文章目录
- 目的
- Mali Offline Compiler 使用实例视频
-
- 分析 shader
- malioc 命令
- 制定你想要分析的 shader
- 制定你想要分析的着色器对应的 GPU
- 实例解析内容
- 硬件结构 & 驱动 & Shader 类型信息
- 寄存器、是否堆溢出、16-bit 算术占比
- 算术,加载/写入、插值、纹理 等单元
- 换个 Mali-G78 r1p1 GPU
- FMA(乘加加速器), CVT(算术类型转换), SFU(特殊单元)
- cycles占比介绍说明
- Shader Properties (属性部分)
- 是否使用到 通用计算
- 是否有 alpha test, alpha-to-coverage
- 是否有使用 later ZS testing 和 later ZS update,以及性能影响说明
- 输出报告
- 一个 cycle 可能的流程
- References
- 扩展
目的
便于后续不用反复观看视频
直接截图 + 字幕说明,文档化
如果你喜欢的话,也可以直接再 油管上直接,选择:搜索视频,查看字幕来定位播放对应时间进度内容
Mali Offline Compiler 使用实例视频
参考:Arm Mali GPU Training - Episode 3.5: Mali Offline Compiler
分析 shader
命令行 ls 列出文件
比如这个 shader 用于游戏中 角色溶解的效果
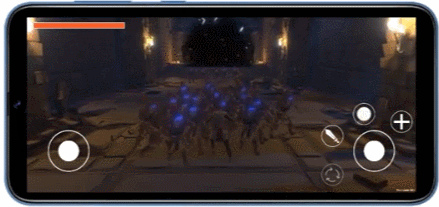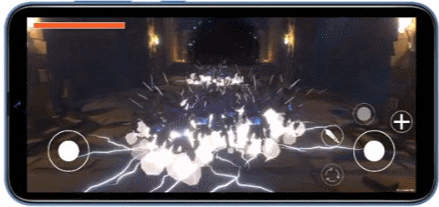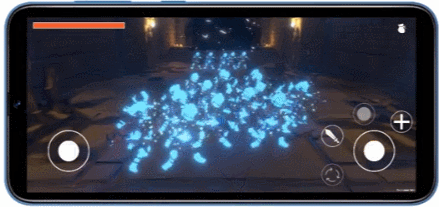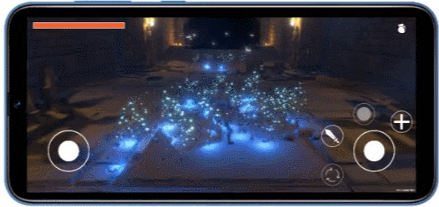
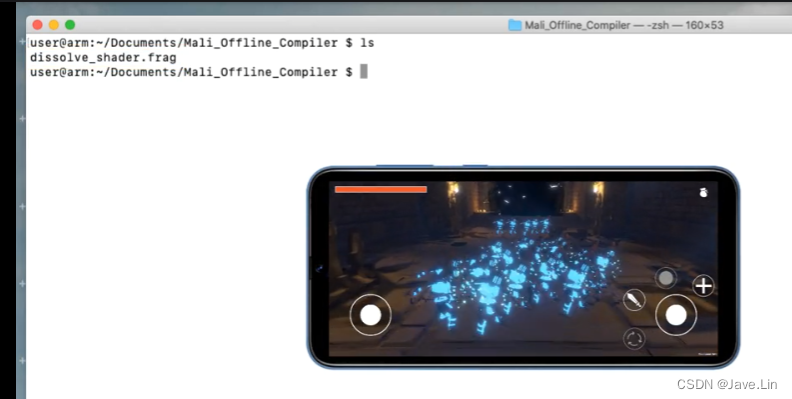
使用 maili offline compiler 分析的示例
malioc 命令
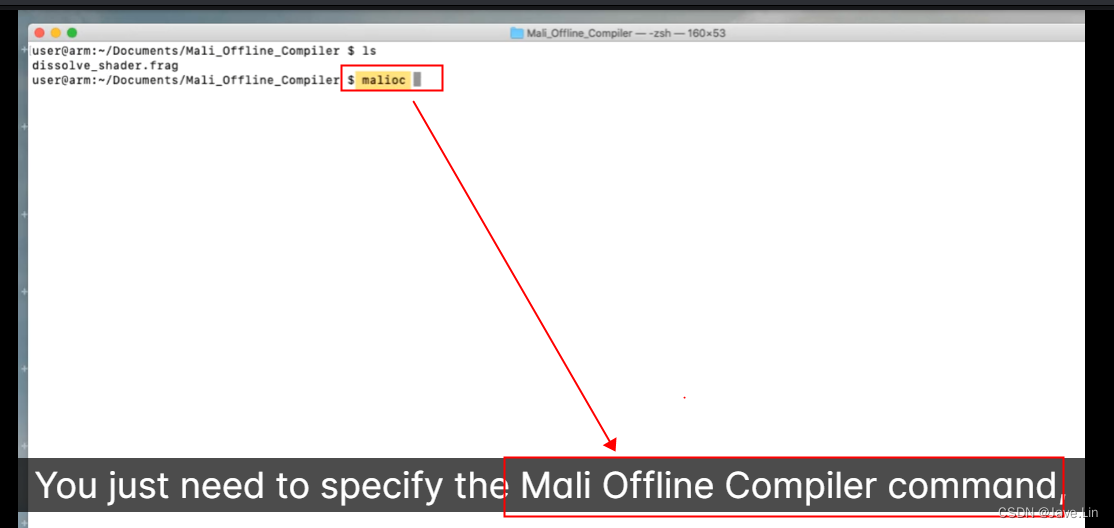
制定你想要分析的 shader
制定你想要分析的着色器对应的 GPU
这里使用的是 Mali-072 型号的 GPU
实例解析内容
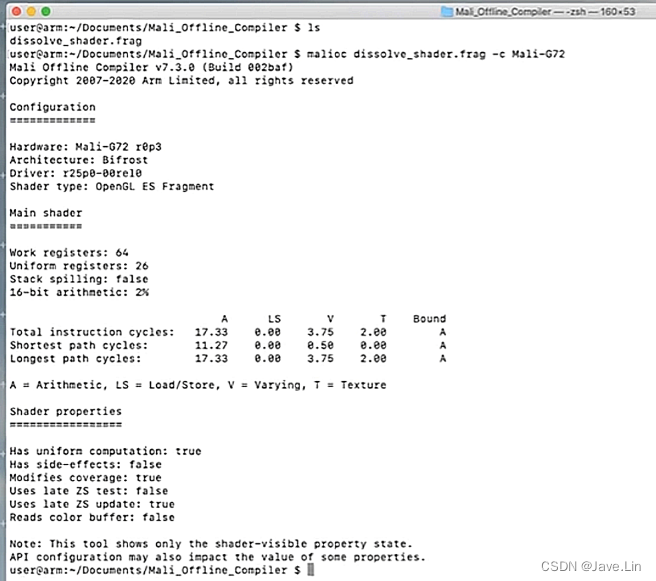
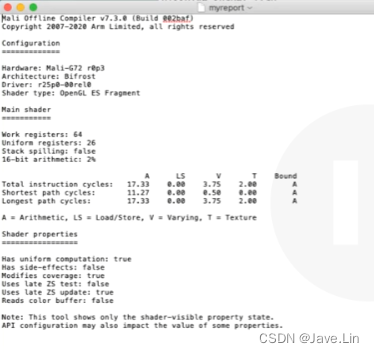
硬件结构 & 驱动 & Shader 类型信息
第一部分是:
- 硬件 : Mali-G72 r0p3
- 结构 : Bifrost
- 驱动 : r25p0-00rel0
- Shader 类型 : OpenGL ES Fragment, OpenGL ES 片源着

寄存器、是否堆溢出、16-bit 算术占比
之后还有
- 使用到的 registers : 64 个
- Uniform registers : 26 个
- Stack spilling : false, 没有堆栈溢出
- 16-bit arithmetic : 2%,16位算术占 2%

寄存器的使用量减少
但是留意,这个 GPU 最大 registers 是 32 个

可用的物理寄存器池被分配给正在执行的着色器线程
the available physical register pool is divided, among the shader threads aht are executing
因此,减少工作寄存器的使用,可以增加可以同时执行的线程数量,有助于保持GPU繁忙
so, reducting work register usage, can increase the number of threads that can be executed simultaneously, helping to keep the GPU busy
浮点精度优化

为了减少工作寄存器的使用,尝试将精度从高32位降低到中16位
To reduce work register usage, try reducing precision from highp, 32-bit to mediump, 16-bit
这使得GPU可以在每个寄存器中存储两倍的变量。
This enables the GPU to store twice as many variables per register.
堆溢出与否
(jave.lin : 看了一些资料说的是,一些变量是否溢出到 Stack 来 读写,如果是,那么性能会下降,如果是从 register 上来读写,那么性能会高很多)

对于Valhall和Bifrost GPU,我们可以看到是否有任何变量溢出到堆栈内存,如果是,每个线程溢出多少字节。
For Valhall and Bifrost GPUs, we can see whether any variables are spilled to stack memory, and if so, how many bytes per thread are spilled.
溢出到堆栈的着色器对于GPU来说是昂贵的,所以如果你看到堆栈溢出,尝试通过降低变量精度,减少变量的有效范围或简化着色器程序来减少寄存器压力
Shaders that spill to stack are expensive for a GPU to process, so if you see stack spilling going on, try to reduce register pressure, by reducing variable precision, reducing the live ranges of variables, or by simplifying the shader program
16-bit 算术占比

在这里,您可以看到以16位或更低精度执行的算术运算的百分比。
Here you can see the percentage of arithmetic operations, that are performed at 16-bit precision or lower.

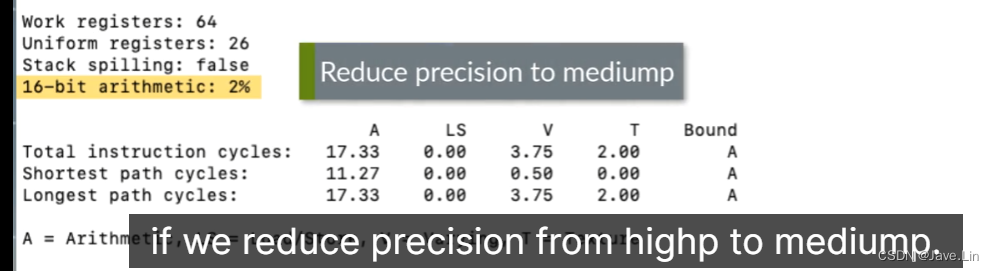
这里的数字越高越好,因为使用mediump选择的16位精度比 highp 32位精度速度快两倍。我们可以看到,只有2%的算法计算是在16位精度下完成的。这意味着着色器在大多数计算中使用32位精度。如果我们将精度从高降低到中,着色器将更有效地运行。这样既降低了能耗,又降低了寄存器压力,使性能翻倍。有些情况下总是需要高分辨率,例如位置和深度计算,但在许多情况下,当将精度降低到中档时,屏幕上几乎没有明显的差异。
A higher number here is better, because 16-bit precision, selected with mediump, is twice as fast as highp at 32-bit precision. We can see that only 2% of artihmetic computation is done at 16-bit precision. This means that the shader is using 32-bit precision highp for most of its calculations. The shader will operate more efficiently if we reduce precision from highp to mediump. This reduces both energy consumption and register pressure, and can double the performance. There are situations where highp is always required, such as for position and depth calculations, but in many cases there is little noticeable difference on-screen when reducing precision to mediump
算术,加载/写入、插值、纹理 等单元
接下来,有一个大概的周期成本分解
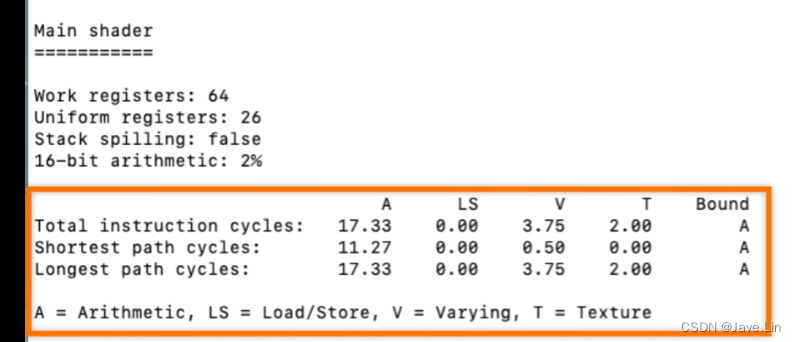
- A = Arithmetic - 算术
- LS = Load/Store - 加载/存储
- V = Varying - 插值其
- T = Texture - 纹理
对于Mali着色器核心中的主要功能单元,算术单元,加载/存储单元,插值单元和纹理单元。
for the major functional units in the Mali shader core, the arithmetic unit, the load/store unit, the varying unit, and the texture unit.
单元占用的cycle周期中,cycle成本最高 和 最小的单元 都是一个很好的候选优化对象。
The unit with the hightest cycle cost in either or both of the shortest path cycles, and longest path cycles, is a good candidate to optimize.
定位瓶颈

在这里,我们可以看到算术单位是使用最频繁的。我们可以通过减少数学运算的次数来优化它,或者降低计算的精度。
Here, we can see that the arithmetic unit is the most heavily used. We can optimize it by reducing the number of mathematical operations that it performs, or the precision of the those calculations.

其实 Bound 也会告诉你,瓶颈在哪个部分,比如上图都是在 A 的部分,也就是 算术部分
(jave.lin : 但是这只是但从单元资源占比分析,具体还是要看 shader 应该场景)
换个 Mali-G78 r1p1 GPU
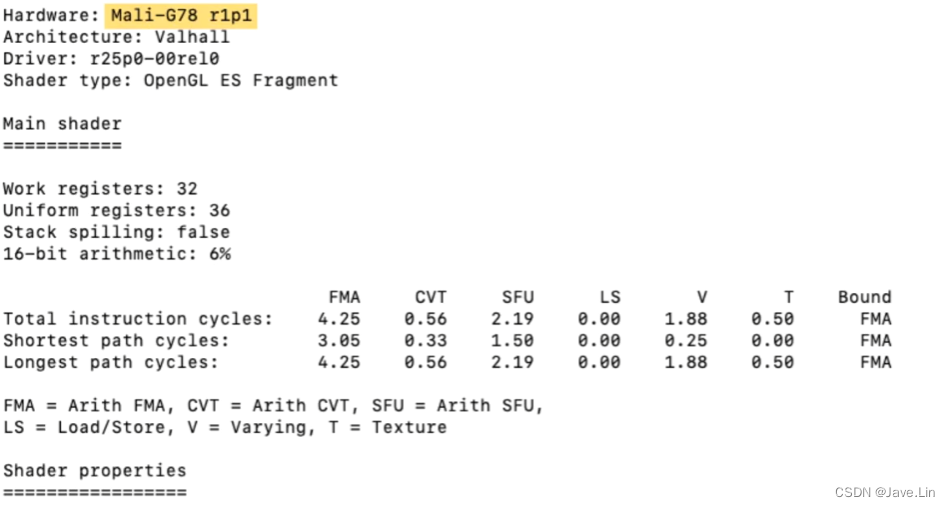

FMA(乘加加速器), CVT(算术类型转换), SFU(特殊单元)
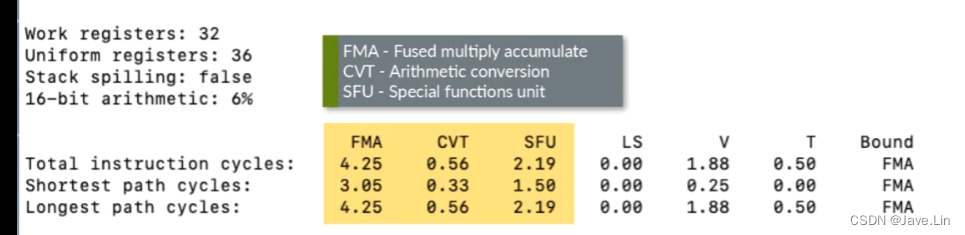
对于基于Valhall的GPU,如Mali-G78,算法成本显示为FMA, CVT和SFU管道的分解。
For Valhall-based GPUs, such as the Mali-G78, arithmetic cost is shown broken down by FMA, CVT and SFU pipelines.
- FMA - Fused multiply accumulate - “熔合乘法累积”(Fused Multiply Accumulate),这是一种结合了乘法和加法的指令,可以通过一条指令实现递归计算。
- 其中最主要的是新增的3操作数指令(3-Operand Instructions)和熔合乘法累积(Fused Multiply Accumulate,FMAC)指令,这两条指令都可以大幅提高操作效率,简化代码。
- CVT - Arithmetic conversion - CVT算术转换
- 隐式类型转换 又称为“标准转换”,包括以下几种情况: 1) 算术转换(Arithmetic conversion) : 在混合类型的算术表达式中, 最宽的数据类型成为目标转换类型。
- SFU - Special functions unit - 特殊功能单元,比如: sin, cos, tan, atan, log, exp 等等
cycles占比介绍说明
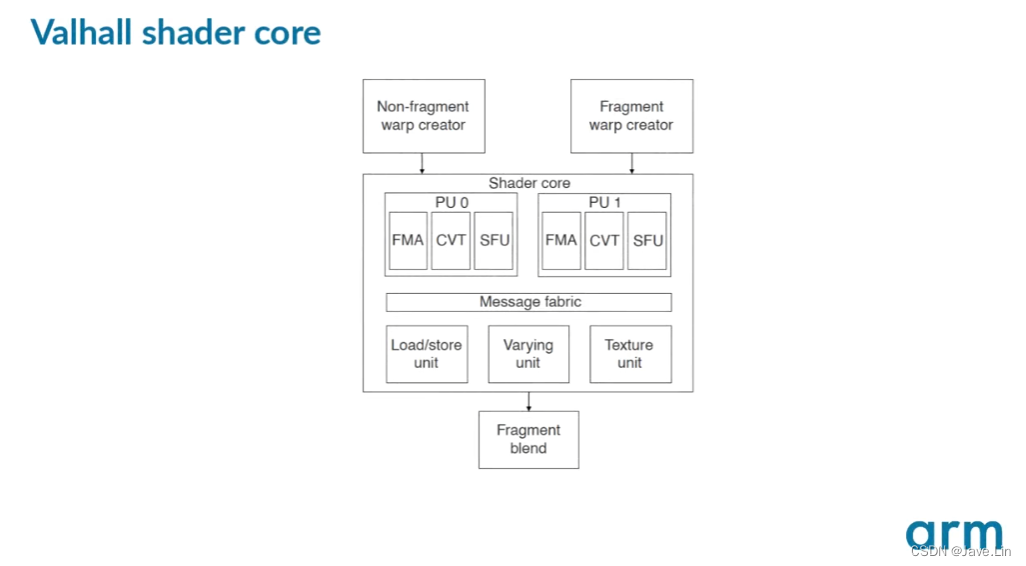
所有Valhall GPU都实现了两个并行处理引擎,每个都包含自己的一组算术流水线。
All Valhall GPUs implement two parallel processing engines, each containing their own set of arithmetic pipelines.
报告中的数据是基于设计中的引擎数量进行归一化的,以给出目标着色器核心的总体成本,而不仅仅是单个引擎的成本。
The data presented in the report is normalized based on the number of engines in the design, to give an overall cost for the targeted shader core, not just for a single engine.
Shader Properties (属性部分)


着色器属性(shader properties)部分给出了着色器使用的语言特性的信息,这些特性可能会影响着色器执行的性能。
The shader properties section, gives information about the shader’s use of language features that can impact the performance of shader execution.
是否使用到 通用计算

尽可能移植到 CPU 上执行

我们可以看到这个着色器包含了统一计算。这种计算将为drawcall或compute dispatch中的每个线程产生相同的结果。Mali驱动程序可以优化这种方式,但它仍然有成本,所以你应该将这种计算从着色器代码中移出,转移到CPU上,在绘制时执行。
We can see that this shader contains uniform computation. This kind of computation will produce the same answer for every thread in the drawcall or compute dispatch. The Mali driver can optimize the way, but it still has a cost, so you should move this kind of computation out of the shader code, and on to the CPU, to be executed at draw time.
是否有 alpha test, alpha-to-coverage

这告诉我们着色器可以修改片段覆盖掩码 (jave.lin : 也就是 片段 可能会丢弃,你可以理解为 现在的 alpha test)。片段覆盖掩码确定每个像素中的哪些样本点被片段覆盖,使用discard语句删除低于alpha阈值的片段。
This tells us that the shader can modify the fragment coverage mask. The fragment coverage mask determines which sample points in each pixel are covered by a fragment, using the discard statement to drop fragments that are below an alpha threshold.
是否有使用 later ZS testing 和 later ZS update,以及性能影响说明

(jave.lin : alpha test) 覆盖范围可修改的着色器必须使用 later ZS更新,这会降低 early ZS测试的效率和同一坐标下later fragments 的调度效率。
Shaders with modifiable coverage must use a later ZS update, which can reduce efficiency of early ZS testing and fragment scheduling for later fragments at the same coordinate.
应该尽可能少 discard

你应该尽可能减少在fragment着色器中使用discard语句和alpha-to-coverage语句。
You shold minimize the use of discard statements and alpha-to-coverage in fragment shaders where possible.

幸运的是,这个着色器不会强制 Later ZS测试,Later ZS测试会完全禁用 Early ZS测试和 HSR (hidden surface removal) 隐藏表面的删除,从而导致显著的效率损失。
Fortunately, this shader does not force a later ZS test, which would completely disable early ZS testing and hidden surface removal a significant efficiency loss.
输出报告

通过运行带有额外命令行选项的命令,您可以将此报告导出到文件。
You can export this report to a file, by running the command with this extra command line option.
输出json报告,制定自己的dashboard

如果你在持续集成环境中工作,你还可以将Mali离线编译器报告导出为机器可读的JSON文件,这样你就可以构建自己的仪表板来监控着色器的性能。
If you are working within a continuous integration enviroment, you can also export Mali Offline Compiler reports as machine-readable JSON files, so that you can build your own dashboard to monitor shader performance over time.
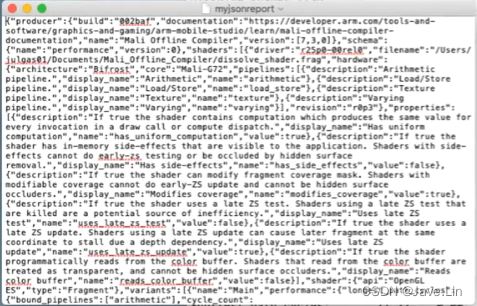
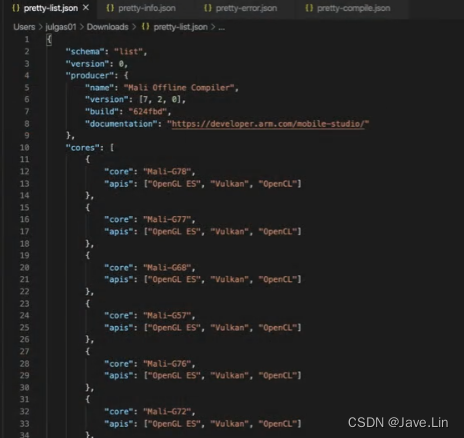
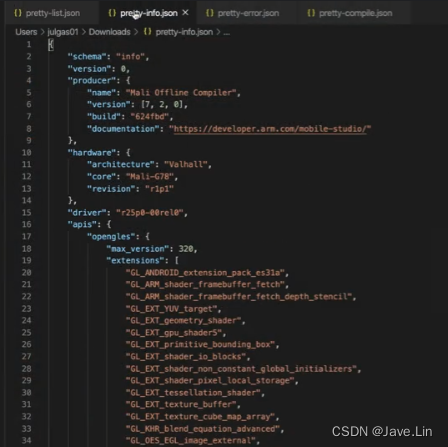

安装目录中提供了示例报告和JSON模式定义。
Sample reports and JSON schema definitions are provided in the installation directory.
检查帮助页面以查看所有可用选项的列表。
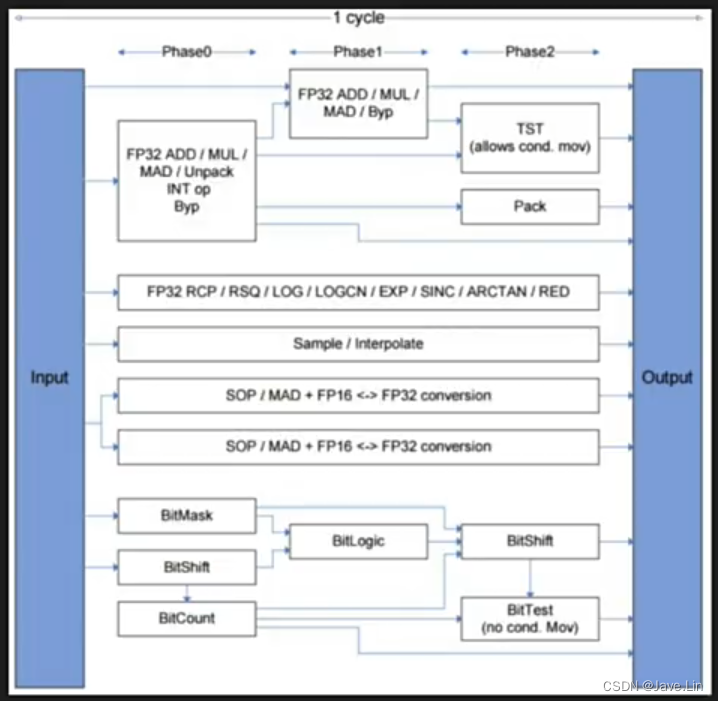
一个 cycle 可能的流程
References
扩展
- Mali GPU Counter
- Mali Offline Compiler
- Mali Graphics Debugger
- 使用Mali Graphics Debugger调优Unity程序(Killer示例)
- 使用Mali Compiler对Unity Shader进行优化
- MaliCompiler
- Shader指令优化 - 大眼的 xcode 下的优化
- 如何评测shader的效率?