本篇文章是博主在人工智能等领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对人工智能等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在学习摘录和笔记专栏:
学习摘录和笔记(12)---《人工智能领域的10大算法》
人工智能领域的10大算法
原文/论文出处:
题目:《人工智能领域的10大算法》
作者:AI智胜未来
时间:2022-09-26
来源:AI智胜未来
1 线性回归
线性回归(Linear Regression)可能是最流行的机器学习算法。线性回归就是要找一条直线,并且让这条直线尽可能地拟合散点图中的数据点。
2 逻辑回归
逻辑回归(Logistic regression)与线性回归类似,但逻辑回归的结果只能有两个的值。如果说线性回归是在预测一个开放的数值,那逻辑回归更像是做一道是或不是的判断题。逻辑函数中Y值的范围从 0 到 1,是一个概率值。逻辑函数通常呈S 型,曲线把图表分成两块区域,因此适合用于分类任务。
3决策树
如果说线性和逻辑回归都是把任务在一个回合内结束,那么决策树(Decision Trees)就是一个多步走的动作,它同样用于回归和分类任务中,不过场景通常更复杂且具体。
4 朴素贝叶斯
朴素贝叶斯(Naive Bayes)是基于贝叶斯定理,即两个条件关系之间。它测量每个类的概率,每个类的条件概率给出 x 的值。这个算法用于分类问题,得到一个二进制“是 / 非”的结果。
5 支持向量机
支持向量机(Support Vector Machine,SVM)是一种用于分类问题的监督算法。支持向量机试图在数据点之间绘制两条线,它们之间的边距最大。为此,我们将数据项绘制为 n 维空间中的点,其中,n 是输入特征的数量。在此基础上,支持向量机找到一个最优边界,称为超平面(Hyperplane),它通过类标签将可能的输出进行最佳分离。
6 K- 最近邻算法
K- 最近邻算法(K-Nearest Neighbors,KNN)非常简单。KNN 通过在整个训练集中搜索 K 个最相似的实例,即 K 个邻居,并为所有这些 K 个实例分配一个公共输出变量,来对对象进行分类。
K 的选择很关键:较小的值可能会得到大量的噪声和不准确的结果,而较大的值是不可行的。它最常用于分类,但也适用于回归问题。
7 K- 均值
K- 均值(K-means)是通过对数据集进行分类来聚类的。例如,这个算法可用于根据购买历史将用户分组。它在数据集中找到 K 个聚类。K- 均值用于无监督学习,因此,我们只需使用训练数据 X,以及我们想要识别的聚类数量 K。
8 随机森林
随机森林(Random Forest)是一种非常流行的集成机器学习算法。这个算法的基本思想是,许多人的意见要比个人的意见更准确。在随机森林中,使用决策树集成(参见决策树)。
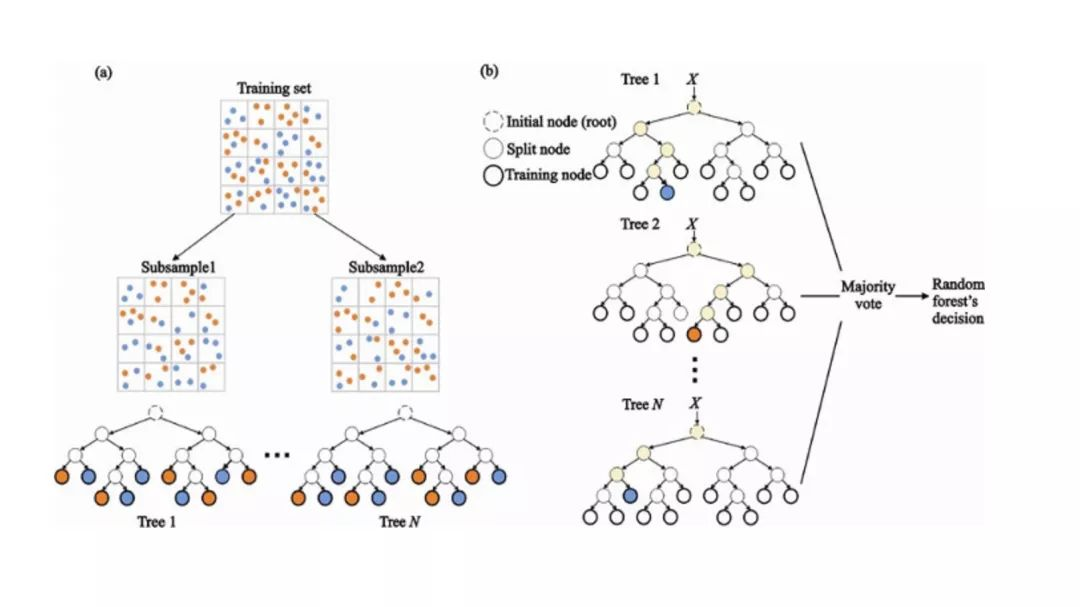
(a)在训练过程中,每个决策树都是基于训练集的引导样本来构建的。
(b)在分类过程中,输入实例的决定是根据多数投票做出的。
随机森林拥有广泛的应用前景,从市场营销到医疗保健保险,既可以用来做市场营销模拟的建模,统计客户来源、保留及流失,也可以用来预测疾病的风险和病患者的易感性。
9 降维
降维(Dimensionality reduction)试图在不丢失最重要信息的情况下,通过将特定的特征组合成更高层次的特征来解决这个问题。主成分分析(Principal Component Analysis,PCA)是最流行的降维技术。
10 人工神经网络
人工神经网络(Artificial Neural Networks,ANN)可以处理大型复杂的机器学习任务。神经网络本质上是一组带有权值的边和节点组成的相互连接的层,称为神经元。
文章若有不当和不正确之处,还望理解与指出。由于部分文字、图片等来源于互联网,无法核实真实出处,如涉及相关争议,请联系博主删除。如有错误、疑问和侵权,欢迎评论留言联系作者,或者关注VX公众号:Rain21321,联系作者。