
可见timestamp的值与时区毫无关系,因为timestamp一旦确定,其UTC时间就确定了,转换到任意时区的时间也是完全确定的,这就是为什么计算机存储的当前时间是以timestamp表示的,因为全球各地的计算机在任意时刻的timestamp都是完全相同的(假定时间已校准)。
datetime转换为timestamp
把一个datetime类型转换为timestamp只需要简单调用timestamp()方法:
>>> from datetime import datetime
>>> dt = datetime(2015, 4, 19, 12, 20) # 用指定日期时间创建datetime
>>> dt.timestamp() # 把datetime转换为timestamp
1429417200.0
注意Python的timestamp是一个浮点数,整数位表示秒。
timestamp转换为datetime
使用datetime提供的==fromtimestamp()方法==:
>>> from datetime import datetime
>>> t = 1429417200.0
>>> print(datetime.fromtimestamp(t))
2015-04-19 12:20:00
注意到timestamp是一个浮点数,它没有时区的概念,而datetime是有时区的。上述转换是在timestamp和本地时间做转换。
本地时间是指当前操作系统设定的时区。例如北京时区是东8区,则本地时间:
2015-04-19 12:20:00实际上就是UTC+8:00时区的时间:
2015-04-19 12:20:00 UTC+8:00
timestamp也可以直接被转换到UTC标准时区的时间:
>>> from datetime import datetime
>>> t = 1429417200.0
>>> print(datetime.fromtimestamp(t)) # 本地时间
2015-04-19 12:20:00
>>> print(datetime.utcfromtimestamp(t)) # UTC时间
2015-04-19 04:20:00
str与datetime互换
str转换为datetime
很多时候,用户输入的日期和时间是字符串,要处理日期和时间,首先必须把str转换为datetime。转换方法是通过==datetime.strptime()==实现,需要一个日期和时间的格式化字符串:
>>> from datetime import datetime
>>> cday = datetime.strptime('2015-6-1 18:19:59', '%Y-%m-%d %H:%M:%S')
>>> print(cday)
2015-06-01 18:19:59
字符串'%Y-%m-%d %H:%M:%S'规定了日期和时间部分的格式。详细的说明请参考Python文档。
注意转换后的datetime是没有时区信息的。
没有时区信息:说白了就是没有UTC
datetime转换为str
如果已经有了datetime对象,要把它格式化为字符串显示给用户,就需要转换为str,转换方法是通过strftime()实现的,同样需要一个日期和时间的格式化字符串:[str from time ]
>>> from datetime import datetime
>>> now = datetime.now()
>>> print(now.strftime('%a, %b %d %H:%M'))
Mon, May 05 16:28
datetime加减
对日期和时间进行加减实际上就是把datetime往后或往前计算,得到新的datetime。加减可以直接用+和-运算符,不过需要导入timedelta这个类:
>>> from datetime import datetime, timedelta
>>> now = datetime.now()
>>> now
datetime.datetime(2015, 5, 18, 16, 57, 3, 540997)
>>> now + timedelta(hours=10)
datetime.datetime(2015, 5, 19, 2, 57, 3, 540997)
>>> now - timedelta(days=1)
datetime.datetime(2015, 5, 17, 16, 57, 3, 540997)
>>> now + timedelta(days=2, hours=12)
datetime.datetime(2015, 5, 21, 4, 57, 3, 540997)
可见,使用timedelta你可以很容易地算出前几天和后几天的时刻。
时区问题
本地时间转换为UTC时间
本地时间是指系统设定时区的时间,例如北京时间是UTC+8:00时区的时间,而UTC时间指UTC+0:00时区的时间。
==一个datetime类型有一个时区属性tzinfo,但是默认为None,所以无法区分这个datetime到底是哪个时区,==除非强行给datetime设置一个时区:
timezone:设置时区对象、返回当地时区(未启动夏令时)距离格林威治的偏移秒数
>>> from datetime import datetime, timedelta, timezone
>>> tz_utc_8 = timezone(timedelta(hours=8)) # 创建时区UTC+8:00
>>> now = datetime.now()
>>> now
datetime.datetime(2015, 5, 18, 17, 2, 10, 871012)
>>> dt = now.replace(tzinfo=tz_utc_8) # 强制设置为UTC+8:00
>>> dt
datetime.datetime(2015, 5, 18, 17, 2, 10, 871012, tzinfo=datetime.timezone(datetime.timedelta(0, 28800)))
如果系统时区恰好是UTC+8:00,那么上述代码就是正确的,否则,不能强制设置为UTC+8:00时区。
时区转换
我们可以先通过utcnow()拿到当前的UTC时间,再转换为任意时区的时间:
utcnow():获取世界标准时间
astimezone() :修改时区 会对应的调整日期和时间【datetine转换成新时区的值】,执行此方法的datetime必须声明过timezone,否则会报错
replace(tzinfo=时区) 只是修改时区属性,不会修改日期和时间【datetime从一个无时区的状态变成有时区的状态】
timezone:设置时区对象、返回当地时区(未启动夏令时)距离格林威治的偏移秒数

# 拿到UTC时间,并强制设置时区为UTC+0:00:
>>> utc_dt = datetime.utcnow().replace(tzinfo=timezone.utc)
>>> print(utc_dt)
2015-05-18 09:05:12.377316+00:00
# astimezone()将转换时区为北京时间:
>>> bj_dt = utc_dt.astimezone(timezone(timedelta(hours=8)))
>>> print(bj_dt)
2015-05-18 17:05:12.377316+08:00
# astimezone()将转换时区为东京时间:
>>> tokyo_dt = utc_dt.astimezone(timezone(timedelta(hours=9)))
>>> print(tokyo_dt)
2015-05-18 18:05:12.377316+09:00
# astimezone()将bj_dt转换时区为东京时间:
>>> tokyo_dt2 = bj_dt.astimezone(timezone(timedelta(hours=9)))
>>> print(tokyo_dt2)
2015-05-18 18:05:12.377316+09:00
时区转换的关键在于,拿到一个datetime时,要获知其正确的时区,然后强制设置时区,作为基准时间。
利用带时区的datetime,通过astimezone()方法,可以转换到任意时区。
注:不是必须从UTC+0:00时区转换到其他时区,任何带时区的
datetime都可以正确转换,例如上述bj_dt到tokyo_dt的转换。
collections
collections是Python内建的一个集合模块,提供了许多有用的集合类。
namedtuple
namedtuple是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素。# namedtuple('名称', [属性list]): Circle = namedtuple('Circle', ['x', 'y', 'r'])
>>> from collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(1, 2)
>>> p.x
1
>>> p.y
2
这样一来,我们用namedtuple可以很方便地定义一种数据类型,它具备tuple的不变性,又可以根据属性来引用,使用十分方便。【eg:一个点的二维坐标】
可以验证创建的**Point对象是tuple的一种子类**:
>>> isinstance(p, Point)
True
>>> isinstance(p, tuple)
True
deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了==高效实现插入和删除操作的双向列表==,适合用于队列和栈:
>>> from collections import deque
>>> q = deque(['a', 'b', 'c'])
>>> q.append('x')
>>> q.appendleft('y')
>>> q
deque(['y', 'a', 'b', 'c', 'x'])
deque除了实现list的append()和pop()外,还支持**appendleft()和popleft(),**这样就可以非常高效地往头部添加或删除元素。
defaultdict
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
>>> from collections import defaultdict
>>> dd = defaultdict(lambda: 'N/A')
>>> dd['key1'] = 'abc'
>>> dd['key1'] # key1存在
'abc'
>>> dd['key2'] # key2不存在,返回默认值
'N/A'
注意默认值是调用函数返回的,而函数在创建defaultdict对象时传入。[lambda: ‘N/A’]
除了在Key不存在时返回默认值,defaultdict的其他行为跟dict是完全一样的。
OrderedDict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要==保持Key的顺序,可以用OrderedDict:==
>>> from collections import OrderedDict
>>> d = dict([('a', 1), ('b', 2), ('c', 3)])
>>> d # dict的Key是无序的
{
'a': 1, 'c': 3, 'b': 2}
>>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
>>> od # OrderedDict的Key是有序的
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
OrderedDict可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key:
ChainMap
ChainMap可以把一组dict串起来并组成一个逻辑上的dict。ChainMap本身也是一个dict,但是查找的时候,会按照顺序在内部的dict依次查找。
[可以用
ChainMap实现参数的优先级查找]什么时候使用
ChainMap最合适?举个例子:应用程序往往都需要传入参数,参数可以通过命令行传入,可以通过环境变量传入,还可以有默认参数。我们可以用ChainMap实现参数的优先级查找,即先查命令行参数,如果没有传入,再查环境变量,如果没有,就使用默认参数。
from collections import ChainMap
import os, argparse
# 构造缺省参数:
defaults = {
'color': 'red',
'user': 'guest'
}
# 构造命令行参数:
parser = argparse.ArgumentParser()
parser.add_argument('-u', '--user')
parser.add_argument('-c', '--color')
namespace = parser.parse_args()
command_line_args = {
k: v for k, v in vars(namespace).items() if v }
# 组合成ChainMap:
combined = ChainMap(command_line_args, os.environ, defaults)
# 打印参数:
print('color=%s' % combined['color'])
print('user=%s' % combined['user'])
Counter
Counter是一个简单的**计数器**,例如,统计字符出现的个数:
>>> from collections import Counter
>>> c = Counter()
>>> for ch in 'programming':
... c[ch] = c[ch] + 1
...
>>> c
Counter({
'g': 2, 'm': 2, 'r': 2, 'a': 1, 'i': 1, 'o': 1, 'n': 1, 'p': 1})
>>> c.update('hello') # 也可以一次性update
>>> c
Counter({
'r': 2, 'o': 2, 'g': 2, 'm': 2, 'l': 2, 'p': 1, 'a': 1, 'i': 1, 'n': 1, 'h': 1, 'e': 1})
Counter实际上也是dict的一个子类,上面的结果可以看出每个字符出现的次数。
base64
https://blog.csdn.net/qq_40967086/article/details/126633267?spm=1001.2014.3001.5501
Base64是一种任意二进制到文本字符串的编码方法,常用于在URL、Cookie、网页中传输少量二进制数据。
Base64编码会把3字节的二进制数据编码为4字节的文本数据,长度增加33%,好处是编码后的文本数据可以在邮件正文、网页等直接显示。
struct
概述
1)bytes、str
bytes是Python3.x新加的数据类型(在Python2.x中被合并在str)中
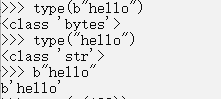
bytes是byte的序列,而str是unicode的序列
bytes通过decode()方法转换为str类型;str通过encode()方法转换为bytes类型
在互联网上是通过二进制进行传输,所以就需要将str通过encode()编码成bytes进行传输,而在接收中通过decode()解码成我们需要的编码进行处理数据这样不管对方是什么编码而本地是我们使用的编码这样就不会乱码
2)bytes()
bytes()是Python3的一个内置函数
>>> b =bytes()
>>> type(b)
<class 'bytes'>
>>> print(b)
b''
>>> len(b)
0
准确地讲,Python没有专门处理字节的数据类型。但由于==b'str'可以表示字节==,所以,字节数组=二进制str。而在C语言中,我们可以很方便地用struct、union来处理字节,以及字节和int,float的转换。
Python提供了一个==struct模块来解决bytes和其他二进制数据类型的转换==
两个函数:pack()、unpack()
struct模块最重要的两个函数就是pack()、unpack()方法
| 函数 | return | explain |
|---|---|---|
| pack(fmt,v1,v2…) | string | 按照给定的格式(fmt),把数据转换成字符串(字节流),并将该字符串返回. |
| pack_into(fmt,buffer,offset,v1,v2…) | None | 按照给定的格式(fmt),将数据转换成字符串(字节流),并将字节流写入以offset开始的buffer中.(buffer为可写的缓冲区,可用array模块) |
| unpack(fmt,v1,v2……) | tuple | 按照给定的格式(fmt)解析字节流,并返回解析结果 |
| pack_from(fmt,buffer,offset) | tuple | 按照给定的格式(fmt)解析以offset开始的缓冲区,并返回解析结果 |
| calcsize(fmt) | size of fmt | 计算给定的格式(fmt)占用多少字节的内存,注意对齐方式 |
打包函数:pack(fmt, v1, v2, v3, ...)
按照fmt(格式化字符串)的格式来打包参数v1,v2,…。
通俗的说就是:
首先将不同类型的数据对象放在一个“组”中(比如元组(1,‘good’,1.22)),
然后打包(“组”转换为字节流对象),最后再解包(将字节流对象转换为“组”)。
import struct
import binascii
values = (1, b'good',1.22) # 查看格式化对照表可知,字符串必须为字节流类型。
s = struct.Struct('I4sf')
packed_data = s.pack(*values)
unpacked_data = s.unpack(packed_data)
print('Original values:', values) # Original values: (1, b'good', 1.22)
print('Format string :', s.format) # Format string : I4sf
print('Uses :', s.size, 'bytes') # Uses : 12 bytes
print('Packed Value :', binascii.hexlify(packed_data)) # Packed Value : b'01000000676f6f64f6289c3f'
print('Unpacked Type :', type(unpacked_data), ' Value:', unpacked_data) # Unpacked Type : <class 'tuple'> Value: (1, b'good', 1.2200000286102295)
解包函数:unpack(fmt, buffer)
v1, v2, …表示要转换的python值
其中,
fmt是格式字符(format的谐音),struct模块支持的格式化字符如下表
- 每个格式前可以有一个数字,表示这个类型的个数,如s格式表示一定长度的字符串,4s表示长度为4的字符串==;4i表示四个int;==
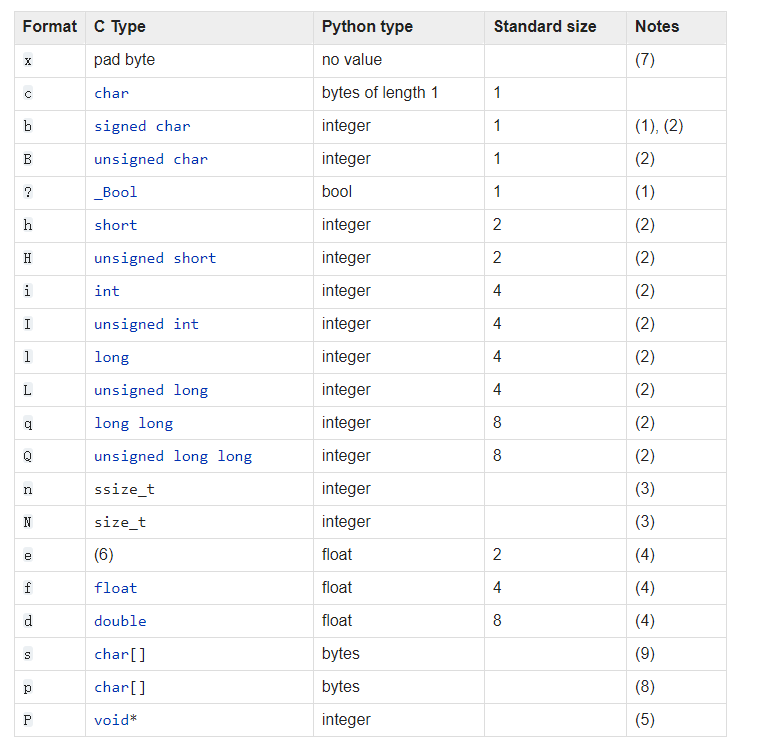
举例如下
# 将两个整数转换为字符串(字节流)
>>> import struct
>>> a=20
>>> b=400
>>> str = struct.pack('ii', a, b) # 转换成字节流,虽然还是字符串,但是可以在网络上传输
# ii 表示两个int8 。可以看到长度为8个字节,正好是两个int型数据的长度
>>> print(str)
b'\x14\x00\x00\x00\x90\x01\x00\x00' # #其中十六进制的\x14\x00\x00\x00--反过来数--> 0x00000014, 0x00001009分别表示20和400
>>>
python中 \u 、\x 、0x
\u : python3中,字符在内存里的表示是unicode。所以看到\u代表目前是unicode编码。
例如;‘中文’ == ‘\u4e2d\u6587’。一般unicode中一个中文字符对应两个字节,8位。这里为了人眼看,计算机一般显示16进制。
0x : 表示十六进制的int型变量。
例如0x61 表示int型的97
\x : 表示十六进制的字符型变量。
例如’\x61’ 表示str型,ASCII码为十进制97的字符,即’a’。换句话说 ‘\x61’ == chr(97)
>>> a1,a2=struct.unpack('ii',str) # “ii”以四个字节(int)为分界,把8个字节的str分成了两个int型的整数
>>> print 'a1',a1
a1 20
>>> print 'a2=',a2
a2= 400
①pack
import struct
list=[]
for n in range(5):
data = struct.pack('i',n)
list.append(data)
print(list,type(list))
# [b'\x00\x00\x00\x00', b'\x01\x00\x00\x00', b'\x02\x00\x00\x00', b'\x03\x00\x00\x00', b'\x04\x00\x00\x00'] <class 'list'>
②unpack
import struct
s =struct.pack('ii',20,400)
print(s)
# b'\x14\x00\x00\x00\x90\x01\x00\x00'
v1,v2 = struct.unpack('ii', s)
print(v1,v2)
# 20 400
③struct.calcsize():用来计算特定格式的输出的大小,是几个字节
>>> struct.calcsize('hh4s') # short*2+bytes*4=2*2+1*4=8
8
>>> struct.calcsize('ii') # int*2=4*2=8
8
import struct
file1 = open('binary.dat','wb')
for n in range(5):
data = struct.pack('i',n)
file1.write(data)
file1.close()
file = open('binary.dat','rb')
size = struct.calcsize('i') # 前后的转换字符格式要相同,否则转换得不到原来的数据
br= file.read(size)
while br:
value = struct.unpack('i',br)
value = value[0]
print(value,end=' ')
br = file.read(size)
file.close()
# 0 1 2 3 4
教程上的内容
struct的pack函数把任意数据类型变成bytes:
>>> import struct
>>> struct.pack('>I', 10240099)
b'\x00\x9c@c'
pack的第一个参数是处理指令,'>I'的意思是:
>表示字节顺序是big-endian,也就是网络序,I表示4字节无符号整数。
后面的参数个数要和处理指令一致。
对齐方式
为了同c中的结构体交换数据,还要考虑c或c++编译器使用了字节对齐,通常是以4个字节为单位的32位系统,故而struct根据本地机器字节顺序转换.可以用格式中的第一个字符来改变对齐方式.定义如下
| Character | Byte order | Size | Alignment |
|---|---|---|---|
| @(默认) | 本机 | 本机 | 本机,凑够4字节 |
| = | 本机 | 标准 | none,按原字节数 |
| < | 小端 | 标准 | none,按原字节数 |
| > | 大端 | 标准 | none,按原字节数 |
| ! | network(大端) | 标准 | none,按原字节数 |
大小端
大端 小端 较低的有效字节存放在较高的存储器地址中,较高的有效字节存放在较低的存储器地址 较高的有效字节存放在较高的存储器地址中,较低的有效字节存放在较低的存储器地址
- 大小端主要区别在于字节存放的顺序;
- 采用大端符合人类的正常思维逻辑;
- 采用小端利于计算机处理;
unpack把bytes变成相应的数据类型:
>>> struct.unpack('>IH', b'\xf0\xf0\xf0\xf0\x80\x80')
(4042322160, 32896)
根据>IH的说明,后面的bytes依次变为I:4字节无符号整数和H:2字节无符号整数
int*1+int*1=4*1+2*1=6I 四个字节,拿走\xf0\xf0\xf0\xf0 H二个字节 拿走\x80\x80
hashlib
摘要算法简介
类似于数据加密
摘要算法在很多地方都有广泛的应用。要注意摘要算法不是加密算法,不能用于加密(因为无法通过摘要反推明文),只能用于防篡改,但是它的单向计算特性决定了可以在不存储明文口令的情况下验证用户口令。
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
举个例子,你写了一篇文章,内容是一个字符串'how to use python hashlib - by Michael',并附上这篇文章的摘要是'2d73d4f15c0db7f5ecb321b6a65e5d6d'。如果有人篡改了你的文章,并发表为'how to use python hashlib - by Bob',你可以一下子指出Bob篡改了你的文章,因为根据'how to use python hashlib - by Bob'计算出的摘要不同于原始文章的摘要。
可见,摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
①MD5
import hashlib
md5 = hashlib.md5()
md5.update('how to use md5 in python hashlib?'.encode('utf-8'))
print(md5.hexdigest())
# d26a53750bc40b38b65a520292f69306
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
import hashlib
md5 = hashlib.md5()
md5.update('how to use md5 in '.encode('utf-8'))
md5.update('python hashlib?'.encode('utf-8'))
print(md5.hexdigest())
②SHA1
import hashlib
sha1 = hashlib.sha1()
sha1.update('how to use sha1 in '.encode('utf-8'))
sha1.update('python hashlib?'.encode('utf-8'))
print(sha1.hexdigest())
有没有可能两个不同的数据通过某个摘要算法得到了相同的摘要?完全有可能,因为任何摘要算法都是把无限多的数据集合映射到一个有限的集合中。这种情况称为碰撞,比如Bob试图根据你的摘要反推出一篇文章
'how to learn hashlib in python - by Bob',并且这篇文章的摘要恰好和你的文章完全一致,这种情况也并非不可能出现,但是非常非常困难。
摘要算法应用
eg:以摘要的形式存储用户的口令,登录的时候匹配口令的摘要是否一致即可
任何允许用户登录的网站都会存储用户登录的用户名和口令。如何存储用户名和口令呢?方法是存到数据库表中:
| name | password |
|---|---|
| michael | 123456 |
| bob | abc999 |
| alice | alice2008 |
存储用户口令的摘要
| username | password |
|---|---|
| michael | e10adc3949ba59abbe56e057f20f883e |
| bob | 878ef96e86145580c38c87f0410ad153 |
| alice | 99b1c2188db85afee403b1536010c2c9 |
当用户登录时,首先计算用户输入的明文口令的MD5,然后和数据库存储的MD5对比,如果一致,说明口令输入正确,如果不一致,口令肯定错误。
采用MD5存储口令不一定安全
由于常用口令的MD5值很容易被计算出来,只需要对比数据库的MD5,黑客就获得了使用常用口令的用户账号。
对此,我们想到了==“加盐”==的措施。
对原始简单口令加一个复杂字符串来实现
def calc_md5(password): return get_md5(password + 'the-Salt')
经过Salt处理的MD5口令,只要Salt不被黑客知道,即使用户输入简单口令,也很难通过MD5反推明文口令。
还有一点就是如果用户名字不允许修改的话,我们就可以将用户名也纳入“加盐”操作中来。
hmac
hashlib的更标准版,适用于所有哈希算法。采用Hmac替代我们自己的salt算法,可以使程序算法更标准化,也更安全。【message+salt---->message+key】
通过哈希算法,我们可以验证一段数据是否有效,方法就是对比该数据的哈希值,例如,判断用户口令是否正确,我们用保存在数据库中的password_md5对比计算md5(password)的结果,如果一致,用户输入的口令就是正确的。
为了防止黑客通过彩虹表根据哈希值反推原始口令,在计算哈希的时候,不能仅针对原始输入计算,需要增加一个salt来使得相同的输入也能得到不同的哈希,这样,大大增加了黑客破解的难度。
如果salt是我们自己随机生成的,通常我们计算MD5时采用md5(message + salt)。但实际上,把salt看做一个“口令”,加salt的哈希就是:计算一段message的哈希时,根据不同口令计算出不同的哈希。要验证哈希值,必须同时提供正确的口令。
这实际上就是Hmac算法:Keyed-Hashing for Message Authentication。它通过一个标准算法,在计算哈希的过程中,把key混入计算过程中。
>>> import hmac
>>> message = b'Hello, world!'
>>> key = b'secret'
>>> h = hmac.new(key, message, digestmod='MD5')
>>> # 如果消息很长,可以多次调用h.update(msg)
>>> h.hexdigest()
'fa4ee7d173f2d97ee79022d1a7355bcf'
可见使用hmac和普通hash算法非常类似。hmac输出的长度和原始哈希算法的长度一致。需要注意传入的key和message都是bytes类型,str类型需要首先编码为bytes。
itertools
Python的内建模块itertools提供了非常有用的用于操作迭代对象的函数。
itertools模块提供的全部是处理迭代功能的函数,它们的返回值不是list,而是Iterator,只有用for循环迭代的时候才真正计算。
“无限”迭代器
itertools提供的几个“无限”迭代器
# 因为count()会创建一个无限的迭代器,所以上述代码会打印出自然数序列,根本停不下来,只能按Ctrl+C退出
>>> import itertools
>>> natuals = itertools.count(1)
>>> for n in natuals:
... print(n)
...
1
2
3
...
# cycle()会把传入的一个序列无限重复下去
>>> import itertools
>>> cs = itertools.cycle('ABC') # 注意字符串也是序列的一种
>>> for c in cs:
... print(c)
...
'A'
'B'
'C'
'A'
'B'
'C'
...
# repeat()负责把一个元素无限重复下去,不过如果提供第二个参数就可以限定重复次数
>>> ns = itertools.repeat('A', 3)
>>> for n in ns:
... print(n)
...
A
A
A
无限序列只有在for迭代时才会无限地迭代下去,如果只是创建了一个迭代对象,它不会事先把无限个元素生成出来,事实上也不可能在内存中创建无限多个元素。
无限序列虽然可以无限迭代下去,但是通常我们会通过takewhile()等函数根据条件判断来截取出一个有限的序列:
>>> natuals = itertools.count(1)
>>> ns = itertools.takewhile(lambda x: x <= 10, natuals)
>>> list(ns)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
takewhile()
takewhile(predicate, iterable)
predicate:内置函数或用户定义的函数。它甚至可以是lambda函数;
iterable:在大多数情况下,迭代器iterable是列表或字符串
该功能属于“terminating iterators”类别。输出不能直接使用,而必须转换为另一种可迭代的形式。通常,它们会转换为列表
下面给出了使用简单if-else对该功能的一般实现。
def takewhile(predicate, iterable):
for i in iterable:
if predicate(i):
return(i)
else:
break
功能takewhile()以谓词和可迭代作为参数。迭代iterable以检查其每个元素。如果指定谓词上的元素的值为true,则将其返回。否则,循环终止。
迭代器操作函数
itertools提供的几个迭代器操作函数更加有用:
chain()
chain()可以把一组迭代对象串联起来,形成一个更大的迭代器:
>>> for c in itertools.chain('ABC', 'XYZ'):
... print(c)
# 迭代效果:'A' 'B' 'C' 'X' 'Y' 'Z'
groupby()
groupby()把迭代器中相邻的重复元素挑出来放在一起:
>>> for key, group in itertools.groupby('AAABBBCCAAA'):
... print(key, list(group))
...
A ['A', 'A', 'A']
B ['B', 'B', 'B']
C ['C', 'C']
A ['A', 'A', 'A']
实际上挑选规则是通过函数完成的,只要作用于函数的两个元素返回的值相等,这两个元素就被认为是在一组的,而函数返回值作为组的key。
如果我们要忽略大小写分组,就可以让元素
'A'和'a'都返回相同的key:>>> for key, group in itertools.groupby('AaaBBbcCAAa', lambda c: c.upper()): ... print(key, list(group)) ... A ['A', 'a', 'a'] B ['B', 'B', 'b'] C ['c', 'C'] A ['A', 'A', 'a']
contextlib
在Python中,读写文件这样的资源要特别注意,必须在使用完毕后正确关闭它们。正确关闭文件资源有如下方法
# try...finally
try:
f = open('/path/to/file', 'r')
f.read()
finally:
if f:
f.close()
# 写try...finally非常繁琐
with open('/path/to/file', 'r') as f:
f.read()
# 实现上下文管理是通过__enter__和__exit__这两个方法实现的
class Query(object):
def __init__(self, name):
self.name = name
def __enter__(self):
print('Begin')
return self
def __exit__(self, exc_type, exc_value, traceback):
if exc_type:
print('Error')
else:
print('End')
def query(self):
print('Query info about %s...' % self.name)
# 编写__enter__和__exit__仍然很繁琐
# Python的标准库contextlib提供了更简单的写法
from contextlib import contextmanager
class Query(object):
def __init__(self, name):
self.name = name
def query(self):
print('Query info about %s...' % self.name)
@contextmanager
def create_query(name):
print('Begin')
q = Query(name)
yield q
print('End')
@contextmanager
是一个装饰器decorator
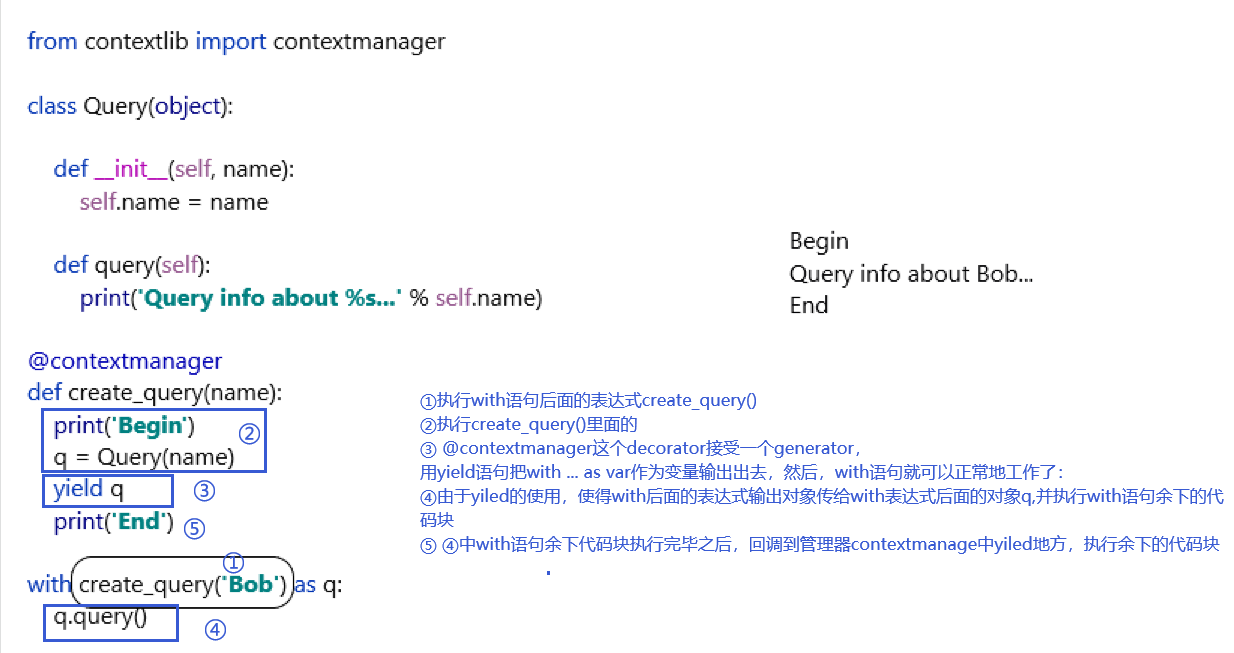
同理,如果我们希望在某段代码执行前后自动执行特定代码,也可以用@contextmanager实现。
@closing
如果一个对象没有实现上下文,我们就不能把它用于with语句。这个时候,可以用closing()来把该对象变为上下文对象。例如,用with语句使用urlopen():
from contextlib import closing
from urllib.request import urlopen
with closing(urlopen('https://www.python.org')) as page:
for line in page:
print(line)
closing也是一个经过@contextmanager装饰的generator,这个generator编写起来其实非常简单:
@contextmanager
def closing(thing):
try:
yield thing
finally:
thing.close()
它的作用就是把任意对象变为上下文对象,并支持with语句。
urllib
urllib提供了一系列用于操作URL的功能。
urllib提供的功能就是利用程序去执行各种HTTP请求。如果要模拟浏览器完成特定功能,需要把请求伪装成浏览器。伪装的方法是先监控浏览器发出的请求,再根据浏览器的请求头来伪装,==
User-Agent==头就是用来标识浏览器的。
Get
urllib的==request模块==可以非常方便地抓取URL内容,也就是发送一个GET请求到指定的页面,然后返回HTTP的响应:
例如,对豆瓣的一个URLhttps://api.douban.com/v2/book/2129650进行抓取,并返回响应:
from urllib import request
with request.urlopen('https://api.douban.com/v2/book/2129650') as f:
data = f.read()
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', data.decode('utf-8'))
可以看到HTTP响应的头和JSON数据:
Status: 200 OK
Server: nginx
Date: Tue, 26 May 2015 10:02:27 GMT
Content-Type: application/json; charset=utf-8
Content-Length: 2049
Connection: close
Expires: Sun, 1 Jan 2006 01:00:00 GMT
Pragma: no-cache
Cache-Control: must-revalidate, no-cache, private
X-DAE-Node: pidl1
Data: {"rating":{"max":10,"numRaters":16,"average":"7.4","min":0},"subtitle":"","author":["廖雪峰编著"],"pubdate":"2007-6",...}
模拟浏览器发送GET请求
原文链接:https://blog.csdn.net/weixin_42157432/article/details/104441027
如果我们要想模拟浏览器发送GET请求,就需要使用Request对象,通过往Request对象添加HTTP头,我们就可以把请求伪装成浏览器。
一个很简单的道理,当我们使用网络爬虫去网站爬取数据的时候,经常会遇到有些网站设置了反爬虫机制。那么这个时候我们就需要使用这种方式,通过把我们的操作伪装成我们正常的使用浏览器访问网站的形式去"骗过"网站,从而获取网站数据。
1 如何伪装成浏览器?
要伪装成浏览器,必须往Request对象中以dict方式添加头部信息,其中’User-Agent’尤为重要。
在写爬虫时,如果**不加header参数,当前网站就会把你当成爬虫**,然后禁止你访问,加入headers可以有效的避免。1.1如何添加头部信息?
- 在定义
Request对象时,便添加头部信息- 使用
request.add_header()往Request对象添加头部信息(request.get_header()可获取头部信息)1.2User-Agent如何获得?
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
标准格式为: 浏览器标识 (操作系统标识; 加密等级标识; 浏览器语言) 渲染引擎标识 版本信息步骤:打开浏览器——F12——network——选择任一项——headers——查找User-Agent
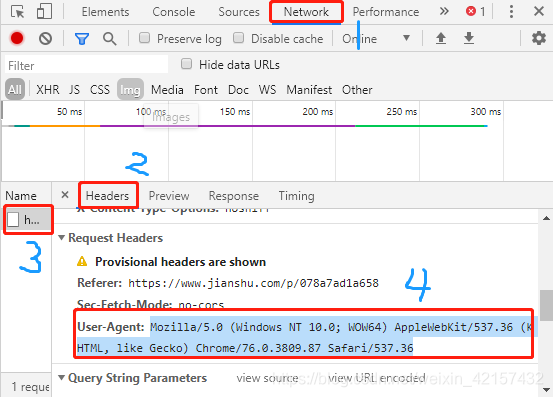
例如,模拟iPhone 6去请求豆瓣首页:
from urllib import request
req = request.Request('http://www.douban.com/')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
with request.urlopen(req) as f:
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', f.read().decode('utf-8'))
这样豆瓣会返回适合iPhone的移动版网页:
...
<meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0">
<meta name="format-detection" content="telephone=no">
<link rel="apple-touch-icon" sizes="57x57" href="http://img4.douban.com/pics/cardkit/launcher/57.png" />
...
URL带参数的请求
```python
from urllib import request
url='https://www.douban.com/search?q='
key=request.quote('罪恶都市') #由于字段含有中文,需要编码
url_all=url+key
header={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36'}
req=request.Request(url_all,headers=header)
with request.urlopen(req) as f: #爬去网页
data=f.read()
with open('./dbsearch.html','wb') as fw:#写入文件
fw.write(data)
Post
如果要以POST发送一个请求,只需要把参数data以bytes形式传入。
数据在内外存和在网络上的传播都是通过bytes来的,为了防止多种不同语言在一起而导致乱码。
我们模拟一个微博登录,先读取登录的邮箱和口令,然后按照weibo.cn的登录页的格式以username=xxx&password=xxx的编码传入:
from urllib import request, parse
print('Login to weibo.cn...')
email = input('Email or PhonNumber: ') # 用户输入登录的邮箱名
passwd = input('Password: ') # 用户输入登录的密码
login_data = parse.urlencode([ # 登录数据,用dict类型储存,parse.urlencode将dict转为url参数
('username', email),
('password', passwd),
('entry', 'mweibo'),
('client_id', ''),
('savestate', '1'),
('ec', ''),
('pagerefer', 'https://passport.weibo.cn/signin/welcome?entry=mweibo&r=http%3A%2F%2Fm.weibo.cn%2F')
])
req = request.Request('https://passport.weibo.cn/sso/login')
req.add_header('Origin', 'https://passport.weibo.cn')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
req.add_header('Referer', 'https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=http%3A%2F%2Fm.weibo.cn%2F')
with request.urlopen(req, data=login_data.encode('utf-8')) as f:
print('Status:', f.status, f.reason) # 返回页面执行的状态
for k, v in f.getheaders(): # 得到HTTP相应的头和JSON数据
print('%s: %s' % (k, v))
print('Data:', f.read().decode('utf-8')) # 得到页面信息
如果登录成功,我们获得的响应如下:
Status: 200 OK
Server: nginx/1.2.0
...
Set-Cookie: SSOLoginState=1432620126; path=/; domain=weibo.cn
...
Data: {"retcode":20000000,"msg":"","data":{...,"uid":"1658384301"}}
如果登录失败,我们获得的响应如下:
...
Data: {"retcode":50011015,"msg":"\u7528\u6237\u540d\u6216\u5bc6\u7801\u9519\u8bef","data":{"username":"[email protected]","errline":536}}
Handler
如果还需要更复杂的控制,比如通过一个Proxy去访问网站,我们需要利用ProxyHandler来处理,示例代码如下:
proxy_handler = urllib.request.ProxyHandler({
'http': 'http://www.example.com:3128/'})
proxy_auth_handler = urllib.request.ProxyBasicAuthHandler()
proxy_auth_handler.add_password('realm', 'host', 'username', 'password')
opener = urllib.request.build_opener(proxy_handler, proxy_auth_handler)
with opener.open('http://www.example.com/login.html') as f:
pass
补充
urlopen
>>> from inspect import signature
>>> signature(request.urlopen)
<Signature (url, data=None, timeout=<object object at 0x000002066EEE7D80>, *, cafile=None, capath=None, cadefault=False, context=None)>
常用参数
url:目标资源在网络中的位置。【URL字符串,Request对象】
data:data用来指明发往服务器请求中的额外的参数信息(如:在线翻译,在线答题等提交的内容),data默认是None,此时以GET方式发送请求;当用户给出data参数的时候,改为POST方式发送请求。
timeout:访问超时时间
直接用urllib.request模块的urlopen()获取页面,page的数据格式为bytes类型,需要decode()解码,转换成str类型。
urllib的其他常用方法
urlopen返回对象提供方法:
| 方法 | 作用 |
|---|---|
| info() | 返回网页的当前环境有关信息 |
| getcode() | 返回网页状态码,若为200则正确,若为其他则错误 |
| geturl() | 返回网页的url |
| urllib.request.quote() | 对网址进行编码 |
| urllib.request.unquote() | 对网址进行解码 |
>>>from urllib import request
>>>response=request.urlopen('http://www.baidu.com')
>>> response.info()
<http.client.HTTPMessage object at 0x000002067168FF48>
>>> response.getcode()
200
>>> response.geturl()
'https://www.baidu.com'
>>> request.quote('https://www.baidu.com')
'https%3A//www.baidu.com'
>>> request.unquote('https%3A//www.baidu.com')
'https://www.baidu.com'
Request对象
>>> signature(request.Request)
<Signature (url, data=None, headers={
}, origin_req_host=None, unverifiable=False, method=None)>
Request实例,除了必须要有 url参数之外,还可以设置另外两个参数:
data:如果是GET请求,data(默认空),如果是POST请求,需要加上data参数,伴随 url 提交的数据。headers(默认空):是一个字典,包含了需要发送的HTTP报头的键值对。【爬虫操作时需设置】
XML
XML虽然比JSON复杂,在Web中应用也不如以前多了,不过仍有很多地方在用,所以,有必要了解如何操作XML。
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
解析XML时,注意找出自己感兴趣的节点,响应事件时,把节点数据保存起来。解析完毕后,就可以处理数据。
DOM vs SAX
操作XML有两种方法:DOM和SAX。
| 优点 | 缺点 | |
|---|---|---|
| DOM | 可以任意遍历树的节点 | DOM会把整个XML读入内存,解析为树,因此占用内存大,解析慢 |
| SAX | SAX是流模式,边读边解析,占用内存小,解析快 | 我们需要自己处理事件 |
正常情况下,优先考虑SAX,因为DOM实在太占内存。
解析XML
在Python中使用SAX解析XML非常简洁,通常我们关心的事件是==start_element,end_element和char_data,准备好这3个函数==,然后就可以解析xml了。
举个例子,当SAX解析器读到一个节点时:
<a href="/">python</a>会产生3个事件【重要思想】:
- start_element事件,在读取
<a href="/">时;- char_data事件,在读取
python时;- end_element事件,在读取
</a>时。
from xml.parsers.expat import ParserCreate
class DefaultSaxHandler(object):
def start_element(self, name, attrs):
print('sax:start_element: %s, attrs: %s' % (name, str(attrs)))
def end_element(self, name):
print('sax:end_element: %s' % name)
def char_data(self, text):
print('sax:char_data: %s' % text)
xml = r'''<?xml version="1.0"?>
<ol>
<li><a href="/python">Python</a></li>
<li><a href="/ruby">Ruby</a></li>
</ol>
'''
需要注意的是==读取一大段字符串时,CharacterDataHandler可能被多次调用,==所以需要自己保存起来,在EndElementHandler里面再合并。
①打印start_element事件
handler = DefaultSaxHandler()
parser = ParserCreate()
parser.StartElementHandler = handler.start_element
parser.Parse(xml)
sax:start_element: ol, attrs: {
}
sax:start_element: li, attrs: {
}
sax:start_element: a, attrs: {
'href': '/python'}
sax:start_element: li, attrs: {
}
sax:start_element: a, attrs: {
'href': '/ruby'}
②打印end_element事件
handler = DefaultSaxHandler()
parser = ParserCreate()
parser.EndElementHandler = handler.end_element
parser.Parse(xml)
sax:end_element: a
sax:end_element: li
sax:end_element: a
sax:end_element: li
sax:end_element: ol
③打印char_data事件
handler = DefaultSaxHandler()
parser = ParserCreate()
parser.CharacterDataHandler = handler.char_data
parser.Parse(xml)
sax:char_data:
sax:char_data:
sax:char_data: Python
sax:char_data:
sax:char_data:
sax:char_data: Ruby
sax:char_data:
④组合打印全部的事件
handler = DefaultSaxHandler()
parser = ParserCreate()
parser.StartElementHandler = handler.start_element
parser.EndElementHandler = handler.end_element
parser.CharacterDataHandler = handler.char_data
parser.Parse(xml)
sax:start_element: ol, attrs: {
}
sax:char_data:
sax:char_data:
sax:start_element: li, attrs: {
}
sax:start_element: a, attrs: {
'href': '/python'}
sax:char_data: Python
sax:end_element: a
sax:end_element: li
sax:char_data:
sax:char_data:
sax:start_element: li, attrs: {
}
sax:start_element: a, attrs: {
'href': '/ruby'}
sax:char_data: Ruby
sax:end_element: a
sax:end_element: li
sax:char_data:
sax:end_element: ol

生成XML
99%的情况下需要生成的XML结构都是非常简单的,因此,最简单也是最有效的生成XML的方法是拼接字符串:
L = []
L.append(r'<?xml version="1.0"?>')
L.append(r'<root>')
L.append(encode('some & data'))
L.append(r'</root>')
return ''.join(L)
如果要生成复杂的XML呢?建议你不要用XML,改成JSON。
HTMLParser
如果我们要编写一个搜索引擎,第一步是用爬虫把目标网站的页面抓下来==【爬取】;第二步就是解析该HTML页面,看看里面的内容到底是新闻、图片还是视频【解析】==。
假设第一步已经完成了,第二步应该如何解析HTML呢?
HTML本质上是XML的子集,但是HTML的语法没有XML那么严格,所以不能用标准的DOM或SAX来解析HTML。
好在Python提供了HTMLParser来非常方便地解析HTML,只需简单几行代码:
举例:找一个网页,例如https://www.python.org/events/python-events/,用浏览器查看源码并复制,然后尝试解析一下HTML,输出Python官网发布的会议时间、名称和地点。
设置标志位
__parsedata很重要
# -*-coding:UTF-8-*-
from html.parser import HTMLParser
from urllib.request import Request,urlopen
import re
def get_data(url):
'''
GET请求到指定的页面
:return: HTTP响应
'''
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36'
}
req = Request(url, headers=headers)
with urlopen(req, timeout=25) as f:
data = f.read()
print(f'Status: {
f.status} {
f.reason}')
print()
return data.decode("utf-8") # 利用request爬到的数据都是bytes格式的
class MyHTMLParser(HTMLParser):
def __init__(self):
super().__init__()
self.__parsedata='' # 【设置一个空的标志位】
self.info = []
def handle_starttag(self, tag, attrs):
if ('class', 'event-title') in attrs:
self.__parsedata = 'name' # 通过属性判断如果该标签是我们要找的标签,设置标志位
if tag == 'time':
self.__parsedata = 'time'
if ('class', 'say-no-more') in attrs:
self.__parsedata = 'year'
if ('class', 'event-location') in attrs:
self.__parsedata = 'location'
def handle_endtag(self, tag):
self.__parsedata = ''# 在HTML 标签结束时,把标志位清空
def handle_data(self, data):
if self.__parsedata == 'name':
# 通过标志位判断,输出打印标签内容
self.info.append(f'会议名称:{
data}')
if self.__parsedata == 'time':
self.info.append(f'会议时间:{
data}')
if self.__parsedata == 'year':
if re.match(r'\s\d{4}', data): # 因为后面还有两组 say-no-more 后面的data却不是年份信息,所以用正则检测一下
self.info.append(f'会议年份:{
data.strip()}')
if self.__parsedata == 'location':
self.info.append(f'会议地点:{
data} \n')
def main():
parser = MyHTMLParser()
URL = 'https://www.python.org/events/python-events/'
data = get_data(URL)
parser.feed(data)
for s in parser.info:
print(s)
if __name__ == '__main__':
main()
Status: 200 OK
会议名称:PyConFr 2023
会议时间:16 Feb. – 19 Feb.
会议年份:2023
会议地点:Bordeaux, France
会议名称:PyCon Namibia 2023
会议时间:21 Feb. – 23 Feb.
会议年份:2023
会议地点:Windhoek, Namibia
会议名称:PyCon PH 2023
会议时间:25 Feb. – 26 Feb.
会议年份:2023
会议地点:Manila, Philippines
会议名称:GeoPython 2023
会议时间:06 March – 08 March
会议年份:2023
会议地点:Basel, Switzerland
会议名称:PyCon DE & PyData Berlin 2023
会议时间:17 April – 19 April
会议年份:2023
会议地点:Berlin, Germany
会议名称:PyCon US 2023
会议时间:19 April – 27 April
会议年份:2023
会议地点:Salt Lake City, Utah, USA
会议名称:XtremePython 2022
会议时间:27 Dec.
会议年份:2022
会议地点:Online
会议名称:PyCon Bolivia 2022
会议时间:09 Dec. – 10 Dec.
会议年份:2022
会议地点:Cochabamba, Bolivia