官网:https://www.mvtec.com/company/research/datasets/mvtec-3d-ad/downloads
数据大小:13个G
1. 介绍
MVTec 3D异常检测数据集(MVTec 3D- ad)是一个用于无监督异常检测和定位任务的综合3D数据集。
它包含由工业3D传感器获得的4000多个高分辨率扫描。
10个不同的对象类别中的每一个都包含一组无缺陷的训练和验证样本,以及一组具有各种缺陷的样本。为每个异常测试样本提供了精确的ground truth注释。
更多信息可以在我们相应的论文“MVTec 3D- ad数据集用于无监督3D异常检测和定位”中找到。该论文在第17届计算机视觉理论与应用国际会议(VISAPP / VISIGRAPP)上获得了最佳工业论文奖。

2. paper
The MVTec 3D-AD Dataset for Unsupervised 3D Anomaly Detection and Localization
《用于无监督三维异常检测与定位的MVTec 3D-AD数据集》
个人比较喜欢用readpaper,一搜就有
第一个用于无监督异常检测和定位任务的 3D 数据集,采用高分辨率工业 3D 传感器来获取 10 个不同对象类别的深度扫描。【扫描是个啥】

1 INTRODUCTION
贡献点:
- 我们介绍了第一个用于3D数据中无监督异常检测和定位的综合数据集。它由10个真实世界中的4147个高分辨率3D点云scan组成对象类别。虽然训练集和验证集只包含无异常数据,但测试集中的样本包含各种类型的异常。为每个异常提供精确的 ground truth 实况注释。
- 我们评估了目前专门为无监督 3D 异常定位设计的方法。我们最初的基准表明,现有方法在我们的数据集中表现不佳,未来有很大的改进空间。
2 RELATED WORK
一种流行的方法是对从在大规模数据集(如 ImageNet)上预训练的神经网络中提取的描述符的分布进行建模。 以这种方式预训练的网络期望 RGB 图像作为输入。因此,由此产生的方法不适合处理 3D 数据的 2D 表示,例如深度图像,不能轻易转移到 3D 异常检测中。
另一项工作使用生成模型,例如卷积自动编码器 (AE) (Masci et al., 2011) 或生成对抗网络 (GAN) (Goodfellow et al., 2014) 通过评估像素重建误差来检测异常。
Schlegl等人(2019)引入了f-AnoGAN,其中GAN是在无异常的训练数据上训练的。在第二步中,训练编码器网络输出潜在样本,这些样本在传递给 GAN 的生成器时重建各自的输入图像。
同样,基于自动编码器的方法(Bergmann 等人,2019b;Park 等人,2020)首先使用低维潜在样本对输入图像进行编码,然后解码该样本以最小化像素重建误差。
对于这两种方法,异常分数是通过输入图像与其重建的像素比较来计算的。由于这些方法不需要特定领域的预训练,因此它们可以适应其他二维表示,例如深度图像。

图2:MVTec 3D-AD数据集所有10个数据集类别的示例。
对于每个类别,左列显示了一个无异常点云,其中 RGB 值被投影到它上。第二列显示了异常测试样本的特写视图。异常点以红色突出显示在第三列。请注意,背景平面被删除以获得更好的可见性。
3 DESCRIPTION OF THE DATASET
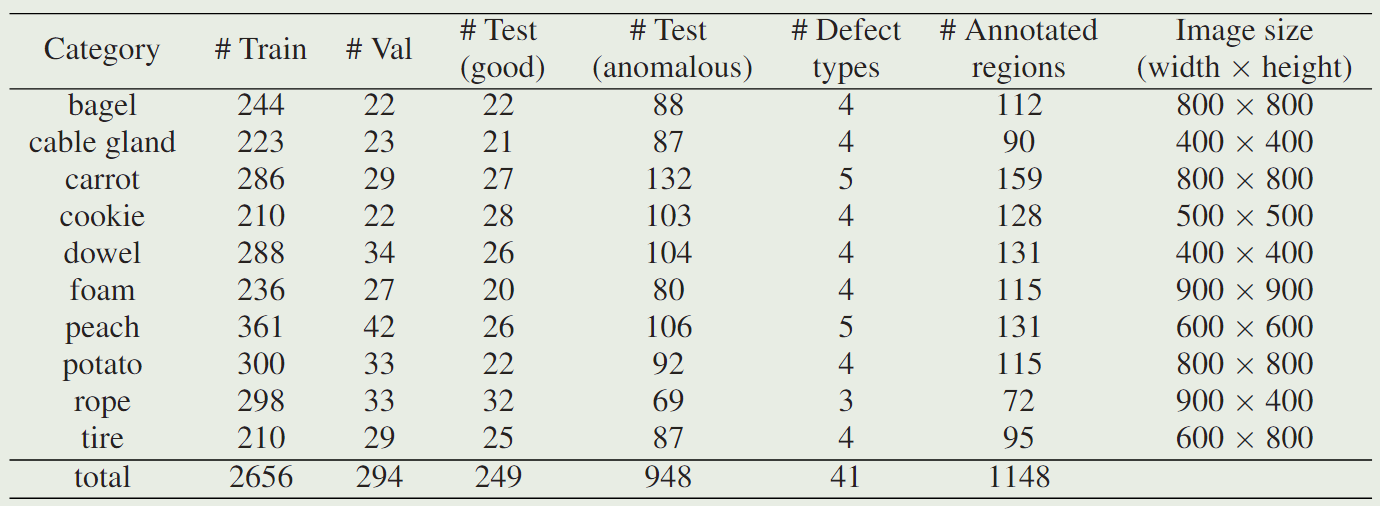
表1:MVTec 3D-AD数据集的统计概述。
对于每个类别,我们列出了训练图像、验证和测试图像的数量。测试图像被分成无异常图像和包含异常的图像。我们报告了每个类别的不同缺陷类型的数量、注释区域的数量以及 (x, y, z) 图像的大小。
我们数据集中的五个对象类别表现出从样本到样本的大量自然变化。这些是bagel, carrot, cookie, peach, and potato.。另外两个对象,foam, rope, and tire,具有标准化的外观,但可以很容易地变形。剩下的两个物体,cable gland and dowel,都是刚性的。原则上,可以通过将对象的几何图形与 CAD 模型进行比较来实现检查最后两个。然而,无监督方法应该能够检测各种对象上的异常,并且在实际应用中,CAD模型的创建可能并不总是可取或实用。每个数据集的示例点云如图 2 所示。该图还显示了一些异常以及相应的地面实况注释。bagel 和 cookie 的图像显示了对象中的裂缝。电缆腺体和穹窿的表面表现出几何变形。carrot、peach、rope表面上有一些污染。foam 部分、potato 和tire被切断。这些是我们的数据集中存在的 41 种异常的典型示例。表 1 列出了有关数据集的更多统计数据。
3.1 Data Acquisition and Preprocessing
所有数据集扫描均使用Zivid One+Medium获取,是一种工业传感器,它使用结构光记录高分辨率的3D扫描。数据由传感器提供,分辨率为1920×1200像素的三通道图像。通道表示相对于局部摄像机坐标系的x、y和z坐标。图像的 (x, y, z) 值为相应的点云提供了一对一的映射。此外,传感器为每个(x, y, z)像素获取互补的RGB值。它被静态安装以从同一角度查看每个单独类别的所有对象。我们对内部相机参数进行校准,允许将3D点投影到各自的像素坐标中(Steger et al., 2018)。场景由间接和漫射光源照射。
对于每个数据集类别,我们指定了一个固定的矩形区域,并裁剪原始 (x, y, z) 和 RGB 图像以减少样本中背景像素的数量。采集设置和预处理与对象通常位于定义位置的真实应用程序非常相似,并且选择照明以最适合任务。此外,我们的设置支持和简化数据增强。所有对象都记录在黑暗的背景上,预处理在对象周围留下足够的余量,以允许应用各种数据增强技术,例如作物、翻译或旋转。这使我们能够使用我们的数据集来训练需要大量数据的深度学习方法,正如我们在第 4 节中的实验所证明的那样。
图3显示了图2所示的桃子异常测试样本提供的数据。图像大小为600×600像素,从原始传感器扫描中裁剪。前三个图像分别可视化数据集样本的 x、y 和 z 坐标。白色像素标记传感器没有返回任何3D信息的区域,例如遮挡、反射或传感器不准确。还显示了相应的 RGB 和地面实况注释图像。
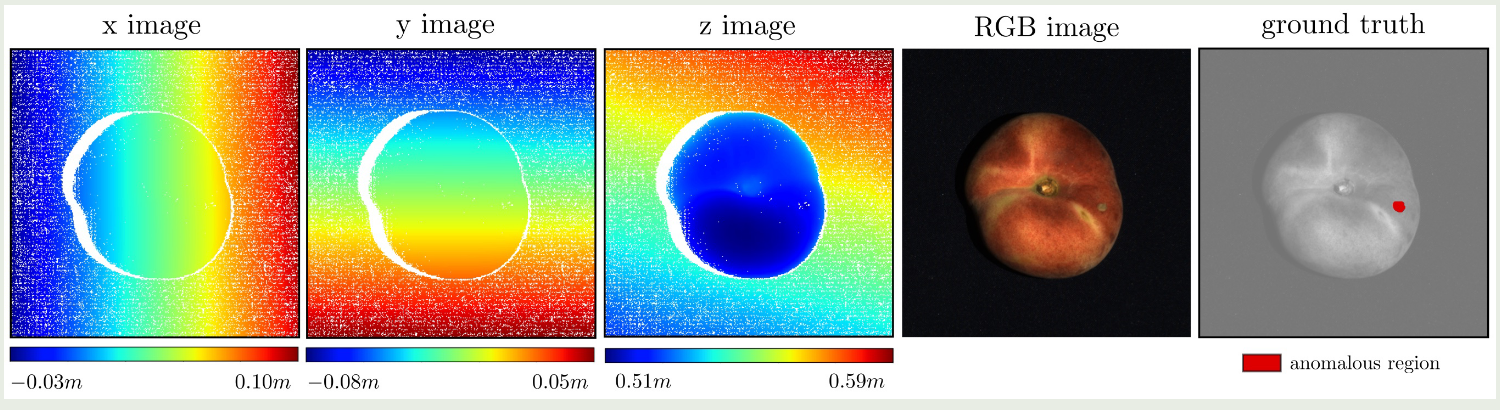
图 3:为数据集类别 peach 的一个异常测试样本提供数据的可视化。
除了对对象的3D坐标进行编码的三个图像外,还提供了RGB信息和像素精确的地面真实图像。
3.2 Ground-Truth Annotations
我们为测试集中的每个异常样本提供准确的真实注释。异常在3D点云中进行注释。由于 3D 点与 (x, y, z) 图像中的各自像素位置有一个一对一的映射,我们将注释作为二维区域提供。此过程允许我们额外标记无效的传感器像素,从而在没有点的情况下注释显示自己的异常。例如,异常可能导致三维重建失败,从而在3D图像中产生无效像素。此外,如果在 RGB 图像中可见异常,其对应的颜色像素尚未包含在地面实况标签中,我们将这些像素附加到注释中。
图 3 显示了一个示例地面实况掩码,其中 peach 上存在污染。在图 2 中,当投影到场景的有效 3D 点时,会可视化进一步的注释。测试集中存在的异常的各个连通分量的大小变化很大,从几百到几千像素。图 4 将它们的分布可视化为具有对数尺度上的异常值的框须图(Tukey,1977)。
3.3 Performance Evaluation
为了评估我们的方法在数据集上的异常定位性能,我们要求它为测试集的每个 (x, y, z) 像素输出一个实值异常分数。与仅将异常分数分配给测试样本的所有有效 3D 点相比,这允许检测通过无效的传感器像素或缺失的 3D 结构表现出自身的异常。这些异常分数使用阈值转换为二进制预测。然后我们计算每个区域的重叠 (PRO) 度量 (Bergmann et al., 2021),它被定义为二进制的平均相对重叠预测 P 与地面实况的每个连通分量 Ck。PRO值计算为:

其中 K 是地面实况组件的总数。
对多个阈值重复此过程,并通过将生成的 PRO 值与相应的假阳性率绘制来构建曲线。最终的性能指标是通过将这条曲线集成到有限的误报率并将结果区域归一化为区间 [0, 1] 来计算的。这是无监督异常定位任务的标准指标,当异常的大小差异很大时特别有用。
我们想强调的是,在处理我们的数据集时,我们强烈阻止在 PRO 曲线下计算高达高误报率的区域。我们建议选择不大于0.3的集成极限。这是因为与图像大小相比,异常区域非常小。在大假阳性率下,数量错误分割的像素将明显大于实际异常像素的数量。这将导致分割结果在实践中不再有意义。我们的数据集也可用于评估算法的性能,如果每个样本包含异常与否,则它对每个样本做出二元决策。在这种情况下,我们将 ROC 曲线下的面积报告为标准分类指标。

图 4:数据集中所有对象的异常大小可视化为框须图。缺陷区域报告为注释连接组件内的像素总数。每个数据集的类别异常的大小差异很大
4 INITIAL BENCHMARK
为了检查现有的 3D 异常定位方法如何在我们的新数据集上执行,我们进行了初始基准。它旨在作为未来方法的基线。已经为此任务明确提出了几种方法,它们都对体素数据进行操作。这主要是由于这些方法最初旨在处理由几层强度图像组成的 MR 或 CT 扫描。作为这类方法的代表,我们在基准测试中包括Voxel f-AnoGAN (Simarro Viana et al., 2021)和我们自己实现卷积体素AE (Bengs et al., 2021)。这些方法的捕食者是为二维图像数据开发的。2D 和 3D 方法之间的主要区别在于分别对图像和体素数据上的 3D 卷积使用 2D 卷积。因此,这些方法很容易适应处理深度图像,我们也将它们包含在我们的基准测试中。除了这些深度学习方法之外,我们还评估了变化模型在体素数据和深度图像上的性能(Steger 等人,2018 年)。他们通过计算与训练数据分布的像素或体素马氏距离来检测异常。
所有评估方法都可以仅在 3D 数据上运行,也可以额外处理附加到每个 3D 点的颜色信息。因此,我们还比较了在向模型添加颜色信息时的性能差异。有关训练参数和模型架构的详细信息可以在附录中找到。
4.1 Training and Evaluation Setup
数据表示。为了将数据集样本表示为体素网格,我们首先计算每个数据集的整个训练集上的全局 3D 边界框。然后,放置一个n × n × n体素的网格