
3 使用xpath技术结合DOM4J技术读取xml文件(了解)
1.概念介绍
问题:通过上面的案例我们发现有个小问题.就是获取标签的过程太过繁琐。我们需要一层一层的去获取。假设xml嵌套了50层的话,对于我们开发者来说是非常繁琐的。所以我们希望应该有这样的技术,一下子直接就能获取我们所需要的标签对象。这就是我们接下来需要学习的xpath技术。
xpath技术 也是 W3C 组织制定的快速获取 xml文件中某个标签的技术。
xpath其实就像在文件系统中定位文件,所以我们学习xpath主要学习xpath的路径表达式。
2.XPath使用步骤
步骤1:导入jar包(dom4j-1.6.1.jar(dom4j核心包)和jaxen-1.1-beta-6.jar(xpath依赖的包))
步骤2:通过dom4j的SaxReader获取Document对象
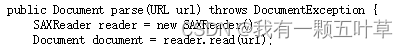
步骤3:使用document常用的api结合xpath的语法完成选取XML文档元素节点进行解析操作。
说明:
- Node叫做节点,DOM里面所有的类型都是Node的子类
- 比如Document Element Attribute 都是 Node的子类
- Node中的两个方法可以使用XPath:
| 方法 | 作用 |
|---|---|
| List selectNodes(“表达式”) | 获取符合表达式的元素集合 |
| Element selectSingleNode(“表达式”) | 获取符合表达式的唯一元素 |
3.XPath语法(了解)
在学习如何使用XPath之前,我们先将课后资料中的tianqi.xml放到项目根目录下,然后我们在演示如何使用xpath。
3.1全文搜索路径表达式方式 掌握
- 代表无论中间有多少层,直接获取所有子元素中满足条件的元素
- 一个“/”符号,代表逐级写路径
- 2个“//”符号,不用逐级写路径,可以直接选取到对应的节点,是全文搜索匹配的不需要按照逐层级 重点
- 需求1:获取天气预报里的所有湿度,不论有多少层
- 需求2:获取广州里面的3个最高温度
//代表无论中间有多少层,直接获取所有子元素中满足条件的元素
@Test
public void demo03() throws Exception {
//全文搜索 //
SAXReader reader = new SAXReader();
Document document = reader.read("tianqi.xml");
//获取天气预报里的所有湿度,不论有多少层
List<Node> list = document.selectNodes("//湿度");
//遍历打印
for (Node node : list) {
System.out.println(node.getText());
}
System.out.println("--------------");
//获取广州里面的3个最高温度
List<Node> list1 = document.selectNodes("/天气预报/广州//最高温度");
for (Node node : list1) {
System.out.println(node.getText());
}
}
