作者:ZOMI酱
文章来源:https://zhuanlan.zhihu.com/p/453992336
1.1 神经网络模型量化概述
随着深度学习的发展,神经网络被广泛应用于各种领域,模型性能的提高同时也引入了巨大的参数量和计算量。模型量化是一种将浮点计算转成低比特定点计算的技术,可以有效的降低模型计算强度、参数大小和内存消耗,但往往带来巨大的精度损失。尤其是在极低比特(<4bit)、二值网络(1bit)、甚至将梯度进行量化时,带来的精度挑战更大。
这篇文章比较详细,所以下面这个图是这篇文章的一个整体目录。当然啦,除了非常多的文字,这篇文章塞了59个公式,涉及到量化在推理和训练的内容。虽然可能看得很辛苦,但是也希望可以多多支持ZOMI酱哈。打公式不容易,发现错误欢迎评论留言指正。
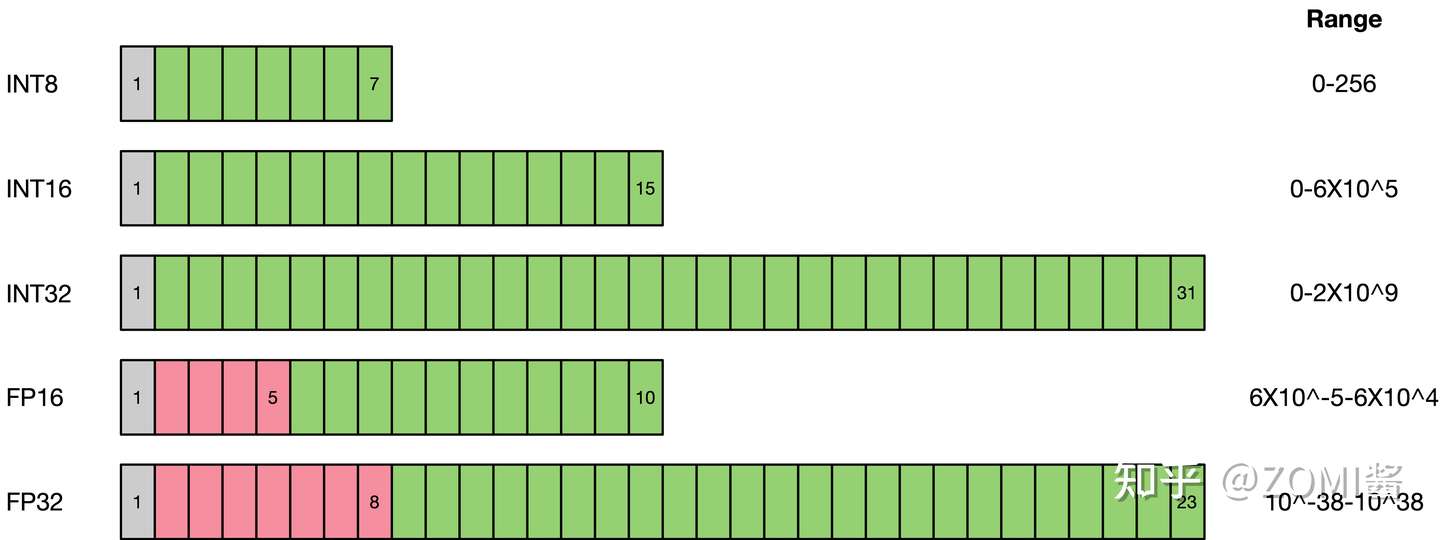
与FP32类型相比,FP16、INT8、INT4的低精度类型所占用空间更小,因此对应的存储空间和传输时间都可以大幅下降。以手机为例,为了提供更人性和智能的服务,现在越来越多的OS和APP集成了深度学习的功能,自然需要包含大量的模型及权重文件。以经典的AlexNet为例,原始权重文件的大小已经超过了200MB,而最近出现的新模型正在往结构更复杂、参数更多的方向发展。显然,低精度类型的空间受益还是很明显的。低比特的计算性能也更高,INT8相对比FP32的加速比可达到3倍甚至更高,功耗上也对应有所减少。
模型量化即以较低的推理精度损失将连续取值(或者大量可能的离散取值)的浮点型模型权重或流经模型的张量数据定点近似(通常为int8)为有限多个(或较少的)离散值的过程,它是以更少位数的数据类型用于近似表示32位有限范围浮点型数据的过程,而模型的输入输出依然是浮点型,从而达到减少模型尺寸大小、减少模型内存消耗及加快模型推理速度等目标。
首先量化会损失精度,这相当于给网络引入了噪声,但是神经网络一般对噪声是不太敏感的,只要控制好量化的程度,对高级任务精度影响可以做到很小。
其次,传统的卷积操作都是使用FP32浮点,浮点运算时需要很多时间周期来完成,但是如果我们将权重参数和激活在输入各个层之前量化到INT8,位数少了乘法操作少了,而且此时做的卷积操作都是整型的乘加运算,比浮点快很多,运算结束后再将结果乘上scale_factor变回FP32,这整个过程就比传统卷积方式快很多。
提前从体系结构的考量角度思考量化带来的另一个好处是节能和芯片面积,怎么理解呢?每个数使用了更少的位数,做运算时需要搬运的数据量少了,减少了访存开销(节能),同时所需的乘法器数目也减少(减少芯片面积)。
1.1.1 主要的量化方法
一边而言,量化方案主要分为两种:在线量化(On Quantization)和离线量化(Off Quantization),在线量化指的是感知训练量化(Aware Quantization),离线量化指的是训练后量化(Post Quantization)。训练量化根据名字的意思很好理解,其实就是在网络模型训练阶段采用量化方案进行量化。训练后量化中的量化方案跟训练并不相关,主要是在模型离线工具(模型转换工具的时候)采用量化方案进行量化。
- 感知量化训练(Aware Quantization)
实际上无论是Tensorflow、MindSpore、Pytroch的量化感知训练是一种伪量化的过程,它是在可识别的某些操作内嵌入伪量化节点(fake quantization op),用以统计训练时流经该节点数据的最大最小值,便于在使用端测转换工具(推理转换工具)的时候,转换成端侧需要的格式时进行量化使用。
目的是减少精度损失,其参与模型训练的前向推理过程令模型获得量化损失的差值,但梯度更新需要在浮点下进行,因而其并不参与反向传播过程。
某些操作无法添加伪量化节点,这时候就需要人为的去统计某些操作的最大最小值,但如果统计不准那么将会带来较大的精度损失,因而需要较谨慎检查哪些操作无法添加伪量化节点。
值得注意的是,伪量化节点的意义在于统计流经数据的最大最小值,并参与前向传播,让损失函数的值增大,优化器感知到这个损失值得增加,并进行持续性地反向传播学习,进一步提高因为伪量化操作而引起的精度下降,从而提升精确度。
值得注意的是,训练时候的原理与在端测推理的时候,其工作原理并不一致。
2. 训练后动态量化(Post Dynamic Quantization)
训练后动态量化是针对已训练好的模型来说的,针对大部分已训练,未做任何量化处理的模型来说均可用此方法进行模型量化。
其工作比较简单,在端测转换工具的时候,对网络模型的权重进行统计其每一层卷积的layer或者channel的最大值和最小值,然后通过量化公式对数据进行byte转换。这样得到的权重参数比以前小1/4。推理的时候,在内存初始化的时候对网络模型中的权重进行反量化操作变成float进行正常的推理。
3. 训练后校正量化(Post Calibration Quantization)
训练后静态量化,同时也称为校正量化或者数据集量化。其原理是对于Mindspore在端测低比特推理的时候(Inference),需要生成一个校准表来量化模型。这个量化校准表的生成需要输入有代表性的数据集,对于分类任务建议输入五百张到一千张有代表性的图片,最好每个类都要包括(即数据无偏)。
量化算法介绍
一般而言,无论per channel还是per layer量化方案,对于weight权重的量化使用对称量化,对于activate激活的量化使用非对称量化。
其原因是对于权重而言,其数据的分布为对称的如或,因此采用对称量化可以进一步有效降低计算量,使得数据分布更加符合其真实的分布;activate激活在网络中通常使用ReLU和ReLU6等作为网络模型的激活函数,其数据分布集中在或者,如果采用对称方案会加剧数据的离散程度,另外一个原理是会造成数据的浪费,如[-128,0]之间并不存储任何数据,只有[0,127]有数据分布。
下面以int8作为量化的标准,介绍一下两种量化算法的主要细节。
- 对称量化symmetry
对称的量化算法原始浮点精度数据与量化后INT8数据的转换如下:
其中,scale默认是float32浮点数,为了能够表示正数和负数,int采用signed int8的数值类型。通过将float32原始高精度数据转换到signed int8数据的操作如下,其中round为取整函数,量化算法需要确定的数值即为常数scale:
由于在神经网络的结构以层(Layer)来进行划分的,因此对权值和数据的量化可以层Layer为单位来进行,对每层Layer的参数和数据分别进行不同scale的量化。
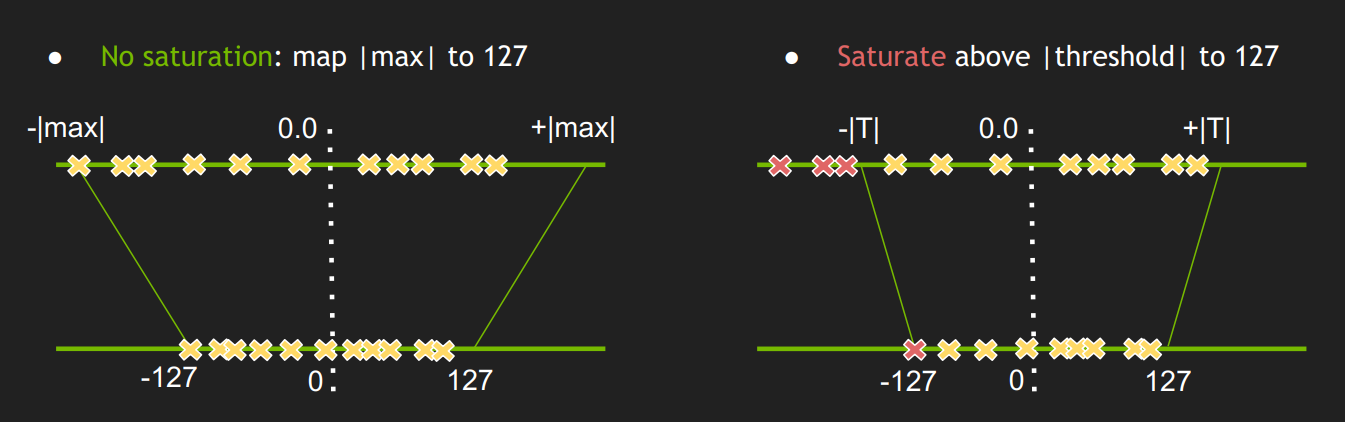
对权值和数据的量化可以归结为寻找scale的过程,由于int8为有符号数,要保证正负数值表示范围的对称性,因此对所有数据首先进行取绝对值的操作,使待量化数据的范围变换为,再来确定scale,其scale正确的计算公式为:
另外对于offset的计算公式为:
确定了scale之后,itn8数据对应的表示范围为 ,量化操作即为对待量化数据以
进行饱和式截断,即超过范围的数据饱和到边界值,然后进行第一条公式所示量化计算即可。
2. 非对称asymmetric
非对称的量化算法与对称的量化算法,其主要区别在于数据转换的方式不同,如下,同样需要确定scale与offset这两个常数:
确定后通过原始float32高精度数据计算得到uint8数据的转换即为如下公式所示:
其中,scale是float32浮点数,uint为unsigned INT8定点数,offset是int32定点数。其表示的数据范围为[ ]。若待量化数据的取值范围为
,则scale的计算公式如下:
offset的计算方式如下:
对于权值和数据的量化,都采用上述公式的方案进行量化, 和
为待量化参数的最小值和最大值,
和
为:
3. 量化初始化
在一般的端测推理的时候,由于网络模型的输入并没有伪量化节点记录输入tensor的最大值和最小值,因为无法求得量化参数scale和offset,这个时候推理框架许可要根据输入数据的标准差deviation和均值mean进行计算,得到对应的量化参数。
其中标准差Standard Deviation的计算公式为下:
其对应的scale为:
Offset的计算为:
值得注意的是,由于在其他端测推理框架(如tflite)需要手工输入标准差deviation和均值mean,容易导致对数据分析、数据输入的错误和框架的割裂,因此感知量化训练的时候会对模型的输入和输出加上fakeQuant伪量化节点,记录数据min和max,从而求得Mindspore端测用到input tensor的scale和offset。
1.1.2 感知量化训练
上面讲解了基本的量化公式和量化的方法,下面来详细展开感知量化训练(Aware Quantization)模型中插入伪量化节点fake quant来模拟量化引入的误差。端测推理的时候折叠fake quant节点中的属性到tensor中,在端测推理的过程中直接使用tensor中带有的量化属性参数。
- 伪量化节点
为量化节点(Fake Quant)的意义在于:
1)找到输入数据的分布,即找到min和max值;
2)模拟量化到低比特操作的时候的精度损失,把该损失作用到网络模型中,传递给损失函数,让优化器去在训练过程中对该损失值进行优化。
a. 基本原理
低比特量化模型运行时,需要确定scale与offset两个量化参数:
其中,是float32浮点数,uint8为unsigned int定点数,offset是int32定点数。其表示的数据范围为:
若待量化数据的取值范围为[a,b],则scale和offset的计算方式如下:
对于权值和数据的量化,都采用上述公式的方案进行量化,min和max为待量化参数的最小值和最大值。
前面呢,曾经提到一般而言,权重数据是对称,为了可以进一步减少数据的计算,较少额外的存储数据,因此推荐使用对称的量化算法。但是在对mobieNetV2,mobileNetV3的实际测试开发的过程中,发现数据大部分是有偏的,例如mobileNetV2中:
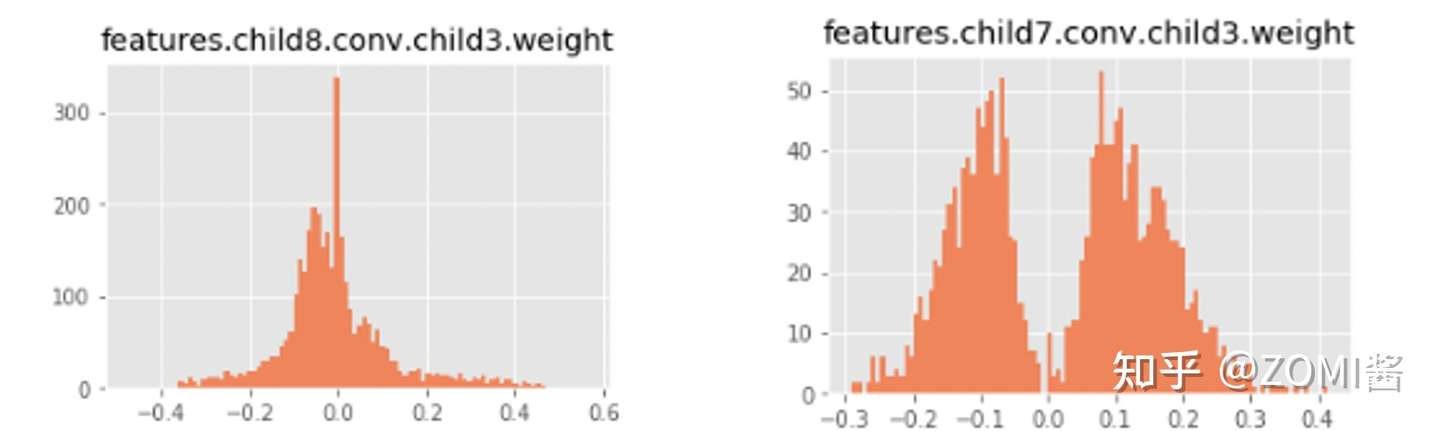
此时权重对应的数据并不是以0为中心点对称,featture.child8.conv.child3.weight的权重数据分布范围是,为了更好地拟合更多的数据,对更多的数据具有更好的泛化性,因此统一使用了非对称的量化算法。
b. 正向传播
为了求得网络模型tensor数据精确的Min和Max值,因此在模型训练的时候插入伪量化节点来模拟引入的误差,得到数据的分布。对于每一个算子,量化参数通过下面的方式得到:
Fake quant节点的具体计算公式为:
为了更好地表示上面公式的作用,正向传播的时候fake quant节点对数据进行了模拟量化规约的过程,如下图所示:
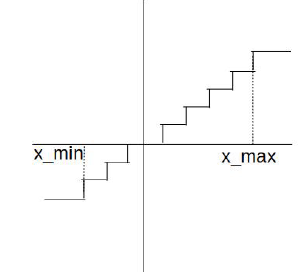
首先对数据根据min和max值进行截断,然后把float数据转换成为int数据,之后再把int数据重新转换成为float数据,该操作会丢失掉float1与float2转换之间的精度差。对于量化感知训练,通过模拟量化操作时候对数据进行规约操作,所以网络模型中每一个tensor数据可以根据下面公式进行封装成为op,得到:
c. 反向传播
按照正向传播的公式,如果方向传播的时候对其求导数会导致权重为0,因此反向传播的时候相当于一个直接估算器:
最终反向传播的时候fake quant节点对数据进行了截断式处理,如下图所示:
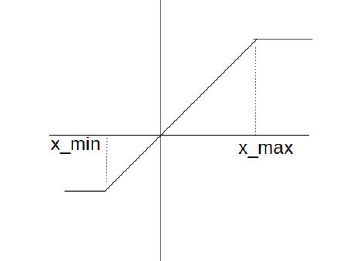
d. 更新Min和Max
FakeQuant伪量化节点主要是根据找到的min和max值进行伪量化操作,更新min和max分别为running和moving,跟batch normal算子一样,这里不进行过多的讲述,具体在Mindspore框架中会自动根据网络模型的结构进行自动插入不同的形式,具体用户不感知。
running minimum的计算公式为:
Running maximum的计算公式为:
Moving minimum的计算公式为:
Moving maximum的计算公式为:
2. BN折叠
初步实施方案中构图比较复杂的主要集中在如何拆分BN层,本节将会对拆分的原理进行细化,落实确定到每一个算子上面,包括每个算子的具体计算公式,控制原理。
a. BN Fold原理
基本卷积操作为:
经过BN层处理后:
拆分上式得到:
定义:
因此conv+batch normal两个算子在推理的时候,合起来融合为一个conv算子:
网络模型中经常使用BN层对数据进行规约,有效降低上下层之间的数据依赖性。然而大部分在推理框架当中都会对BN层和卷积操作进行融合,为了更好地模拟在推理的时候的算子融合操作,这里对BN层进行folding处理。下面左边图是(a)普通训练时模型,右边图是(b) 融合后推理时模型。
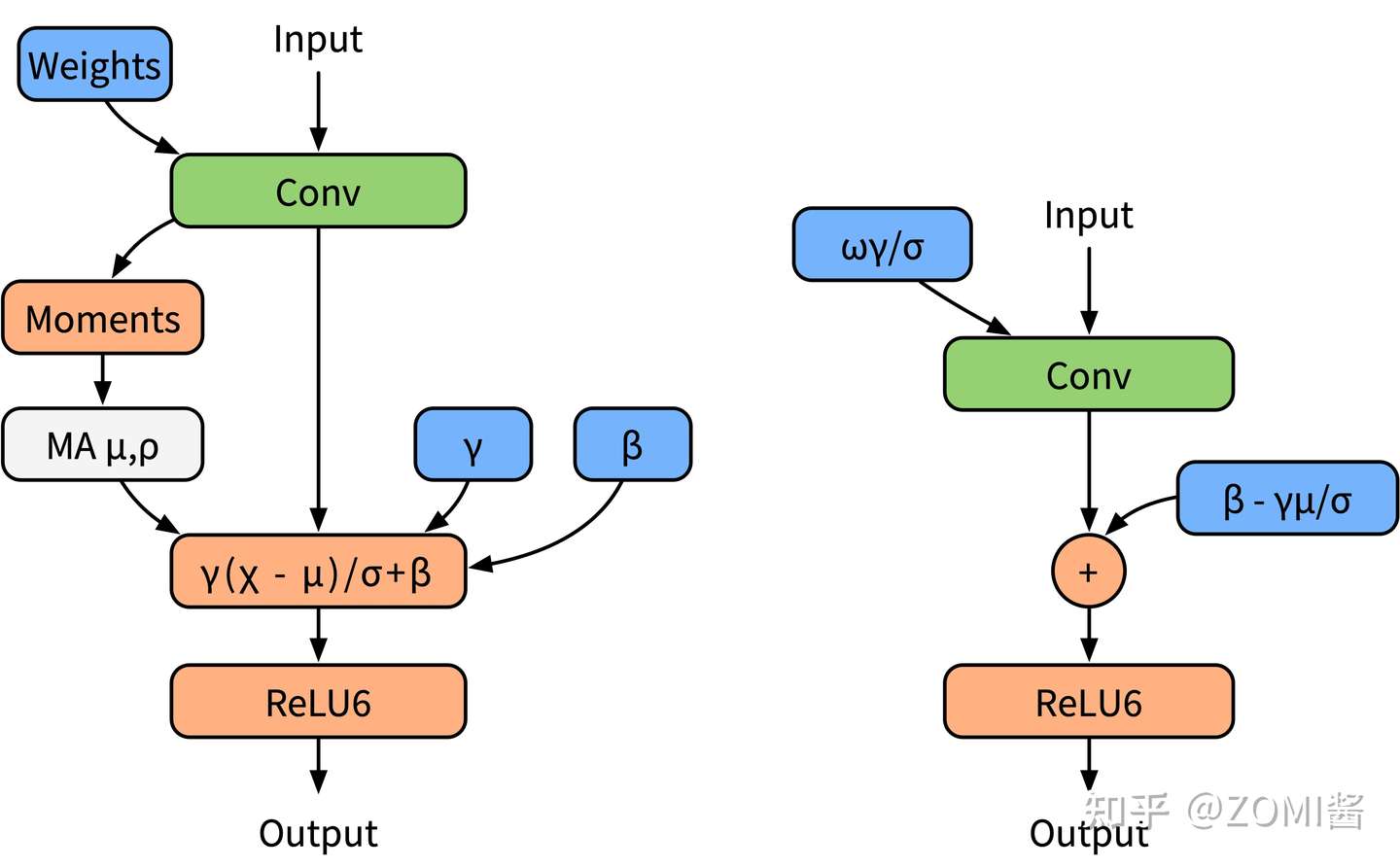
下面图中左边是BN折叠的BN folding训练模型,右边是BN folding感知量化训练模型。
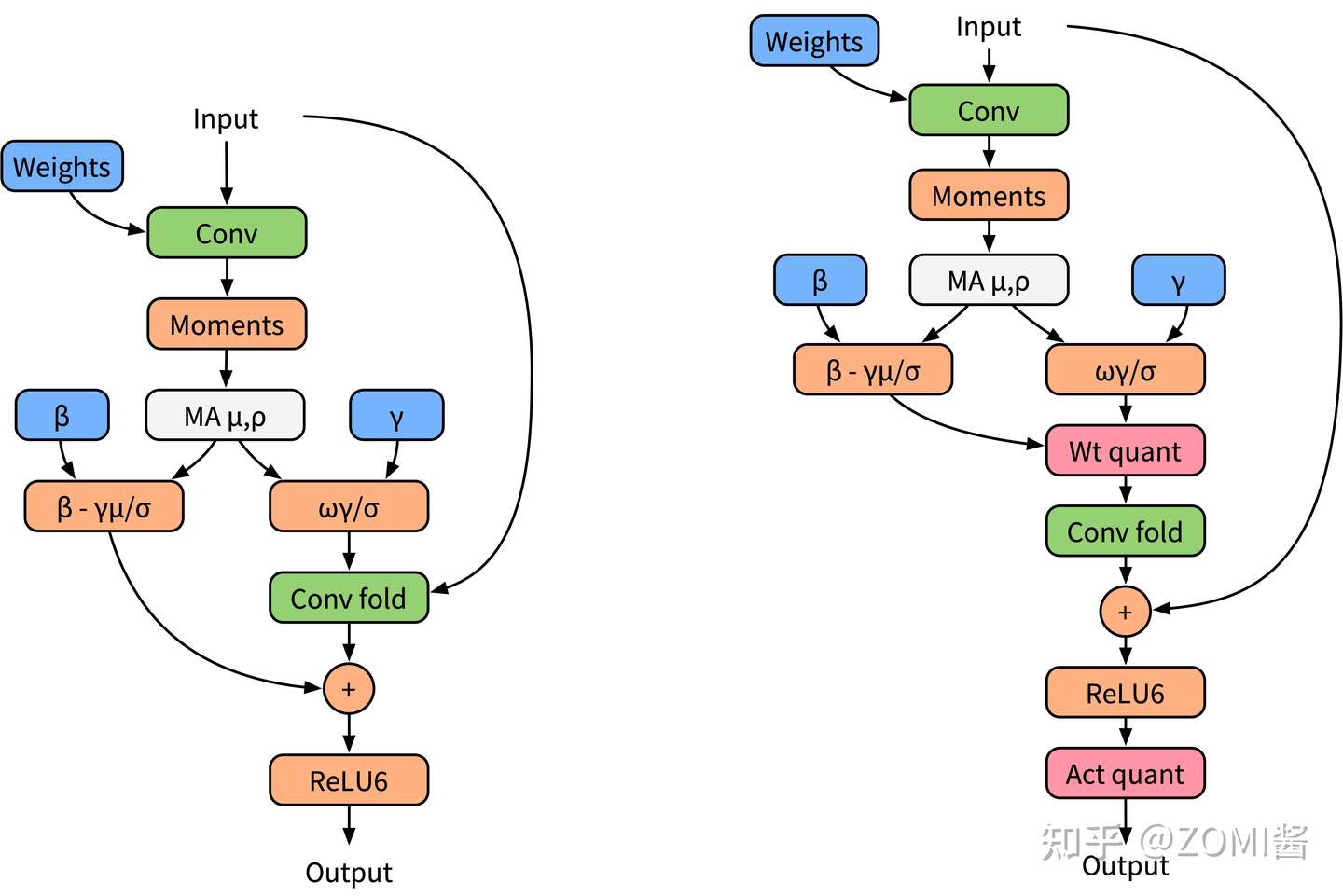
b. Correction数据矫正
- 贝塞尔矫正(Bessel Correction)
在计算方差的时候,论文并没有提及贝塞尔校正,因为贝塞尔校正是通用的统计学方法,用于校正方差。
具体对应于样本标准差为:
贝塞尔校正的样本标准差为:
因此对应贝塞尔因子为:
- Batch Normal矫正
由于每次更新batch参数的delta的时候,都是使用当前batch的统计数据,这会使得权重参数连带着一起被当前的batch影响,为了避免当前权重数据w的抖动,加入correction的校正因子将权重缩放到长期batch统计数据中。
模型开始训练的时候会在fold conv卷积的输出除以correction因子,这样的操作是为了让模型直接去学习正常的BN操作(根据当前的batch进行学习),在学习到一定程度之后,冻结当前的BN不再更新全局delta,然后fold conv卷积的操作中直接作用,并同时修改bias,作为correction_2更新到ADD算子中。
Frozen前:
Frozen后:
加上correction能够有效地抑制在后期阶段weight的数据波动。
c. BN FOLD训练图
- 算子
组合模式ConvD+BN+ReLU拆分子图并加入FakeQuant算子,一共拆分为为以下几个算子:Conv2D、BatchNormFold、CorrectionMul、MulFold、FakeQuantWithMinMaxPreChannel、ConvMul、CorrectionAdd、AddFold、ReLU、FakeQuantWithMinMax。
1) Conv2D (in: x, weight; out: y):普通卷积,用于计算BatchNormFold的入参:
2) BatchNormFold ( ):FoldBN,用于计算当前
和
,并使用CMA算法更新
和
,运行时使用
和
。该算子输出
并不作用于网络,因此该算子实际计算公式为更新
:
3) CorrectionMul ( ):对w乘以校正因子。由于每次更新batch参数的
的时候,都是使用当前batch的统计数据,这会使得权重参数连带着一起被当前的batch影响,为了避免当前权重数据w的抖动,加入correction校正因子将权重缩放到长期batch统计数据中:
4) MulFold ( ):根据batch mean参数对w进行规约,模拟融合操作:
5) FakeQuantWithMinMaxPreChannel (in: w, delay; out: self):控制流delay,训练模型中插入伪量化节点fake quant来模拟量化引入的误差,推荐权重按PerChannel模式。
6) Conv2D (in: w, x, out:x):实际作用的卷积:
7) ConvMul ( ):控制流freeze,模型开始训练的时候会在fold conv卷积的输出除以correction校正因子,这样的操作是为了让模型直接去学习正常的BN操作(根据当前的batch进行学习);在学习到一定程度之后,冻结当前的BN不再更新全局。
8) CorrectionAdd ( ):控制流freeze,在学习到一定程度之后冻结当前BN,校正因子修正bias偏置。
9) AddFold ( ):作用于bias偏置,BN融合后剩余参数作用于bias偏置:
10) ReLU (in:x, out: x):实际作用的激活函数;
11) FakeQuantWithMinMax(in:x, min, max, delay; out: x):控制流delay,训练模型中插入伪量化节点fake quant来模拟量化引入的误差,并用指数移动平均算法更新min和max:
- 正向图
下面左边为原始设计bn折叠训练图,右边是实际Mindspore执行经过优化融合的训练图。
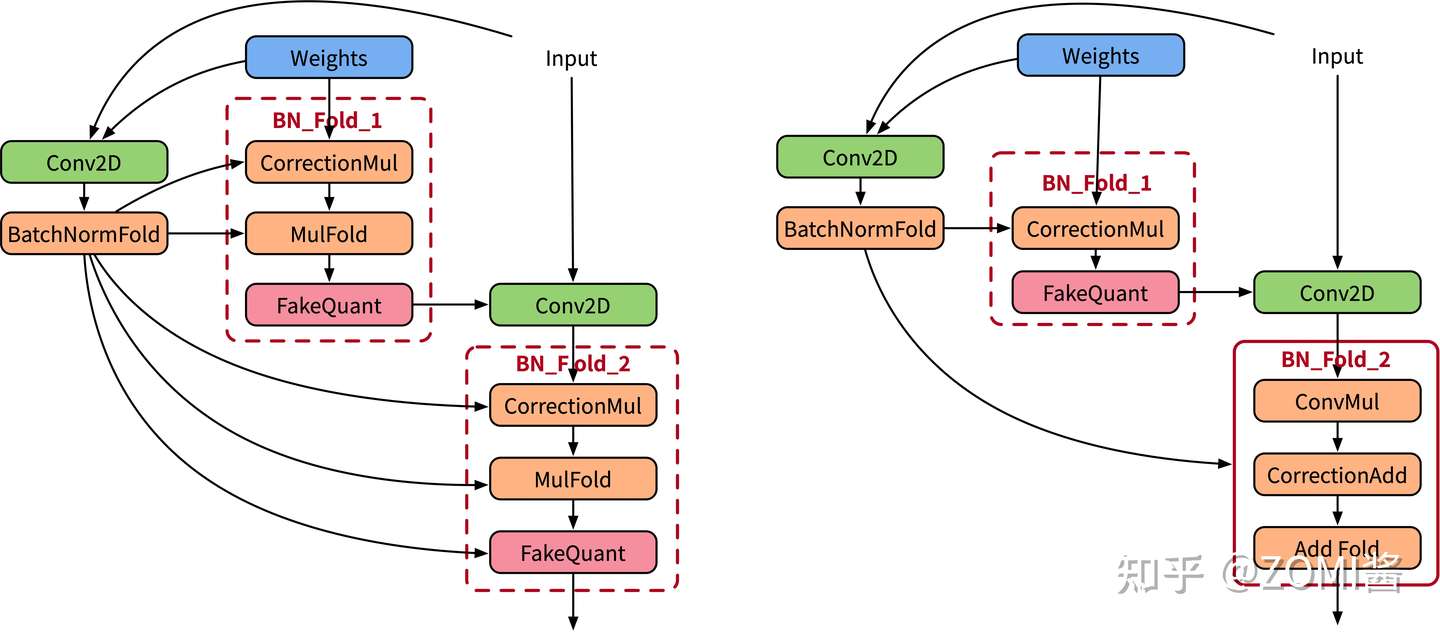
图中主要注意的点为BN_Fold_1和BN_Fold_2,其中BN_Fold_1的作用有两个:拆分融合的BN层对weight的影响,和对权重数据进行校正;BN_Fold_2的作用有两个:拆分融合的BN层对bias的作用影响,和对bias数据进行校正。
d. BN FOLD推理图
- 算子
组合模式ConvD+BN+ReLU拆分子图并加入FakeQuant算子,一共拆分为以下个算子:Conv2D、BatchNormFold、MulFold、FakeQuantWithMinMaxPreChannel、AddFold。
1) Conv2D (in: x, weight; out: y):普通卷积,用于计算BatchNormFold的入参:
2) BatchNormFold ( ):开根号作用:
3) MulFold ( ):根据BN参数对w进行规约,模拟融合操作:
4) FakeQuantWithMinMaxPreChannel (in: w, delay; out: self):训练模型中插入伪量化节点fake quant来模拟量化引入的误差,推荐权重按PerChannel模式。
5) Conv2D (in: w, x, out:x):实际作用的卷积:
6) AddFold ( ):作用于bias偏置,BN融合后剩余参数作用于bias偏置:
- 验证图示例
正向推理验证图,上面的所有公式都会化为这个图的实际计算方式。
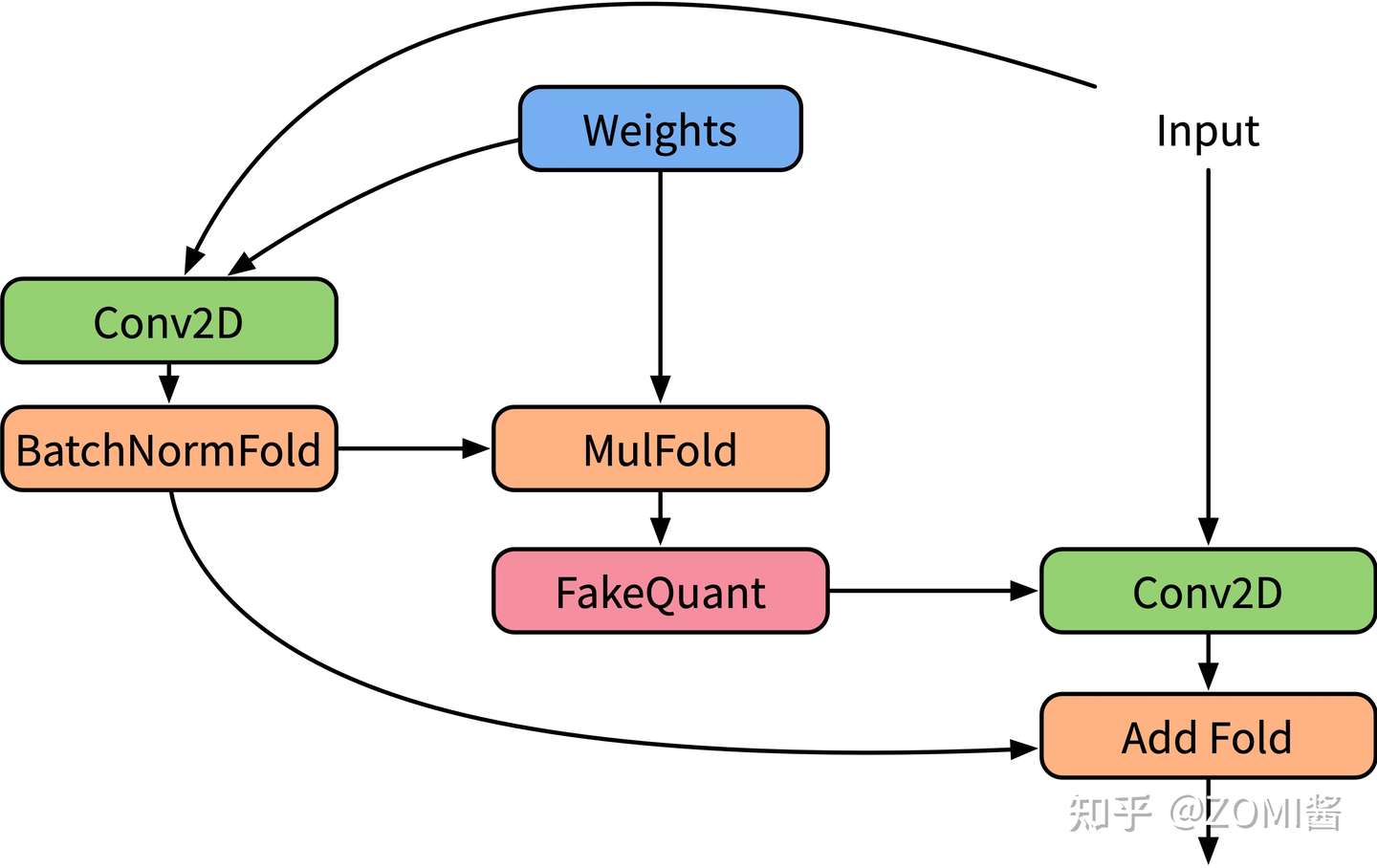
1.1.3 训练后量化
训练后静态量化(Post Calibration Quantization),同时也称为校正量化或者数据集量化。其原理是对于Mindspore在端测低比特推理的时候(Inference),需要生成一个校准表来量化模型。其核心是取得数据值的量化参数表。
1. 权值量化
权值在进行推理加速时均已确定,因此不需要对权值进行校准。如果使用对称量化方案,max使用权值的绝对值的最大值,对于非对称量化算法,max和min使用权值的最大值和最小值。
根据算法验证结果,对于Convolution,每个卷积核按照per channel的方式采用一组独立的量化系数(scale和offset),量化后推理精度较高。因此,Convolution权值的量化根据卷积核数量分组进行,计算得到的scale和offset的数量与卷积核数量相同。Dense的权值使用一组scale和offset。
2. 数据量化
数据量化是对每个要量化的Operation的输入数据进行统计,每个Operation计算出最优的一组scale和offset。
数据是推理计算的中间结果,其数据的范围与输入高度相关,需要使用一组参考输入作为激励,得到每个Operation的输入数据用于确定量化max和min。数据的范围与输入相关,为了使确定的min和max在网络接收不同输入时有更好的鲁棒性,因此提出基于统计分布确定min和max的方案。
该方案的思路为最小化量化后数据的统计分布与原始高精度数据的统计分布差异性,操作流程如下:
- 使用直方图统计的方式得到原始float32数据的直方图统计分布;
- 在给定的min和max搜索空间中选取若干个和分别对待量化数据进行量化,分别得到量化后的数据;
- 使用同样的直方图统计的方式得到n个的直方图统计分布;
- 分别计算中每个与的统计分布差异性,找到差异性最低的一个对应的min和max作为确定的量化数值。
在上述操作中,涉及的超参数包括进行直方图统计时选取的直方图bin个数、min和max的搜索空间、统计分布差异性的指标。
对于直方图bin个数,该参数直接反应了直方图统计特征的分布数个数,由于数据经过量化后会集中到256个离散的点上,因此bin的个数不宜过大,否则绝大多数的bin都没有数值。
max的搜索空间可以通过search_start_scale,search_end_scale与search_step来确定。
- search_start_scale为搜索空间起始点与search_value的比值。
- search_end_scale为搜索空间结束点与search_value的比值。
search_step为搜索空间中每次搜索的值与seach_value的比值步进值。以max_candidate=100,search_start_scale=0.8,search_end_scale=1.2,search_step=0.01为例,对称量化算法下,其定义的max搜索空间为从100*0.8=80到100*1.2=120的范围,每次步进100*0.01=1,一共41个d_max搜索值;非对称量化算法下,搜索0.8*(max–min) ~ 1.2*(max–min),确定最好的一个系数。
继续举多一个例子, search_start_scale =0.3,search_step=0.01,search_end_scale==1.7,bin=150。需要在0.3*max~1.7*max这个范围中找一个最好的max,搜索步长是0.01max,因此需要搜索(1.7-0.3)/0.01 + 1 = 141个max数值。直方统计的bin个数也可以设置,假设当前是150。对于算法方案一,将0-2*max的数据分为150段,统计数据落在每段中的频率,使用数据的绝对值统计,对于算法方案二,在0.3*(max – min)~1.7*(max - min)这个范围中找一个最好的ratio,将0-2*(max - min)的数据分为150段,统计数据落在每段中的频率,使用data – min的值来统计频率。141个数值都要统计,因此一个量化算子需要存储141*150个数值。多个batch情况下对frequancy进行累加。
统计分布差异性的指标为计算两个长度为n直方图、分布之间的信息差异度,选取的指标包括如下三种:
1) Kullback-Leibler Divergence(KL散度)计算方式如下:
2) Symmetric Kullback-Leibler Divergence(对称KL散度):对于 、
两个分布,
相对
与
相对
的KL Divergence是不同的,Symmetric KL Divergence的计算方式为
相对
与
相对的KL Divergence的均值,计算方式如下:
3) Jensen-Shannon Divergence(JS散度):首先生成一个新的分布M,为与的均值,JS Divergence为相对M的KL Divergence与相对M的KL Divergence的均值, 计算方式如下:
3. Calibration流程
a. Calibration功能
离线Calibration需要完成以下功能:
- 对算子的输入数据量化校准,计算出数据的最优scale和offset;
- 将算子的权值量化为INT8,计算出权值的scale和offset。
- 将算子的bias量化为INT32。
- 由于算子输入数据在推理过程中才能产生,因此离线Calibration还要实现inference功能。与普通inference过程的不同之处在于对每个需要量化的op的输入数据和权值数据进行了量化和反量化过程。
b. Calibration过程
Calibration过程可以分为4步:
- 遍历graph中的node,对需要量化的算子的权重进行量化。
- 第一次inference,搜索需要量化的算子的输入数据的max和min。
- 第二次inference,进行数据的直方统计。
- 计算分布差异性能指标(见4.2),根据指标选择最好的min和max,然后计算出数据的scale和offset,根据数据和权值的scale,进行bias量化。
值得注意的是,min不一定是所有数据batch中的最小值,max也不一定是所有batch中的最大值,与min_percentile和max percentile的值相关。
假设每个batch处理10张图片,共100个batch,某个op的1张图片输入数据是1000个数,max_percentile = 0.99999,数据总量是10*100*1000 = 1000000个数。1000000*0.99999 = 999990。把所有输入数据从大到小排序,max取第10个数。因此需要缓存10个数,对第一个batch的输入1000个数进行从大到小排序,取前10大的数进行缓存,第二个batch的输入1000个数进行从大到小排序,取前10个数,与缓存的10个数共20个数进行排序,取前10大的数,以此类推,最终获得所有batch数据中前10大的数。
Inference有两种方式,第一种是数据不做量化进行推理,第二种是数据量化后进行推理。数据量化是指算子的当前batch输入数据使用当前batch的max和min进行量化,将数据量化为INT8,再由INT8转回FP32进行inference计算。
第二次inference,进行数据的直方统计。根据第2步已经根据max_percentile找到需要的max的值。
最后,计算分布差异指标,根据指标选择最好的min和max,然后计算出数据的scale和offset,根据数据和权值的scale,进行bias量化。
c. 搜索空间
影响搜索空间的参数可以分为两类:一类是增加搜索组合的数量的可以称之为配置参数,一类是影响单个模型结果的称之为超参数(不增加结果数量)。
1.1.4 端测量化推理
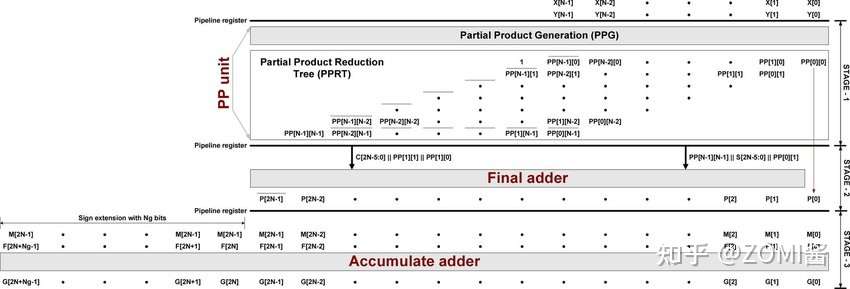
端侧量化推理的结构方式主要由3种,分别是下图的(a) Fp32输入Fp32输出、(b) Fp32输入int8输出、(c) int8输入int32输出。
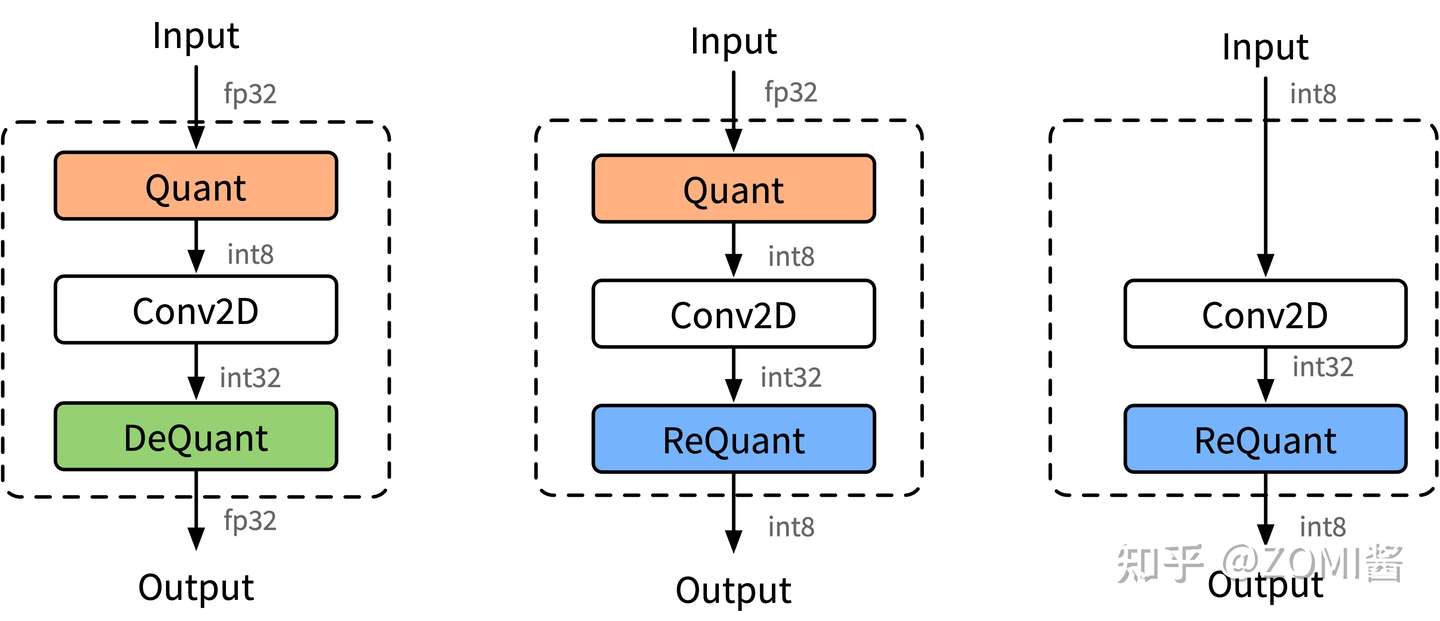
INT8卷积示意图,里面混合里三种不同的模式,因为不同的卷积通过不同的方式进行拼接。

使用INT8进行inference时,由于数据是实时的,因此数据需要在线量化,量化的流程如图所示。数据量化涉及Quantize,Dequantize和Requantize等3种操作。
1. Quantize量化
将float32数据量化为int8。离线转换工具转换的过程之前,计算出数据量化需要的scale和offset,如果采用对称量化算法,则根据公式4进行数据量化,如果采用非对称量化算法,则根据本文公式6进行数据量化。
2. Dequantize反量化
INT8相乘、加之后的结果用INT32格式存储,如果下一Operation需要float32格式数据作为输入,则通过Dequantize反量化操作将INT32数据反量化为float32。
Dequantize反量化推导过程如下:
因此反量化需要input和weight的scale。值得注意的是,后面实际的公式约减了 、
和
,是因为在实际网络的运行和测试过程结果表明,发现这两个参数对网络模型的精度并不影响,其作用相当于bias add,因此故作减约。
3. Requantize重量化
INT8乘加之后的结果用INT32格式存储,如果下一层需要INT8格式数据作为输入,则通过Requantize重量化操作将INT32数据重量化为INT8。
重量化推导过程如下:
其中y为下一个节点的输入,即 :
有:
因此重量化需要本Operation输入input和weight的scale,以及下一Operation的input输入数据的scale和offset。
4. Conv2d的INT8计算
计算公式如下:
其中,P为与w矩阵相同大小的全1矩阵,Q为与x矩阵相同大小的全1矩阵
其中, 是量化后INT8权值,
是量化后INT8数据,
是量化后INT32的bias。
c3项可以在离线时计算好,作为新的bias参数传入。c1和c2项需要在线计算。Conv2d的INT8计算根据输入是float32还是int8决定是否需要插入Quantize OP,根据输出是float32还是int8决定输出是插入Dequantize OP还是Requantize OP。