【通览一百个大模型】CodeX(OpenAI)
作者:王嘉宁,本文章内容为原创,仓库链接:https://github.com/wjn1996/LLMs-NLP-Algo
订阅专栏【大模型&NLP&算法】可获得博主多年积累的全部NLP、大模型和算法干货资料大礼包,近200篇论文,300份博主亲自撰写的markdown笔记,近100个大模型资料卡,助力NLP科研、学习和求职。
CodeX大模型基本信息资料卡
| 序号 | 大模型名称 | 归属 | 推出时间 | 规模 | 预训练语料 | 评测基准 | 模型与训练方法 | 开源 | 论文 | 模型地址 | 相关资料 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | CodeX CodeX-C CodeX-D 产品:Copilot |
OpenAI | 2021-07 | <12B | 1、来自GitHub约为159GB的代码数据,用于Code Fine-Tuning 2、监督微调:编程比赛网站和持续合入的代码仓分别构造了10000、40000个编程问题,并进行了过滤。 |
构建HumanEval、APPS评测数据集。不采用BLEU等指标,而是定义pass@k来表示大模型在HumanEval测试集上功能正确性 | 在GPT3的基础上,先在大规模的代码语料上进行预训练,得到CodeX。其次在监督数据集上进行微调,CodeX-C:根据函数名、docstrings生成函数体;CodeX-D:根据函数名和函数体生成docstrings。 |
未开源 | 论文 | 未开源 | 查看 资料 |
CodeX
欢迎订阅阅读【大模型&NLP&算法】。
- 作者:王嘉宁
- 本文章内容为转载或整理;
- 仓库链接:https://github.com/wjn1996/LLMs-NLP-Algo
Evaluating Large Language Models Trained on Code
论文:https://arxiv.org/pdf/2107.03374.pdf
相关资料:https://zhuanlan.zhihu.com/p/414210861
转载
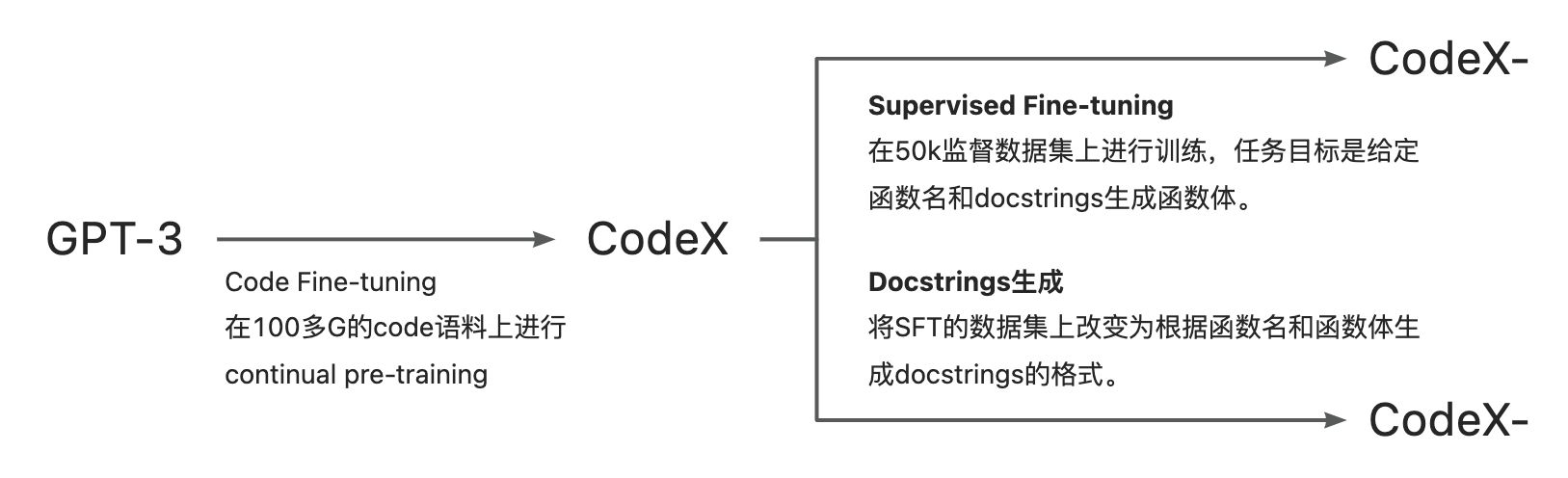
正如OpenAI 的联合创始人兼首席技术官 Greg Brockman介绍的那样,“Codex是GPT-3的后代”,Codex基于GPT-3使用code数据进行了Fine-Tuning,模型参数从 12M 到 12B不等。
CodeX训练过程:
一. 数据集
1. Code Fine-Tuning数据集
首先是用来做Fine-Tuning的code数据集,根据论文介绍,Codex在2020年5月从Github 的 54,000,000 个公开代码仓上收集了数据,包括 179 GB 文件大小在 1 MB 以下的独一无二的python文件,在经过过滤后,最终的数据集大小为159GB。
这部分数据相当于是用于continual pre-training的
2. 评测数据集
在之前的代码生成工作中,主要采用的是基于匹配的方法,即基于模型输出和参考代码的精确或模糊匹配,如BLEU,也有一些工作基于匹配的方法做了一定的改进来捕捉代码的语义正确性,如CodeBLEU ,但论文中认为基于匹配的方法,不能评价编程功能的正确性,因为从功能上看,参考代码所对应的解空间是十分巨大和复杂的。因此,论文中参考了之前代码迁移工作 和“伪代码到代码”转换工作 中的做法,将生成代码的功能正确性作为评测指标。
具体来说,在论文中,关注从docstrings生成python函数的任务,并通过unit tests的方法来评测生成代码的正确性。
评测指标采用的pass@k,在之前的工作 中,该指标表示被解决问题的比例,其中每个问题在预测时采样k个样本,k个样本中任何一个通过unit tests,则认为该问题被解决,但论文中指出,用这种方式计算 pass@k 方差比较大,论文对该评测指标进行了改进。与之前工作不同的是,对每个问题,在预测时产生 n≥k 个样本,统计能够通过unit tests的正确样本的数量 c ≤ n, 并根据下式计算 pass@k 的无偏估计:

pass@K的估计:
pass@K的评测脚本:


2.1 HumanEval
为了评价函数功能的正确性,论文中构建了一个包括164个人工受写的编程问题的数据集,叫做HumanEval,其中每个编程问题包括函数头、docstrings、函数体和几个 unit tests。HumanEval中的编程问题可以用来评估语言理解能力、推理能力、算法能力和简单的数学能力,该数据集已经开源 。

2.2 APPS
APPS 是 Hendrycks 等人提出的用来衡量语言模型编程能力的数据集,APPS一共包含10000个编程问题,每个编程问题都有若干个 unit tests,其中5000个编程问题作为训练集,5000个编程问题作为测试集,训练集中的每个问题还包括若干个正确答案。
3. Supervised Fine-Tuning数据集
从Github上收集的Code Fine-Tuning数据集除了独立函数外,还包含类实现、配置文件、脚本,甚至还包含存储数据的文件,这些代码和从 docstring 生成函数的相关性不大,因此,论文认为这种数据分布的不匹配会影响模型在HumanEval数据集上的效果。
为了进行额外的有监督的 fine-tuning,论文构建了一个用于正确生成独立函数的数据集,数据集的来源是编程比赛网站和持续合入的代码仓,论文通过前者构造了10000个编程问题,通过后者构造了40000个编程问题,并进行了过滤。
4. Docstrings 生成数据集
论文中还尝试了从代码生成docstrings,由于数据集中通常的数据格式为 <函数头><函数体>,因此根据函数头和 docstrings 生成函数体相对比较容易,而根据函数头和函数体生成 docstrings 可能没那么容易。通过将之前数据集中的数据格式变为<函数头><函数体>, 构造了一个根据代码生成 docstrings 的数据集。
二. 模型
Codex 的模型结构和 GPT 完全一样,论文中尝试了从头训练和基于 GPT-3 的参数 fine-tuning,结果发现基于 GPT-3 的参数 fine-tuning 并没有取得效果上的提升,原因可能是 Code Fine-tuning 数据集太大,但基于 GPT-3 的参数 fine-tuing 可以收敛的更快,因此,论文中都采用的是这种训练策略。
为了尽可能的利用 GPT 的文本表示,Codex 使用了和 GPT-3 一样的分词器,但因为代码中词的分布和自然语言中词的分布有很大区别,GPT-3 的分词器在表示代码时可能不是非常有效,在 python 语言中,分词器编码低效的一个主要原因是空格的编码,因此,论文中在GPT-3 的分词器中加入了额外的一些 token 来表示不同长度的空格,这样在表示代码时可以少使用 30% 的 token。
推理时,使用核采样 不断采样 Codex 生成的 token,直到碰见以下字符中的任何一个。
“\nclass”,“\ndef”,“\n#”,“\nif” , ‘\nprint’
2.1 Codex
论文中训练得到的第一个模型就是Codex,即在不同参数量的 GPT-3 上做 Code-Funing 得到的模型,模型参数量有12M、25M、42M、85M、300M、679M,2.5B 和 12B。
2.2 Codex-S
为了提升 Codex 在 HumanEval 数据集上的效果,论文将 Codex 在 Supervised Fine-Tuning 数据集上进行了fine-tuning,得到的模型称为 Codex-S。为了和HumanEval保持一致,将数据都处理成了图2所示例子的形式,当一个batch内提示(函数名和 docstrings )长度不同时,采用了 left-pad 的方法进行了处理,在训练时,mask了所有提示中的token上的loss。
2.3 Codex-D
为了训练 Codex 生成 docstrings 的能力,论文将 Codex 在 Docstrings 生成数据集上进行了fine-tuning,得到的模型称为Codex-D,在训练时,mask了所有代码(函数名+函数体)中token上的loss。
博客记录着学习的脚步,分享着最新的技术,非常感谢您的阅读,本博客将不断进行更新,希望能够给您在技术上带来帮助。
【大模型&NLP&算法】专栏
近200篇论文,300份博主亲自撰写的markdown笔记。订阅本专栏【大模型&NLP&算法】专栏,或前往https://github.com/wjn1996/LLMs-NLP-Algo即可获得全部如下资料:
- 机器学习&深度学习基础与进阶干货(笔记、PPT、代码)
- NLP基础与进阶干货(笔记、PPT、代码)
- 大模型全套体系——预训练语言模型基础、知识预训练、大模型一览、大模型训练与优化、大模型调优、类ChatGPT的复现与应用等;
- 大厂算法刷题;
