I/O多路复用(I/O multiplexing)
multiplexing一词其实多用于通信领域,为了充分利用通信线路,希望在一个信道中传输多路信号,要想在一个信道中传输多路信号就需要把这多路信号结合为一路,将多路信号组合成一个信号的设备被称为Multiplexer(多路复用器),显然接收方接收到这一路组合后的信号后要恢复原先的多路信号,这个设备被称为Demultiplexer(多路分用器)。
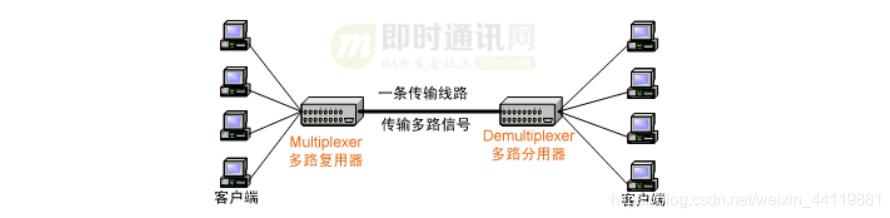
所谓I/O多路复用指的是这样一个过程:
1)我们拿到了一堆文件描述符(不管是网络相关的、还是磁盘文件相关等等,任何文件描述符都可以);
2)通过调用某个函数告诉内核:“这个函数你先不要返回,你替我监视着这些描述符,当这堆文件描述符中有可以进行I/O读写操作的时候你再返回”;
3)当调用的这个函数返回后我们就能知道哪些文件描述符可以进行I/O操作了。
I/O多路复用三剑客
本质上:Linux上的select、poll、epoll都是阻塞式I/O,也就是我们常说的同步I/O。
原因在于:调用这些I/O多路复用函数时如果任何一个需要监视的文件描述符都不可读或者可写那么进程会被阻塞暂停执行,直到有文件描述符可读或者可写才继续运行。
select:初出茅庐
在select这种I/O多路复用机制下,我们需要把想监控的文件描述集合通过函数参数的形式告诉select,然后select会将这些文件描述符集合拷贝到内核中。
我们知道数据拷贝是有性能损耗的,因此为了减少这种数据拷贝带来的性能损耗,Linux内核对集合的大小做了限制,并规定用户监控的文件描述集合不能超过1024个,同时当select返回后我们仅仅能知道有些文件描述符可以读写了,但是我们不知道是哪一个。因此程序员必须再遍历一边找到具体是哪个文件描述符可以读写了。
因此,总结下来select有这样几个特点:
1)我能照看的文件描述符数量有限,不能超过1024个;
2)用户给我的文件描述符需要拷贝的内核中;
3)我只能告诉你有文件描述符满足要求了,但是我不知道是哪个,你自己一个一个去找吧(遍历)。
因此我们可以看到,select机制的这些特性在高并发网络服务器动辄几万几十万并发链接的场景下无疑是低效的。
poll:小有所成
poll和select是非常相似的。
poll相对于select的优化仅仅在于解决了文件描述符不能超过1024个的限制,select和poll都会随着监控的文件描述数量增加而性能下降,因此不适合高并发场景。
epoll:独步天下
在select面临的三个问题中,文件描述数量限制已经在poll中解决了,剩下的两个问题呢?
针对拷贝问题:epoll使用的策略是各个击破与共享内存。
实际上:文件描述符集合的变化频率比较低,select和poll频繁的拷贝整个集合,内核都快被烦死了,epoll通过引入epoll_ctl很体贴的做到了只操作那些有变化的文件描述符。同时epoll和内核还成为了好朋友,共享了同一块内存,这块内存中保存的就是那些已经可读或者可写的的文件描述符集合,这样就减少了内核和程序的拷贝开销。
针对需要遍历文件描述符才能知道哪个可读可写这一问题,epoll使用的策略是“当小弟”。
在select和poll机制下:进程要亲自下场去各个文件描述符上等待,任何一个文件描述可读或者可写就唤醒进程,但是进程被唤醒后也是一脸懵逼并不知道到底是哪个文件描述符可读或可写,还要再从头到尾检查一遍。
但epoll就懂事多了,主动找到进程要当小弟替大哥出头。
在这种机制下:进程不需要亲自下场了,进程只要等待在epoll上,epoll代替进程去各个文件描述符上等待,当哪个文件描述符可读或者可写的时候就告诉epoll,epoll用小本本认真记录下来然后唤醒大哥:“进程大哥,快醒醒,你要处理的文件描述符我都记下来了”,这样进程被唤醒后就无需自己从头到尾检查一遍,因为epoll小弟都已经记下来了。
因此我们可以看到:在epoll这种机制下,实际上利用的就是“不要打电话给我,有需要我会打给你”这种策略,进程不需要一遍一遍麻烦的问各个文件描述符,而是翻身做主人了——“你们这些文件描述符有哪个可读或者可写了主动报上来”。
这种机制实际上就是大名鼎鼎的事件驱动——Event-driven