1.1、倒排索引
Elasticsearch使用一种称为倒排索引的结构,它适用于全文搜索,一个倒排索引由文档中所有不重复 的列表构成,对于其中每一个词,有一个包含它的文档列表。
示例:
(1):假设文档集合包含五个文档。每个文档内容如图所示,在图中最左端一栏是每个文档对应的文档编号。我们的任务就是对这个文档集合建立倒排索引。

(2):中文和英文等语言不同,单词之间没有明确分隔符号,所以首先要用分词系统将文档自动切分成单词序列,这样每个文档就转换为由单词序列构成的数据流,为了系统后续处理方便,需要对每个不同的单词赋予唯一的单词编号,同时记录下哪些文档包含这个单词,在如此处理结束后,我们可以得到最简单的倒排索引,“单词ID”一栏记录了每个单词的单词编号,第二栏是对应的单词,第三栏即每个单词对应的倒排列表。

(3):索引系统还可以记录除此之外的更多信息,下图还记载了单词频率信息(TF)即这个单词在某个文档中的出现次数,之所以要记录这个信息,是因为词频信息在搜索结果排序时,计算查询和文档相似度是很重要的一个计算因子,所以将其记录在倒排列表中,以方便后续排序时进行分值计算。

(4):倒排列表中还可以记录单词在某个文档出现的位置信息
(1,<11>,1),(2,<7>,1),(3,<3,9>,2)
有了这个索引系统,搜索引擎可以很方便地相应用户的查询,比如用户输入查询词“Facebook”,搜索系统查找倒排索引,从中可以读出包含这个单词的文档,这些文档就是提供给用户的搜索结构,而利用单词频率信息、文档频率细心即可以对这些候选搜索结果进行排序,计算文档和查询的相似性,按照相似性得分由高到低排序输出,此即为搜索系统部分内部流程。
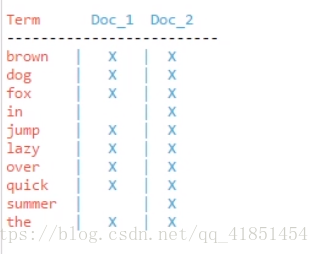
1.2、倒排索引
两个表:
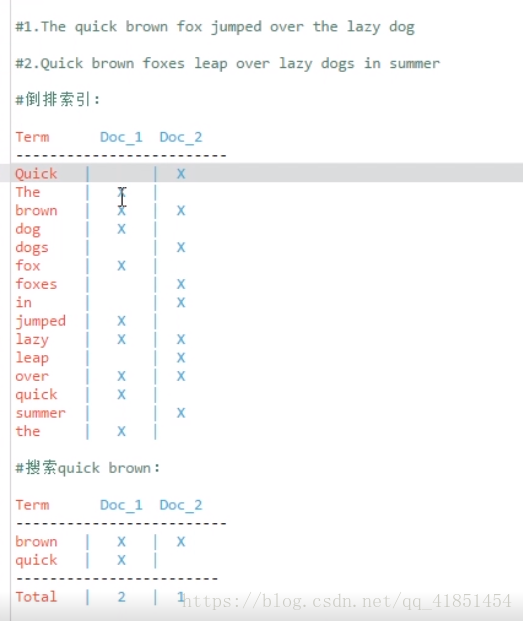
计算相关度分数时,文档1的匹配度高,分数会比文档2高
问题:
Quick 和 quick 以独立的词条出现,然而用户可能认为它们是相同的词。
fox 和 foxes 非常相似,就像 dog 和 dogs;它们有相同的词根。
jumped 和 leap , 尽管没有相同的词根,但它们的司仪很相近。它们是同义词。
搜索含有 Quick fox 的文档是搜索不到的
使用标准化规则(normalization)
建立倒排索引的时候,会对拆分出的各个单词进行相应的处理,以提升后面搜索的时候能够搜索到相关的文档的概率;
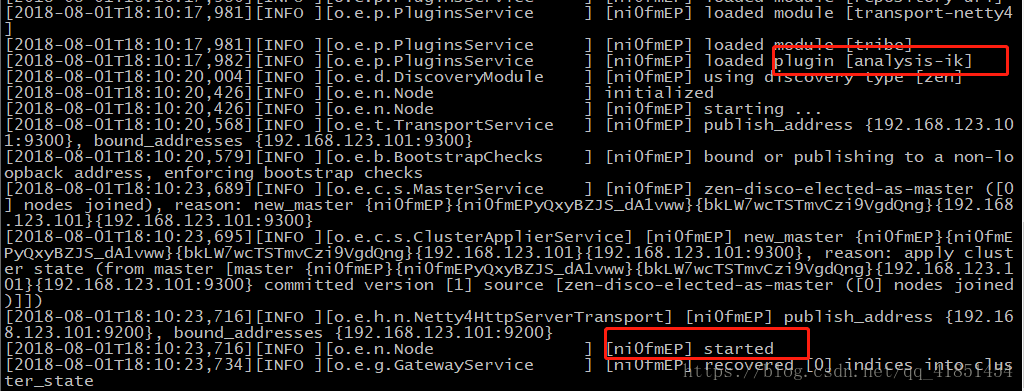
2.1、分词器介绍及内置分词器
分词器:从一串文本中切分出一个一个的词条,并对每个词条进行标准化
包括三部分:
character filter:分词之前的预处理,过滤掉HTML标签,特殊符号转换等
tokenizer:分词
token filter:标准化
内置分词器:
standard分词器:(默认的)他会将词汇单元转换成小写形式,并去除停用词和标点符号,支持中文采用的方法为单字切分;
simple 分词器:首先会通过非字母字符来分隔文本信息,然后将词汇单元统一为小写形式。该分析器会去掉数字类型的字符;
Whitespace分词器:仅仅是去除空格,对字符没有lowcase化,不支持中文;并且不对生成的词汇单元进行其他的标准化处理;
language分词器:特定语言的分词器,不支持中文。
2.2、安装中文分词器
(1)下载中文分词器:
https://github.com/medcl/elasticsearch-analysis-ik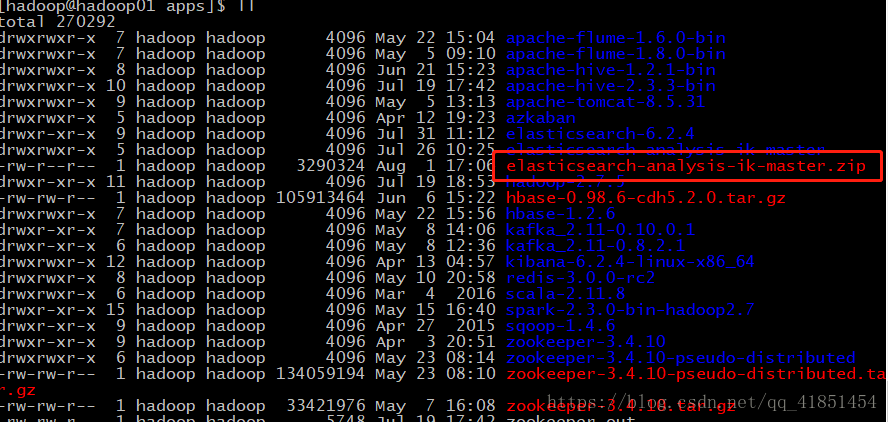
(2)解压elasticsearch-analysis-ik-master.zip
[hadoop@hadoop01 apps]$ unzip elasticsearch-analysis-ik-master.zip (3)进入elasticsearch-analysis-ik-master,编译源码(需要用到maven,自行百度下载)
mvn clean install -Dmaven.test.skip=true
编译成功!
后来报错版本不匹配,后查看elasticsearch安装的是6.2.4,elasticsearch-analysis-ik-6.3.0.zip安装的是6.3.0。
https://github.com/medcl/elasticsearch-analysis-ik/releases
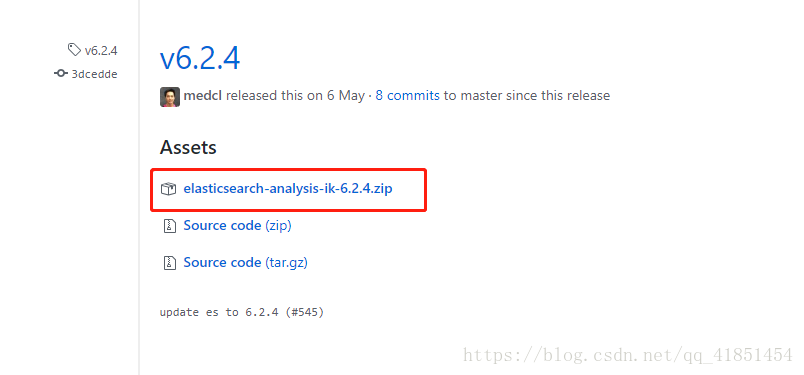
下载6.2.4zip包放入
/home/hadoop/apps/elasticsearch-analysis-ik-master/target/releases路径下:
在这个路径下/home/hadoop/apps/elasticsearch-6.2.4/plugins 新建一个文件夹ik
[hadoop@hadoop01 plugins]$ mkdir ik把zip包挪过来:
[hadoop@hadoop01 releases]$ cp elasticsearch-analysis-ik-6.2.4.zip /home/hadoop/apps/elasticsearch-6.2.4/plugins/ik解压缩:
[hadoop@hadoop01 ik]$ unzip elasticsearch-analysis-ik-6.2.4.zip把elasticsearch里面的文件全部挪到ik目录下:(把空文件夹删掉即可)
[hadoop@hadoop01 elasticsearch]$ mv * /home/hadoop/apps/elasticsearch-6.2.4/plugins/ik启动:
[hadoop@hadoop01 ik]$ elasticsearch