问题
在公司的产品开发中,存在多个团队负责产品的不同子系统,数据从上游进入系统,然后流向下游应用,每个子系统相互独立,是通过数据串在一起,在这种场景下,如果以传统的思维方式,可能是调用下游提供的WebAPI来post数据,也可能是上下游共用相同的数据库,不仅使得上下游耦合紧密,而且难以横向扩展,提高吞吐量,在产品中,我们使用Kafka作为数据总线,在上下游之间传递消息,这样不仅解耦各个子系统,而且可以很容易的扩展kafka集群,使得消息快速的分发和响应,与其他的消息中间件相比(如RabbitMQ等),Kafka相对性能更高,在单机QPS可以达到十万量级甚至更高,而且因为是发布订阅模式,可以实现多播方式,供多个消费者消费,这样如果结合大数据系统,那么一个consumer group对接Hadoop的分析系统,另外一个consumer group对接spark,storm等在线实时系统。通过使用Kafka,解决了子系统间的数据流动瓶颈,在子系统之间,不再需要协商定义调用接口,只需要定义传递的数据协议

Kafka简介
Kafka是一个分布式的发布订阅消息系统,通过横向扩展及分区,可以极大的提高吞吐率,消息具有持久化的能力,支持实时与离线处理
Kafka 拓扑架构

在kafka中有以下基本概念
- Topic:主题,指Kafka处理的消息分类,是一个逻辑上的概念
- Partition:Topic物理上的分区,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。
- Message:消息,是通信的基本单位,每个producer可以发布某一个topic的消息。
- Producers:生产者,推送消息到kafka集群
- Consumers:消费者,建立到kafka集群的长连接,并拉取消息进行处理
- Broker:缓存代理,Kafa集群中的一台或多台服务器统称为broker。
Producer发送消息时必须指定它的Topic,创建topic时,指定分区数量,Topic在逻辑上可以被看作是一个虚拟的queue,可以简单理解为必须指明把这条消息放进某个队列里,而最终消息是在Broker上存储在每个分区中。为了使得Kafka的吞吐率可以线性提高,物理上把Topic常分成多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件,一个append log文件,任何发布到此partition的消息都会被追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型的数字,它唯一标记一条消息。
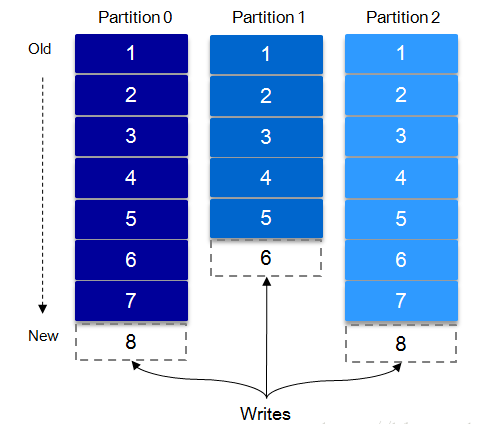
对于consumer,通常位于group中,在一个group中,可以有多个consumer,但其数量不能多于所消费的topic的分区数量,在一个group中,每个分区的消息至多只能送到一个消费者上,即一个消费者可以消费多个分区,一个分区只能给一个消费者消费,下图显示一个有5个分区的topic,消息存储在2个broker上,每个consumer自己记录在分区(队列)上消费的消息的状态位置offset,kafka集群中的每个server更像以文件方式顺序存储的无状态的日志系统。如果有多个消费组,那便是多播方式

项目架构:

说明
- 此处WebAPI和Java Kafka Service部署在同一个server上,因跨进程,使用ICE进行通信,Google Buffer定义协议,需要分别编译为C# 及Java version
- producer发送主题消息,用avro定义好消息格式,并获取offset ack
- consumer从分区拉取消息,进行处理
安全性:
从0.9版本后,Kafka引入Security,主要包括3部分:身份认证(Authentication),权限控制(Authorization),数据加密(Encryption)。认证机制主要是指配置SSL/SASL,在客户端与服务端连接进行身份认证,而授权是实现消息级别的权限控制,配置客户端的读写操作权限。此外,在clients(producer,consumer)与tools,brokers之间,使用SSL对数据加密。

从WebAPI之后的都是部署在内网,外部无法访问,但即使是内网,也有不同的子系统在使用kafka,只有经过认证和授权的用户才可以使用kafka发布消息及消费消息,上面第2步及第3步,使用的是Kerberos身份认证,ZooKeeper需要启用Kerberos认证模式
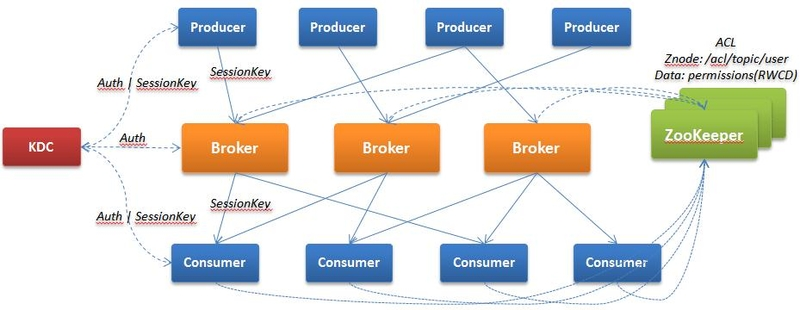
Broker:启动时,读取配置文件中的身份信息向KDC认证,只有认证通过才可以加入kafka集群
Producer(Consumer):启动时需要经过以下步骤
- 读取producer的配置文件(java.security.auth.login.config)jaas及keytab的身份信息,向KDC进行身份认证,如果通过则获得TGT
- producer使用TGT向KDC请求Kafka服务,KDC验证TGT并向Producer返回SessionKey(会话密钥)和ServiceTicket(服务票证)
- Producer使用SessionKey和ServiceTicket与Broker建立连接,Broker使用自身的密钥解密ServiceTicket,获得与Producer通信的SessionKey,然后使用SessionKey验证Producer的身份,通过则建立连接,否则拒绝连接
producer(consumer)jaas配置文件
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="C:/Users/xyz/keytabs/xyz.keytab"
doNotPrompt=true
serviceName="kafka"
principal="[email protected]";
};
keytab 文件创建方法
ktpass /princ [email protected] /pass mypassword1 /ptype KRB5_NT_PRINCIPAL /crypto All /out xyz.keytab cacls xyz.keytab /g [email protected]:f
扩展阅读: