Meta公司宣布,将向研究人员开放一种新的“类人”人工智能模型的部分组件,该模型可以比现有模型更准确地分析和完成未完成的图像
Meta 宣布推出一个全新的 AI 模型 Image Joint Embedding Predictive Architecture (I-JEPA),可通过对图像的自我监督学习来学习世界的抽象表征,实现比现有模型更准确地分析和完成未完成的图像。目前相关的训练代码和模型已开源,I-JEPA 论文则计划在下周的 CVPR 2023 上发表

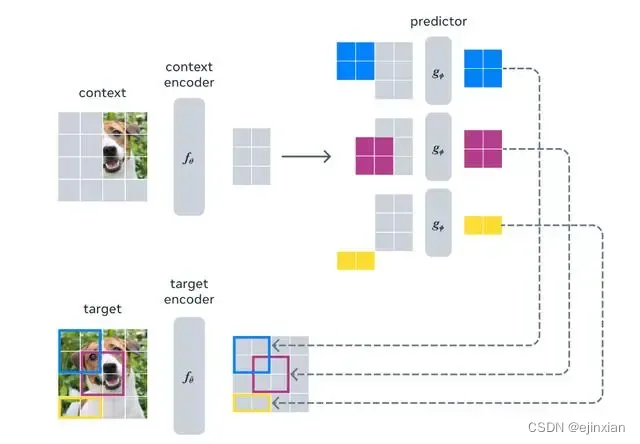
模型名为 I-JEPA,其利用对世界的背景知识来填补图像中缺失的部分,而不是像其他生成式人工智能模型那样,只根据附近的像素进行推断。这种方法采用了 Meta 公司首席人工智能科学家 Yann LeCun 倡导的类人推理方式,有助于避免人工智能生成图像中常见的错误,比如多出一根手指等问题
日前Meta方面还发布、并开源了音乐生成模型MusicGen。据悉,该模型由Meta研究科学家Gabriel Synnaeve领导的团队,目前用户可在Hugging Face上体验MusicGen,而且除了单一的文本提示词外,该模型还支持文本与旋律的组合输入。对此Gabriel Synnaeve表示,“我们公开发布代码和预训练模型,以供开放研究、可重复性和更广泛的音乐界研究这项技术”
自监督学习的通用架构,其中系统学习捕捉其输入之间的关系。目标是为不兼容的输入分配一个高能量,并为兼容的输入分配一个低能量。(a) 联合嵌入(不变)体系结构学习为兼容输入x、y输出相似嵌入,为不兼容输入输出不同嵌入。(b) 生成式架构学习从兼容信号x直接重构信号y,使用以附加(可能是潜在的)变量z为条件的解码器网络来促进重构。(c) 联合嵌入预测架构学习从兼容信号x中预测信号y的嵌入,使用以附加(可能是潜在的)变量z为条件的预测网络来促进预测。

参考:
Encord | Data-Centric AI Development Software for Computer Vision