1. Set接口
Set与List同为Collection的继承子接口最大不同就是Set接口中的内容是不允许重复的。当添加重复元素时,不会报错,但是这个添加操作会被忽略。
而且Set并没有对Collection接口进行方法的扩充。
Set有两个实现子类,分别是HashSet和TreeSet,继承关系如下:
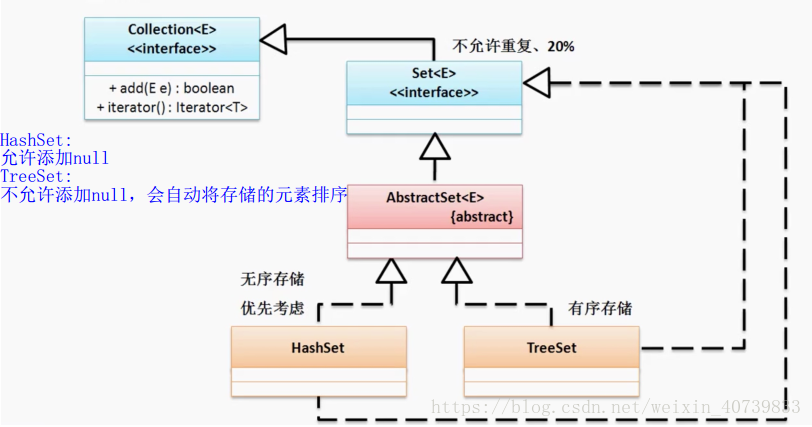
1.1 HashSet
HashSet定义如下:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.SerializableHashSet子类可以添加元素null,添加重复元素时会自动忽略添加操作,存储入HashSet的元素的存储顺序是无序的。
由于Set接口没有扩充Collection接口,所以Set的实现子类拥有的方法和Collection一致,主要方法如下:
// 返回集合长度
public int size();
// 集合是否为空,空返回true,反之false
public boolean isEmpty();
// 集合中是否包含指定元素
boolean contains(Object o);
// 返回一个Iterator接口对象,用于集合的输出,后面会讲
Iterator<E> iterator();
// 将集合编程对象数组返回
Object[] toArray();
// 将指定元素添加进集合中
boolean add(E e);
// 在集合中删除指定元素
boolean remove(Object o);使用:
import java.util.HashSet;
import java.util.Set;
public class Test {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("hello");
// 添加重复元素
set.add("hello");
// 添加null
set.add(null);
set.add(null);
set.add("world");
set.add("java");
System.out.println(set);
}
}运行结果:

1.2 TreeSet
TreeSet子类定义如下:
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.SerializableTreeSet子类添加重复元素时和HashSet处理方式一致,不允许添加null,会报错。另外,存储在TreeSet中的元素会自动进行升序排序。
TreeSet也是Set接口的实现类,其方法与HashSet一致。
import java.util.Set;
import java.util.TreeSet;
public class Test {
public static void main(String[] args) {
Set<Character> set = new TreeSet<>();
set.add('c');
// 重复存储
set.add('c');
set.add('d');
set.add('a');
set.add('b');
System.out.println(set);
}
}运行结果:

2. TreeSet排序分析
这里,我们分析一下TreeSet将存储的对象数组自动排序这个特性。
虽然TreeSet可以完成对象数组的排序处理,但并不是所有的对象都能进行排序。
只有对象所在的类实现了Comparable接口并且覆写接口中的compareTo方法,TreeSet底层才能通过该方法知道对象的大小关系然后进行排序。
另外,对象类覆写compareTo()方法时,类中所有属性都要进行比较操作,实例如下:
import java.util.Set;
import java.util.TreeSet;
class Person implements Comparable<Person> {
private int age;
private String name;
public Person(String name, int age) {
super();
this.age = age;
this.name = name;
}
@Override
public String toString() {
return "[name: "+this.name+", age: "+this.age+"]\n";
}
// 比较方法中所有的属性都要参与比较操作
// 比较策略:优先比较age属性
@Override
public int compareTo(Person obj) {
if(this.age > obj.age) {
return 1;
} else if(this.age < obj.age) {
return -1;
} else {
// String类覆写过compareTo方法,所以这里直接调用
return this.name.compareTo(obj.name);
}
}
}
public class Test {
public static void main(String[] args) {
Set<Person> set = new TreeSet<>();
set.add(new Person("xucc", 14));
set.add(new Person("licc", 13));
set.add(new Person("dabb", 12));
set.add(new Person("bbgir", 11));
System.out.println(set);
}
}运行结果:

因为我们的比较策略是优先比较年龄,可以看出TreeSet按照年龄将Person进行了升序排序。
在实际使用TreeSet中,如果一个类的属性很多,那么覆写它的compareTo()方法将会变得非常麻烦,所以我们使用的还是HashSet子类比较多一点。
3. HashSet对重复元素的判断
Set接口的子类不能存储重复元素。TreeSet是根据覆写的compareTo()方法进行判断的。而HashSet是根据Object类的两个方法进行判断的:
// Hash码
public native int hashCode();
// 对象比较
public boolean equals(Object obj);HashMap底层是通过哈希表实现的,所以在判断重复的时候,首先根据对象的Hash码快速找到对象所位于的桶,然后使用equals方法对该桶上所有的对象进行比较,如果找到了一个相同的对象,证明当前判断的元素重复,否则就不重复。
由此可以看出来,hashCode方法的作用是提高查找的效率,equals方法才算是真正的对象判断方法。
看下面的例子:
import java.util.HashSet;
import java.util.Objects;
import java.util.Set;
class Person {
public int age;
public String name;
public Person(String name, int age) {
super();
this.age = age;
this.name = name;
}
@Override
public String toString() {
return "[name: "+this.name+", age: "+this.age+"]\n";
}
@Override
public boolean equals(Object obj) {
if(this == obj) {
return true;
}
if(obj==null || this.getClass()!=obj.getClass()) {
return false;
}
return Objects.equals(this.name, ((Person)obj).name) &&
Objects.equals(this.age, ((Person)obj).age);
}
// hash方法最后调用了Objects的hash方法
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
public class Test {
public static void main(String[] args) {
Set<Person> set = new HashSet<>();
set.add(new Person("xucc", 14));
set.add(new Person("licc", 13));
set.add(new Person("dabb", 12));
set.add(new Person("bbgir", 11));
System.out.println(set);
}
}运行结果:

如果两个对象hashCode()相同,equals()不同,不能证明两个对象相同,因为对象经过hash函数转换之后可能在同一个桶中,但是值不一定相同。
如果两个对象hashCode()不同,equals()相同,也不能证明对象相同。第一个原因是因为传入的对象可能不属于同一个Map,当不属于同一个Map时,就算同一个对象,它们的hash码也是不同的。第二个原因是我们覆写的equals()方法可能存在编写漏洞,所以再加上hashCode()的判定可以起到双重保险的作用。
所以,只有hashCode()和equals()方法一起使用才能标识出对象的唯一性。
到这里,Collection接口下的List子接口和Map子接口都介绍完了,关于它俩,再提出最后一点小建议: 保存自定义对象的时候使用List接口的子类,保存系统类信息的时候使用Set接口的子类。