如何使用配置文件参数 - 实现预训练模型训练

引言
预训练模型在各个领域的应用取得了显著的成果,但是标准预训练模型可能无法完全满足个性化需求。为了实现更好的性能和效果,研究人员和开发者需要对预训练模型进行定制化的训练。在过去,修改模型的架构、调整数据处理流程、优化训练策略和调整运行设置等通常需要对源代码进行修改,这对于大多数用户来说可能具有一定的挑战性。然而,通过修改配置文件参数,我们可以灵活地调整预训练模型的各个方面,从而实现个性化的训练。
本文将探讨如何通过修改配置文件中的参数来实现预训练模型的定制化训练。我们将介绍配置文件的基本结构和参数含义,详细阐述参数修改的方法和步骤,并通过实际案例展示参数修改对预训练模型的影响。通过这种方法,用户可以根据自己的需求和任务特点,灵活地修改模型的架构、调整数据处理方式、优化训练策略和调整运行设置,以达到更好的性能和效果。
为什么使用配置文件来预训练模型呢
为了管理深度学习实验的各种设置,我们使用配置文件来记录所有这些配置。这种配置文件系统具有模块化和继承特性。
使用配置文件来预训练模型具有重要的管理、灵活性、可维护性、可重复性和共享性等优势。配置文件提供了一种方便的方式来记录和管理深度学习实验的各种设置,使得模型的定制化训练和实验管理更加高效和可靠性。
使用配置文件我们可以脱离源代码的编写,只需要在配置文件中去修改模型的参数,增加对应的模型块,就可以实现修改模型的功能。比起最老套的预训练方法,只通过数据集来改变模型的参数,这种修改配置文件方法,更能够从模型本质上修改,使出来后的模型更适合自己
如果能把配置后的模型,通过Netron软件可视化出来,那就更完美了,这样跟玩积木有什么区别呢。

配置文件结构
配置文件结构大致可以分为以下四个:
- 模型(model)部分:
模型架构:包括模型的层级结构、各层的参数配置、激活函数的选择等。
模型参数:包括学习率、优化器类型、正则化参数等与模型训练相关的参数设置。
- 数据(data)部分:
数据集路径:指定用于训练和验证的数据集的路径。
数据预处理:包括数据清洗、数据标准化、数据增强等预处理操作的设置。
数据划分:指定训练集、验证集和测试集的划分方式和比例。
- 训练策略(schedule)部分:
学习率策略:设置学习率的初始值、衰减方式、衰减步数等。
正则化策略:设置正则化方法和参数。
批次大小:指定每个训练批次的样本数量。
训练迭代次数:设定模型训练的总迭代次数。
- 运行设置(runtime)部分:
训练设备:指定在哪种硬件设备上进行训练,如CPU、GPU等。
日志记录:设置日志文件的保存路径和格式。
模型保存:指定训练过程中模型参数的保存路径和保存频率。
可视化工具:选择可视化工具来监控模型训练过程的指标变化。
这种通过配置文件修改模型预训练,有一个缺点,就是必须依赖于不同框架他们规定的配置格式进行配置定义参数。虽然每种框架底层都用的跟torch类似的方法,但组合起来就是不一样的。
下面我使用飞浆的 ResNet50 配置文件来说明不同配置文件的含义
以PaddleClas套件为例,配置文件如下所示:

# global configs
Global:
checkpoints: null
pretrained_model: null
output_dir: ./output/
device: gpu
save_interval: 1
eval_during_train: True
eval_interval: 1
epochs: 120
print_batch_step: 10
use_visualdl: False
# used for static mode and model export
image_shape: [3, 224, 224]
save_inference_dir: ./inference
# training model under @to_static
to_static: False
# model architecture
Arch:
name: ResNet50
class_num: 1000
# loss function config for traing/eval process
Loss:
Train:
- CELoss:
weight: 1.0
Eval:
- CELoss:
weight: 1.0
Optimizer:
name: Momentum
momentum: 0.9
lr:
name: Piecewise
learning_rate: 0.1
decay_epochs: [30, 60, 90]
values: [0.1, 0.01, 0.001, 0.0001]
regularizer:
name: 'L2'
coeff: 0.0001
# data loader for train and eval
DataLoader:
Train:
dataset:
name: ImageNetDataset
image_root: ./dataset/ILSVRC2012/
cls_label_path: ./dataset/ILSVRC2012/train_list.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- RandCropImage:
size: 224
- RandFlipImage:
flip_code: 1
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 64
drop_last: False
shuffle: True
loader:
num_workers: 4
use_shared_memory: True
Eval:
dataset:
name: ImageNetDataset
image_root: ./dataset/ILSVRC2012/
cls_label_path: ./dataset/ILSVRC2012/val_list.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 64
drop_last: False
shuffle: False
loader:
num_workers: 4
use_shared_memory: True
Infer:
infer_imgs: docs/images/inference_deployment/whl_demo.jpg
batch_size: 10
transforms:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
- ToCHWImage:
PostProcess:
name: Topk
topk: 5
class_id_map_file: ppcls/utils/imagenet1k_label_list.txt
Metric:
Train:
- TopkAcc:
topk: [1, 5]
Eval:
- TopkAcc:
topk: [1, 5]
对于模型参数配置,这里有一个技巧,可以将所有的模型分成四部分组成来配置,分别是:
- 顶层模块(Top Module):顶层模块是网络的最高级别模块,负责整体的输出和任务执行。它通常包括输出层、损失函数和评估指标等,用于生成最终的预测结果或执行特定的任务。
- 主干网络(Backbone Network):主干网络是网络的核心部分,负责提取输入数据的高级特征表示。主干网络通常由多个卷积层、池化层和全连接层组成,用于逐层地学习输入数据的特征。
- 颈部(Neck):颈部位于主干网络和顶层模块之间,起到连接和转换的作用。颈部通常由一些中间层或模块组成,用于进一步处理和压缩主干网络提取的特征表示,以便更好地适应特定任务的需求。
- 头部(Head):头部位于颈部之后,负责对颈部输出的特征进行进一步处理和解码,以生成最终的预测结果。头部通常包括一些全连接层、池化层、归一化层等,用于将特征映射到最终的输出空间。
这些部分在网络结构中的位置可以根据具体的网络架构而有所不同,因为不同的网络模型可能具有不同的层次结构和组件配置。然而,一般来说,主干网络通常位于网络的中间部分,颈部和头部位于主干网络之后,而顶层模块则位于网络的最顶层。
基本上很多模型框架都会有一个模型组件纵览图:例如PaddleDetection
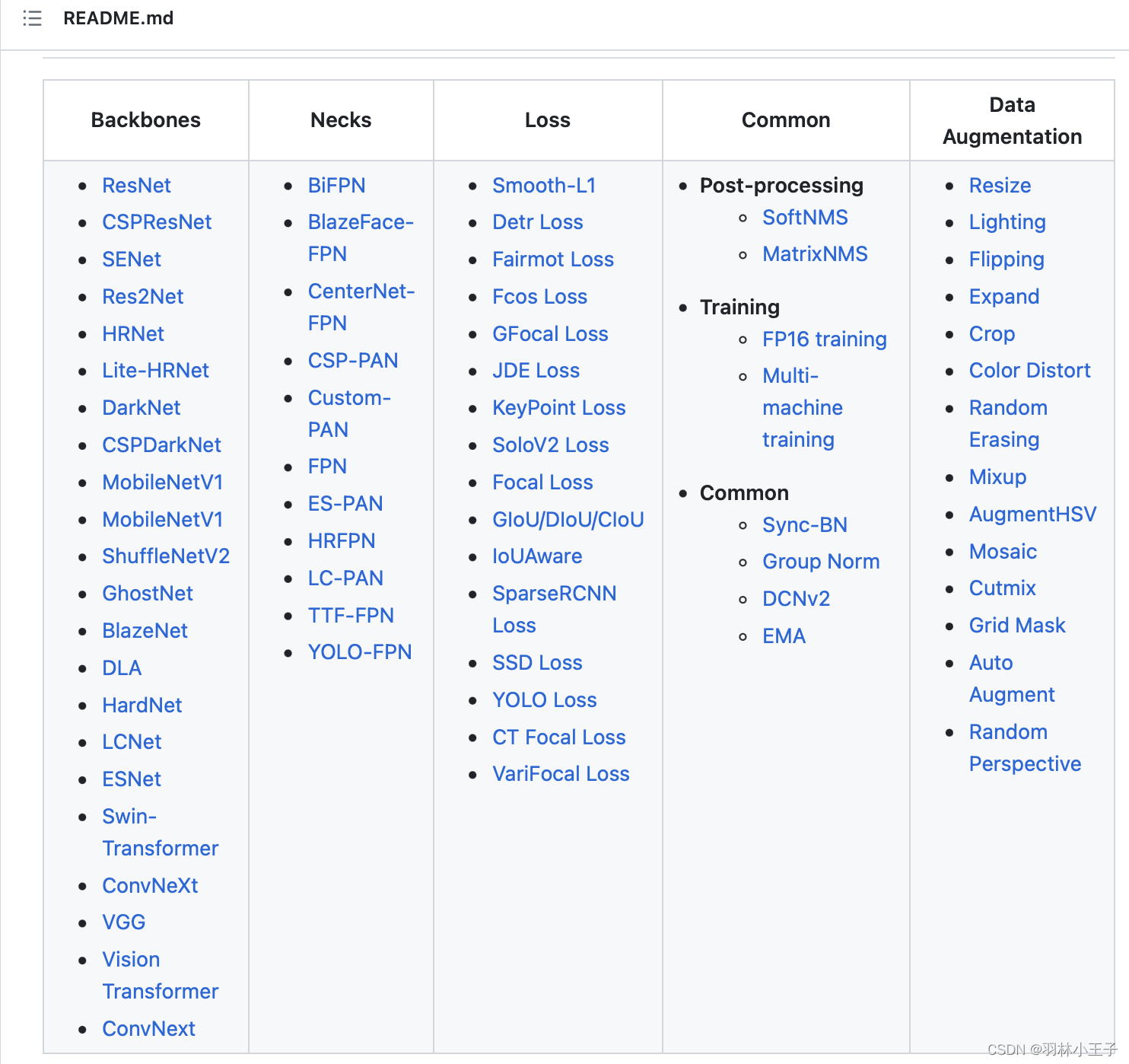
如果能搞明白,不同组块之间如果对接上,其实有跟玩乐高一个道理了,自己也可以拼一个模型出来。
举例实现通过配置文件训练模型
要通过配置文件修改模型的配置,并进行预训练模型训练,可以按照以下示例代码进行操作:
import torch
import torch.nn as nn
from torchvision.models import resnet50
import yaml
# 加载配置文件
with open('config.yaml', 'r') as file:
config = yaml.safe_load(file)
# 创建主干网络
if config['model']['type'] == 'resnet50':
backbone = resnet50(pretrained=config['model']['pretrained'])
backbone.fc = nn.Identity() # 移除原始ResNet50的全连接层
# 获取主干网络输出尺寸
dummy_input = torch.zeros(1, 3, 224, 224) # 假设输入为3通道、224x224的图像
backbone_output_size = backbone(dummy_input).size(1)
# 创建顶层模块
if config['top_module']['type'] == 'linear_classifier':
top_module = nn.Sequential(
nn.Dropout(config['top_module']['dropout']),
nn.Linear(backbone_output_size, config['model']['num_classes'])
)
# 创建颈部
if config['neck']['type'] == 'global_avg_pooling':
neck = nn.AdaptiveAvgPool2d((1, 1)) # 全局平均池化
# 创建头部
if config['head']['type'] == 'linear_layer':
head = nn.Linear(backbone_output_size, config['head']['hidden_size'])
# 进行预训练模型训练
# 定义损失函数和优化器等
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(list(backbone.parameters()) + list(top_module.parameters()), lr=config['training']['lr'])
epochs = config['training']['epochs']
# 进行训练循环
for epoch in range(epochs):
# 在每个epoch中进行训练和验证等操作
backbone.train()
top_module.train()
for batch_idx, (images, labels) in enumerate(train_loader):
# 将输入数据(images)和标签(labels)加载到设备上
images = images.to(device)
labels = labels.to(device)
# 前向传播
features = backbone(images)
outputs = top_module(features)
# 计算损失
loss = loss_fn(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 打印训练信息
if batch_idx % config['training']['log_interval'] == 0:
print(f'Train Epoch: {
epoch+1}/{
epochs} '
f'Batch: {
batch_idx+1}/{
len(train_loader)} '
f'Loss: {
loss.item()}')
# 验证模式
backbone.eval()
top_module.eval()
val_loss = 0
correct = 0
with torch.no_grad():
for images, labels in val_loader:
# 将输入数据(images)和标签(labels)加载到设备上
images = images.to(device)
labels = labels.to(device)
# 前向传播
features = backbone(images)
outputs = top_module(features)
# 计算损失
loss = loss_fn(outputs, labels)
val_loss += loss.item()
# 计算准确率
_, predicted = outputs.max(1)
correct += predicted.eq(labels).sum().item()
val_loss /= len(val_loader)
accuracy = correct / len(val_dataset)
# 打印验证信息
print(f'Validation Epoch: {
epoch+1}/{
epochs} '
f'Loss: {
val_loss:.4f} Accuracy: {
accuracy:.4f}')
# 保存模型
torch.save({
'backbone_state_dict': backbone.state_dict(),
'top_module_state_dict': top_module.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'epoch': epochs
}, 'pretrained_model.pth')
如何微调配置文件训练出优秀的模型呢
一开始肯定还是就用预训练模型默认的配置参数来训练,如果发现模型性能一般,再来考虑微调配置文件的事情
要修改配置参数以改善模型的性能,通常需要依据以下几个方面来进行判断和调整:
数据集特征
观察你的数据集的特点,包括图像的分辨率、颜色空间、目标类别的数量和类别之间的差异等。根据数据集的特征,你可以选择合适的主干网络、颈部和头部结构,以及相应的超参数。
- 图像分辨率:
图像分辨率指图像的像素大小,如224x224或384x384。高分辨率图像可以捕捉更多细节,但也需要更大的计算资源。低分辨率图像可能丢失一些细节,但计算效率较高。
示例:如果数据集包含高分辨率图像,可以选择主干网络和颈部结构,以处理细节丰富的图像。例如,选择ResNet-152主干网络和更大的颈部特征图尺寸。
- 颜色空间:
颜色空间指图像的颜色表示方式,如RGB、灰度等。不同的颜色空间可能对不同的任务有不同的影响。
示例:对于基于颜色信息的任务(如图像分类、目标检测),RGB颜色空间通常是首选。对于黑白图像,可以使用灰度颜色空间。
- 目标类别数量和差异:
数据集中目标类别的数量和类别之间的差异对模型设计和参数调整有重要影响。不同类别之间的差异性越大,模型可能需要更复杂的结构来处理这种差异。
示例:对于具有大量类别和差异较大的数据集,可以选择更深、更宽的主干网络,以便提取更丰富的特征。
- 数据集的样本均衡性:
数据集中类别样本的分布是否均衡也是影响模型设计和参数调整的重要因素。如果某些类别样本数量较少,模型可能倾向于更频繁地预测常见类别,导致性能偏差。
示例:对于不平衡的数据集,可以使用加权损失函数,增加少数类别样本的权重,以平衡训练过程。还可以考虑数据增强技术,增加少数类别的样本数量。
模型架构
理解模型架构的原理和设计思路。不同的模型架构适用于不同的任务和数据集。例如,对于目标检测任务,YOLOv3是一种常用的模型,它采用了特殊的特征提取和预测策略。根据你的任务需求,可以尝试修改模型的层数、通道数、注意力机制等。
- 模型架构原理:
模型架构是指模型的整体结构和组成部分,包括主干网络、颈部和头部等。每个部分都有特定的功能和设计原理,以实现特定任务的最佳性能。
主干网络负责从原始图像中提取高级特征,通常采用卷积神经网络(CNN)的形式。颈部和头部模块负责进一步处理和解释主干网络的特征,并产生最终的预测结果。
- 不同模型架构的适用性:
模型架构的选择取决于任务和数据集的特点。不同任务和数据集需要不同的特征表示和预测策略,因此适用的模型架构也会有所不同。
例如,对于图像分类任务,模型需要具备良好的特征提取能力,因此常见的选择是使用经典的卷积神经网络(如ResNet、VGG、Inception等)作为主干网络,然后使用全局平均池化和线性分类器作为颈部和头部。
对于目标检测任务,模型需要能够同时检测出物体的位置和类别。YOLOv3是一种常用的目标检测模型,它将图像划分为网格单元,并在每个单元预测多个边界框和类别概率。这种设计使得YOLOv3能够在保持较高检测速度的同时实现较高的准确率。
- 修改模型架构的关键参数:
修改模型架构时,关键参数包括层数、通道数、注意力机制等。
增加模型的层数可以增加模型的表示能力,但也会增加计算和内存需求。适当增加层数可以提高模型性能,但需要注意过拟合问题。
调整通道数可以控制特征图的维度和复杂性。增加通道数可以提升特征表示能力,但也会增加计算成本。适当调整通道数可以平衡性能和效率。
引入注意力机制可以提高模型对重要特征的关注程度,从而提升性能。注意力机制可以通过自注意力机制(如Transformer)、通道注意力机制(如SENet)等方式实现。
先前研究和经验
参考相关的研究论文、博客文章和经验总结,了解已经取得良好性能的模型和配置。可以借鉴他人的经验,尝试使用类似的配置或参数设置。
- 阅读相关研究论文:
通过阅读相关领域的研究论文,可以了解当前在特定任务上取得良好性能的模型和配置。论文通常会详细描述模型的架构和参数设置,以及在不同数据集上的实验结果。
示例:如果你正在处理图像分类任务,可以查阅领域内知名的图像分类论文,如ResNet、EfficientNet、ViT等。了解它们的架构设计、超参数设置以及在公开数据集上的表现。
- 参考博客文章和经验总结:
许多机器学习从业者会在博客文章或技术社区上分享他们的经验和实践。这些文章通常提供了有关模型配置、参数调整和技巧的宝贵建议。
示例:你可以搜索特定任务或模型的优化技巧,如"improve performance of object detection models"或"hyperparameter tuning for neural networks"。阅读这些文章可以获得实用的指导和建议。
- 实例分享和开源项目:
一些开源项目和平台提供了模型和配置的实例分享。这些实例可以帮助你了解在类似任务上取得良好性能的模型架构和参数设置。
示例:GitHub 上的开源项目、Kaggle 竞赛中的优胜解决方案、论坛上的分享等都是获取实例分享的良好途径。你可以参考这些实例,并根据自己的任务进行适当的调整。
超参数调优
超参数包括学习率、批量大小、权重衰减等。通过实验和验证集的性能表现,可以进行超参数的调优,选择最佳的配置。可以尝试使用学习率调度器、自适应优化器等技术来优化训练过程。
- 学习率调优:
学习率是控制模型参数更新幅度的重要超参数。合适的学习率可以加快模型收敛速度并提高性能,而不合适的学习率可能导致训练不稳定或陷入局部最小值。
常见的学习率调优策略包括学习率衰减、学习率预热、学习率自适应调整等。你可以尝试不同的学习率调度器,如StepLR、CosineAnnealingLR、ReduceLROnPlateau等,来动态地调整学习率。
- 批量大小:
批量大小是指在每次参数更新时使用的样本数量。较小的批量大小可以提高模型的收敛速度,但可能导致训练过程中的噪声增加。较大的批量大小可以减少噪声,但会占用更多的内存。
在选择批量大小时,需要考虑可用的硬件资源和内存限制。通常建议使用较大的批量大小,但要确保在硬件资源允许的范围内进行。
- 权重衰减:
权重衰减是一种正则化技术,用于减小模型参数的幅度,防止过拟合。通过在损失函数中添加权重衰减项,可以惩罚较大的权重值。
权重衰减的系数通常作为超参数进行调优。你可以尝试不同的权重衰减系数,如0.0001、0.001等,并观察模型在验证集上的性能表现。
- 自适应优化器:
传统的优化算法如随机梯度下降(SGD)具有固定的学习率和动量参数。然而,自适应优化器(如Adam、RMSprop)可以根据梯度的变化自动调整学习率和动量参数,以提高训练的效果。
使用自适应优化器时,你可以调整学习率、动量、权重衰减等参数,并观察模型在验证集上的性能。
实例示例:
假设你正在训练目标检测模型,你可以使用以下超参数配置来进行调优:
学习率:初始学习率设为0.001,然后使用学习率衰减策略,如每经过10个epoch,将学习率衰减为当前的一半。
批量大小:根据可用的硬件资源和内存限制,选择适当的批量大小,如32或64。
权重衰减:尝试不同的权重衰减系数,如0.0001或0.001,并选择在验证集上表现最好的值。
自适应优化器:使用Adam优化器,设置合适的初始学习率、动量参数和权重衰减系数,例如学习率为0.001,动量为0.9,权重衰减为0.0005。
通过实验和验证集的性能表现,你可以尝试不同的超参数配置,并选择在验证集上表现最佳的配置。可以使用交叉验证等技术来评估不同超参数配置的性能,并选择具有最佳性能的配置作为最终的选择。
需要注意的是,超参数调优是一个迭代的过程,需要根据实际情况进行多次实验和调整。此外,还可以考虑使用自动化超参数调优工具如Hyperopt、Optuna等来加速超参数搜索的过程。
迭代实验和评估
进行一系列实验和评估,观察模型在不同配置下的性能变化。使用合适的评估指标(如准确率、精确率、召回率、mAP等)来评估模型的性能,并根据评估结果进行调整和优化。
以下是一些详细解读和示例:
- 实验设计
确定实验的目标和评估指标。根据任务需求,选择适当的评估指标,如准确率、精确率、召回率、mAP(平均精度均值)等。确保评估指标能够全面反映模型在不同配置下的性能。
- 参数调整
根据先前的研究、经验和超参数调优的结果,选择一组初始配置参数。这些参数包括模型架构、超参数、优化器设置等。使用这组参数训练模型,并在验证集上评估性能。
- 性能评估
根据选定的评估指标,计算模型在验证集或测试集上的性能表现。观察指标的数值,并进行分析和比较。通过比较不同配置下的性能,找到性能最好的配置。
- 调整和优化
根据评估结果,分析模型在不同配置下的表现差异。如果模型在某些配置下表现较差,可以尝试调整相关参数,如增加网络层数、调整学习率衰减策略、更改数据增强方法等。重新训练模型并重新评估性能。
- 迭代实验
进行多次实验和评估的迭代过程。根据前一轮实验的结果,调整配置参数,并进行下一轮的训练和评估。通过不断迭代,逐步优化模型的性能。
示例:对于目标检测任务,你可以尝试不同的主干网络(如ResNet、EfficientNet等),调整网络的深度和通道数,尝试不同的检测头(如YOLO、SSD等),以及调整相关的超参数(如学习率、批量大小等)。通过训练和评估,比较不同配置下的mAP值,选择具有最佳性能的配置。
⚠️注意在修改参数时,建议遵循以下步骤:
- 确定目标和指标:明确你想要改进的目标和性能指标,例如提高分类准确率、加快模型推理速度等。
- 单一变量原则:在调整参数时,尽量只改变一个变量,保持其他参数不变。这样可以更好地理解每个参数的影响,并避免因多个参数同时变化而难以分析结果。
- 设定合理范围和步长:根据经验或先前研究,设定参数的合理范围和步长。避免设置过大或过小的步长,以免错过最优值或导致过度调整。
- 实验和评估:进行实验并评估模型的性能。使用验证集或交叉验证来评估模型在不同参数配置下的表现记录实验结果并进行统计和分析。比较不同参数配置下的性能指标,观察其变化趋势和影响程度。这样可以获得关于参数调整的定量和定性信息。
- 迭代和优化:根据实验和分析的结果,进一步调整参数。可以采用网格搜索、随机搜索、贝叶斯优化等方法来探索更广泛的参数空间,并找到更好的配置。
- 注意平衡:在调整参数时要注意平衡各个方面的性能和需求。例如,增加模型的复杂性可能会提高准确率,但也会增加计算和内存需求。因此,需要在模型性能和计算资源之间进行权衡,找到适合任务需求的最佳配置。