模型量化的原理与实践 ——基于YOLOv5实践目标检测的PTQ与QAT量化
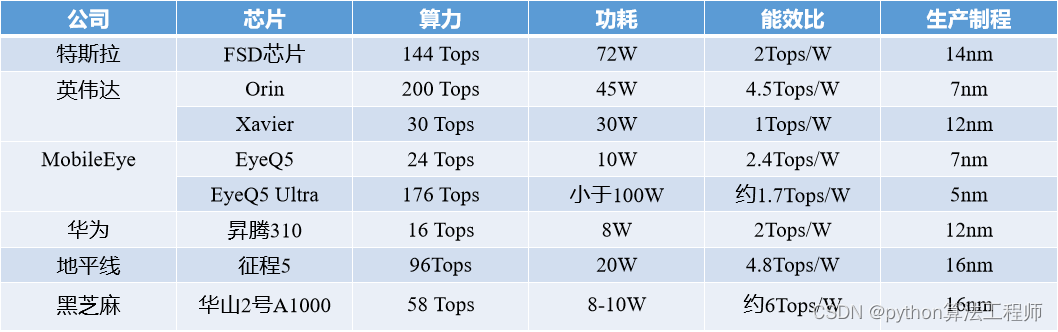
1、Tops是什么意思?
1TOPS代表处理器每秒可进行一万亿次(10^12)操作
3、什么是定点数
大家都知道,数字既包括整数,又包括小数,如果想在计算机中,既能表示整数,也能表示小数,关键就在于这个小数点如何表示?
于是计算机科学家们想出一种方法,即约定计算机中小数点的位置,且这个位置固定不变,小数点前、后的数字,分别用二进制表示,然后组合起来就可以把这个数字在计算机中存储起来,这种表示方式叫做定点表示法,用这种方法表示的数字叫做定点数。
也就是说「定」是指固定的意思,「点」是指小数点,所以小数点位置固定的数即为定点数。
定点数的表示方式如下:
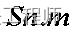
其中S表示有符号(Signed),n和m分别代表定点数格式中的整数和小数位数,但是考虑到二进制的补码形式表示负数,总的位数为n+m+1,比如S2.13比对应n=2,m=13,二进制的长度为n+m+1=16,也就是说用的16位的定点化表示。
4、定点数转换
定点数转换涉及将实数值转换为定点数值或将定点数值转换为实数值。
实数转换为定点数
将实数转换为定点数需要确定小数点的位置和位数,以及表示范围和精度。
例如,将实数3.1415926转换为小数点位置在第三位上、精度为0.01的定点数,需要先将实数乘以100,得到314.15926,然后将其四舍五入为314,最后加上小数点,得到3.14,即表示3.1415926的定点数值。
定点数转换为实数
将定点数转换为实数需要根据小数点位置和位数进行反向计算。
例如,将小数点位置在第三位上、精度为0.01的定点数3.14转换为实数,需要先将定点数除以100,得到0.0314,然后将其加上小数点后面的数字乘以相应的精度,得到3.1414,即表示定点数3.14对应的实数值。
在实际应用中,定点数转换常用于数字信号处理、嵌入式系统、计算机图形学等领域。对于一些特殊的应用场景,也可以采用其他定点数表示方式,如Q格式、S格式等。
2、什么是量化?
模型量化是指将深度学习模型中的浮点数参数和计算操作转换为定点数参数和计算操作的过程。模型量化可以减小模型的存储空间和计算量,提高模型在移动设备和嵌入式系统上的部署效率。
在模型量化中,浮点数参数和计算操作被转换为定点数参数和计算操作。定点数通常采用8位整数或16位整数表示,可以使用卷积、矩阵乘法等计算操作进行模型推理。
模型量化的过程通常包括以下几个步骤:
选择量化方法,包括权重量化、激活量化、全精度量化、混合精度量化等。
确定量化参数,包括量化位数、缩放因子、偏置等。
进行模型量化,包括权重量化、激活量化、计算操作量化等。
对量化后的模型进行微调,以保证模型精度。
模型量化可以大幅度减小模型的存储空间和计算量,使得模型可以在移动设备和嵌入式系统上高效部署。但是,模型量化可能会引入一定的精度损失,因此需要在精度和效率之间进行平衡,选择合适的量化方法和参数。
2、量化有什么优缺点
作用:将FP32的浮点计算转化为低bit位的计算,从而达到模型压缩和运算加速的目的。比如int8量化,就是让原来32bit存储的数字映射到8bit存储。int8范围是[-128,127](实际工程量化用的时候不会考虑-128), uint8范围是[0,255]。
模型量化优点:
- 加快推理速度,访问一次32位浮点型可以访问4次int8整型,整型运算比浮点型运算更快;
- 减少存储空间,在边缘侧存储空间不足时更具有意义;
- 减少设备功耗,内存耗用少了推理速度快了自然减少了设备功耗;
- 易于在线升级,模型更小意味着更加容易传输;
- 减少内存占用,更小的模型大小意味着不再需要更多的内存;
模型量化缺点:
6. 模型量化增加了操作复杂度,在量化时需要做一些特殊的处理,否则精度损失更严重;
7. 模型量化会损失一定的精度,虽然在微调后可以减少精度损失,但推理精度确实下降;
模型量化算法
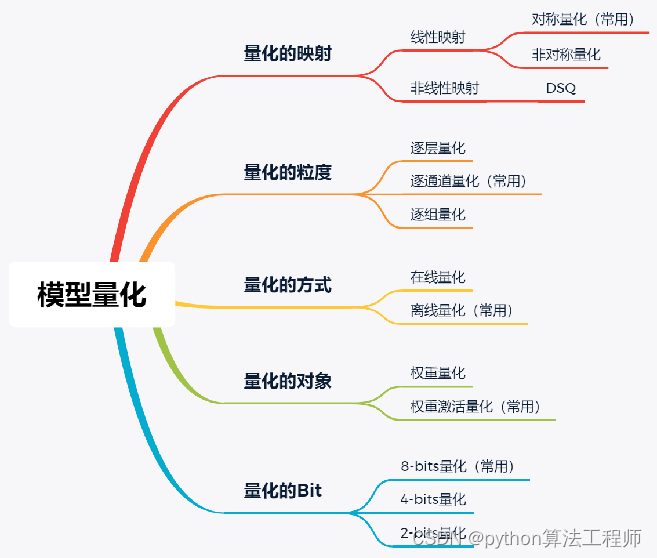
仿射映射量化
**
**至于模型的量化映射方式,如上图所示可以分为线性映射和非线性映射,对于线性映射又可以分为对称量化和非对称量化。
由于实际项目中基本不会使用非线性量化,本次课程不对非线性量化进行介绍。
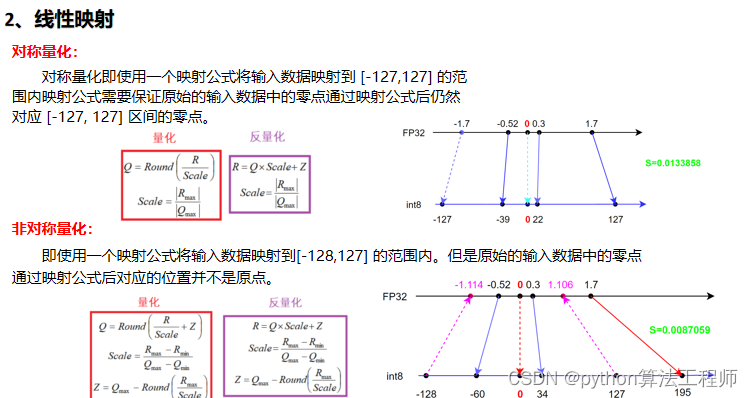
2、线性映射
3、逐层量化、逐组量化和逐通道量化
根据量化的粒度可以分为逐层量化(per-Tensor)、逐组量化(per-Group)和逐通道量化(per-Channel)。
- 逐层量化以一个层为单位,整个 layer 的权重共用一组缩放因子 S 和偏移量 Z;
- 逐组量化以组为单位,每个 Group 使用一组 S 和 Z;
- 逐通道量化则以通道为单位,每个 channel 单独使用一组 S 和 Z。
当 Group =1 时,逐组量化与逐层量化等价;当 Group =num_filters (即深度可分离卷积)时,逐组量化逐通道量化等价。
4、在线量化和离线量化
据激活值的量化方式,可以分为在线(online)量化和离线(offline)量化。
-
在线量化:指激活值的Scale和Z-point在实际推断过程中根据实际的激活值动态计算;
-
离线量化:即指提前确定好激活值的Scale和 Z-point 。
由于不需要动态计算量化参数,通常离线量化的推断速度更快些。
5、权重量化和权重激活量化
权重量化:只将权重的精度从浮点型减低为8bit整型。由于只有权重进行量化,所以无需验证数据集就可以实现。如果只是想为了方便传输和存储而减小模型大小,而不考虑在预测时浮点型计算的性能开销的话,这种量化方法是很有用的。
权重激活量化:可以通过计算所有将要被量化的数据的量化参数,来将一个浮点型模型量化为一个8bit精度的整型模型。由于激活输出需要量化,这时我们就得需要标定数据了,并且需要计算激活输出的动态范围,一般使用100个小批量数据就足够估算出激活输出的动态范围了。
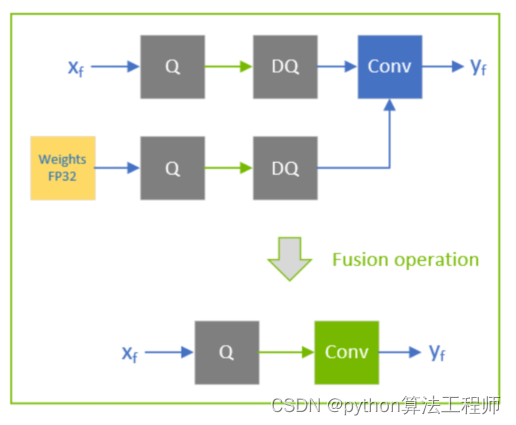
6、量化的一般步骤
对于模型量化任务而言,具体的执行步骤如下所示:
步骤1:在输入数据(通常是权重或者激活值)中计算出相应的 min_value 和 max_value;
步骤2:选择合适的量化类型,对称量化(int8)还是非对称量化(uint8);
步骤3:根据量化类型、min_value 和 max_value 来计算Z(Zero point) 和 S(Scale);
步骤4:根据标定数据对模型执行量化校准操作,即将预训练模型由 FP32 量化为 INT8模型;
步骤5:验证量化后的模型性能,如果效果不好,尝试着使用不同的方式计算 S 和 Z,重新执行上面的操作。
步骤6:如果步骤5.未能满足性能要求,则尝试使用敏感层分析和量化感知训练。
什么是校准?
校准是为模型权重和激活选择边界的过程。为了简单起见,这里只描述了对称范围的校准(工业界一般对称量化即可满足需求),如对称量化所需。这里考虑三种校准方法:

- Max:使用校准期间的最大绝对值;
- Histogram:将范围设置为校准期间看到的绝对值分布的百分位。
- Entropy:使用 KL 散度来最小化原始浮点值和量化比特表示的值之间的信息损失
Max校准是一种常用于深度学习模型量化的技术,用于确定量化参数中的缩放因子和偏置。Max校准通过找到量化前和量化后的最大值之间的差异来确定这些参数。
Max校准的具体步骤如下:
对于每个权重或激活张量,在量化前记录最大值max_pre和最小值min_pre;在量化后记录最大值max_post和最小值min_post。
计算量化参数的缩放因子scale和偏置zero_point。缩放因子是量化前后最大值之间的比例,即scale = (max_pre - min_pre) / (max_post - min_post)。偏置是量化前后最大值的差值除以缩放因子,即zero_point = round((max_pre - max_post) / scale)。
对于每个张量,将其乘以缩放因子scale并减去偏置zero_point,得到量化后的张量。
Max校准可以有效地确定量化参数,使得量化后的模型精度损失最小化。但是,Max校准也可能会引入一定的精度损失,因此需要在精度和效率之间进行平衡,选择合适的量化方法和参数。
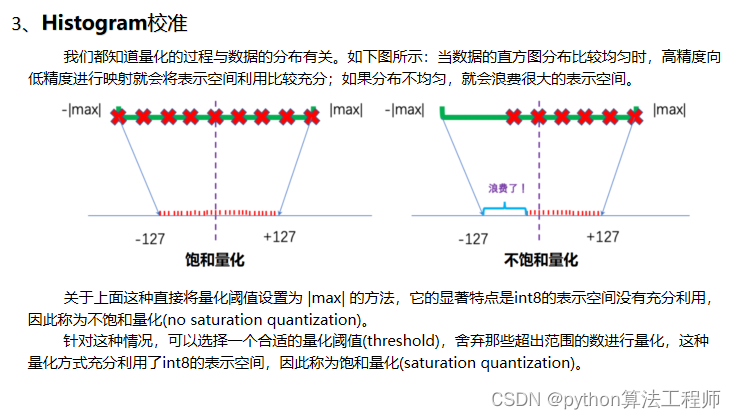
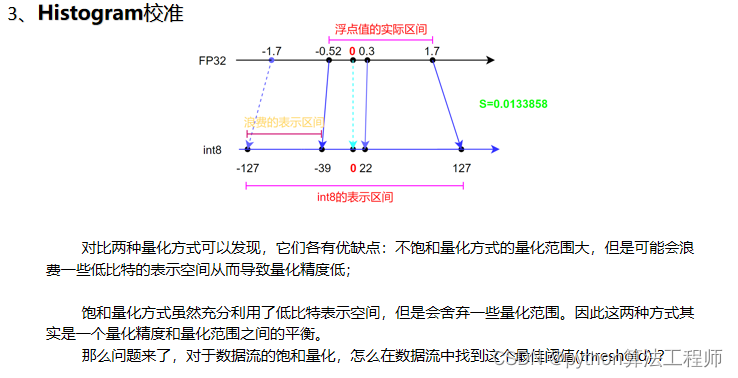

Histogram校准是一种深度学习模型量化的技术,用于确定量化参数中的缩放因子和偏置。它通过直方图分析量化前后的值分布情况,来确定量化参数。
Histogram校准的具体步骤如下:
对于每个权重或激活张量,在量化前记录最大值max_pre和最小值min_pre;在量化后记录最大值max_post和最小值min_post。
统计量化前后的值分布情况。对于每个张量,将其量化前的值按照一定的区间划分为多个桶(bucket),并统计每个桶中的数量。同样地,将量化后的值按照相同的区间划分为多个桶,并统计每个桶中的数量。
计算量化参数的缩放因子scale和偏置zero_point。缩放因子是使得量化前后的值分布尽可能一致的值,即将量化前的值映射到量化后的值,使得两个值分布的重叠部分最大。偏置是使得量化前后的最大值和最小值尽可能一致的值,即将量化前的最大值映射到量化后的最大值,将量化前的最小值映射到量化后的最小值。
对于每个张量,将其乘以缩放因子scale并减去偏置zero_point,得到量化后的张量。
Histogram校准可以更加准确地确定量化参数,使得量化后的模型精度损失最小化。但是,Histogram校准的计算量较大,因此在实际应用中需要权衡精度和效率,选择合适的量化方法和参数。
那么问题来了,对于数据流的饱和量化,怎么在数据流中找到这个最佳阈值(threshold) ?*
对于数据流的饱和量化,通常需要在数据流中找到最佳的阈值(threshold),以便将数据流量化为二进制或多位数字。一种常用的方法是使用自适应阈值法(Adaptive Thresholding)。
自适应阈值法是一种基于数据流动态变化的阈值选择方法,它可以根据数据流的特性自适应地选择阈值,从而实现饱和量化。具体步骤如下:
将数据流分为若干个大小相等的块(block)。
对于每个块,计算其均值(mean)和标准差(std)。
根据均值和标准差计算阈值。常用的阈值计算方法包括:
a. 固定阈值法:将阈值设置为固定值,例如均值或中位数。
b. 自适应阈值法:将阈值设置为均值加上若干倍的标准差,例如mean + k * std,其中k为可调参数。
c. Otsu阈值法:将阈值设置为能够最大化类间方差的值。
将数据流量化为二进制或多位数字,例如将数据流中的每个值与阈值进行比较,大于阈值的赋值为1,小于等于阈值的赋值为0。
将量化后的数据流传输或存储。
自适应阈值法可以根据数据流的特性动态选择阈值,从而更好地适应数据流的动态变化。但是,选择合适的阈值计算方法和参数仍然需要经验和实验验证。
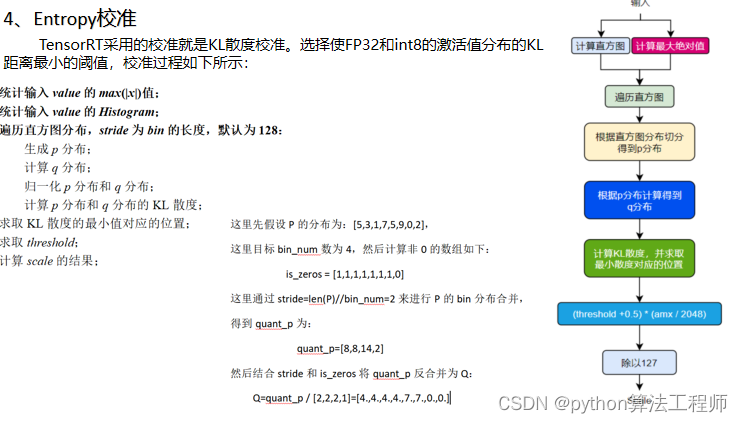
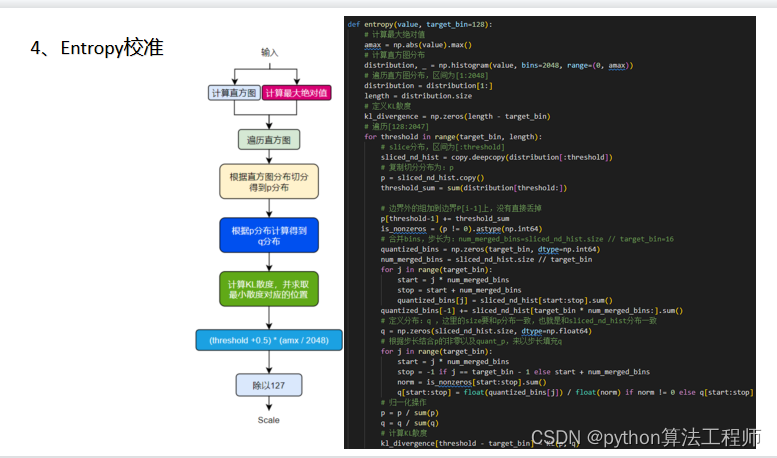 Entropy校准是一种深度学习模型量化的技术,用于确定量化参数中的缩放因子和偏置。它通过最小化量化前后的信息熵差异来确定量化参数。
Entropy校准是一种深度学习模型量化的技术,用于确定量化参数中的缩放因子和偏置。它通过最小化量化前后的信息熵差异来确定量化参数。
Entropy校准的具体步骤如下:
对于每个权重或激活张量,在量化前记录最大值max_pre和最小值min_pre;在量化后记录最大值max_post和最小值min_post。
统计量化前后的值分布情况。对于每个张量,将其量化前的值按照一定的区间划分为多个桶(bucket),并统计每个桶中的数量。同样地,将量化后的值按照相同的区间划分为多个桶,并统计每个桶中的数量。
计算量化参数的缩放因子scale和偏置zero_point。缩放因子是使得量化前后的信息熵尽可能一致的值,即将量化前的值映射到量化后的值,使得两个值的信息熵差异最小。偏置是使得量化前后的最大值和最小值尽可能一致的值,即将量化前的最大值映射到量化后的最大值,将量化前的最小值映射到量化后的最小值。
对于每个张量,将其乘以缩放因子scale并减去偏置zero_point,得到量化后的张量。
Entropy校准可以更加准确地确定量化参数,使得量化后的模型精度损失最小化。但是,Entropy校准的计算量较大,因此在实际应用中需要权衡精度和效率,选择合适的量化方法和参数。
