目录
1.关联式容器和序列式容器
set:关联式容器——数据之间关联紧密
线性表(vector,list,deque):序列式容器——数据之间关联性基本为0
2.键值对
用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量,键值key和对应的信息val
比如现在想要统计十个成语出现的次数,那么成语这个字符串和他的次数就有紧密的一一对应关系
第一个模板参数是T1类型,就是key的类型,第二个是val的类型
键值对是一个类,T1和T2的类型允许不同,两个成员变量first和second都是公有的

template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
pair() : first(T1()), second(T2())
{}
pair(const T1& a, const T2& b) : first(a), second(b)
{}
};3.树型结构的关联式容器
根据不同的应用场景,STL实现了两种功能不同的管理式容器:树型结构和哈希结构
树形结构一般有四种:set,map,multiset,multimap
这四种容器的特点是:底层结构使用红黑树(平衡搜索二叉树),中序遍历是有序的
4.set

注意:
1. 与map/multimap不同,map/multimap中存储的是真正的键值对<key, value>,set中只放
value,但在底层实际存放的是由<value, value>构成的键值对。
2. set中插入元素时,只需要插入value即可,不需要构造键值对。
3. set中的元素不可以重复(因此可以使用set进行去重)。
4. 使用set的迭代器遍历有序
5. set中的元素默认按照小于比较
6. set中查找某个元素,时间复杂度为:logn
7. set中的元素不允许修改:随意修改会破坏二叉搜索树的结构
8. set中的底层使用二叉搜索树(红黑树)来实现。
 并且看到最后一种初始化方式,set可以拷贝构造
并且看到最后一种初始化方式,set可以拷贝构造
set支持迭代器,也就是set支持范围for

int main()
{
int arr[] = { 0,12,3,4,5,65,7,1,4,1,4,7,4 };
set<int> s1;
for (auto e : arr)
{
s1.insert(e);
e++;
}
set<int> s2(s1);
for (auto e : s2)
{
cout << e << " ";
e++;
}
return 0;
}很明显观察到,set:去重+排序
注意:set一般不喜欢用push,而是使用insert
5.multiset

他也在set的头文件,无需新加
他的功能从字面上就是可以允许重复元素
multiset:排序
其余和set没区别,只是set和multiset都有count函数,因为这个计算特殊val个数的函数在头文件<set>中,虽然计数对于set没啥用(因为去重),但是对于multiset还是很有用

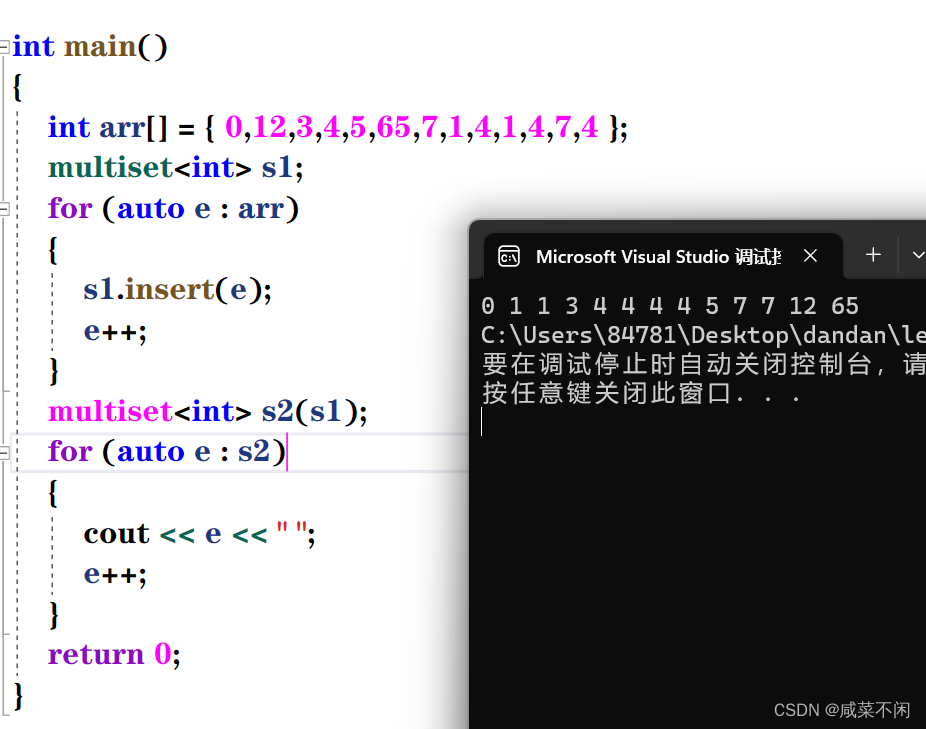
int main()
{
int arr[] = { 0,12,3,4,5,65,7,1,4,1,4,7,4 };
multiset<int> s1;
for (auto e : arr)
{
s1.insert(e);
e++;
}
multiset<int> s2(s1);
for (auto e : s2)
{
cout << e << " ";
e++;
}
return 0;
}那么允许重复怎么通过val找到位置,答案是找中序的第一个val

那么set/multiset的find和算法库里面的find有什么区别?
肯定是原理不同,find是暴力查找,但是set.find()是按搜索树顺序查找,更快


6.map

清楚看到。map的类模板有key的类型,val类型和比较函数模板,还有空间适配器申请底层空间(现在不需要了解)
并且map中元素都是成对出现的,key值主要是用来排和唯一标识元素,而val值主要是存储key值的信息(这让我想起来法语的复合时态:etre/avoir+v. 第一个单词无实意,是用来表明时态的(过去或者将来之类的),而动词的用法常常表明意思),这一对组合起来构成map的成员类型,他是一个键值对
看两个函数

说明lower_bound是闭区间

upper_bound 是开区间

erase删除的区间也是左闭右开

这段代码的iulow是找小于等于'b'的元素,itup是指找大于‘d’的map中最小的元素
所以最后的结果是

int main()
{
std::map<char, int> mymap;
std::map<char, int>::iterator itlow, itup;
mymap['a'] = 20;
mymap['b'] = 40;
mymap['c'] = 60;
mymap['d'] = 80;
mymap['e'] = 100;
itlow = mymap.lower_bound('b'); // itlow points to b
itup = mymap.upper_bound('d'); // itup points to e (not d!)
mymap.erase(itlow, itup); // erases [itlow,itup)
// print content:
for (std::map<char, int>::iterator it = mymap.begin(); it != mymap.end(); ++it)
std::cout << it->first << " => " << it->second << '\n';
return 0;
}看一下map是怎么使用的吧

int main()
{
map<string, string> dict;
dict.insert(pair<string,string>("string","字符串"));
dict.insert(pair<string, string>("left", "左"));
dict.insert(pair<string, string>("is", "是"));
for (auto e : dict)
{
cout << e.first << ":" << e.second << endl;
}
return 0;
}但是这样每次自己写pair很繁琐,所以以后这种过程可以简化为

这是自己创建map,那么对于一个数组,我想统计每一个字符串出现的次数怎么看呢
用一个find函数找map中是不是有e对应的字符串,find返回值是一个迭代器
![]()
迭代器的类型是value_type,上面说过就是map的key和val合起来的类型,就是pair类
![]() 迭代器的second在我的Map就是int类型,用来记录每一个字符串出现次数
迭代器的second在我的Map就是int类型,用来记录每一个字符串出现次数

int main()
{
string s[] = { "苹果","香蕉","柿子","苹果","香蕉" ,"香蕉","柿子","香蕉" };
map<string, int> Map;
for (auto& e : s)
{
auto it =Map. find(e);
if (it == Map.end())
Map.insert(make_pair(e, 1));
else
it->second++;
}
for (auto e : Map)
{
cout << e.first << ":" << e.second << endl;
}
return 0;
}
但是这样写其实是笨笨的
因为map有一个很神奇的运算符重载,就是方括号[ ]

居然一排就搞定了,那么这个方括号的作用到底是什么?
 我们一起慢慢看这段文字
我们一起慢慢看这段文字
首先方括号的运算符重载函数的参数是key,返回值是val
也就是你传入一个key,我就给你他的val,并且返回引用,具体的值是用默认的构造函数构造的
那如果你给的key不在map里,我给你new一个key盛装你传过来的参数
并且他还贴心的告诉我们,有一个方括号同样功能的函数at,行为一样吗,只不过如果你传的key不在map,抛异常(老操作了,之前讲的很多支持下标随机访问的容器也都支持at,都是如果不成功那么抛异常)
最后看一下他给的一行奇怪原理
他说调用方括号函数的时候,是这样调用的
 肯定是从内往外看
肯定是从内往外看

首先他通过this指针调用insert函数,插入一个键值对,键值对的key就是你传过来的参数key,val的部分调用一个匿名构造
![]() 然后insert有返回值
然后insert有返回值

insert的返回值是一个键值对,这个键值对的第一个成员变量first会设置一个迭代器,指向新插入的元素,或者指向在map中有相同key的元素
第二个成员变量second被设置成bool类型,如果这个元素成功插入(原来map中没有key),second=true;否则(map存在key),second=false;

无论如何,insert的返回值就是一个键值对,也就橙色框现在是一个键值对,通过.的方式访问类的first成员变量(来到红色框)然后解引用,找到对应的second,返回second的值
验证一下我们的解释
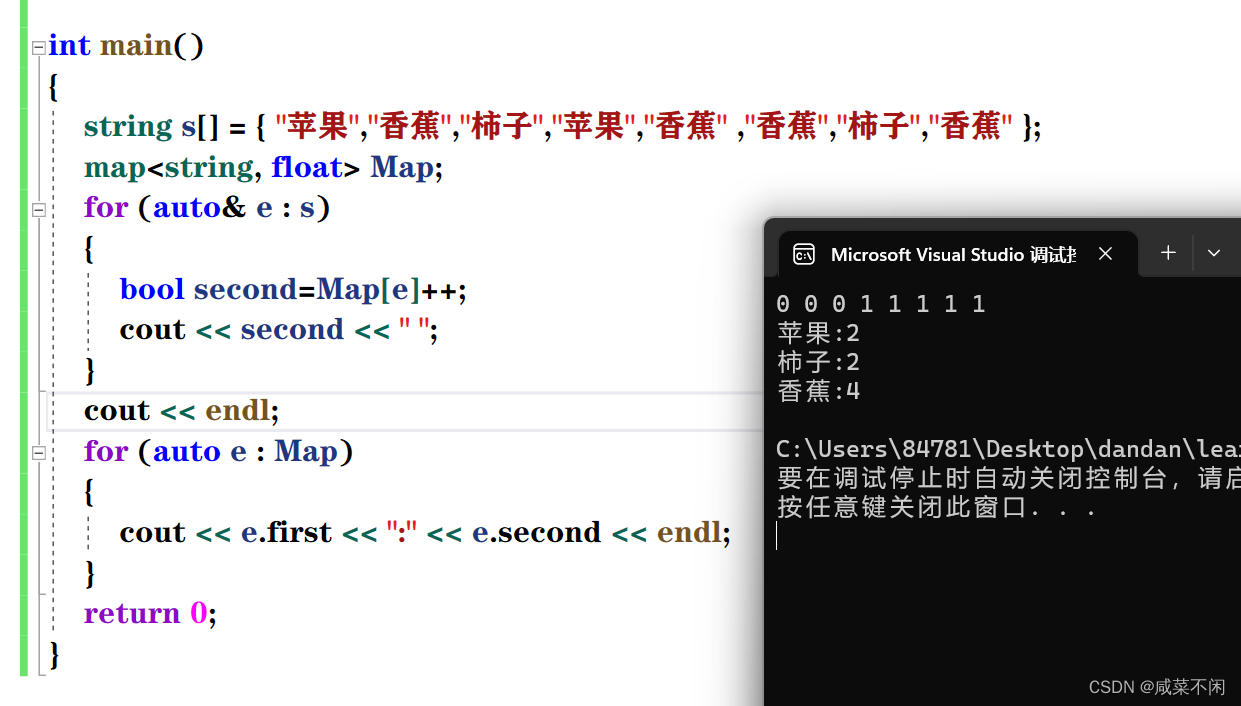
当第一次遇到苹果,香蕉,柿子的时候,second都是false(0)
再遇到就变成true(1),因为map中已经有这三个字符串
小小总结这个强大的函数[ ]:
他有三层功能:插入,查找,修改
7.multimap
允许相同的key存在多个不同的val

他的功能和map是一样的,但是他不支持[ ]
因为在multimap中一个key可能对应好多个val,通过first找second会乱套
他也给我们提供一个很好的思路——一个key可以对应多个val
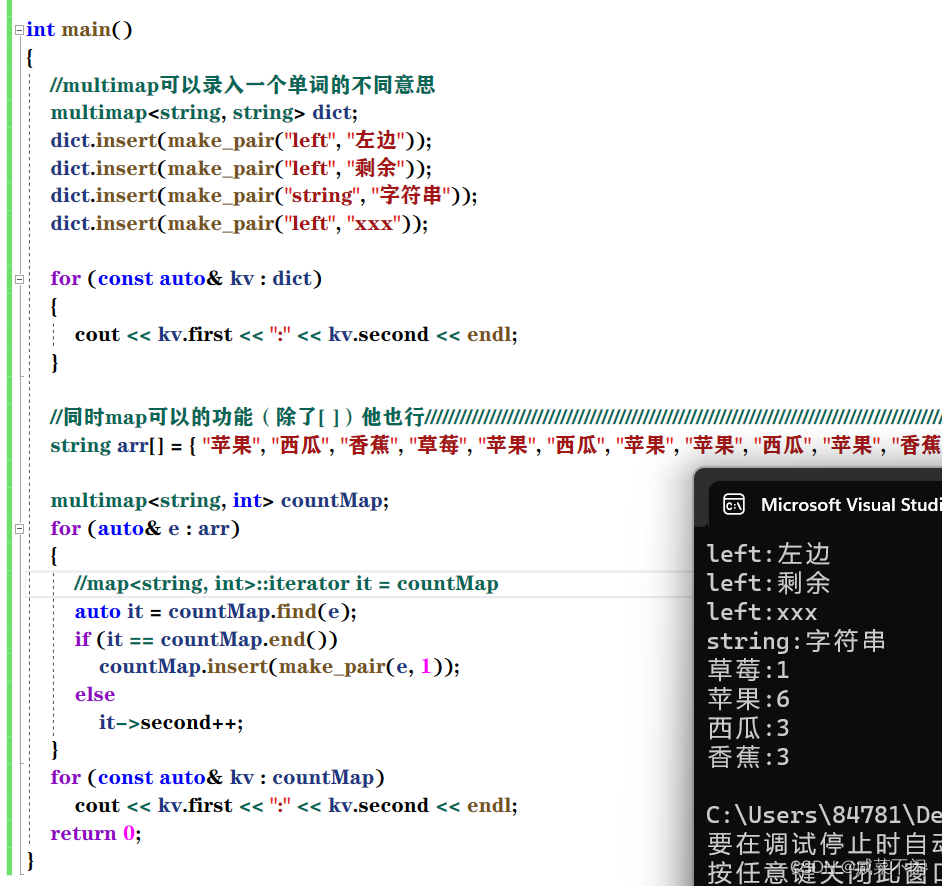
int main()
{
//multimap可以录入一个单词的不同意思
multimap<string, string> dict;
dict.insert(make_pair("left", "左边"));
dict.insert(make_pair("left", "剩余"));
dict.insert(make_pair("string", "字符串"));
dict.insert(make_pair("left", "xxx"));
for (const auto& kv : dict)
{
cout << kv.first << ":" << kv.second << endl;
}
//同时map可以的功能(除了[ ])他也行/
string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
multimap<string, int> countMap;
for (auto& e : arr)
{
//map<string, int>::iterator it = countMap
auto it = countMap.find(e);
if (it == countMap.end())
countMap.insert(make_pair(e, 1));
else
it->second++;
}
for (const auto& kv : countMap)
cout << kv.first << ":" << kv.second << endl;
return 0;
}