
Title: Accelerated Coordinate Encoding: Learning to Relocalize in Minutes using RGB and Poses
Paper: https://arxiv.org/pdf/2305.14059.pdf
Code: https://github.com/nianticlabs/ace
背景
视觉重定位
视觉重定位是指在计算机视觉领域中的一个任务,其目标是通过分析场景中的视觉信息来确定相机的位置和姿态(即相机的位置和朝向)。
主流的基于学习的视觉重定位pipeline
- **场景训练:**通过深度学习网络学习回归图像中每个像素点的三维坐标。
- **特征提取和描述:**在待定位的图像中提取特征点或特征描述子。
- **2D-3D对应:**将提取的特征点与场景的三维模型进行匹配,建立二维图像点与三维场景点之间的对应关系。
- **姿态估计:**利用鲁棒姿态估计器,如RANSAC PnP算法(随机采样一致性加权最小化重投影误差),从2D-3D对应中估计相机的六自由度姿态(平移和旋转)。
- **迭代优化:**在得到初步姿态估计后,可以通过迭代优化方法进一步优化姿态估计结果。
导读

Learning-based的视觉重定位在姿态准确性方面表现出色,但需要数小时或数天的训练时间。由于每个新场景都需要进行训练,长时间的训练使得基于学习的重定位在大多数应用中不切实际,尽管其具有高准确性的优势。
在本文中,论文展示了如何在不到5分钟的时间内实现相同的准确性。论文将一个重定位网络可以分为一个与场景无关的特征backbone和一个特定场景的预测头。使用多层感知器(MLP)的预测头使论文方法能够在每个单独的训练迭代中同时优化数千个视角。这导致了稳定而极快的收敛速度。此外,论文用基于重投影损失的鲁棒位姿求解器替代了有效但缓慢的端到端训练,这样论文的方法就不需要先验知识,比如深度图或3D模型,以进行快速训练。总体而言,论文的方法在建图方面比最先进的场景坐标回归方法快高达300倍。
贡献
本文的主要贡献如下:
- **加速坐标编码(Accelerated Coordinate Encoding (ACE))**是一种场景坐标回归系统,能够在5分钟内对新场景进行mapping。与先前的最先进的场景坐标回归系统相比,其需要数小时的mapping时间才能达到可比较的重定位精度。
- ACE将一个场景编译成了4MB的网络权重,这是先前场景坐标回归系统所需存储空间的7倍以上,或者为了场景压缩而牺牲了准确性。
- 论文方法只需要具有位姿信息的RGB图像进行建图。而以前的快速建图重定位器则依赖于像深度图或场景网格等先验知识来实现快速建图。
方法
**论文的目标是根据单个RGB图像 I I I估计相机的姿态 h h h。**论文将相机姿态定义为将相机坐标系中的坐标 e i e_i ei映射到场景坐标系(世界坐标系)中的坐标 y i y_i yi的刚体变换,因此 y i = h ⋅ e i y_i = h \cdot e_i yi=h⋅ei。然后可以通过图像到场景的对应关系来估计姿态:

其中 C \mathcal{C} C 是2D像素位置 x i x_i xi 和3D场景坐标 y i y_i yi 之间的对应关系集合。函数 g g g表示鲁棒的姿态求解器。
为了获取2D-3D对应关系,论文采用了场景坐标回归的方法。具体来说,论文学习一个函数预测任意2D图像位置的3D场景点:
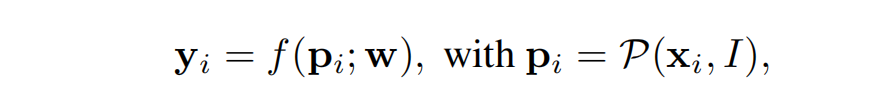
其中, f f f是一个由可学习权重 w w w参数化的神经网络, p i p_i pi是从图像 I I I中的像素位置 x i x_i xi周围提取的图像patch。
使用具有ground truth位姿 h i ∗ h_i^* hi∗的图像来进行监督,训练函数 f f f:
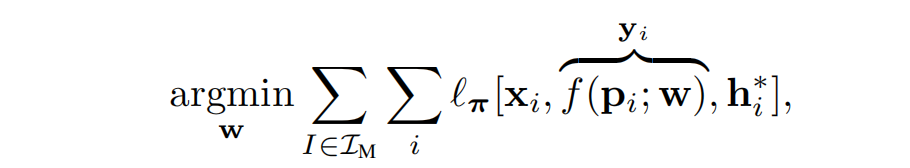
其中, ℓ π ℓ_π ℓπ是一个重投影损失函数。
通过梯度去相关化实现高效训练

如上图所示,传统的2D图像回归3D场景训练过程中,图像特征编码器和预测头解码器都是CNN,在每次训练迭代中对所有的像素构成的成千上万个patch的预测(场景坐标)进行优化,但它们都来自同一幅图像。因此,它们的损失和梯度之间存在很高的相关性。一个像素的预测 y i y_i yi和其相邻像素的预测将非常相似,像素损失和梯度也将相似。
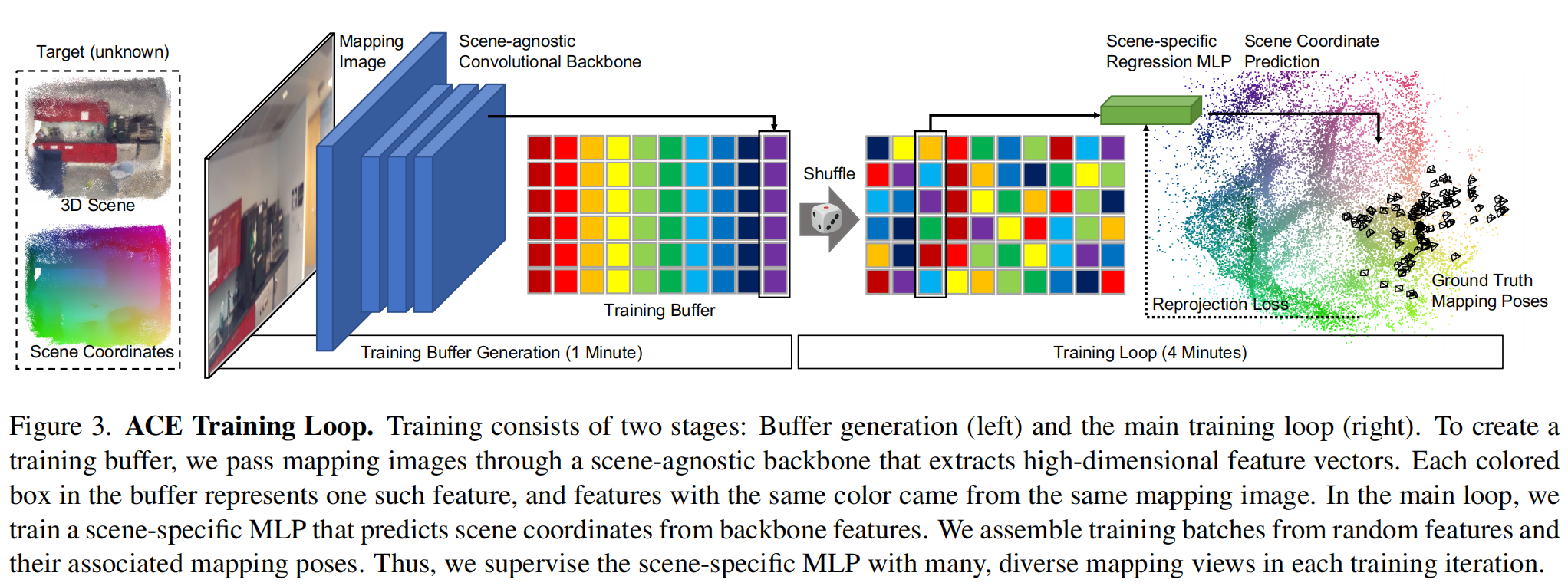
如上图所示,论文的关键思想是在整个训练集上随机选择patch,并随机从许多不同的mapping views构建训练batches。这样可以在batches内去梯度相关化,产生非常稳定的训练信号,对较高的学习率具有鲁棒性,并使用较高的学习率实现快速收敛(说人话就是不需要那么多的patch,mapping之间冗余度太高。。。)。论文将回归网络分解为一个用来预测表示图像特征的高维向量的backbone f B f_\text{B} fB,和一个用来预测场景坐标的多层感知器(MLP)head f H f\text{H} fH:


通过在mapping图像上运行预训练的backbone网络 f B f_\text{B} fB,来构建一个固定大小的训练缓冲区。该缓冲区包含了数百万个特征 f i f_i fi,以及它们对应的像素位置 x i x_i xi、相机内参 K i K_i Ki和ground truth mapping姿态 h i ∗ h^*_i hi∗。(缓冲区中的每个彩色框代表一个这样的特征,而具有相同颜色的特征来自于相同的mapping图像)。
在训练的第一分钟生成这个缓冲区,然后开始主要的训练循环,对缓冲区进行迭代。在每个epoch开始时,对缓冲区进行洗牌,以在所有mapping数据中混合特征(实质上是图像块)。在每个训练步骤中,论文构建包含数千个特征的batches,可能一次计算对数千个mapping视图的参数更新。
Curriculum Training(课程训练)
为了模拟端到端训练的效果,论文采用了一个更简单的像素级重投影损失构建了一个Curriculum。在整个训练过程中,论文使用一个动态的内点阈值,从宽松逐渐变得更严格。因此,网络可以专注于已经好的预测,并忽略那些在姿态估计期间会被RANSAC滤除的不太准确的预测。训练损失基于DSAC* 的像素级重投影损失:

该损失函数优化了有效坐标预测的鲁棒重投影误差,有效预测范围在10cm到1000m之间,并且重投影误差在1000px以下。使用tanh函数对重投影误差进行限制:
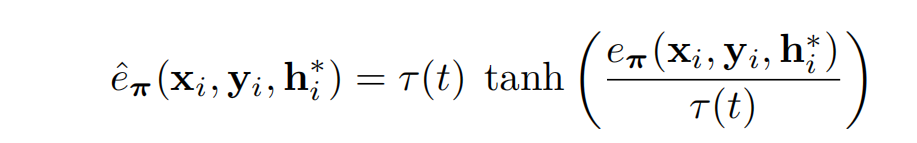
根据在整个训练过程中变化的阈值 τ τ τ动态地重新调整tanh:

其中t∈(0,1)表示相对训练进度。
Backbone Training
为了训练主干网络,论文使用了DSAC的图像级训练方法,并结合了提出自己的Curriculum Training。与仅针对单个场景训练回归头部不同,论文并行训练了多个回归头,每个头对应一个场景。这种设计迫使主干网络预测适用于多个场景的特征。
实验
室内重定位

论文在7Scenes和12Scenes数据集上进行了实验,比较了多种重定位方法的性能。ACE是唯一一种在不到10分钟的时间内实现了高准确性的方法,每个场景所需存储空间不超过10MB,并且无需深度信息进行mapping。
室外重定位
Cambridge Landmarks

论文在剑桥老城区的建筑物上进行了mapping和查询图像的实验。与SfM算法相似的特征匹配方法在该数据集上表现良好。ACE相对于DSAC表现不错,考虑到场景的空间范围和内存占用。论文还提供了ACE的变体Poker,将场景分成四个模型,并在查询时返回具有最大内点数的姿态估计。Poker平均而言优于DSAC,同时mapping时间和存储方面相对较为高效。
Wayspots


论文选择了一个新的重定位数据集(图4),名为Wayspots,从手机扫描数据集中精选而来。论文的方法在平均性能上优于DSAC*,同时mapping速度快两个数量级。在图5中,论文展示了ACE和DSAC在“Rock”场景上的质量比较,包括一个mapping5分钟后停止的DSAC变体。
Analysis
Mapping Time
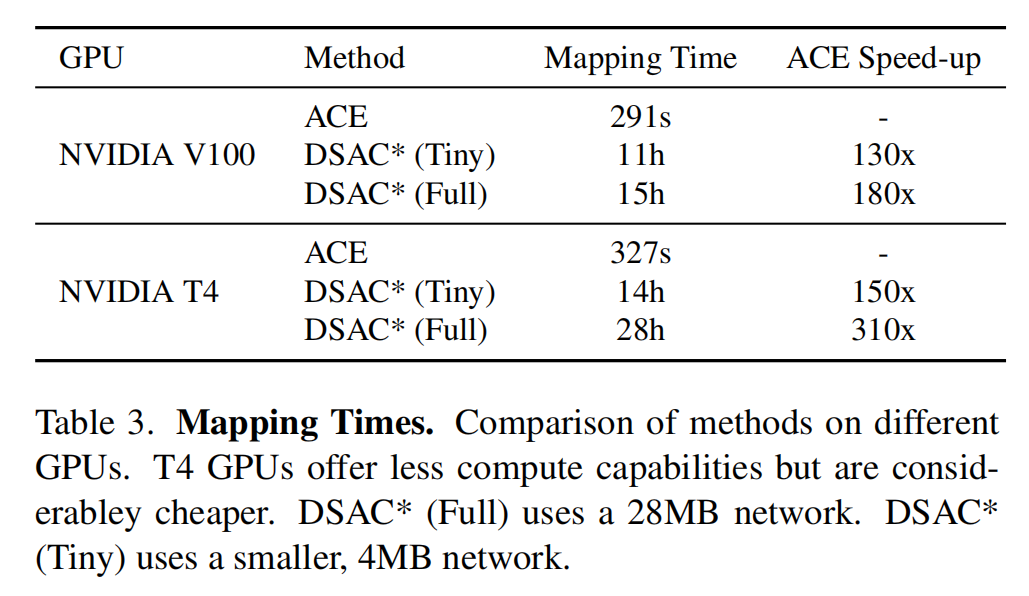
GPU型号决定了网络训练速度。在表格3中,论文比较了ACE和DSAC在高端GPU(NVIDIA V100)和经济型GPU(NVIDIA T4)上的映射时间。DSAC在更便宜的GPU上映射时间是原来的两倍。而ACE只在T4 GPU上降速了10%,因为只需要训练回归头部并使用半精度。
Map Size

网络架构决定地图大小。较小的地图精度略低,但仍能达到95%以上的可靠重定位率。较大的地图并不明显改善结果,因为网络对训练缓冲区的遍历次数较少。ACE仅需一个epoch(75秒)即可实现约80%的准确性。
总结
ACE是一种新颖的视觉重定位方法,可以在5分钟内绘制新环境的地图。与先前基于RGB的场景坐标回归方法相比,ACE显著降低了成本和能源消耗,使其成为实用的解决方案。ACE 的关键改进主要是概念上的,利用patch级别的训练来使梯度解耦。通过巧妙的工程技术,如并行化缓冲区创建和训练,或者对于简单场景的提前停止,还有进一步提高速度的潜力。