三个多月前,微软亚洲研究院在论文《Language Is Not All You Need: Aligning Perception with Language Models》中发布了一个强大的多模态大模型 Kosmos-1,成功将感知与语言对齐,在 ChatGPT 的多轮对话与推理判断能力的基础上增加了图像识别与理解的能力,将大模型的能力从语言向视觉推进了一小步

而三个多月后,就在昨天,微软亚洲研究院更进一步,推出了 KOSMOS-1 的加强升级版 KOSMOS-2,相较于早期的多模态大模型,KOSMOS-2 解锁了多模态大模型的 Grounding Capability,获得了与输入进行对象级交互的能力,换言之 KOSMOS-2 可以真正将语言与视觉世界相互联系,举一个例子,如下图所示,当我输入一张图片,我希望让模型描述其中有什么时,模型并不仅仅是语言上给出一段文字说一个雪人在烤火,并且我们希望模型可以真正识别到哪里是雪人哪里是火堆,而 KOSMOS-2 则真正具有了这种不仅仅是语言上的描述,并且还可以识别图像之中实体的能力。

某种程度上说,多模态的大模型的这种能力奠定了通往具身 AI(Embodiment AI)的基础,为真正的多模态——语言、感知、行动与世界的大结合提供了启示,再来看一些例子,当用户输入“左眼的 emoji”,KOSMOS-2 可以成功定位到图片之中的心形(1),当输入有多少头牛在图片中,KOSMOS-2 不仅可以回答“Two”,还可以真正的定位到是哪两头牛(2),又如输入一张图片我们询问横幅上是什么字,KOSMOS-2 也能准确识别,并且给出定位(3)。

如果调换一下图片与语言的顺序,输入一张类似龟兔赛跑乌龟与兔子同步冲刺的图片,选中乌龟询问模型为什么 this animal (代指选中的乌龟)并不常见,KOSMOS-2 也可以有理有据的给出解释(4),代表模型可以理解框选的物体以及语言中 this 的指代,再如一个看图说话的场景,输入图片询问 what is it?KOSMOS-2 也成功定位到了画面的主体(5),或者一个框选两瓶饮料询问这两瓶饮料最大的不同,模型也能识别最大的不同在于 label,一个指柠檬,一个指西瓜。

而如果希望来一个全面的分割与解释,来看看 KOSMOS-2 是如何描述图片细节的,如下图所示,KOSMOS-2 不仅成功描述了画面内容,还为每个描述给出了定位。
除了这种偏向感性的认识,来自微软的学者们还对 KOSMOS-2 的各项指标做了一系列的实验,实验分为两部分,一部分测评 KOSMOS-2 区别于 KOSMOS-1 的新能力即 Grounding Capability 的表现,另一部分则对比 KOSMOS-1 在通用的语言任务与 Perception-Language 任务展现 KOSMOS-2 的优势。
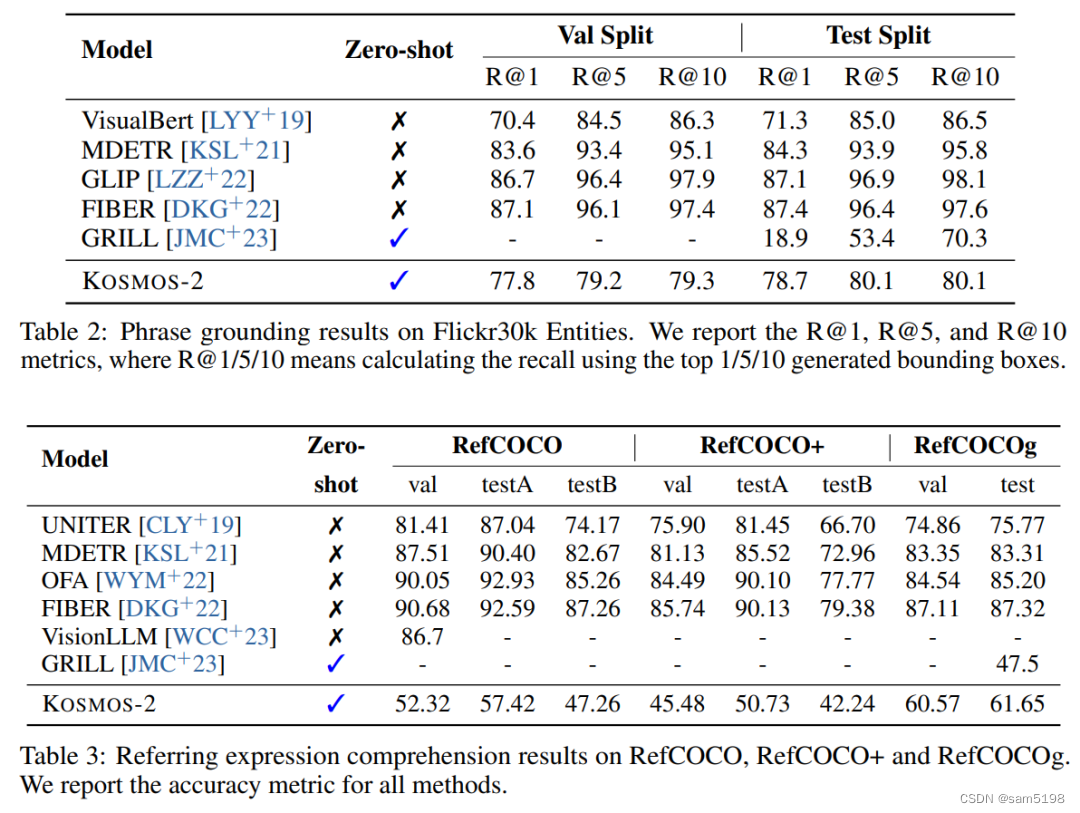
作者采用了两类输入形式对 Grounding 能力进行测试,分别是 Phrase grounding 与 Referring expression comprehension。Phrase grounding 要求模型根据一个或多个短语生成出一组对应的边界框,而 Referring expression comprehension 任务则跟进一步需要模型通过给定的句子找到图片之中的实体,如下图所示:

对比传统微调模型,KOSMOS-2 表现相当亮眼,作为一种 Zero-shot 的模型,在 Phrase grounding 任务中,在指标R@1 上甚至击败了微调模型,且与其他更复杂的模型差距不大。而在 Referring expression comprehension 中,也大幅超过了对标的 Zero-shot 模型,在 RefCOCOg 中也取得了不俗的效果。

同时,作者也希望从对图像的理解出发对模型进行测评,对比之前的多模态大模型只能通过详细的文本描述将图像区域指代给模型的方法,KOSMOS-2 可以使用直接框图的模式,因此论文也希望测评模型是否真正理解了框选出的图像的内容,因此作者团队构建了一个 Referring expression generation 任务,并将 KOSMOS-2 在其中进行了实验:
在这一任务中,KOSMOS-2 的 Zero-shot 能力也让人印象深刻,并且在指标 CIDEr 上也成功击败了微调模型,取得了领先。
而对比 KOSMOS-1,KOSMOS-2在一般的语言及视觉-语言多模态任务,包括图像描述(Image Captioning),视觉回答(Visual Question Answering),以及八个标准的语言任务上进行了实验:

对比 KOSMOS-1,KOSMOS-2 在获得了新的能力的同时,性能整体上与 KOSMOS-1 相当,并且在图像描述任务中还获得了一定的提升。在语言能力方面,KOSMOS-2 在 StoryCloze、HellaSwag、Winograd、Winogrande 和 PIQA 之中的性能都与 KOSMOS-1 相当,在 CB 之中有所下降但在 BoolQ 与 COPA 中有所提供,总的而言 KOSMOS-2 还是在获取新的强大能力的同时保持了自身的基础能力。
那么,KOSMOS-2 是如何诞生的呢?其中一个核心就是作者构建的 Grounded 的图像文本对数据集,即 Grounded Image-Text Pairs(GRIT)。为了实现 KOSMOS-2 的 Grounding 能力,论文基于COYO-700M 和 LAION-2B 构建了一个 Grounded 图像文本对数据集,并与 KOSMOS-1 中的多模态语料库相结合进行训练。整体数据集构建分为两步,首先生成名词-短语-边界框的数据对,得到基础的训练数据,而为了使得模型获得处理复杂语言描述的能力,论文又将短语扩展为复杂的句子,从而扩展了模型的处理能力,数据集 GRIT 的整体构建过程如下图所示:

在经过两步构建之后,最终 GRIT 获得了大约 9100 万幅图像、1.15 亿个文本段落以及 1.37 亿个相关的边界数据框,在上图的表格中作者对比了 GRIT 与现存的 Grounding 数据集的规模。而基于此构建的 GRIT 数据集,KOSMOS-2 采用与 KOSMOS-1 相同的模型架构和训练目标对模型进行训练,值得注意的是,作者通过“超链接”的数据格式连接位置标记与相应的文本段落,整体训练策略与方式可以参考 KOSMOS-1 的论文。
总结与讨论
无疑,将自然语言真正的链接到视觉世界是实现智能的关键一步,而 KOSMOS-2 则有力的推进了视觉与语言更深层次的联系,实现了对象级感知图像区域的新能力,并且具有不俗的语言理解与图像识别的能力。当具身的 AI 真正进入现实世界,Grounding Capability 将是一个真正的基础能力,KOSMOS-2 的出现一定可以让一窥具身 AI 的真正曙光!