业务问题
- 跨IDC读写导致带宽压力大问题。多个业务还可能有重复consume和produce,造成跨IDC网络的极大浪费, 另外跨IDC网络并不稳定,经常遇到一些异常
- 业务直接使用官方裸客户端有困难,要进行二次封装
- 异常情况会catch不全
- 使用好kafka对业务有较高要求
- 客户端容错不能完全cover住360场景要求。当网络或集群异常直至不可用性时,数据就会丢失
- 不支持exactly once语义,需要业务配合实现
- ......
- 数据高可用支持不足,如果分片的所有副本都分布在单个机架上,数据有丢失风险高
- 数据分片(partition)分布不均衡。如果集群节点数量远大于分区数,kafka默认分配算法会造成数据倾斜,某些节点分配多,一些分配很少硬件资源利用率低
- 集群内新老机器因配置差异负载不均衡。随着时间推移硬件快速发展,新加入的机器性能是老机器成几何倍数提高,如果平均分配,则负载不均衡,新机器吃不饱,老机器吃不了。
技术选型
360选型Kafka从下面几个维度考虑:社区活跃度、客户端支持、吞吐量、数据可靠性比较
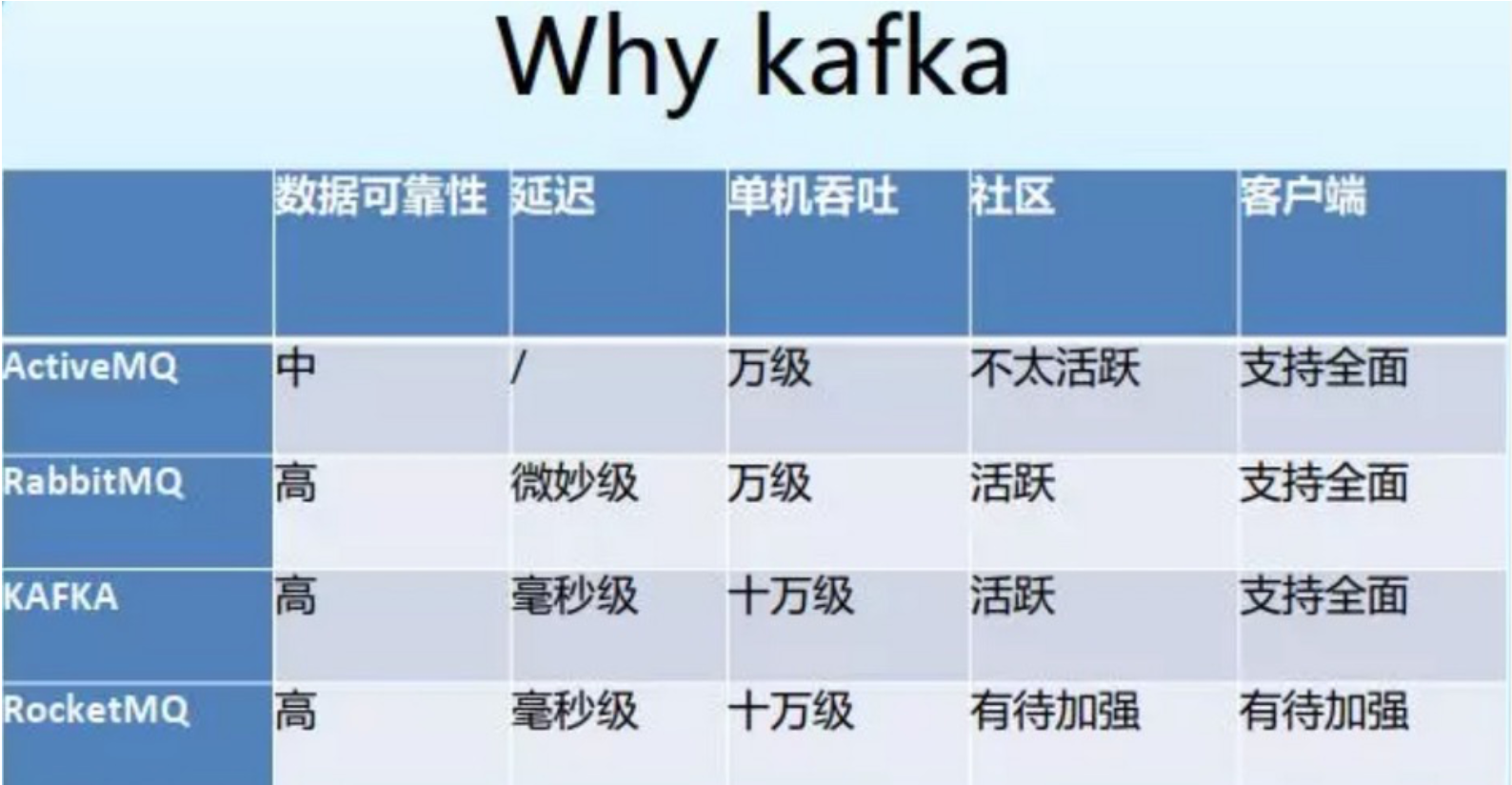
从kafka架构设计亮点分析
- Kafka性能和吞吐都很高,通过sendfile和pagecache来实现zero copy机制,顺序读写的特性使得用普通磁盘就可以做到很大的吞吐,相对来说性价比比较高。
- Kafka通过replica和isr机制来保证数据的高可用。
- Kafka集群有两个管理角色:controller主要是做集群的管理;coordinator主要做业务级别的管理。他们都由Kafka里面的某个broker来担任,当某个broker failover时,选举其中一个broker来替代即可,从中可以发现Kafka一个去中心化的设计,但controller本身也是一个瓶颈,可以类比于hadoop的namenode。
- 分布式系统实现要么是CP,要么是AP。Kafka实现比较灵活,不同业务可以根据自身业务特点来对topic级别做偏CP或偏AP的配置。

根据以上多个MQ多维度比较,综合权衡优劣势考虑,360最终选择了Kafka
生产环境
- 目前集群有千亿级日志量,PB级数据量
- 集群规模:100多台万兆机器,
- cpu 24 core、network 10Gb/s、128GB、磁盘 4TB*12 JBOD
- 单topic的最大峰值60万QPS
- 集群的峰值大概在500万QPS
- 部署版本为kafka-1.1.1
解决措施
改造跨IDC读写带宽大问题
- 利用mirrormaker进行IDC同步数据,IDC间数据只同步一份
- 一是屏蔽了异常对业务的影响
- 节省了IDC之间的带宽,通过同步机制能保证这份数据只传输一份
- 所有业务只做本地读写
- 硬件资源池docker化,提供服务SLA
解决Kafka客户端易用性和稳定性
- 基于Kafka官网客户端进行二次封装,封装原则如下
- 对业务进行细节屏蔽掉,暴露出足够简单的接口
- 框架处理所有细节,减少业务犯错概率
- 针对producer和consumer分别提高2个组件LogProducer和LogConsumer
- 极端情况仍然可用
- 网络或集群异常保证仍然可用,如果网络或集群不可用,数据会先落到本地,等恢复的时候再从本地磁盘恢复到Kafka中。
- 提供LogProducer
- 支持at least once语义
- 提供LogConsumer
- 支持at least once
- exactly once语义,需要业务去实现rollback接口
解决数据和资源均衡性及利用率问题
- 用一致性hash环增加虚拟节点,解决数据分片(partition)分布不均衡问题
- 新建hash circle:通过vnode_str(比如hostname-v0)做一个MD5的hash,得到虚拟节点的vnode_key,再用ring字典来保存虚拟节点到物理节点的映射,同时将vnode_key加入到sorted_keys的list中
- 在hash环中分配replica: 将(topic_name + partition_num + replica_num)作为key用相同的MD5 hash算法得到replica_key, 接着二分查找该replica_key在sorted_keys中的position, 最后用ring字典来映射到物理机node, 至此replica分配完成
- 用多机架均衡分配副本解决副本聚集单机架可用性低问题
- 实现replica的rack aware,物理节点上面会有rack信息,在为replica分配物理节点的时候会记录已经分配的rack信息,如果有重复的情况,就会把vnode_key找到position的位置+1找下一个物理节点,我们会确保三个replica的物理rack一定是不一样的(假如replica=3)
- 用分区及副本的权重数量分配解决新老机器配置差异负载不均衡问题
- 添加物理节点只需迁移很小一部分数据;
- 对不同配置的物理机做权重设置,可以支持异构集群的部署;
启用鉴权、授权和ACL,增强安全性
- 白名单机制,通过工单申请流程管理合法topics、consumers,过滤非法的
监控报警支持
- 用jmx exporter+promehteus+grafana来做图表展示,每个broker上面部署jmx exporter, prometheus会去pull这些数据,最后通过grafana来展示
- 用Kafka manager做瞬态指标的监控
- 用burrow做consumer lag的监控
- 用wonder来做告警,这个是360内部实现的一个组件,类似zabbix
SLA保障
- 把业务分为三类优先级,高优先级重点保障,低优先topic降级
- 当突然服务负载高,紧急情况下可对低优先级服务降级。例如:进行请求/复制限流
参考资料
千亿级数据量的Kafka深度实践:https://mp.weixin.qq.com/s/5p1IgayVXvCSLLc0Zvoqew