XML内容:
`<?xml version="1.0" encoding="UTF-8"?>
<!-- 这里是注释,可以写上说明。。。。。。。。。 -->
<!-- 非法字符:< <=<,& &=& -->
<studs>
<k>
<stu id="10086">
<name>object<</name>
<age>18&</age>
<stuinfo><![CDATA[<a href="http://www.baidu.com">This is my blog如果不想解析器解析一些内容,可以把这些内容放入CDATA区</a>]]></stuinfo>
</stu>
</k>
<stu id="10076">
<name>whatever</name>
<age>random</age>
<stuinfo>nothing</stuinfo>
</stu>
</studs>`
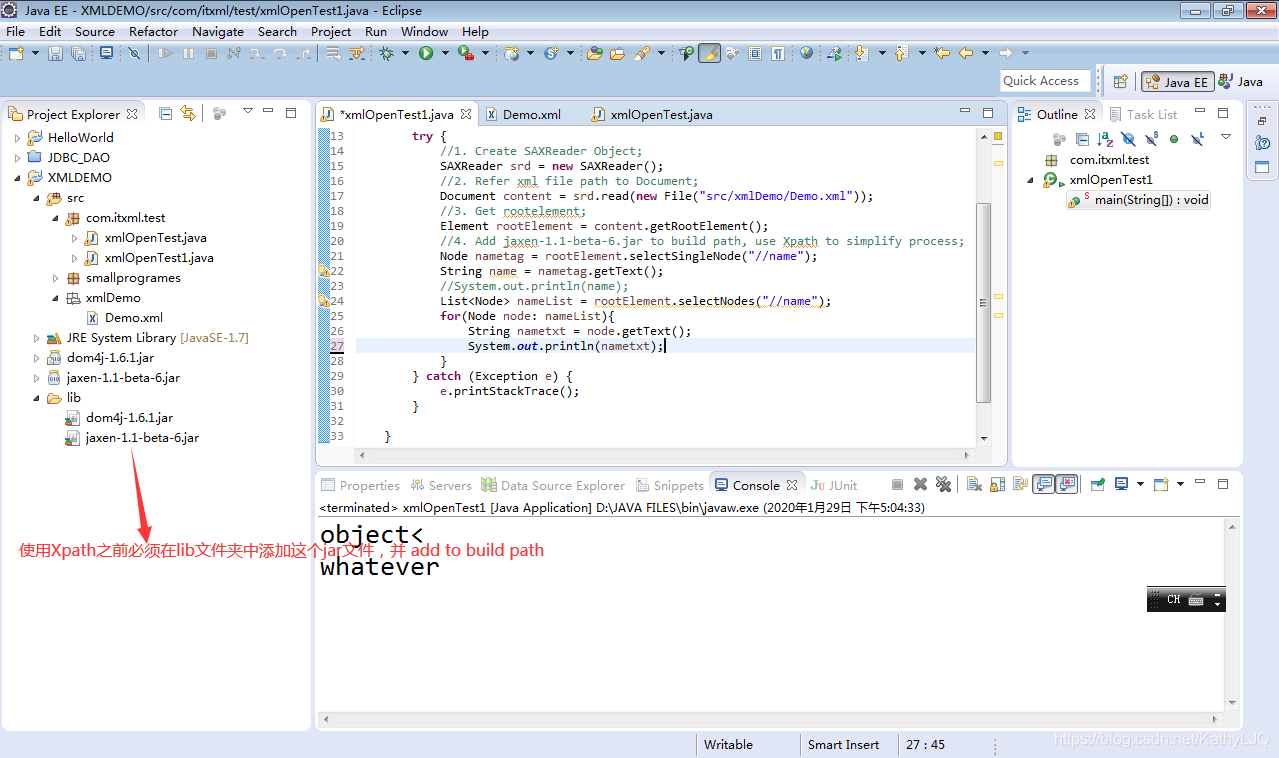
JAVA读取代码:
package com.itxml.test;
import java.io.File;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
public class xmlOpenTest1 {
public static void main(String[] args){
try {
//1. Create SAXReader Object;
SAXReader srd = new SAXReader();
//2. Refer xml file path to Document;
Document content = srd.read(new File("src/xmlDemo/Demo.xml"));
//3. Get rootelement;
Element rootElement = content.getRootElement();
//4. Add jaxen-1.1-beta-6.jar to build path, use Xpath to simplify process;
//Node nametag = rootElement.selectSingleNode("//name");
//String name = nametag.getText();
//System.out.println(name);
List<Node> nameList = rootElement.selectNodes("//name");
for(Node node: nameList){
String nametxt = node.getText();
System.out.println(nametxt);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
