为什么要有主从复制,使redis具有高可用性!
多机情况下主从复制
同步文件和同步命令
同步文件
-
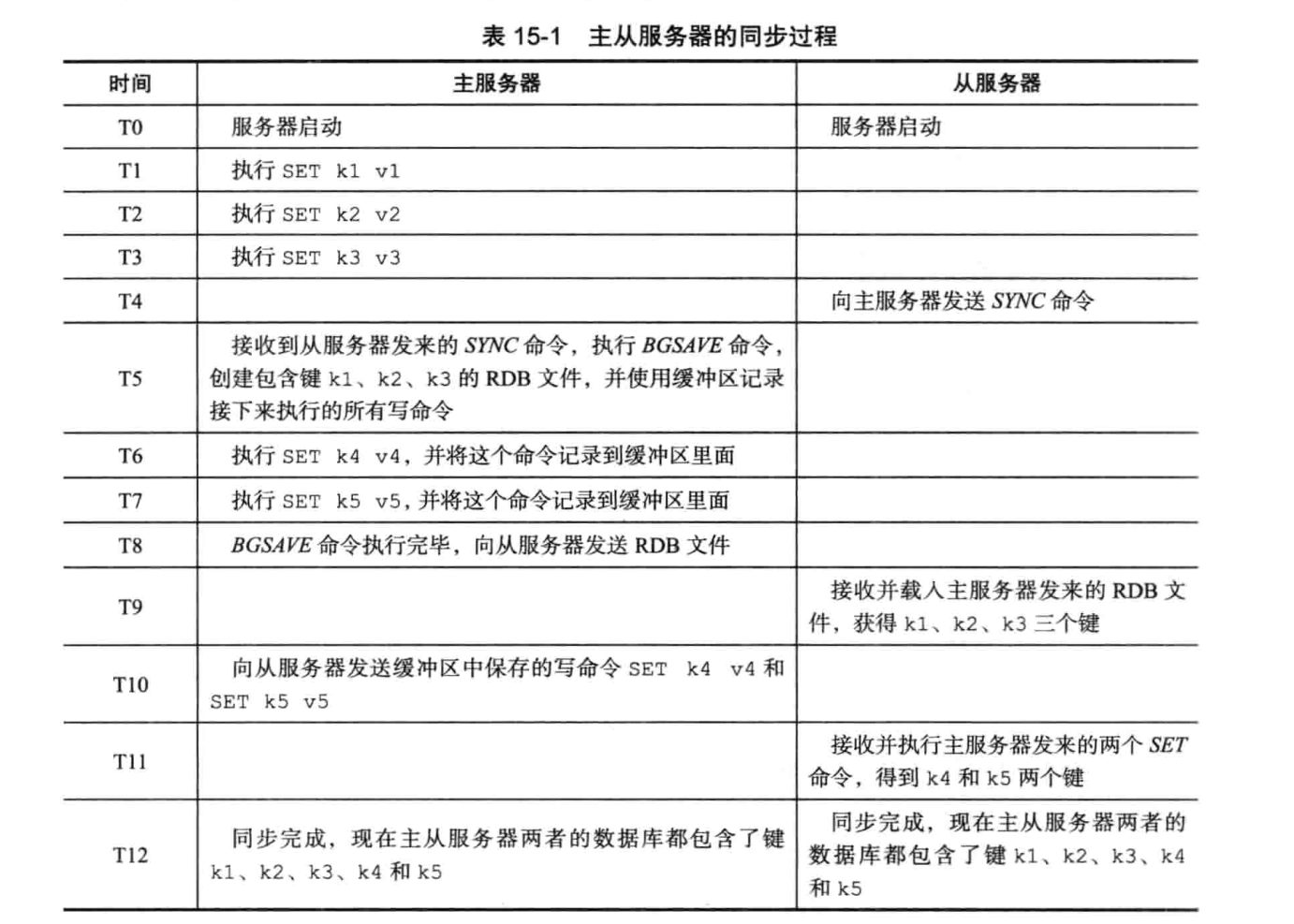
客户端发送命令 slaveof 给从服务器 -
从服务器发送 sync 命令给主服务器,主服务器收到以后,会执行bgsave命令 生成rdb文件,同时会使用缓冲区保存从现在开始执行的所有命令 -
主服务器发送rdb文件给从服务器,从服务器同步状态,主服务器还会同步缓存区内的执行命令给从服务器
同步命令传播
当主从首次同步完全量数据后,此时主从数据是一致的,但是主服务器是可以一直接受命令的,所以主服务器执行完自己的命令,也需要发送相同的命令给从服务器的,来保证主从服务器的数据一致。
旧版,新版复制功能对比
旧版复制流程(redis2.8版本之前)

首先复制分两种:初次复制和断线复制
初次复制没什么好说的,就是利用从服务器发送sync命令 拿到rdb文件来同步自身的数据库数据,因为初次复制,从服务器是没有任何数据的,这也是最快最有效的方法。
断线复制:可以想象下,当在执行命令传播时,因为网络的原因,传播失败,从服务器重连主服务器的过程中,如果主服务器有新的命令需要执行时,那从服务器必然会丢失掉一些命令,也就是导致主从数据不一致的情况,而这时当从服务器重连成功后,就会向主服务器发送sync命令去重新同步主服务器的数据,这样就能达到主从服务器数据一致了。
弊端
每次主从断连,主服务器都要执行bgsave命令保存快照数据,非常耗内存,而从服务器也要恢复数据cpu也会上升。

新版复制流程
主服务器内会有一个数据的偏移量,当发送传播命令时,偏移量会随着发送的数据字节增加,而从服务器接收到命令后,之成功后,也会将自身的偏移量增加,正常情况下主从服务器的偏移量是一致的。
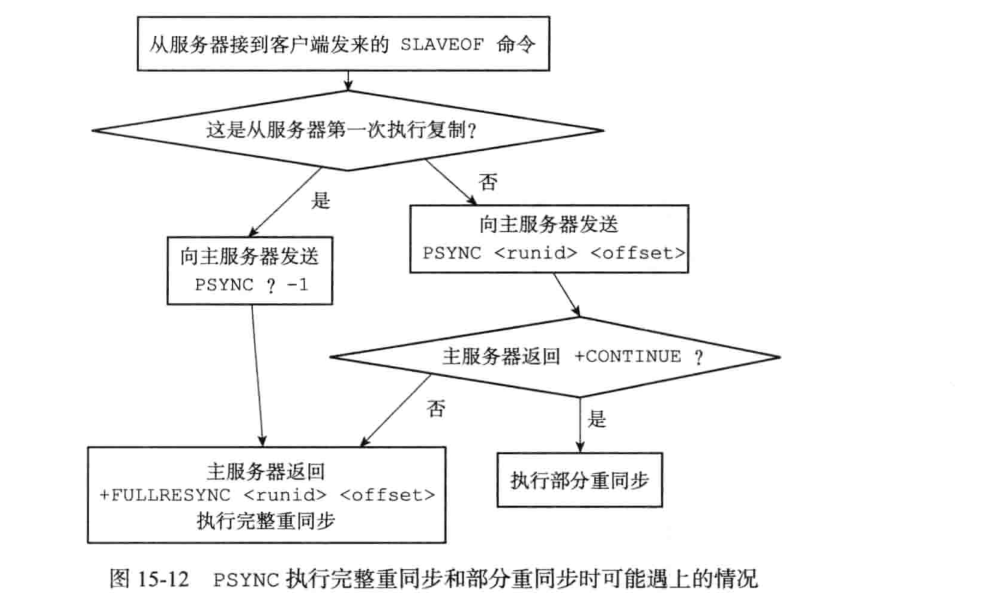
最大的变化:断线重连后,会根据offset偏移量是不是处于复制积压缓冲区 ,runId判断是否是部分复制还是全量复制,减少复制的数据量。客户端发送的命令不是sync,而是psync.
部分同步功能的实现三个部分组成:
-
主从服务器的复制偏移量 -
主服务器的复制积压缓冲区(固定长度的先进先出队列) -
服务器的运行id(runId)(服务器的唯一标识)


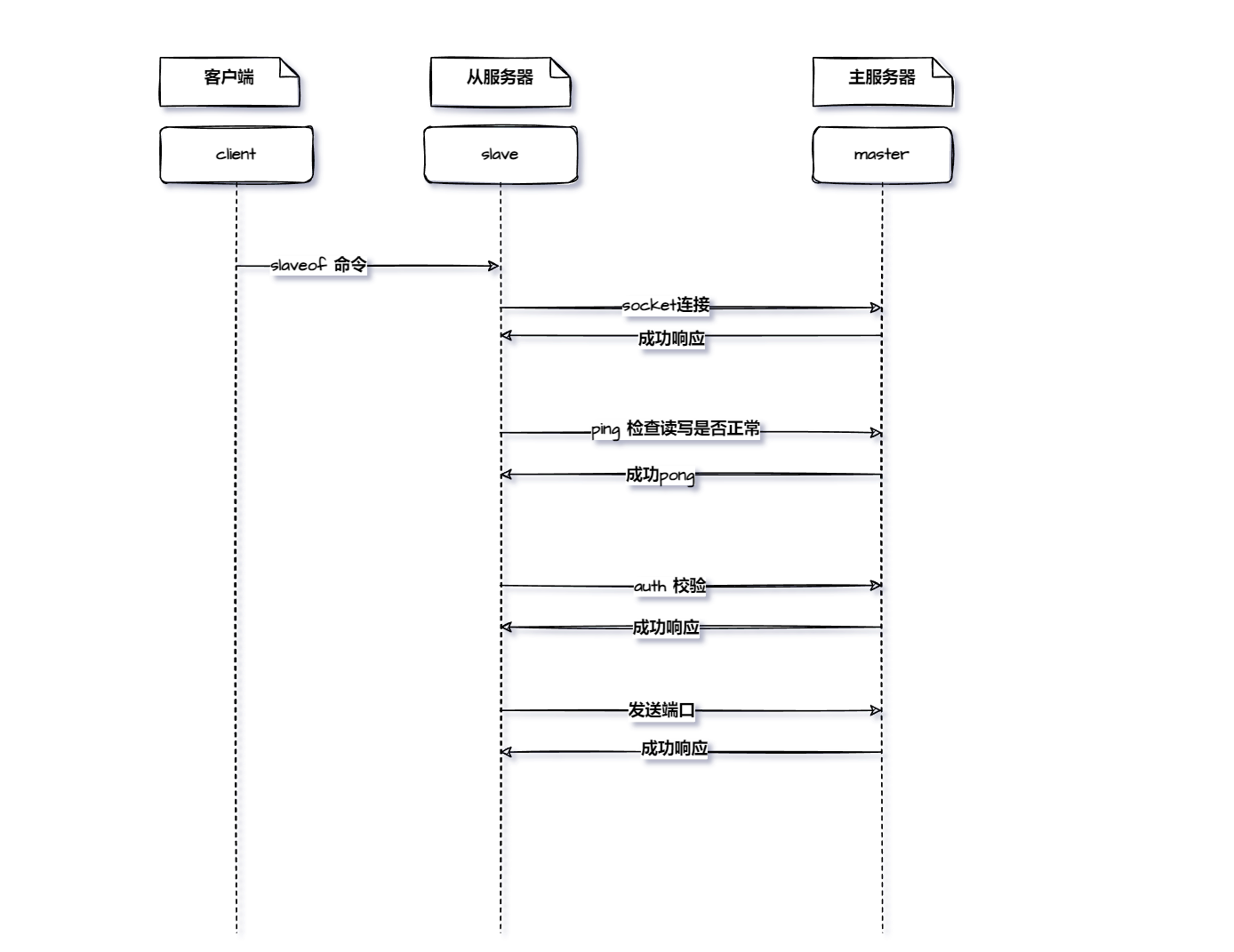
主从建立连接的过程
心跳检测
从服务器会默认以每秒的频率,向主服务器发送命令 replconf ack <reolication_offset>
reolication_offset是从服务器的复制偏移量
作用:
-
检测主从服务器的网络连接状态 -
辅助实现min-slaves -
检查命令丢失
检测主从服务器的网络连接状态
命令 info replication 查看最近一次从服务器向主服务器发送 replconf ack命令距离现在过了多少秒

辅助实现min-slaves

检查命令丢失

小记
-
为什么要读写分离?
避免资源竞争,增加开销
-
形成主从关系命令 (5.0之后,replicaof;5.0之前,salveof;) -
主从级联模式分担全量复制时主库的压力
总结:学习主从连接过程,以及主服务器通过什么条件来判断进行部分复制还是全量复制。
本文由 mdnice 多平台发布