低比特量化
一、 什么是量化
所谓的模型量化就是将浮点存储(运算)转换为整型存储(运算)的一种模型压缩技术。简单直白点讲,即原来表示一个权重需要使用float32表示,量化后只需要使用int8来表示就可以啦,仅仅这一个操作,我们就可以获得接近4倍的网络加速
量化并不是什么新知识,我们在对图像做预处理时就用到了量化。回想一下,我们通常会将一张 uint8 类型、数值范围在 0~255 的图片归一成 float32 类型、数值范围在 0.0~1.0 的张量,这个过程就是反量化。类似地,我们经常将网络输出的范围在 0.0~1.0 之间的张量调整成数值为0~255、uint8 类型的图片数据,这个过程就是量化
二、 为什么要进行量化
随着深度学习技术在多个领域的快速应用,具体包括计算机视觉-CV、自然语言处理-NLP、语音等,出现了大量的基于深度学习的网络模型。这些模型都有一个特点,即大而复杂、适合在N卡上面进行推理,并不适合应用在手机等嵌入式设备中,而客户们通常需要将这些复杂的模型部署在一些低成本的嵌入式设备中,因而这就产生了一个矛盾。为了很好的解决这个矛盾,模型量化应运而生,它可以在损失少量精度的前提下对模型进行压缩,使得将这些复杂的模型应用到手机、机器人等嵌入式终端中变成了可能。
随着模型预测越来越准确,网络越来越深,神经网络消耗的内存大小成为一个核心的问题,尤其是在移动设备上。通常情况下,目前的手机一般配备 4GB 内存来支持多个应用程序的同时运行,而三个模型运行一次通常就要占用1GB内存。
模型大小不仅是内存容量问题,也是内存带宽问题。模型在每次预测时都会使用模型的权重,图像相关的应用程序通常需要实时处理数据,这意味着至少 30 FPS。因此,如果部署相对较小的 ResNet-50 网络来分类,运行网络模型就需要 3GB/s 的内存带宽。网络运行时,内存,CPU 和电池会都在飞速消耗,我们无法为了让设备变得智能一点点就负担如此昂贵的代价。
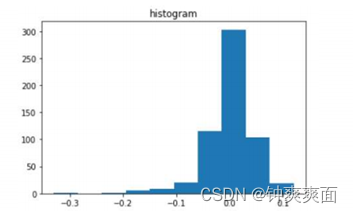
当然量化也有副作用,就是会降低推理精度。从下图可以看出,无论是表示范围还是精度,float32都远远高于int8。如果量化的不好会出现数据溢出和精度丢失,所以量化算法直接决定量化效果的好坏!

三、 量化的目的
加快推理速度、减少推理内存、减少模型文件存储空间
四、 量化方法的分类
(1) 训练后量化与量化感知训练
训练后量化(PTQ=Post-Training Quantization):
是指先用全精度float32数据训练好模型后,再将训练好的模型量化至int8;
量化感知训练(QAT=Quantization Aware Training)
是指在网络训练的过程中就插入量化模块,边训练边完成量化,从而让网络参数能更好地适应量化带来的信息损失。
• 相比来说,量化感知训练理论上精度更高,但是实现难度更大,而且使用操作更加复杂
(2) 对称量化与非对称量化
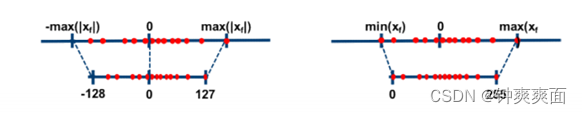
对称量化是将输入范围为 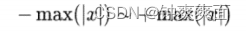
范围的浮点数沿着零点对称映射到 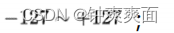
非对称量化将输入范围为 范围的浮点数映射到 ,在tflite里是[0,255],这个只差一个offset
相比来说,非对称量化理论上精度更高,但是实现难度更大。
(3) 线性量化与非线性量化
使用了线性函数 将进行Quantize和Dequantize转换映射,即线性量化;当然也可以
使用其他非线性函数转换(如 ),即非线性量化。
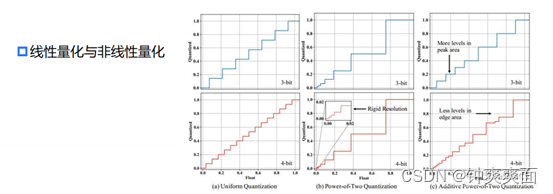
相比来说,非线性量化理论上精度更高(仍然实际不一定),但是实现难度更大,并且大部分的硬件都不支持非线性量化的推理,寄存器有限(分段量化系数)。
TensorRT与ncnn框架都选择了最简单粗暴的“训练后量化+对称量化+线性量化”方式,
五、 Ncnn与tensorrt中的量化方案
(1) 采用对称性量化*
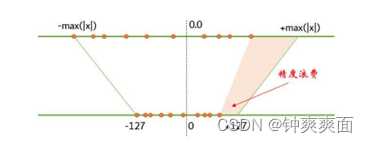
既然选择了对称量化+线性量化模式,享受简单粗暴优势的同时,精度也会有所牺牲。
将float32数据从 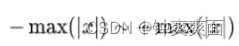
通过线性函数 
量化到 
的过程中,如果输入数据不是沿着零点对称分布,就必然会造成int8有一部会被浪费掉。由于int8数据本身就范围小,浪费太多必然导致量化精度急剧下降
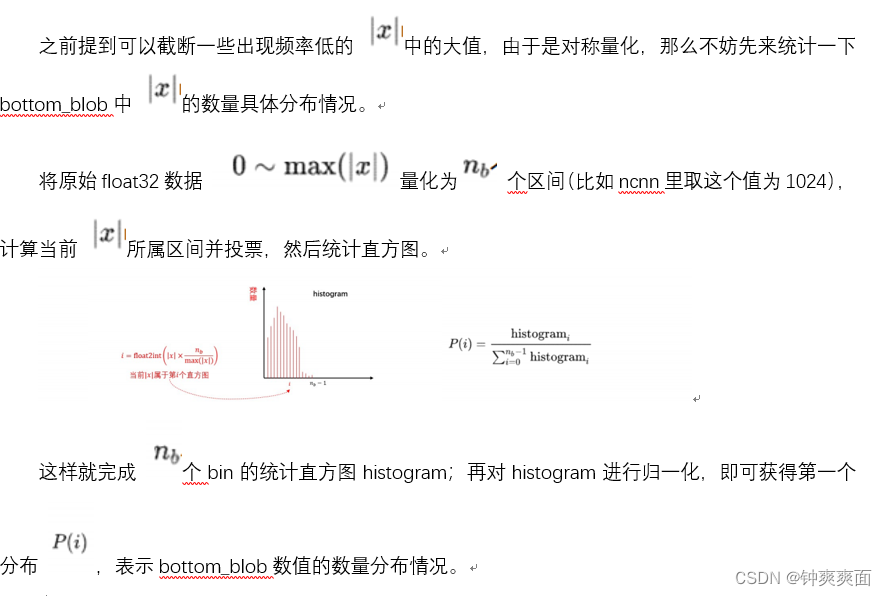
那么能否通过截断float32一部分数据,使得量化到int8尽量饱和?即由于卷积神经网络一般情况下特征值主要分布在零点附近,可以考虑截断一些出现频率低的 中的大值。所以可以考虑使用如下 进行量化:
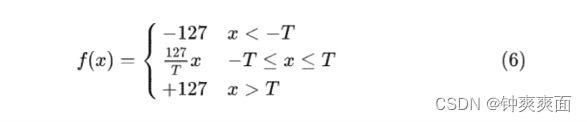
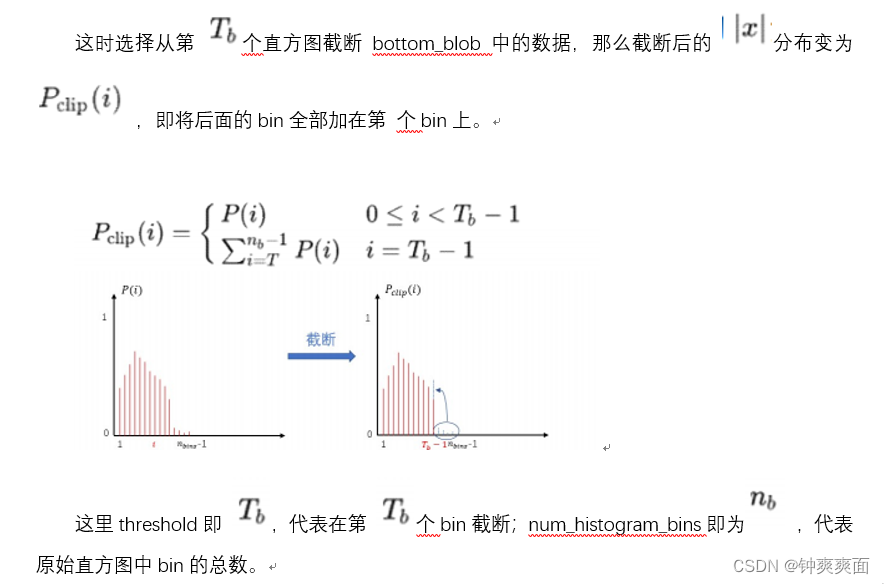
即大于 T的浮点数都量化为 127 ,小于 -T的都量化为 -127 。那么截断多少合适(即 T 如何选取)?
接下来分析ncnn如何建立数学模型解决这个问题
Kullback-Leibler散度:
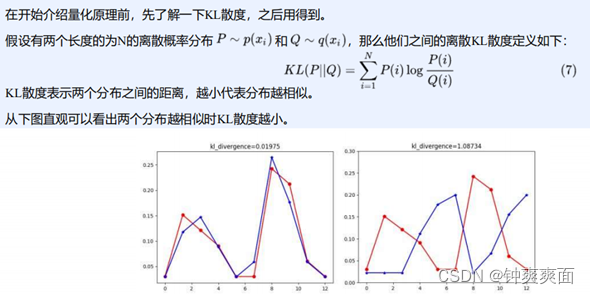
所以我们希望量化前和量化后的KL散度接近,不会相差太远,这样才能保证量化后的精度不会下降太多。
1、int8量化的数学模型建立
之前提到NCNN使用对称量化+线性量化,且会进行截断。那么从这三个关键词看看如何建立数学模型。
2、对称量化
3、截断
(2) 线性量化
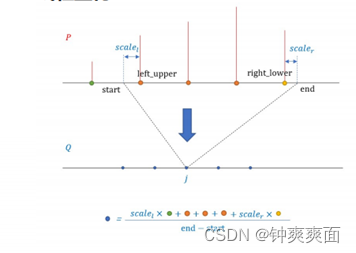
由于 代表原始float32数据截断后的分布情况, 代表原始float32数据量化为int8后的分布情况,我们希望两个分布越相似越好,也就是KL散度越小越好。这样就建立了数学模型,将如何量化的问题转化为通过选取 最小化 和 的KL散度值。

(3) Bottom_scale计算
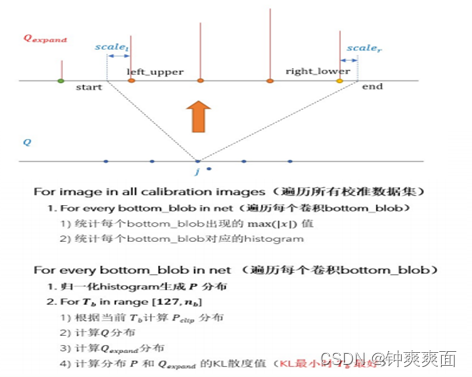
上文提到可以最小化 和 两个分布的KL散度值求解。但是需要注意,KL散度要求两个分布长度一致,但是 是一个长度为 的离散分布,而是一个长为128的离散分布。所以需要将 上采样成和 一样长的 ,然后再计算KL散度


需要注意 代表在截断bin的索引(也就是c++代码中的threshold),不是真正的阈值,所以获得 之后,按照如下公式转换为公式(6)中的截断 阈值,即bottom_scale计算完毕

(4) Weight_scale计算
之前已经计算完了bottom_blob的截断阈值,接下来还要计算所有卷积权重weight的的截断阈值。需要注意weight的截断阈值是一个数组。
卷积权重weight相比bottom_blob分布均匀且都在0点附近(不信你可以随便找个网络看看某层权重),不截断效果也还可以,所以对于权重的量化则比较简单:
推理计算weight卷积输出
统计输出每个通道的 
每个输出通道对应卷积核的量化权重为weight_scales[n]=127/ absmax
这样就获得了bottom_blob与weight的所有量化参数