1.ES数据类型
核心数据类型(Core Data Types):
核心数据类型是 Elasticsearch 最基本和常用的数据类型,用于存储大部分数据。这些核心数据类型包括:
- Text(文本):用于存储长文本数据,进行全文搜索和分析。
- Keyword(关键字):用于存储精确值,用于过滤、聚合和精确匹配。
- Numeric(数值):用于存储数值数据,包括整数、浮点数等。
- Date(日期):用于存储日期和时间数据。由于Json没有date类型,所以es通过识别字符串是否符合format定义的格式来判断是否为date类型。
- Boolean(布尔):用于存储布尔值。
- Binary(二进制):用于存储二进制数据。
- Range(范围):Range 类型用于存储数值范围、日期范围和 IP 范围等。它允许你对字段进行范围查询和范围聚合操作。
复杂数据类型(Complex Data Types):
复杂数据类型允许存储结构化的数据,如对象、数组和嵌套字段。这些复杂数据类型包括:
- Object(对象):用于存储嵌套对象或复杂结构的数据。
- Array(数组):用于存储多个值的列表。直接使⽤[ ]定义即可,数组中所有的值必须是同⼀种数据类型, 不⽀持混合数据类型的数组:
使用复杂数据类型可以创建更灵活和复杂的数据结构,支持嵌套查询和聚合操作。
专用数据类型(Specialized Data Types):
专用数据类型是 Elasticsearch 提供的特定用途的数据类型,用于解决特定领域的需求。这些专用数据类型包括:
- GeoPoint(地理点):用于存储地理坐标点,支持地理空间搜索和距离计算。
- GeoShape(地理形状):用于存储复杂的地理形状数据,如多边形、线和点。
- IP(IP 地址):用于存储 IP 地址,支持 IP 地址范围查询和聚合操作。本质上是⼀个⻓整型字段
专用数据类型使得 Elasticsearch 可以更好地处理与地理位置和网络地址相关的数据
2.ES文档CRUD操作
新增文档
1)指定id方式新增:
PUT /my_index/_doc/1
{
"title": "Elasticsearch",
"content": "Elasticsearch is a distributed, RESTful search and analytics engine."
}
2)不指定id方式新增:
PUT /my_index/_doc
{
"title": "Elasticsearch",
"content": "Elasticsearch is a distributed, RESTful search and analytics engine."
}
3)指定id的方式新增,防止因为id相同误修改,可以指定操作类型:
PUT /my_index/_doc/1?op_type=create
{
"title": "Elasticsearch",
"content": "Elasticsearch is a distributed, RESTful search and analytics engine."
}
4)开启自动创建索引:
查看auto_create_index开关状态:
GET /_cluster/settings
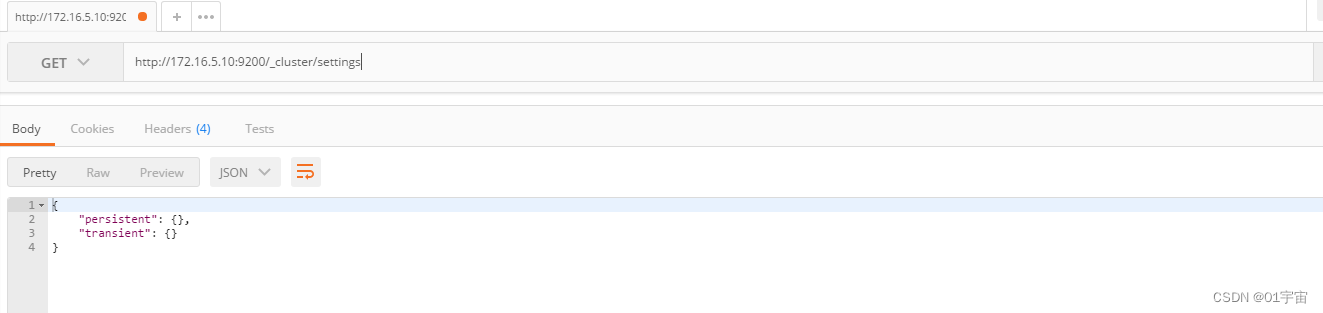
如上图所示没有auto_create_index字段,或者为false表示未开启
开启自动创建索引:
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "true"
}
}
开启自动创建索引后,会更加数据格式自动匹配映射。
查看文档
1)根据id查看
GET /my_index/_doc/1
2)查看多个
POST /my_index/_doc/mget
{
"ids" : ["1", "2"]
}
修改文档
1)更新文档数据
POST /my_index/_doc/1/_update
{
"doc": {
"content": "Elasticsearch is a distributed, RESTful search and analytics platform."
}
}
2)向_source字段,增加⼀个字段
POST my_index/_update/1
{
"script": "ctx._source.lable = es"
}
3)向_source字段,删除⼀个字段
POST my_index/_update/1
{
"script": "ctx._source.remove(\"lable \")"
}
4)根据条件参数,更新指定⽂档的字段
upsert 当指定的⽂档不存在时,upsert参数包含的内容将会被插⼊到索引中,作为⼀个新⽂档;如果指定的⽂档存在,ElasticSearch引擎将会执⾏指定的更新逻辑。
POST my_index/_update/1
{
"script": {
"source": "ctx._source.lable+= params.lable",
"params": {
"lable": "good"
}
},
"upsert": {
"lable": "just so so"
}
}
删除文档
DELETE /my_index/_doc/1