- 如何优化sql带查询的分页查询
1、分析浅分页和深分页查询的效率(深分页的效率更差)

分析:

- 其中type为all说明走的全表扫描
- Extra说明有额外执行我们的using filesort
深分页

分析:

情况是一样的但是执行时间会有不同

浅分页1.2s
深分页2.0s
思考:为什么浅分页的查询时间短,而深分页查询时间长?
原理:其中浅分页我们的偏移量小,而我们的深分页偏移量大,其中偏移量大扫描的行数就会比浅分页要多,所以就时间更长
2、如何优化sql
2.1、方案一order by增加索引(我们要先给这个排序字段建立索引。这样不就走索引了吗)

分析

我们就发现其中key走了索引,然后type就是index了,extra也为空,那么也就是没有执行额外的任务了
我们再看深分页(出现问题了)

分析:还是全表扫描,也有额外执行任务,没走索引

浅分页用时,0.38s
深分页用时,1.91s
思考:为什么浅分页查询得到提升,深分页没有变化?
原理:

我们找完sorce是很快,但是我们找其他字段还会回表查找,而浅分页回表成本会很低,而深分页的回表成本会很高所以就不行了
2.2深分页强制走索引?(用时3.1s更高了)

用时更高了!!!

原理:我们的排序有时间成本,回表也有时间成本(mysql帮我们两者去最优反而没什么用了)
2.3、深分页回表成本高我们就不要回表,增加联合索引(给order by 和select增加联合索引)执行时间大大提高

其中key有走联合索引,extra 消除了using filesort也就是使用了我们的覆盖索引

!!!执行时间0.04s
2.4、不足之处
当我们需求变更的时候(例如又需要查找其他字段),索引就失效了

解决方案
2.4.1、方案1.我们根据id手动回表(让其强制走索引)
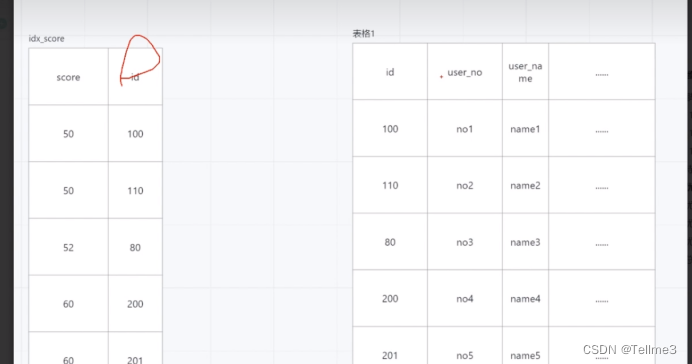
先找id,再根据id找其对应的三个参数

分析


用时0.08s
2.4.2、方案二:从业务着手,通过限制分页和前端配合交互(每页最后一条的所需数据字段传过来)
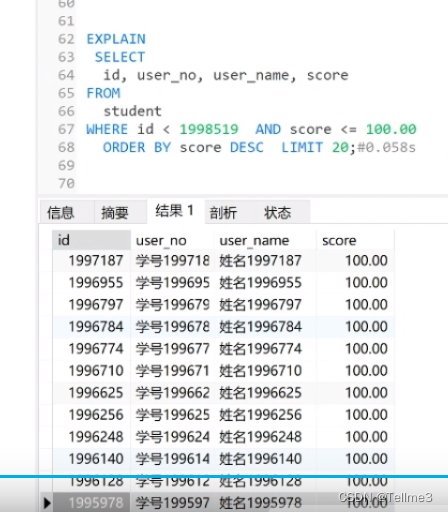
时间0.058s
原理:是我们的where条件和我们的desc配合,查询出分页。
总结
