前言:
当使用dom4j查询比较深的层次结构的节点 很麻烦!!!
之前写的几篇博客关于XML的读取都是通过一层一层查找下去,这样的代码冗余难看,也加重了负担,这个时候xPath技术就应运而生了。
老样子:三个问题:
xPath是什么?
xPath怎么用?
xPath运用场景?xPath是什么?
主要是用于快速获取所需的节点对象。是针对XML结构而言。
xPath运用场景?
爬虫(爬取XML结构的节点内容)
我也百度了挺多内容,不过 关于xPath技术的内容不多,而且都比较老,但还是来学习一下吧。简单了解下 以后要是用到了再来学习。
有很多种方法调用xPath技术
这里也就来介绍用Dom4j来操作xPath。
因为Dom4j内置了jar包支持xPath技术。
Dom4j下载
问题:
dom4j-2.1.0源码下载后并没有找到支持xPath的jar包
而dom4j-1.6.1源码下载后有jaxen-1.1-beta-6.jar 这个才是关键
具体原因我也不知道……百度google半天没找到 原因 ,要是有人知道 麻烦告诉我一下,谢谢。
注意:
1. 采用xpath查找需要引入jaxen-xx-xx.jar,否则会 java.lang.NoClassDefFoundError: org/jaxen/JaxenException异常。
2. 如果层次太深还是不建议用xPath,而是用迭代取出,不然会爆内存
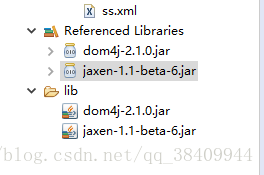
jaxen-1.1-beta-6.jar位置:dom4j-dom4j_1_6_1–>lib–>jaxen-1.1-beta-6.jar
导入:
前提先导入dom4j核心包:
dom4j-1.6.1.jar或者dom4j-2.1.0.jar都可以
然后导入jaxen-1.1-beta-6.jar放入项目中的lib文件夹 然后右键build path–>add to build path
效果图:
使用xpath方法
List<Node> selectNodes("xpath表达式"); 查询多个节点对象
Node selectSingleNode("xpath表达式"); 查询一个节点对象@Test
public void test2() throws Exception {
// 1.读取xml文档,返回Document对象
SAXReader reader = new SAXReader();
Document doc = reader.read(new File(".\\src\\day33\\ss.xml"));
//查询id为12的cons标签
//使用xpath技术
Element element=(Element)doc.selectSingleNode("//cons[@id='12']");
System.out.print(element.getName());
element.detach();
FileOutputStream fileOutputStream=new FileOutputStream("D:\\zz.xml");
XMLWriter writer=new XMLWriter(fileOutputStream);
writer.write(doc);
writer.close();
}意思就是删除了 id为12的cons元素
xPath语法:
/ 绝对路径 表示从xml的根位置开始或子元素(一个层次结构)
// 相对路径 表示不分任何层次结构的选择元素。
* 通配符 表示匹配所有元素
[] 条件 表示选择什么条件下的元素
@ 属性 表示选择属性节点
and 关系 表示条件的与关系(等价于&&)
text() 文本 表示选择文本内容举例:
//选择id属性值为001,且name属性为eric的contact标签
xpath = "//contact[@id='001' and @name='eric']";
//选择name标签下的文本内容,返回Text对象
xpath = "//name/text()";
String id = ((Element)elem.elements().get(0)).getText();
String id = elem.selectSingleNode("td[1]").getText();两者方法达到的效果是一样的 ,都是得到elem下 第一个td标签的文本。
xPath都是写在这些方法里面 返回的是Node元素 根据 最后的结果再强转为我们需要的
List<Node> selectNodes("xpath表达式"); 查询多个节点对象
Node selectSingleNode("xpath表达式"); 查询一个节点对象举例:
xpath = "//@id"; //选择id属性节点对象,返回的是Attribute对象
xpath = "//name/text()"; //选择name标签下的文本内容,返回Text对象
xpath = "//name"; //选择name标签
具体语法和使用可以下载百度云:
截图效果: 我觉得ojbk
Xpath离线文档
注意:
主页面在:
General_chi文件夹下
自己存在百度云的 永久保存的,不丢失
xPath技术模拟用户登录:
user.xml:
<?xml version="1.0" encoding="utf-8"?>
<users>
<user id="001" name="eric" password="123456"></user>
<user id="002" name="rose" password="123456"></user>
<user id="003" name="jack" password="123456"></user>
</users>主程序:
public static void main(String[] args)throws Exception{
//1.获取用户输入的用户名和密码
BufferedReader br =
new BufferedReader(new InputStreamReader(System.in));
System.out.println("请输入用户名:");
String name = br.readLine();
System.out.println("请输入密码:");
String password = br.readLine();
//2.到“数据库”中查询是否有对应的用户
//对应的用户: 在user.xml文件中找到一个
//name属性值为‘用户输入’,且password属性值为‘用户输入’的user标签
Document doc = new SAXReader().read(new File("./src/user.xml"));
Element userElem = (Element)doc.selectSingleNode("//user[@name='" +name +"' and @password='"+password+"']");
if(userElem!=null){
//登录成功
System.out.println("登录成功");
}else{
//登录失败
System.out.println("登录失败");
}
}