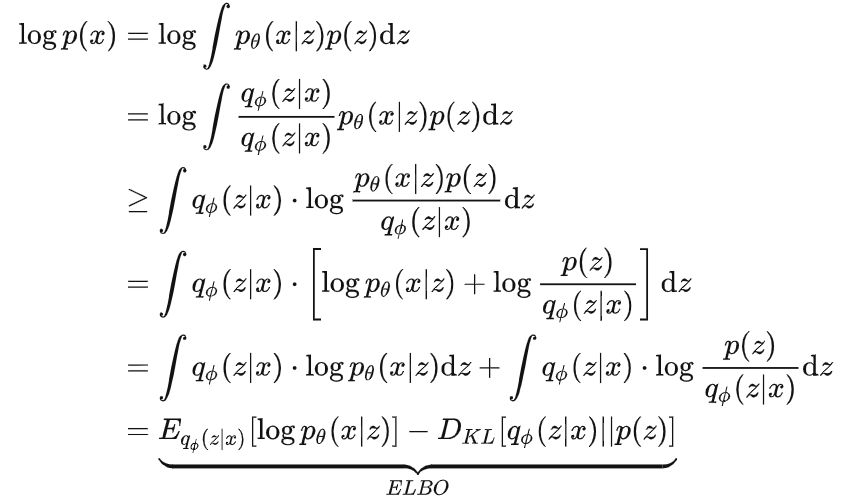1 简介
本文根据openAI 2021年2月的《Zero-Shot Text-to-Image Generation》翻译总结的。原文详见https://arxiv.org/pdf/2102.12092v1.pdf。
DALL·E : 论文中没看到这个名字,可能是后起的吧。
DALL·E有120亿参数,基于自回归transformer,在2.5亿 图片-文本对上训练的。在人为评价中,90%的时间认为该模型好于以前的模型。
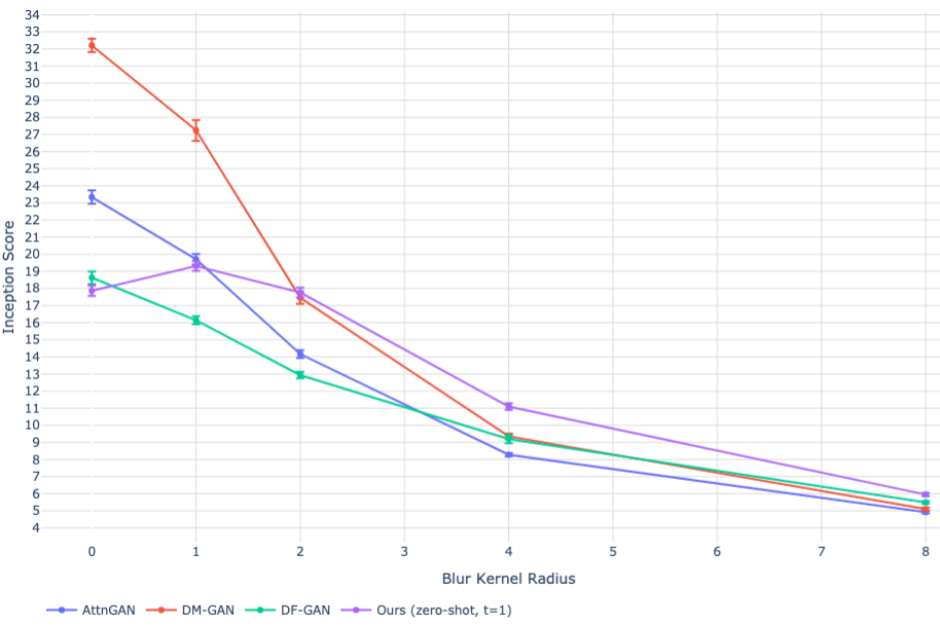
DALL-E还没有使用扩散模型,使用的dVAE(discrete variational autoencoder离散变分自动编码器)。文中主要和GAN相关模型进行比较,如AttnGAN、DM-GAN、DF-GAM.
2 方法
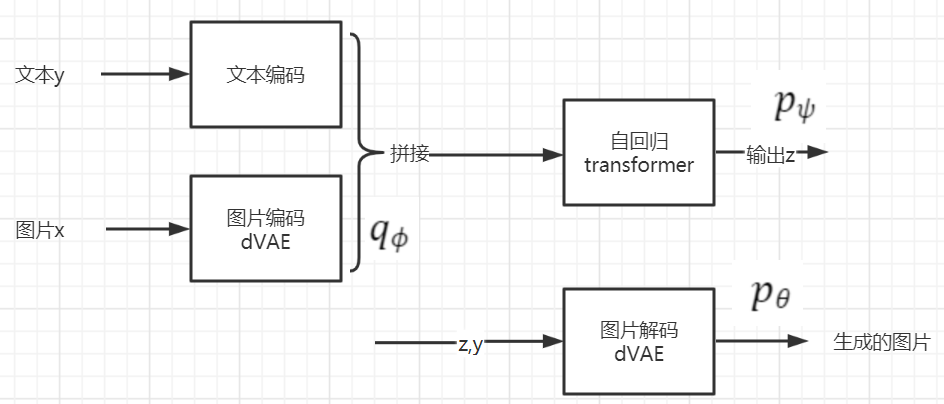
采用两步法。
第一步:训练一个dVAE(discrete variational autoencoder离散变分自动编码器),其将256*256的RGB图片转换为32*32的图片token。图片token的词汇量大小是8192个。第一阶段同时训练dVAE编码器和dVAE解码器。图片token示例如下:

第二步:将文本token(采用256 Byte Pair Encoding (BPE) 编码)和图片token(32*32=1024)进行拼接,然后训练一个自回归transformer来建模文本和图片token的联合分布。
训练目标:采用Evidence Lower BOund (ELBO,推导详见文章最下面)。如下:

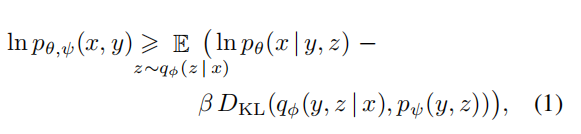
其中,x指图片,y指文本,z指对编码的图片(用于生成图片)。

ELBO的一般取1,但我们发现使用更大的值更好。
3 步骤一:学习视觉

4 步骤二:学习先验

给定一个文本-图片对,我们采用BPE编码小写的文本描述,最多256个token,词汇量大小为16384。使用dVAE编码器,编码图片为32*32=1024 token,词汇量大小为8192。然后将文本和图片token拼接,作为一个单独的数据流,输入到自回归模型。
transformer采用只有编码的部分。其中每一个图片token对所有文本token进行注意力关注。共有3中自注意力在模型中使用。文本对文本的注意力时标准的causal mask;图片对图片的注意力使用行、列,或者卷积关注mask。
5 样本生成
我们使用一个对比(contrastive)模型对从transformer绘制的样本进行重排序。给定一个文本描述和候选图片,对比模型对图片是否很好的匹配文本进行打分。我们绘制了N=512个样本进行重排序。下图显示了,N越大效果越好,如第1行N=512。

6 实验结果
和GAN相关模型进行比较,如AttnGAN、DM-GAN、DF-GAM,可以看到DALL-E(第2行)效果更好。

在MS-COCO 数据集上的效果,DALL-E也比较好。
7 ELBO推导